Article Summary
Dominando OCR por Lotes a Excel en 2026 En el panorama impulsado por los datos de 2026, la entrada manual tradicional de documentos no estructurados, como facturas, recibos e informes de logística, se ha convertido en un cuello de botella crítico para el crecimiento. Este artículo proporciona una guía definitiva sobre las tecnologías de OCR por Lotes a Excel, enfatizando que el OCR moderno ha trascendido la simple transcripción de texto para centrarse en la reestructuración inteligente de datos y la conciencia del contexto.
Dominio de Grandes Conjuntos de Datos: La Guía Definitiva de OCR por Lotes a Excel
Lidiar con grandes conjuntos de datos a menudo significa enfrentarse a una montaña de documentos no estructurados. Ya sea en finanzas, logística o atención médica, el gran volumen de facturas, recibos e informes puede ser abrumador. El método tradicional de entrada manual de datos no solo es lento; es un cuello de botella que sofoca el crecimiento e introduce errores costosos. La solución moderna radica en aprovechar la extracción automatizada de datos a través de tecnologías de OCR por lotes a Excel. Pero, ¿cómo navegar por el panorama de las herramientas disponibles e implementar una solución que realmente escale? Esta guía proporciona la experiencia profunda que necesita para dominar el procesamiento de documentos a granel y lograr OCR de alta precisión para sus datos financieros y operativos críticos.
Reflexiones sobre el panorama actual de OCR: más allá de la transcripción básica
Un análisis reciente e perspicaz de Lido, titulado "El mejor software de OCR para la extracción de datos en 2024", profundiza en los matices críticos de la selección de la herramienta de Reconocimiento Óptico de Caracteres adecuada. El autor enfatiza que el OCR moderno ha trascendido la simple transcripción de texto, exigiendo ahora una estructuración de datos sofisticada y conciencia del contexto. Específicamente, el artículo destaca:
"El verdadero valor del OCR moderno no reside solo en el reconocimiento de caracteres, sino en la comprensión de la estructura de los datos que extrae. Para las empresas que manejan documentos complejos como facturas y estados financieros, la capacidad de analizar con precisión tablas y mantener relaciones de datos es primordial. Sin esto, los 'datos extraídos' son simplemente un revoltijo de texto, que aún requiere un esfuerzo manual considerable para reorganizarlo y hacerlo utilizable. Las plataformas de extracción de datos efectivas deben ofrecer una detección robusta de tablas y capacidades de análisis de diseño para ofrecer información verdaderamente procesable directamente en formatos como Excel o bases de datos relacionales." (Fuente: https://www.lido.app/blog/best-ocr-software)
Como experto en marketing de contenidos SaaS profundamente inmerso en el espacio de la automatización de documentos, encuentro esta perspectiva increíblemente resonante. El artículo de Lido identifica correctamente el desafío central que muchas empresas pasan por alto: la 'T' en OCR debería significar 'Transformación', no solo 'Transcripción'. El mercado está inundado de herramientas OCR genéricas que pueden digitalizar una página de texto. Sin embargo, muy pocas poseen la inteligencia especializada requerida para el análisis de tablas financieras en cientos o miles de documentos simultáneamente. Aquí es precisamente donde el cuello de botella cambia de 'leer' el documento a 'reestructurar' los datos, un paso crítico para el análisis posterior o la integración ERP.
Además, el artículo subraya el papel crítico de la integración. En mi experiencia, incluso un motor OCR altamente preciso se convierte en un silo si no puede inyectar datos sin problemas en los flujos de trabajo existentes. Una solución robusta de OCR por lotes a Excel debe no solo sobresalir en el análisis de diseño, sino también proporcionar APIs o webhooks robustos para conectarse con plataformas como Salesforce, NetSuite o software de contabilidad especializado. Esto se hace eco del enfoque de la pieza de Lido en plataformas que ofrecen pipelines de datos integrales. La capacidad de manejar diversos formatos de documentos, desde PDFs e JPEGs hasta TIFFs complejos de varias páginas, en masa, manteniendo una alta precisión e integridad estructural, ya no es un lujo; es una necesidad competitiva para cualquier organización impulsada por datos.

El cuello de botella de múltiples formatos: por qué la variedad de sus documentos está matando la eficiencia
Hablemos del verdadero punto débil en el procesamiento de documentos a gran escala. No es solo el volumen; es la pura y sin adulterar [variedad] de formatos y diseños de documentos. Su departamento de finanzas no recibe facturas en un único formato estandarizado. Las reciben como PDF vectoriales de proveedores importantes, JPEGs escaneados de baja calidad de proveedores más pequeños, TIFFs de varias páginas de sistemas de fax antiguos y, tal vez, incluso algunos caóticos documentos de Word. Esta es la Incapacidad de Procesar en Lote Formatos Variados, y es un asesino de la productividad. Los métodos convencionales y las herramientas OCR menos avanzadas le obligan a procesar cada formato de manera diferente, a menudo requiriendo una tediosa preselección manual o la creación de plantillas para cada diseño de proveedor individual.
- Cada nuevo diseño de proveedor exige una [nueva plantilla] o configuración.
- Los documentos escaneados a menudo requieren [preprocesamiento manual de imágenes] como la corrección de inclinación.
- Combinar diferentes tipos de archivo en un único lote de procesamiento es frecuentemente [imposible].
- Las reglas de extracción de datos que funcionan para un PDF claro [fallan] en un escaneo granulado.
- El resultado es un flujo de trabajo fragmentado que [no puede ser verdaderamente automatizado].
Imagine a su equipo de cuentas por pagar intentando procesar 10.000 facturas al mes. 6.000 son PDF estándar, pero 4.000 son una mezcla de escaneos, correos electrónicos con imágenes incrustadas y tipos de archivo extraños. El enfoque convencional significa que el equipo puede automatizar quizás el 60% del flujo de trabajo, pero el 40% restante requiere una intervención manual muy disruptiva y lenta. Esto no es solo ineficiente; es una [barrera de escalabilidad masiva]. La incapacidad de tratar todos estos formatos variados como un solo 'lote' unificado significa que su procesamiento de documentos en masa está constantemente encontrando obstáculos. No está logrando una verdadera automatización; solo está automatizando las partes fáciles y dejando las partes difíciles y costosas para los humanos, lo que va en contra del propósito de adoptar la tecnología en primer lugar.
Este dolor se intensifica drásticamente al tratar con documentos complejos de varias páginas como [contratos legales] o [informes de ensayos clínicos]. Un documento de 50 páginas podría contener tablas financieras críticas en las páginas 12, 35 y 48, cada una formateada de manera ligeramente diferente. Una herramienta OCR básica podría extraer todo el texto, pero fallaría por completo en reconocer que la tabla de la página 35 es una continuación de la de la página 12, o que el formato ha cambiado. Los datos salen como un flujo incoherente de texto, lo que requiere horas de corte, pegado y reestructuración manual en Excel. Este cambio de contexto constante y lleno de fricciones, junto con la limpieza de datos, es lo que hace que el procesamiento de documentos a gran escala sea increíblemente doloroso y costoso. No se trata solo de leer caracteres; se trata de conquistar el caos del diseño.
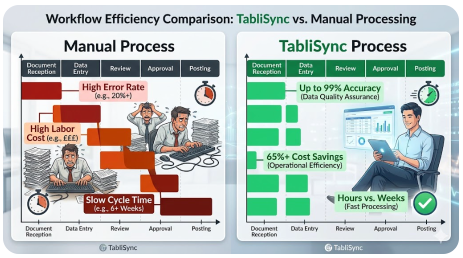
La Brecha de Eficiencia y Costos: Organización Manual vs. Conversión Automatizada con TabliSync
Para comprender verdaderamente el valor de la OCR de alta precisión y la extracción automatizada de datos, debemos comparar el status quo —organizar manualmente los datos en un archivo de Excel— con la conversión utilizando TabliSync. La diferencia no es solo marginal; es transformadora en términos de [eficiencia, ahorro de costos y calidad de los datos]. Analicemos la economía y las realidades operativas de ambos enfoques utilizando puntos de referencia y escenarios reales de la industria.
Los Costos Ocultos del Status Quo Manual
Procesar manualmente 10.000 documentos al mes es una tarea monumental. Un especialista experimentado en entrada de datos puede procesar, en promedio, quizás 40-60 documentos complejos (como facturas multilínea) por hora, incluida la verificación. Para manejar 10.000 documentos, necesitaría aproximadamente 200 horas de trabajo concentrado. Con un costo promedio total de $30/hora (incluyendo beneficios y gastos generales), su costo mensual de mano de obra solo para la entrada de datos es de $6.000.
- [Altas tasas de error]: La entrada de datos humana típicamente tiene una tasa de error del 1-3%. Para 10.000 documentos, eso son 100-300 documentos con datos incorrectos, lo que lleva a costosos problemas de [reconciliación], retrasos en los pagos o problemas de cumplimiento.
- [Problemas de escalabilidad]: Para duplicar su capacidad, debe duplicar su personal, lo que genera aumentos proporcionales en los costos y gastos generales de gestión. [Escalar es lineal y costoso].
- [Tiempos de ciclo lentos]: Puede llevar días o semanas procesar un lote grande, lo que retrasa la visibilidad financiera y la toma de decisiones operativas. [Datos lentos equivalen a negocios lentos].
- [Baja moral de los empleados]: La entrada de datos es repetitiva y tediosa, lo que lleva a una alta [rotación] de empleados y los costos de reclutamiento asociados.
La ventaja de TabliSync: Eficiencia y ahorros realizados
Ahora, veamos los mismos 10.000 documentos procesados con la solución OCR por lotes a Excel de TabliSync. TabliSync puede procesar miles de páginas por hora. El esfuerzo manual cambia de la 'entrada' al 'manejo de excepciones' y la 'verificación'. Típicamente, para documentos de alta calidad, las tasas de automatización pueden superar el 90-95%, lo que significa que solo el 5-10% de los documentos requieren revisión humana.
En lugar de 200 horas, su equipo podría dedicar 20 horas a verificar excepciones. Con la misma tarifa de $30 por hora, su costo de mano de obra se reduce a $600. El costo de la plataforma TabliSync (asumiendo un nivel SaaS típico para este volumen) podría rondar los $1,500 por mes. Su costo total ahora es de $2,100, una [reducción del 65%] en los costos operativos. Pero los ahorros no terminan ahí.
- [Tasas de error drásticamente más bajas]: El motor impulsado por IA de TabliSync proporciona hasta un 99% de precisión, lo que reduce significativamente los costos asociados con los errores de datos.
- [Escalabilidad casi instantánea]: Para manejar 20,000 documentos, simplemente ajusta tu suscripción. No hay necesidad de contratar o capacitar nuevo personal. [La escalabilidad es exponencial y rentable].
- [Tiempos de ciclo rápidos]: Los lotes que tomaban semanas ahora se procesan en horas, lo que proporciona [visibilidad financiera en tiempo real].
- [Trabajo de mayor valor]: Su equipo se libera para [tareas analíticas], planificación estratégica y gestión de relaciones con proveedores.
- [Cumplimiento mejorado]: Cada extracción se registra y es auditable, creando un [rastro de auditoría] sólido y reduciendo el riesgo regulatorio.
Considere una gran empresa de logística que cambió a TabliSync para procesar conocimientos de embarque. Redujeron su equipo de entrada de datos de 15 a 3 personas, mientras *aumentaban* su volumen de procesamiento en un 40%. Los 12 miembros del personal fueron recapacitados y trasladados a roles de alto valor en planificación logística y atención al cliente. Los ahorros directos fueron de más de $450,000 anuales, sin incluir el valor derivado de ciclos de facturación más rápidos y errores reducidos. Este es el impacto cuantificable de pasar del caos manual a la precisión automatizada.
Guía paso a paso para ejecutar un proyecto de OCR a gran escala a Excel
Ahora que comprende el sólido caso de negocio para OCR por lotes a Excel, repasemos la ejecución real utilizando una plataforma potente como TabliSync. El éxito en el procesamiento de documentos masivos no se trata solo de hacer clic en un botón; implica un enfoque metódico para garantizar la precisión, la estructura y un flujo de datos sin problemas. Esta guía describirá los pasos precisos, completos con detalles de configuración y mejores prácticas operativas, para llevarlo de una montaña de documentos a datos estructurados y procesables en Excel.
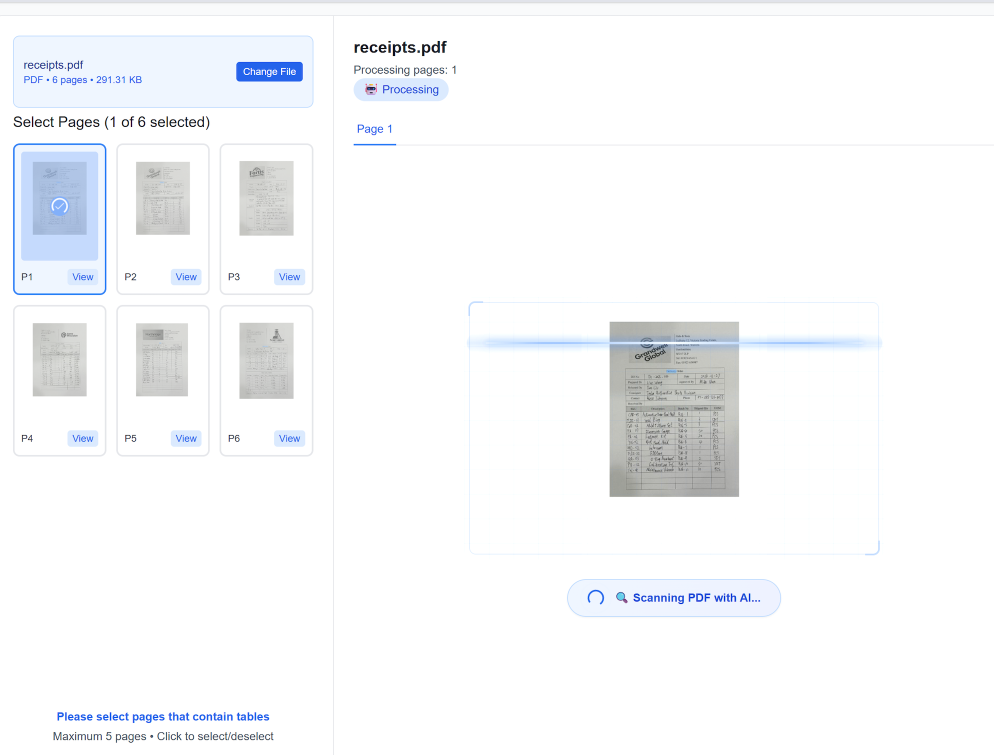
Paso 1: Configuración del lote e ingesta de documentos
El primer paso, y quizás el más crítico, es configurar su lote e ingerir sus diversos documentos. Aquí es donde supera el cuello de botella de los múltiples formatos. En TabliSync, no necesita preclasificar los archivos. Simplemente inicie sesión en su panel seguro y cree un nuevo [Lote de procesamiento]. Dentro de la configuración, especifica el [formato de salida] (en este caso, Excel), la [configuración del motor OCR] preferida (por ejemplo, equilibrar velocidad vs. precisión para escaneos particularmente granulados) y cualquier [regla de preprocesamiento] como rotación automática o reducción de ruido.
Una vez configurado, tiene varias opciones de ingesta para sus grandes conjuntos de datos. Para unos pocos cientos de archivos, la interfaz de [carga web directa] es suficiente. Para miles de documentos, idealmente utilizaría nuestra [puerta de enlace SFTP] segura o la potente [API de TabliSync]. Por ejemplo, una empresa de logística global utiliza la API para enrutar automáticamente los correos electrónicos entrantes con archivos adjuntos directamente a un lote de procesamiento, eliminando por completo el manejo manual. TabliSync acepta prácticamente cualquier formato: PDF multipágina, TIFF complejos, JPEG e incluso archivos ZIP que contienen una mezcla de tipos de archivos. El sistema [desempaqueta, estandariza y prepara] automáticamente cada documento para la siguiente etapa, proporcionando un registro de ingesta en tiempo real.
[Nota de precaución]: Al configurar su lote, preste mucha atención a la [configuración del idioma del documento]. Si bien TabliSync admite varios idiomas, la selección del idioma principal de los documentos aumenta significativamente la precisión, especialmente para variaciones sutiles de caracteres o símbolos de moneda. Además, para documentos escaneados, asegúrese de que tengan una resolución de al menos [300 DPI] para obtener resultados confiables; los escaneos de muy baja resolución son la principal causa de errores de OCR.
Paso 2: Análisis inteligente de diseño y análisis de tablas
Con los documentos ingeridos, el motor de IA principal de TabliSync toma el control. Este paso no se trata de leer texto; se trata de comprender la [jerarquía visual y las relaciones estructurales] dentro de cada página. Aquí es donde el análisis de tablas financieras se vuelve crucial. Nuestro motor no solo busca palabras clave; analiza el espacio en blanco, la alineación y las pistas de formato para identificar [tablas, elementos de línea, encabezados y pares clave-valor] (como 'Fecha de factura' y su fecha correspondiente).
Este es un proceso sin plantillas. La IA de TabliSync ha sido entrenada con millones de documentos diversos, por lo que reconoce automáticamente que una tabla de elementos de línea en una factura de proveedor es una sola entidad, incluso si abarca varias páginas y no tiene líneas de borde claras. Para el análisis de tablas financieras, separa inteligentemente la [cantidad, precio unitario, descripción y total de línea] en columnas discretas y precisas. Puede supervisar este progreso a través del panel de TabliSync, que le muestra exactamente qué documentos se están analizando y marca aquellos en los que el diseño es ambiguo para la revisión humana.
Para garantizar resultados de nivel profesional para la conciliación de su [Libro Mayor], utilice las reglas de validación de TabliSync. Puede configurar reglas que verifiquen si los totales de los elementos de línea individuales suman el subtotal de la factura, o si el monto del impuesto se calcula correctamente según una tasa especificada. Esto va más allá de la simple extracción y agrega una capa de [validación de lógica de negocio], asegurando que los datos que llegan a su archivo de Excel no solo sean precisos sino también lógicamente consistentes, acelerando significativamente sus procesos de Conciliación posteriores.
Paso 3: Validación de datos, manejo de excepciones y exportación a Excel
El paso final es refinar los datos extraídos, manejar cualquier excepción y exportar la información estructurada y finalizada a Excel. Después de que la IA completa su análisis, TabliSync presenta una [Interfaz de Verificación]. Aquí, los documentos se marcan para revisión humana solo si la puntuación de confianza de la IA para los campos clave cae por debajo de su umbral predefinido. Por ejemplo, si una nota manuscrita particularmente desordenada oscurece un 'Monto Total', el sistema marcará ese documento específico.
En la pantalla de verificación, puede ver la imagen original del documento junto con los datos extraídos. Su equipo puede [corregir rápidamente cualquier error], añadiendo inteligencia humana donde la IA tuvo dificultades. Para un lote típico, esta revisión es increíblemente rápida porque solo está viendo las excepciones marcadas, no los 10.000 documentos completos. Para el procesamiento de documentos en lote, este enfoque de bucle humano es fundamental para mantener una integridad de datos cercana al 100%. La interfaz está optimizada para la velocidad, lo que permite a los verificadores navegar por los campos y utilizar atajos de teclado para correcciones rápidas. Una vez que todos los documentos se verifican, simplemente haga clic en [Exportar a Excel].
TabliSync no solo le da un volcado de texto sin procesar; proporciona un libro de Excel bellamente estructurado y de varias hojas. Una hoja puede contener los [datos a nivel de encabezado] (Número de factura, Fecha, Nombre del proveedor), mientras que otra hoja puede contener todos los [elementos de línea detallados] (SKU del producto, Descripción, Cantidad, Precio), con un identificador único que los vincula. Esta estructura relacional es invaluable para el análisis complejo y la integración ERP. Además, puede configurar la exportación para utilizar [tipos de datos de Excel] específicos (por ejemplo, formatear fechas como fechas y moneda como números), asegurando que los datos estén listos para su uso inmediato en tablas dinámicas o modelado financiero, sin requerir ninguna limpieza manual.
El Impacto Estratégico: Por qué el OCR por Lotes a Excel es una Competencia Central, No un Complemento
Durante demasiado tiempo, las empresas han tratado el procesamiento de documentos como una tarea administrativa de back-office, un centro de costos necesario. Este es un profundo error estratégico. En la era digital, su capacidad para la extracción automatizada de datos de los documentos no estructurados que impulsan su negocio es un [determinante directo] de su velocidad operativa, agilidad financiera y, en última instancia, de su ventaja competitiva. Dominar el OCR por Lotes a Excel no se trata solo de ahorrar tiempo; se trata de desbloquear el valor latente dentro de los datos de su organización.
Considere el valor estratégico de tener [datos financieros casi en tiempo real]. Cuando puede procesar 10.000 facturas en horas en lugar de semanas, su equipo de cuentas por pagar ya no reacciona a eventos pasados. Están [gestionando activamente el flujo de caja], optimizando el capital de trabajo y aprovechando los descuentos por pronto pago. Su equipo de adquisiciones puede analizar datos de partidas individuales en miles de compras para identificar patrones de gasto y negociar mejores condiciones con los proveedores. Sus equipos de cumplimiento y auditoría tienen un [rastro de auditoría instantáneo y verificable] para cada transacción, lo que reduce drásticamente el costo y el riesgo asociados con las auditorías. Este nivel de capacidad de respuesta solo es posible con una solución de procesamiento masivo robusta y de alta precisión.
Además, esta agilidad de datos es la base para iniciativas avanzadas de análisis e IA. Un [Libro Mayor] que se actualiza en tiempo real con datos detallados y precisos de partidas individuales se convierte en una herramienta poderosa para la previsión y la planificación estratégica. Puede alimentar estos datos estructurados en modelos de aprendizaje automático para predecir la demanda, optimizar los niveles de inventario o detectar transacciones fraudulentas. Los datos no estructurados ocultos en sus documentos son el combustible para su transformación digital, y Batch OCR to Excel es la refinería que los hace utilizables. Ignorar esto es similar a tener un campo petrolero y negarse a construir un oleoducto.
Preguntas frecuentes detalladas: Abordando la complejidad de OCR a Excel a gran escala
Pasar de un proceso manual a una solución compleja y automatizada de Batch OCR to Excel inevitablemente plantea preguntas técnicas y operativas. Esta sección de preguntas frecuentes se basa en una profunda experiencia en la implementación de cientos de proyectos de automatización de documentos a gran escala. Abordamos no solo el 'cómo', sino el 'por qué' y los 'qué pasaría si', proporcionando la comprensión matizada que necesita para una implementación exitosa y profesional.
¿Cuál es la diferencia entre detección de tablas y extracción de tablas?
Esta es una distinción crítica que a menudo se pasa por alto. La [detección] de tablas simplemente identifica que existe una tabla en una página y dibuja un recuadro a su alrededor. Muchas herramientas de OCR genéricas se detienen aquí. La [extracción] de tablas, sin embargo, es la tarea mucho más compleja de comprender la estructura interna de esa tabla. Implica identificar con precisión filas, columnas, encabezados y los datos precisos dentro de cada celda, incluso si la tabla no tiene bordes o tiene celdas complejas y fusionadas. Para el análisis de tablas financieras, la extracción confiable es innegociable. TabliSync utiliza un análisis avanzado de diseño para no solo detectar la tabla, sino para recrear su estructura y datos con alta fidelidad en Excel.
¿Puede TabliSync Manejar Documentos Escaneados, de Baja Calidad o Torcidos?
Sí, pero con advertencias. El motor de TabliSync es muy robusto e incluye capacidades automáticas de [preprocesamiento] de imágenes. Puede enderezar documentos, reducir el ruido y agudizar el texto para mejorar el reconocimiento. Nuestro OCR de alta precisión es particularmente efectivo con diseños complejos y calidad de impresión variada. Sin embargo, la regla cardinal del OCR aún se aplica: [basura entra, basura sale]. Los documentos con desenfoque extremo, escritura a mano significativa sobre texto crítico o una resolución inferior a [300 DPI] siempre tendrán una menor precisión de extracción. Para estos casos, TabliSync marca el documento para verificación humana para garantizar que no lleguen datos incorrectos a su informe final de Excel.
¿Cumple TabliSync con GDPR y CCPA?
La privacidad de los datos es primordial, especialmente cuando se trata de documentos financieros o personales. TabliSync está construido con seguridad y cumplimiento de nivel empresarial en su núcleo. Cumplimos totalmente con GDPR, CCPA y otras regulaciones importantes de privacidad de datos. Todos los datos están [cifrados] tanto en reposo como en tránsito. Además, ofrecemos funciones como [redacción] automática de PII y políticas de retención de datos configurables, lo que garantiza que tenga control total sobre cómo se procesa y almacena la información confidencial. Cuando participa en el procesamiento de documentos masivos con TabliSync, lo hace en una plataforma que prioriza la seguridad y el cumplimiento normativo.
¿Cómo Puedo Integrar TabliSync con mi Sistema ERP o de Contabilidad Existente?
La integración perfecta es fundamental para la automatización real. Si bien la exportación a Excel es potente, la integración directa suele ser el objetivo final. TabliSync proporciona una [API robusta y bien documentada] que le permite automatizar todo el proceso. Puede utilizar la API para enviar documentos a TabliSync, supervisar su estado y extraer los datos estructurados y verificados directamente en su sistema ERP o de contabilidad, como NetSuite, Salesforce o QuickBooks. También admitimos [Webhooks], para que sus otros sistemas puedan ser notificados instantáneamente cuando se completa un lote de procesamiento, activando acciones automatizadas adicionales en su flujo de trabajo.
¿Qué sucede si la IA no extrae correctamente un punto de datos crítico?
Aquí es donde el paso de validación "humano en el bucle" es crucial. TabliSync no adivina; proporciona una puntuación de confianza para cada punto de datos extraído. Si la puntuación de confianza para un campo crítico (por ejemplo, 'Importe total') cae por debajo de un umbral que usted define, el documento se marca automáticamente y se presenta en la [Interfaz de Verificación]. Su equipo puede entonces revisar y corregir rápidamente ese punto específico. Esto garantiza que solo se exporten datos 100% verificados y precisos a su archivo Excel final, manteniendo la alta integridad de los datos requerida para la Reconciliación profesional y la presentación de informes financieros.
¿Puede TabliSync procesar documentos de varias páginas donde una tabla se extiende a través de páginas?
Sí, esta es una fortaleza principal de nuestro motor de análisis de tablas financieras. TabliSync puede rastrear inteligentemente tablas a través de varias páginas. Reconoce los encabezados de la tabla en la primera página y entiende que las páginas subsiguientes son una continuación de la misma tabla, incluso si los encabezados no se repiten. Consolida todos los datos en [una tabla única y continua] en su salida de Excel, preservando la estructura relacional de los datos y ahorrándole horas de trabajo manual de consolidación que de otro modo serían necesarias.
¿Qué tipos de 'excepciones' debe manejar un humano?
Las excepciones no se tratan solo de baja confianza de OCR. También pueden involucrar [validación de lógica de negocio]. Por ejemplo, TabliSync puede verificar si la suma calculada de los elementos de línea extraídos es igual al total de la factura extraída. Si no lo es, ese documento se convierte en una excepción. Esto podría deberse a un error de extracción genuino, o podría ser un error de cálculo en la propia factura del proveedor. Los revisores humanos reciben el contexto para resolver rápidamente el problema, ya sea corrigiendo la extracción o marcando el documento para que el equipo de finanzas lo aborde con el proveedor.
¿Hay un límite en la cantidad de documentos que puedo procesar en un lote?
Si bien existen límites prácticos para un solo lote para mantener un rendimiento manejable, TabliSync está diseñado para una escala masiva. Para [conjuntos de datos muy grandes], recomendamos dividir el procesamiento en lotes lógicos (por ejemplo, por proveedor o por mes). Nuestros niveles empresariales están diseñados para escalar a [cientos de miles o incluso millones] de documentos por año. Para requisitos excepcionalmente grandes y de alto volumen, podemos configurar recursos de procesamiento dedicados para garantizar que sus flujos de trabajo de [extracción automatizada de datos] cumplan con sus precisos SLA de velocidad y volumen.
Desbloquee una agilidad y eficiencia de datos sin precedentes hoy mismo
Ahora ha explorado el panorama integral de OCR por lotes a Excel, desde los puntos débiles arraigados del procesamiento manual hasta la ejecución precisa paso a paso en una plataforma como TabliSync. La capacidad de convertir automática y con precisión montañas de documentos no estructurados y multiformato en datos estructurados y accionables ya no es una ganancia de eficiencia periférica; es un imperativo comercial central para cualquier organización que aspire a la excelencia operativa y la agilidad estratégica en un mundo impulsado por los datos. Los costos de la inacción (altos costos laborales, errores de datos generalizados, tiempos de ciclo lentos y una falta total de escalabilidad) son simplemente demasiado altos para ignorarlos.
Cada minuto que su equipo dedica a la entrada manual de datos es un minuto [robado] al análisis de alto valor, la conciliación de proveedores y la planificación financiera estratégica. El panorama competitivo no esperará a que modernice su procesamiento de documentos. Las organizaciones que adoptan la extracción automatizada de datos ahora están construyendo una base de agilidad operativa que generará dividendos durante años. No permita que sus datos comerciales críticos permanezcan atrapados en papel o en archivos digitales fragmentados. Tome el control de su canal de datos e impulse su organización. Confiamos tanto en la capacidad de TabliSync para transformar sus flujos de trabajo que lo invitamos a experimentarlo de primera mano. Deje de permitir que los cuellos de botella manuales lo detengan. Regístrese para su prueba gratuita de TabliSync hoy y sea testigo del inmediato, poder transformador de la OCR de alta precisión. El futuro de la agilidad de sus datos comienza ahora, no se demore.
¿Qué es Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos?
Respuestas rápidas sobre Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos y cómo TabliSync ayuda a los equipos a trabajar más rápido en Excel.
¿Qué es Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos?
Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos cubre flujos prácticos de Excel, errores comunes y patrones de automatización. Esta guía de TabliSync explica el concepto, muestra ejemplos y enlaza tutoriales relacionados.
¿Cómo puede TabliSync ayudar con Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos?
TabliSync puede extraer tablas de capturas o PDF, limpiar datos desordenados y automatizar tareas repetitivas de Excel relacionadas con Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos.
¿Por dónde empiezo con Cómo Usar OCR por Lotes a Excel para Grandes Conjuntos de Datos?
Empieza con la visión general de esta página y luego abre los artículos relacionados para guías paso a paso, plantillas y flujos con IA.
Todos los Artículos de OCR por Lotes a Excel(11)

Cómo Duplicar una Hoja en Excel: Guía Paso a Paso
Esta guía proporciona instrucciones paso a paso sobre cómo duplicar una hoja en Excel, ayudando a los usuarios a administrar sus hojas de cálculo de manera eficiente y precisa. Ya sea que esté trabajando con informes financieros, hojas de inventario o cualquier otro dato, duplicar hojas puede ahorrar tiempo y garantizar la coherencia. Siga nuestras instrucciones claras para dominar esta habilidad esencial de Excel. Al final de esta guía, podrá duplicar hojas con confianza y mantener su trabajo organizado. ¡No olvide explorar cómo TabliSync puede mejorar aún más sus tareas de administración de hojas de cálculo después de haber aprendido esta habilidad!

Solución de problemas de fórmulas bloqueadas en Excel
Esta guía de solución de problemas proporciona a los usuarios soluciones prácticas para desbloquear fórmulas en Excel, abordando problemas comunes y ofreciendo consejos para prevenir problemas futuros. Las fórmulas bloqueadas pueden ser un obstáculo importante para los usuarios empresariales, especialmente aquellos en finanzas y administración que dependen de la manipulación precisa de datos. A través de un enfoque paso a paso, este artículo ayuda a los lectores a comprender las causas de las fórmulas bloqueadas y ofrece estrategias efectivas para resolver estos problemas. Al implementar las soluciones descritas aquí, los usuarios pueden recuperar el control de sus hojas de cálculo, asegurando que puedan editar y administrar sus datos de manera efectiva sin frustraciones innecesarias. El artículo también enfatiza las mejores prácticas para prevenir tales problemas en el futuro, contribuyendo a flujos de trabajo de hojas de cálculo más fluidos y eficientes y permitiendo a los usuarios centrarse completamente en el manejo preciso de los datos.

Cómo Agregar un Menú Desplegable a Excel
La entrada manual repetitiva de datos a menudo causa inconsistencias y baja eficiencia de trabajo para el personal de negocios que utiliza Excel. Este artículo explica las dificultades en la creación de menús desplegables en Excel, e introduce dos soluciones que incluyen la configuración manual y métodos automatizados de extracción de datos. También cubre pasos detallados de operación, verificaciones clave previas a la exportación, errores comunes de configuración y preguntas frecuentes. La creación de menús desplegables estandarizados unifica eficazmente los estándares de entrada de datos, reduce los errores manuales y optimiza los flujos de trabajo de procesamiento de datos de oficina diarios y los informes financieros.

Cómo Agregar Viñetas en Excel
"Esta guía proporciona instrucciones paso a paso para agregar viñetas en Excel usando atajos de teclado y el menú de la Cinta de opciones, junto con ejemplos prácticos de su uso en documentos profesionales y consejos para un formato eficaz que mejore la legibilidad general."

Cómo usar atajos de teclado para pegar valores y limpiar datos complejos de hojas de cálculo
Reduzca el tiempo de limpieza de datos hasta en un 80% utilizando atajos de teclado directos para pegar valores en lugar de eliminar el formato manualmente. Elimine errores de formato ocultos, fórmulas rotas y tipos de datos inconsistentes de conjuntos de datos importados o heredados. Mantenga un flujo de datos limpio y reproducible sin macros ni VBA, solo con pulsaciones de teclas nativas de Excel. Conecte flujos de trabajo de datos estructurados y no estructurados combinando pegar valores con herramientas de extracción como TabliSync.

Cómo hacer puntos de viñeta en Excel para tablas de datos limpias
Esta guía cubre dos métodos eficientes para agregar y limpiar puntos de viñeta en Excel para tablas de datos estructuradas y analizables. Explica los flujos de trabajo integrados de Excel, incluidos los atajos de teclado, las funciones CHAR, Power Query y las tablas de Excel para tareas de formato sencillas y únicas. También presenta la solución TabliSync, impulsada por IA, para extraer, estandarizar y organizar automáticamente listas de viñetas desordenadas de PDF, capturas de pantalla e informes externos en filas limpias de Excel, resolviendo problemas comunes de limpieza de datos y optimizando los flujos de trabajo de datos comerciales recurrentes para la creación de filtros, análisis y paneles.

IA: Cómo separar nombres y apellidos en Excel
Elimine los errores de división manual de nombres utilizando el análisis impulsado por IA, lo que reduce el tiempo de limpieza de datos hasta en un 85%. Automatice la extracción de nombres y apellidos de informes basados en imágenes y PDF, ahorrando más de 10 horas por semana por analista. Mantenga un formato de nombres consistente en los conjuntos de datos con sincronización en tiempo real, lo que reduce los fallos de conciliación posteriores en un 90%.

Cómo bloquear celdas en Excel: Protección de datos específicos contra cambios
Implemente la protección granular de celdas para garantizar un 0 % de errores de anulación manual de fórmulas. Domine el flujo de trabajo de bloqueo y protección de dos pasos para ahorrar el 90 % del tiempo dedicado a la auditoría de hojas de cálculo. Aproveche la sincronización de OCR impulsada por IA para transformar datos no estructurados en activos comerciales bloqueados e inmutables.

Cómo Eliminar Duplicados y Originales en Excel: Una Guía Paso a Paso
Elimine el 100% del Ruido: Domine la técnica para eliminar no solo duplicados, sino también las entradas originales, dejando solo datos verdaderamente únicos. Ahorro de Tiempo del 90%: Transición de la auditoría manual fila por fila a flujos de trabajo de automatización de limpieza de datos automatizada. 0% de Error en la Entrada Manual: Aproveche el OCR de IA para analizar datos no estructurados en esquemas limpios sin intervención humana. Higiene de Datos Escalable: Implemente estrategias de alto nivel para valores únicos en Excel que manejen conjuntos de datos de más de 100 mil filas sin esfuerzo.

Error de libro de Excel: Lo sentimos, no pudimos encontrar la guía de solución
* Solucione errores de inicio de Excel al instante identificando rutas temporales locales ocultas. * Reduzca el tiempo de resolución manual de problemas en un 90% utilizando la validación automatizada de rutas. * Logre un 0% de errores de entrada manual migrando datos no estructurados a través de OCR con IA. * Transforme enlaces de archivos rotos en activos de datos resilientes sincronizados en la nube.

Cómo desbloquear hoja de Excel sin conocer la contraseña
Descifre hojas de Excel sin contraseñas con un 99,9 % de integridad de datos; Reduzca el tiempo de recuperación manual en un 90 %; Ejecución impecable de macros XML y VBA; OCR impulsado por IA para la extracción de datos estructurados.
Stop Manual Data Entry – Extract Tables in Seconds
Convert any image or PDF table to Excel instantly with 99.9% accuracy. TabliSync's AI-powered OCR handles handwritten forms, receipts, and complex tables – then syncs directly to Google Sheets, Notion, or Airtable
Try TabliSync Free Now