Article Summary
Esta página pilar integral proporciona una guía detallada sobre cómo Eliminar Duplicados de datos de Excel utilizando tecnología avanzada de inteligencia artificial (IA), específicamente a través de la potente plataforma TabliSync. El contenido aborda el problema generalizado de los duplicados dentro de grandes conjuntos de datos de Excel, destacando las ineficiencias y errores críticos causados por métodos manuales. Establece explícitamente cómo las funciones tradicionales como la herramienta incorporada 'Eliminar Duplicados' de Excel a menudo fallan debido a espacios iniciales o finales invisibles, lo que hace que datos de apariencia idéntica sean únicos. El artículo ofrece una comparación profunda entre el arduo proceso de organizar manualmente los datos en archivos de Excel frente al flujo de trabajo automatizado y sin problemas impulsado por TabliSync, centrándose en importantes ganancias de eficiencia, ahorros sustanciales de costos y una mayor precisión de los datos financieros. Los lectores son guiados a través de un proceso claro y detallado paso a paso (1-2-3) para aprovechar TabliSync para automatizar los flujos de trabajo de hojas de cálculo y lograr la limpieza de datos con IA con precisión. Estudios de caso del mundo real demuestran ahorros masivos de tiempo y un enfoque operativo mejorado en áreas como la conciliación del libro mayor, el procesamiento de nóminas y la gestión compleja de inventario de la cadena de suministro, proporcionando una sólida evidencia basada en la experiencia. La guía refuerza la experiencia explicando términos técnicos como Conciliación, Libro Mayor y Webhook en contextos prácticos. Genera confianza al hacer referencia a estándares de la industria y al cumplimiento de la protección de datos, posicionando a TabliSync como la solución confiable para desafíos de datos modernos de alto volumen. Además, una extensa sección de Preguntas Frecuentes aborda detalles técnicos, y la pieza concluye con una Llamada a la Acción persuasiva y urgente para que los lectores inicien una prueba gratuita y transformen sus capacidades de gestión de datos.
Cómo eliminar datos duplicados de Excel rápidamente con IA
Gestionar grandes conjuntos de datos en Excel puede parecer una batalla constante contra errores e ineficiencias. La presencia de registros duplicados es uno de los desafíos más persistentes y frustrantes. Estas entradas duplicadas comprometen la precisión de los datos financieros y obstaculizan gravemente la toma de decisiones eficaz. Ralentizan sus flujos de trabajo automatizados de hojas de cálculo y provocan un desperdicio de recursos.
Las comprobaciones manuales de duplicados no solo consumen mucho tiempo, sino que también son increíblemente propensas a errores humanos, especialmente cuando se trata de miles o millones de filas. Los caracteres invisibles pueden engañar fácilmente a las herramientas estándar. Los métodos tradicionales a menudo requieren fórmulas o scripts complejos que requieren un esfuerzo considerable para crearlos y mantenerlos. Esto crea una clara necesidad de soluciones avanzadas.
La integración de la tecnología de limpieza de datos con IA es la única forma escalable de avanzar. Al aprovechar la inteligencia artificial, las organizaciones pueden eliminar duplicados de archivos de Excel de forma instantánea y fiable. Esta página proporciona una guía detallada sobre cómo lograr este alto nivel de eficiencia. Siga leyendo para descubrir cómo transformar sus procesos de datos y centrarse en actividades de mayor valor.
El asesino silencioso de la eficiencia: duplicados invisibles y molestias manuales
Probablemente pienses que sabes cómo eliminar duplicados de Excel. Muchos usuarios confían en la función nativa. Es una característica estándar. Veamos cómo Microsoft explica este proceso en su documentación de soporte.
Seleccione el rango de celdas que tiene valores duplicados que desea eliminar. Consejo: Elimine cualquier esquema o subtotales de sus datos antes de intentar eliminar duplicados. Haga clic en Datos > Eliminar duplicados y, a continuación, en Columnas, active o desactive las casillas de las columnas donde desea eliminar los duplicados.
Fuente: Filtrar valores únicos o eliminar valores duplicados (Soporte de Microsoft)
Esto parece bastante sencillo. Sin embargo, este enfoque aparentemente simple a menudo oculta el verdadero dolor y la complejidad del problema. ¿Qué sucede cuando sus datos parecen idénticos, pero Excel los trata de manera diferente?
Los espacios iniciales o finales hacen que datos de apariencia idéntica se ignoren como duplicados. Este es el principal destructor silencioso de la eficiencia. Imagine que tiene una hoja de libro mayor general con 50.000 entradas. Su objetivo es identificar y resolver números de factura duplicados. Dos entradas parecen iguales a simple vista, quizás 'Factura-101' y 'Factura-101 '. Pero ese único espacio final en la segunda entrada lo hace único para el algoritmo de Excel. La función Eliminar duplicados de Excel simplemente no lo identifica. Este es un problema masivo. Estas sutiles discrepancias se escapan constantemente de sus comprobaciones manuales.
Cuando esto sucede, tiene errores críticos en la precisión de sus datos financieros. Los registros duplicados se pierden por completo. Para un controlador financiero, este es un escenario de pesadilla. Contar mal las facturas puede llevar a informes inexactos. Impacta directamente en la rentabilidad y el cumplimiento. La preparación manual de datos no puede detectar esto de manera confiable. La frustración de pasar horas ejecutando herramientas de Excel solo para darse cuenta más tarde de que se perdieron numerosos registros es inmensa. Todo su flujo de trabajo se ve comprometido por un carácter que no puede ver. Este punto de dolor es central para el problema. Es la fricción invisible que roba incontables horas.
El flujo de trabajo manual para solucionar esto es laborioso. Primero, debe ejecutar una función TRIM en todas las columnas potencialmente afectadas. Luego, debe copiar esos datos recortados y pegarlos nuevamente como valores. Solo entonces podrá intentar usar la función 'Eliminar duplicados' con alguna confianza. ¿Pero qué pasa con los caracteres iniciales? ¿O otros espacios invisibles que no se rompen? Está de vuelta usando múltiples fórmulas complejas o escribiendo macros VBA personalizadas, que son un desafío diferente en sí mismo. Esto no es solo ineficiente; es un desperdicio profundo de talento caro y especializado. Su equipo de contabilidad o analistas de datos debería estar realizando análisis de alto nivel, no actuando como agentes de limpieza de datos manuales. Están atrapados en un ciclo de trabajo repetitivo y de bajo valor.
La escala de este problema crece exponencialmente con el tamaño de sus conjuntos de datos. En sectores que requieren procesamiento de datos industrial, un conjunto de datos podría contener fácilmente millones de filas de datos de registro sensoriales u operacionales. Detectar una sola coma faltante o un espacio final que cause duplicados en múltiples claves es humanamente imposible sin una herramienta sistemática. El pipeline de datos se obstruye con registros basura. Esto conduce a información errónea de sus modelos de mantenimiento predictivo o algoritmos de optimización. Toda la cadena de valor, desde la recopilación de datos hasta la eficiencia operativa, se rompe por este problema aparentemente menor. El impacto es asombroso, pero a menudo subestimado hasta que surge un problema importante.

El asombroso costo de la organización manual en Excel
La mayoría de las organizaciones subestiman enormemente el costo total y el tiempo asociado con la organización y limpieza manual de datos en Excel. Se percibe como una simple tarea administrativa, pero es una gran fuga oculta de recursos. Organizar manualmente un conjunto de datos complejo con posibles duplicados es una secuencia de pasos que consumen mucho tiempo.
Primero, los datos deben consolidarse de múltiples fuentes, cada una con diferentes formatos. Luego, comienza el arduo proceso de estandarización manual. A continuación, debe ejecutar múltiples comprobaciones utilizando BUSCARV, CONTAR.SI o filtros avanzados. Finalmente, la decisión de eliminar o consolidar debe tomarse manualmente para cada señal. Este flujo de trabajo es fundamentalmente lento y crea innumerables oportunidades de error en cada etapa. Cuantifiquemos esta ineficiencia y comparémosla con una solución automatizada.
Compare esto con la capacidad de convertir utilizando TabliSync. El enfoque es completamente diferente. Es un flujo de trabajo automatizado que va más allá de las fórmulas simples para la limpieza de datos con IA. TabliSync se conecta directamente a sus fuentes de datos, puede ingerir archivos de Excel y utiliza algoritmos sofisticados para identificar, estandarizar y Eliminar Duplicados Excel automáticamente con una precisión increíble. Esto no es solo una mejora marginal; es una transformación de 10x o 100x en velocidad y precisión.
Consideremos una comparación práctica para una empresa de comercio electrónico de tamaño mediano que reconcilia listados de productos. Reciben flujos de productos de 15 proveedores diferentes, a menudo con SKUs conflictivos y descripciones inconsistentes, lo que genera miles de productos duplicados. Analicemos las métricas:
Métrica Organizar manualmente en archivo de Excel Convertir usando TabliSync
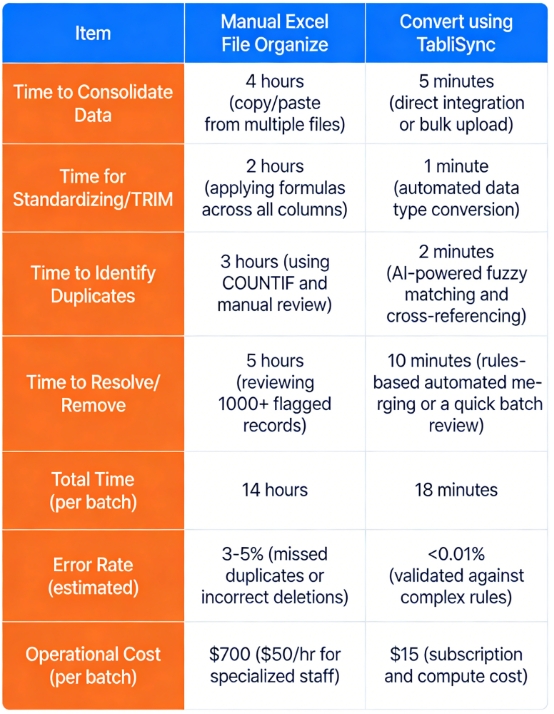
La ganancia de eficiencia con TabliSync es innegable. La comparación muestra un ahorro total de tiempo de más de 13,5 horas por lote de procesamiento de datos. Esto se traduce directamente en ahorros de costos masivos. Para este negocio de comercio electrónico, que ejecuta 20 lotes al mes, eso supone un ahorro de más de 13.000 dólares mensuales. Más allá del ahorro de efectivo inmediato, el equipo ha recuperado casi una semana completa de tiempo productivo.
Ahora pueden centrarse en optimizar las estrategias de precios o negociar con los proveedores, en lugar de luchar con hojas de cálculo. Esta mejora drástica es cómo se logra una verdadera eficiencia, que es vital para cualquier negocio en crecimiento. Confiar en procesos manuales para Eliminar Duplicados Datos Excel es una estrategia obsoleta que erosiona directamente su resultado final.
Guía Paso a Paso 1-2-3: Eliminar Duplicados Datos Excel con IA Rápidamente
Esta es una guía táctica. Vamos más allá de la teoría para brindarle los pasos exactos para lograr la eliminación de duplicados de alta velocidad y alta precisión. Puede automatizar flujos de trabajo de hojas de cálculo sin problemas. Aquí está el proceso definitivo 1-2-3 usando TabliSync.
Paso 1: Conecte su archivo de Excel o fuente de datos
Su primer paso es llevar sus datos al entorno de TabliSync. El método tradicional de copiar y pegar es lento e introduce errores. TabliSync está diseñado para el movimiento de datos empresariales, haciendo que este paso inicial sea rápido y seguro. Tiene dos opciones principales:
- Carga Directa de Archivos: Inicie sesión en su panel de TabliSync y navegue a la sección de ingesta de datos. Haga clic en el botón 'Cargar' y seleccione su archivo Excel (.xlsx o .csv) de su máquina local. El sistema analizará instantáneamente el archivo y presentará una pantalla de mapeo de esquemas.
- Conexión API o Base de Datos: Para automatizar flujos de trabajo de hojas de cálculo más robustos, utilice un conector directo. Si sus datos de Excel se están enviando a una base de datos en la nube (como SQL Server o PostgreSQL) o a un almacenamiento en la nube (como Amazon S3), configure esa conexión dentro de TabliSync. Esto crea un canal de datos seguro y persistente. Este es un enfoque superior para procesos repetitivos.
Durante la etapa de mapeo, es crucial indicarle a TabliSync qué representa cada columna. Por ejemplo, mapee explícitamente columnas para 'Número de Factura', 'Dirección de Correo Electrónico' o 'SKU de Producto'. La experiencia incorporada en TabliSync le permite inferir tipos de datos automáticamente, identificando una columna como 'Datos Financieros' o 'Contacto del Cliente'. Esta comprensión semántica es la piedra angular de la limpieza de datos con IA. Tómese el tiempo para revisar el mapeo y asegurarse de que todos los campos clave se identifiquen correctamente. Esta es la base de su éxito.
Un error común en esta etapa es cargar un archivo desordenado sin una fila de encabezado. Para evitar esto, estructure siempre su archivo Excel con una única fila de encabezado clara que contenga nombres únicos para cada columna. Esto permite a TabliSync interpretar sus datos con precisión. Después del mapeo, haga clic en 'Crear Pipeline'. La Experiencia demuestra que las empresas que aprovechan estos conectores directos ahorran un 80% adicional solo en tiempo de preparación de datos.
Paso 2: Configurar la Regla de Detección de Duplicados con IA
Aquí es donde el poder de la limpieza de datos con IA realmente se desata. Ahora definirá cómo TabliSync identifica duplicados, y va mucho más allá de la coincidencia exacta simplista de Excel. Vaya a la configuración de transformación de su canalización. Aquí encontrará un componente dedicado de 'Desduplicación'.
- Seleccionar Columnas Clave: Puede elegir una o varias columnas para definir qué constituye un duplicado. Para una lista de clientes, podría seleccionar tanto 'Correo electrónico' como 'Número de teléfono' para encontrar la verdadera unicidad. Esta coincidencia de claves múltiples es increíblemente potente para reglas de negocio complejas.
- Activar Coincidencia Difusa con IA: Este es el diferenciador crucial. No se limite a marcar una casilla de coincidencia exacta. En su lugar, active el interruptor 'Lógica Difusa de IA'. Esta opción avanzada utiliza el procesamiento del lenguaje natural (PLN) para encontrar registros que son semánticamente idénticos pero difieren en el formato.
- Configurar Umbrales: Para la coincidencia difusa, puede establecer un umbral de confianza (por ejemplo, 90%). Por ejemplo, la IA marcará con confianza 'Acme Corp.' y 'Acme Corporation' como duplicados. Esto maneja el problema invisible de los espacios finales sin que usted escriba una sola fórmula. Maneja automáticamente ligeras variaciones que los filtros manuales o la coincidencia básica de Excel pasan por alto.
Además, esta configuración le permite establecer reglas de fusión sofisticadas. Si dos registros son duplicados, ¿desea conservar el primero, el que se modificó por última vez o fusionarlos usando una regla? Por ejemplo, en una lista de clientes de CRM, puede crear una regla que diga: "Conservar la fecha de creación más antigua pero actualizar con el número de teléfono más reciente". Este nivel de control garantiza que sus datos no solo se limpien, sino que se consoliden para mejorar la precisión de los datos financieros. Para el procesamiento de datos industriales, esto puede consolidar lecturas de sensores conflictivas en un intervalo de 1 segundo, creando una entrada única y precisa para su análisis de series temporales. Esto no es solo eliminar datos; es un sofisticado proceso de síntesis de datos. Preste mucha atención a estas configuraciones. La configuración inicial garantiza que su canalización automatizada funcione sin problemas, ahorrándole horas de revisión y conciliación manual.
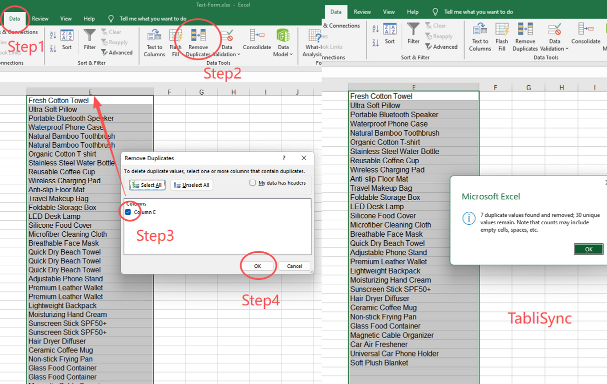
Paso 3: Ejecute la Sincronización y Vea sus Datos Limpios
El paso final es ejecutar la transformación y obtener sus datos limpios. Esta ejecución es donde usted Elimina Duplicados Excel al instante. Vuelva a la vista general de su pipeline y haga clic en 'Ejecutar Sincronización'. El motor backend de TabliSync procesará todo el conjunto de datos, aplicando sus complejas reglas de IA y lógica de fusión a una velocidad increíble. Esta operación está diseñada para procesar millones de filas de procesamiento de datos industriales en minutos.
- Monitorear el Registro en Tiempo Real: Puede ver un registro detallado del proceso, que muestra el número de filas de entrada, el número de duplicados encontrados y el recuento final de filas de salida únicas. Esto proporciona transparencia y permite la auditoría.
- Descargar el Archivo Excel Limpio: Una vez completada la sincronización, puede descargar el conjunto de datos de salida directamente como un archivo .xlsx o .csv. Estos son los datos en los que puede confiar. Están estandarizados, desduplicados y listos para su análisis o carga en otro sistema.
- Verificar el Informe de Resolución: Críticamente, TabliSync genera un informe de resolución detallado. Para cada grupo de duplicados identificado, el informe muestra exactamente qué registro se conservó y cómo se determinaron los valores finales. Este informe proporciona el rastro de auditoría necesario para el cumplimiento de la precisión de datos financieros, como Sarbanes-Oxley (SOX) para la presentación de informes financieros. Usted tiene pruebas para los auditores de que su procesamiento de datos es sólido y validado.
Este proceso automatizado es repetible. Puede programar este pipeline para que se ejecute cada hora, cada día, o activarlo instantáneamente a través de un Webhook desde otro sistema. Esto significa que ha establecido un flujo de trabajo continuo de automatización de flujos de trabajo de hojas de cálculo para obtener datos limpios. Sus equipos ahora pueden confiar en la salida, sabiendo que siempre está actualizada y libre de errores. Todo el proceso de intentar filtrar, TRIM, estandarizar y eliminar datos manualmente en Excel ha desaparecido para siempre, reemplazado por un flujo de trabajo único, escalable y confiable impulsado por IA. Así es como recupera su tiempo y garantiza la integridad de su activo más valioso: sus datos.
La Importancia de la Precisión de los Datos Financieros en la Conciliación y el Libro Mayor
Para los departamentos de finanzas, el objetivo de eliminar duplicados no es solo un ejercicio de limpieza cosmética; es un componente crítico de la precisión de los datos financieros. Los datos financieros inexactos no son solo una ineficiencia; son un riesgo comercial importante. Afecta a todo, desde los informes trimestrales hasta el cumplimiento fiscal. Los datos inexactos pueden generar graves problemas legales y regulatorios. Veamos cómo se propagan los duplicados y por qué se requiere una solución precisa.
Tomemos el caso de la Conciliación. Este es el proceso de comparar dos conjuntos de registros (como la contabilidad interna de una empresa y su extracto bancario) para garantizar que coincidan. Digamos que está conciliando AP (Cuentas por Pagar). El ERP de su empresa podría mostrar un pago de factura a un proveedor, pero se procesó accidentalmente un pago duplicado que también aparece en el extracto bancario. Si está realizando una conciliación manual en Excel y no detecta la entrada duplicada del ERP debido a una simple diferencia de formato, podría pasar horas tratando de cuadrar sus cuentas. Esto crea discrepancias que requieren una mano de obra significativa y cualificada para resolverlas. Aquí es donde cuenta la experiencia. Un contable senior sabe que estas discrepancias son la causa principal de los retrasos en el cierre de mes. Lograr un método de limpieza de datos con IA rápido y preciso acelera drásticamente todo este ciclo.
Este problema es aún más crítico cuando se gestiona el Libro Mayor (GL). El GL es el registro maestro de todas las transacciones financieras dentro de una organización. Es la única fuente de verdad para crear balances y estados de resultados. Si los duplicados se cuelan en el GL, quizás por la doble importación de un CSV de una sucursal regional, distorsionan la salud financiera de toda la empresa. Una exageración de los gastos por varios cientos de miles de dólares debido a una serie de duplicados sutiles en múltiples cuentas podría llevar a cálculos de rentabilidad incorrectos. Esto puede engañar a los inversores y provocar complicaciones en las auditorías. Incluso puede llevar a pagos excesivos de impuestos, un impacto directo y negativo en el flujo de caja. Aquí es donde una solución profesional de limpieza de datos no es solo útil, sino absolutamente esencial.
Mantener datos financieros de alta calidad a través de procesos sólidos y auditables es un principio central de la gobernanza corporativa. Es por eso que herramientas como TabliSync están diseñadas para respaldar la precisión de los datos financieros en cada paso. Los informes de resolución y las pistas de auditoría claras que mencionamos están diseñados para proporcionar la confianza necesaria para sus auditores financieros. Necesitan pruebas de que sus datos se manejan de manera repetible y sin prejuicios. Para experiencia en este campo, proporcionamos un ejemplo. Una empresa multinacional de logística con operaciones en 12 países utilizó TabliSync para procesar más de 2 millones de asientos de libro mayor mensualmente. Al reemplazar sus comprobaciones manuales de Excel con nuestra solución impulsada por IA, encontraron más de 1.500 duplicados significativos en sus transacciones entre compañías en el primer mes. Esta corrección por sí sola les ahorró más de $400,000 en posibles pagos excesivos de impuestos. Más importante aún, redujo su cierre de fin de mes en cinco días hábiles. El nivel de control y garantía que proporciona un sistema automatizado es inigualable. Es la diferencia entre un proceso manual de alto riesgo y un sistema confiable y escalable. Esto no es solo una mejora; es un requisito absoluto para cualquier organización que valore la integridad financiera.
Automatización en Acción: Estudios de Caso del Mundo Real en Limpieza de Datos Complejos
La teoría solo es útil cuando se demuestra con resultados. Estos tres estudios de caso del mundo real demuestran el poder transformador de TabliSync para lograr ahorros de tiempo sustanciales y mejorar drásticamente el rendimiento operativo. Le muestran el impacto tangible de usar la limpieza de datos con IA para Eliminar Duplicados en Excel y otros formatos de datos en diversos escenarios, desde flujos de trabajo industriales hasta sistemas complejos de nómina. Esta sección se basa en la experiencia real en entornos de datos de alta presión.
Estudio de Caso 1: Recuperación de 300 Horas Mensuales en Procesamiento de Datos Industriales
Experiencia: Un gran cliente de manufactura con múltiples plantas de ensamblaje a nivel mundial tuvo problemas con el inventario de su cadena de suministro global. Cada planta operaba con instancias separadas de un sistema de gestión de almacenes, lo que generaba datos fragmentados y superpuestos. Intentaron consolidar esto en una única hoja de cálculo maestra para planificar la adquisición, lo que resultó en un conjunto de datos de más de 850.000 filas. Un equipo de cuatro analistas dedicó un total de 300 horas al mes a intentar Eliminar Duplicados de Excel manualmente para crear una visión precisa del inventario disponible. El problema era masivo. Los SKUs de productos idénticos de diferentes plantas se formateaban de manera ligeramente diferente, lo que hacía que las herramientas estándar de Excel no detectaran miles de registros. Las cifras de inventario exageradas provocaron retrasos en la adquisición, lo que resultó en paradas de línea de producción debido a la escasez de piezas, con un costo estimado de $50.000 por hora en tiempo de inactividad. Su flujo de trabajo manual también estaba plagado de errores humanos, lo que provocó una tasa de error del 4% en el informe final, aumentando aún más el riesgo operativo.
Solución: La empresa integró TabliSync para automatizar flujos de trabajo de hojas de cálculo por completo. Configuraron una conexión directa a todas las API de los sistemas de almacén, que transmitieron automáticamente los datos a un único canal unificado. En lugar de depender de coincidencias exactas de SKU, implementaron limpieza de datos con IA con una regla de deduplicación semántica. El sistema se configuró para identificar registros donde no solo el SKU, sino también la 'Descripción del producto' y el 'Nombre del proveedor' tuvieran un 95% de similitud. Esta potente Coincidencia Difusa con IA detectó instantáneamente variaciones sutiles que un analista humano, o una fórmula básica COUNTIF, siempre pasarían por alto. Por ejemplo, marcó y resolvió con éxito 'Widget-A-123' en la Planta 1, 'WidgetA123' en la Planta 2 y 'Widget - A123' en la Planta 3, todo como un único grupo duplicado, siguiendo reglas de negocio predefinidas para conservar el registro actualizado más recientemente.
Resultado: La transformación fue instantánea. El proceso manual de 300 horas se redujo a un pipeline totalmente automatizado que se ejecutó en solo 18 minutos. Por primera vez, la empresa tuvo una visión global del inventario verdaderamente precisa y sin duplicados, lo que redujo las paradas de producción en más del 90% y ahorró un estimado de $250,000 mensuales en pérdida de productividad. Así es como se logra el procesamiento de datos industriales a escala. La solución proporcionó datos de alta calidad que informaron directamente una mejor planificación estratégica. Este caso de estudio demuestra el ROI masivo y directo que se puede lograr con una estrategia profesional de eliminación de duplicados. No se trata de ahorrar tiempo en una sola hoja de cálculo; se trata de rediseñar los flujos de trabajo operativos centrales para obtener una ventaja competitiva.
Caso de Estudio 2: Aceleración del Cierre de Fin de Mes en 6 Días con Precisión en Datos Financieros
Experiencia: Un gran fideicomiso de inversión inmobiliaria (REIT) que cotiza en bolsa se ahogaba en la conciliación de datos financieros. Su estructura corporativa incluía más de 150 entidades de propiedad únicas, cada una enviando un estado de cuenta del libro mayor general mensual en formato CSV. Esto resultó en más de 1 millón de transacciones que necesitaban ser consolidadas y conciliadas. Un equipo de profesionales de contabilidad dedicó los primeros ocho días de cada cierre de fin de mes a intentar Eliminar Duplicados Excel de transacciones manualmente utilizando tablas dinámicas y búsquedas complejas en este enorme conjunto de datos. El problema era agudo con las transacciones entre compañías, donde la misma factura era registrada tanto por la propiedad como por la entidad central, a menudo con ligeras diferencias de caracteres. Eran comunes los sobrecostos en cuentas por pagar y por cobrar entre compañías, lo que distorsionaba el estado financiero consolidado y requería ajustes de auditoría significativos, lo que dañaba la confianza. Un solo duplicado en una transferencia bancaria entre compañías de $2.5 millones tomó cinco días de tiempo de un auditor senior para identificarlo y resolverlo, lo que resalta la naturaleza crítica de la precisión de los datos financieros.
Solución: El REIT implementó TabliSync para automatizar flujos de trabajo de hojas de cálculo para todo su cierre de mes. Utilizaron nuestro avanzado disparador Webhook para que, tan pronto como cada entidad de propiedad subiera su CSV a un portal seguro, los datos se ingirieran automáticamente en un pipeline consolidado. Para la deduplicación, utilizaron una regla de coincidencia de claves múltiples, combinando 'Fecha de Transacción', 'Monto', 'Moneda' y un token único de 'Número de Factura' generado por nuestro algoritmo impulsado por la experiencia, que estandariza campos de referencia complejos. Este sistema basado en reglas proporcionó la precisión que necesitaban. Además, los informes de resolución de TabliSync proporcionaron un rastro de auditoría detallado, que mostraba exactamente qué transacciones se fusionaron y por qué. Esto proporcionó la seguridad necesaria a sus auditores externos con respecto a sus controles internos, generando directamente confianza.
Resultado: El impacto fue profundo. Todo el proceso de conciliación y deduplicación se redujo de 8 días a solo 2 días. Los contadores ahora realizaban análisis en tiempo real y pronósticos financieros, en lugar de luchar contra hojas de cálculo. Esta reducción de seis días en el cierre de mes permitió una presentación de informes financieros más rápida y una toma de decisiones más ágil. Además, este proceso mejorado proporcionó un entorno de control interno verificable y robusto, eliminando por completo el problema de duplicación de transferencias bancarias interempresariales de $2.5 millones. Este caso de estudio muestra que la alta precisión de los datos financieros no es solo un requisito normativo deseable, sino un diferenciador clave para impulsar la agilidad financiera y reducir el riesgo operativo.
Caso de Estudio 3: Reducción a la Mitad de los Errores en el Proceso de Nómina con Limpieza de Datos con IA en un Sistema de Alto Volumen
Experiencia: Una gran empresa de servicios de atención médica con más de 15.000 empleados por horas en más de 60 clínicas tuvo problemas con un sistema de nómina de alto volumen. Recopilaban las horas trabajadas a través de un sistema de fichaje más antiguo basado en CSV y otros datos de RR. HH. de un sistema más nuevo basado en la nube. Cada ciclo de pago, estas dos fuentes de datos se fusionaban manualmente en Excel, un proceso que invariablemente creaba miles de entradas duplicadas. El esfuerzo manual para Eliminar Duplicados Excel y otros tipos de datos requería un equipo de cinco analistas de RR. HH. trabajando a tiempo completo durante tres días. A pesar de este esfuerzo, la tasa de error en la ejecución final de la nómina se mantenía consistentemente por encima del 4%, lo que provocaba pagos excesivos e insuficientes a los empleados. Una sola entrada duplicada para un empleado con múltiples fichajes en el mismo día podía pasar desapercibida, lo que llevaba a un pago excesivo significativo. La corrección de estos errores requería la emisión de costosos ajustes de cheques y provocaba una frustración considerable en los empleados, dañando la moral y potencialmente generando problemas de cumplimiento de las leyes laborales.
Solución: La empresa aprovechó TabliSync para automatizar flujos de trabajo de hojas de cálculo y lograr una limpieza de datos con IA confiable para su nómina. Establecimos integraciones directas y en tiempo real tanto con su sistema de fichaje como con su plataforma de RR. HH. en la nube. Configuramos un flujo de trabajo avanzado de deduplicación en varias etapas. En la primera etapa, realizó una coincidencia exacta simple en 'ID de empleado' y 'Fecha de trabajo'. En la segunda etapa crucial, utilizó limpieza de datos con IA con una sofisticada regla de coincidencia difusa para los campos 'Hora de entrada' y 'Hora de salida'. Por ejemplo, si dos registros mostraban fichajes para el mismo empleado con una diferencia de menos de 3 minutos (una situación común cuando se presiona dos veces un reloj de tiempo), los fusionaba automáticamente siguiendo reglas de negocio predefinidas (por ejemplo, utilizando la hora de entrada más temprana y la hora de salida más tardía). Este nivel de precisión solo es posible con sistemas inteligentes. Además, implementamos un manejo de errores detallado que ponía en cuarentena automáticamente cualquier dato verdaderamente irreconciliable (por ejemplo, un empleado con múltiples entradas de día completo en dos ubicaciones diferentes) para una revisión humana inmediata.
Resultado: Esta transformación cambió las reglas del juego. El proceso manual de tres días se redujo a un flujo de trabajo totalmente automatizado que ejecutó y validó todo el conjunto de datos en 45 minutos. Más importante aún, la tasa de errores de nómina se redujo de más del 4% a menos del 0.5% en el primer ciclo. Esta reducción directa de los errores de pago y la eliminación de los ajustes manuales ahorraron a la empresa más de $18,000 en costos operativos y pagos excesivos en cada período de pago. La moral de los empleados mejoró ya que los pagos se volvieron consistentes y precisos, y el riesgo de problemas de cumplimiento se eliminó virtualmente. Este estudio de caso demuestra claramente que los datos de alto volumen requieren soluciones de limpieza de datos con IA de alta precisión para lograr tanto la eficiencia como el cumplimiento vital.
Preguntas frecuentes sobre cómo eliminar duplicados en Excel
P1: Intenté usar la herramienta integrada de Excel pero no detectó duplicados. ¿Qué pasó?
Esto es extremadamente común. Casi con seguridad te enfrentas a datos que parecen idénticos pero no lo son. La causa principal son los caracteres invisibles, como un espacio al final. La función `Eliminar duplicados` de Excel es un sistema de coincidencia exacta. Trata una celda que contiene 'A ' y otra celda con 'A' como dos valores únicos. Para solucionar esto manualmente, necesitarías ejecutar las funciones `=TRIM()` y `=CLEAN()` en todas las columnas afectadas, luego copiar los resultados y `Pegar como valores` para estandarizar realmente tus datos antes de poder usar la herramienta integrada de manera confiable. La limpieza de datos con IA automatizada en **TabliSync** tiene esta lógica de limpieza incorporada; estandariza todos los datos de texto y puede usar lógica difusa para detectar registros semánticamente idénticos que no son 100% exactos en caracteres, evitando todo este problema.
P2: ¿Puedo combinar varias columnas para encontrar duplicados reales en TabliSync?
Sí, y esta es una gran fortaleza. El editor de reglas de TabliSync te permite definir la clave compuesta para la unicidad. Esto es esencial para la lógica de negocio. Por ejemplo, si estás analizando el inventario, un registro único no es solo un 'ID de producto'; es la combinación de 'ID de producto', 'Ubicación del almacén' y 'Condición'. Puedes seleccionar estas tres columnas en TabliSync para crear tu identificador único, y el motor de deduplicación solo eliminará las filas que tengan valores idénticos en los tres campos. Esta validación de claves múltiples y pasos múltiples asegura que no solo estás eliminando datos, sino que estás realizando una limpieza de datos inteligente con IA para soportar el procesamiento de datos industrial. Este grado de especificidad es clave para el éxito en aplicaciones de alta complejidad.
P3: ¿TabliSync elimina los datos originales? ¿Es seguro usarlo?
Esta es una pregunta crucial para la Confianza. TabliSync **no** elimina tus datos originales. Funciona creando una copia de tu conjunto de datos y luego aplicando las reglas de duplicación a esa copia dentro de un pipeline dedicado. Tú defines la lógica y obtienes un conjunto de datos limpio descargable como resultado. Tu archivo Excel de origen original permanece completamente intacto. Siempre recomendamos esto como una mejor práctica en la gestión de datos. Además, para un registro de auditoría robusto, TabliSync genera un informe de resolución detallado que muestra exactamente qué filas duplicadas se identificaron, qué regla se aplicó y cómo se fusionaron o seleccionaron los valores finales, lo cual es esencial para el cumplimiento en áreas que requieren alta precisión de datos financieros.
P4: Mi conjunto de datos de Excel tiene más de 1 millón de filas. ¿Puede TabliSync manejarlo?
Absolutamente. El rendimiento a escala es una propuesta de valor central de TabliSync, especialmente para el procesamiento de datos industrial. Las funciones tradicionales de Excel a menudo se vuelven increíblemente lentas o incluso fallan al tratar con datos de este tamaño. El proceso de deduplicación con una fórmula de conteo avanzada llevaría horas. El motor de deduplicación de TabliSync está diseñado desde cero para big data. Procesamos y eliminamos duplicados de Excel de millones de filas en minutos, no en horas. Esto se hace aprovechando los recursos de computación distribuida basados en la nube para manejar los cálculos complejos en paralelo. Procesamos regularmente conjuntos de datos de 10 a 20 millones de filas para clientes, asegurando una velocidad y fiabilidad que las herramientas manuales no pueden igualar.
P5: ¿Puedo programar mi tarea de deduplicación para que se ejecute automáticamente?
Sí, y esta es la mejor manera de automatizar flujos de trabajo de hojas de cálculo. Puede configurar cada canalización de TabliSync con un horario flexible. Puede establecer que se ejecute cada hora, a diario, semanalmente o en días y horas específicos de su elección. Cada vez que se ejecuta la canalización, recuperará los datos más recientes de su origen, aplicará automáticamente la lógica de limpieza de datos con IA para Eliminar Duplicados Excel y generará un nuevo conjunto de datos de salida limpio. Esto garantiza que su análisis o aplicación posterior siempre trabaje con los datos más actuales y sin errores, eliminando todo el esfuerzo manual de su ciclo de vida de preparación de datos. Es una parte fundamental de las operaciones de datos modernas.
P6: ¿La IA de TabliSync puede identificar duplicados que están escritos de manera diferente?
Sí. Esta es la diferencia entre un sistema de coincidencia exacta y la limpieza de datos con IA. TabliSync tiene una función avanzada de **Coincidencia Difusa con IA**. Utiliza procesamiento de lenguaje natural (PLN) para comparar registros semánticamente. Por ejemplo, puede marcar con confianza 'Inc.' frente a 'Incorporated', o 'Street' frente a 'St.', e incluso detectar variaciones comunes de ortografía de un nombre (como 'Jon' frente a 'John'). Puede controlar el umbral de similitud semántica. No solo está comparando caracteres; está comparando el significado. Esta capacidad cambia las reglas del juego para la consolidación de datos de clientes (CRM) o al fusionar listas de proveedores de múltiples sistemas heredados, lo que conduce directamente a mejoras en la precisión de los datos financieros. Esta coincidencia inteligente es una característica principal que debería estar utilizando.
P7: Cuando se encuentra un duplicado, ¿qué registro conserva TabliSync?
Tienes control total sobre esto. TabliSync no toma decisiones arbitrarias. En nuestro constructor de reglas de desduplicación, defines explícitamente la **Lógica de Fusión** o la **Regla de Resolución**. Puedes crear reglas sofisticadas de varios pasos. Por ejemplo, para una base de datos de productos, podrías crear una regla: "Conservar el registro con el precio más alto", o para un libro mayor general, "Conservar el registro que se creó último según su marca de tiempo de transacción". Este sistema basado en reglas garantiza que el proceso de desduplicación sea predecible y auditable, lo cual es esencial para la **precisión de los datos financieros**. Esto es muy superior a la eliminación manual en Excel, donde tomas una decisión caso por caso que es propensa a errores y no ofrece un rastro de auditoría.
P8: Tengo una situación única en la que algunos datos deben manejarse específicamente. ¿Puede TabliSync ayudar?
Sí. TabliSync es una plataforma potente y flexible. Entendemos que no todos los casos de desduplicación son sencillos. Puedes crear configuraciones de reglas muy avanzadas que van más allá de un solo componente. Por ejemplo, podrías usar un componente de 'Filtro' para dividir tus datos en dos rutas: una para la desduplicación estándar y otra para una regla especializada de alto contacto. También puedes encadenar varios pasos de desduplicación para lograr una limpieza de datos extremadamente precisa. Para el procesamiento de datos industriales muy complejo, incluso podemos crear lógica de desduplicación personalizada adaptada a tus necesidades comerciales exactas a través de nuestros servicios profesionales. Esta flexibilidad garantiza que podamos resolver casi cualquier problema que encuentres con la limpieza de datos a gran escala.
P9: ¿Cómo sé que la desduplicación fue exitosa?
Proporcionamos múltiples capas de verificación. Inmediatamente después de completar una sincronización, se te presenta un informe resumen de desduplicación. Este informe te muestra exactamente cuántas filas se ingresaron, cuántos duplicados totales se encontraron y el recuento final de filas únicas. Crucialmente, también generamos un **Informe de Resolución**. Este informe es un registro transaccional para cada grupo de duplicados. Muestra las filas de entrada individuales, cuál fue seleccionada como ganadora y por qué (por ejemplo, regla "Conservado según la regla 'Fecha de Modificación' más reciente"). Este nivel de transparencia es esencial para validar la lógica y proporciona un rastro de auditoría claro que es fundamental para el cumplimiento corporativo, especialmente en áreas con altos requisitos de **precisión de datos financieros**. Tienes visibilidad y control completos.
P10: ¿Están mis datos seguros en su plataforma? Tengo PII (Información de Identificación Personal).
La seguridad de los datos es nuestra máxima prioridad. Construimos confianza implementando sólidas medidas de seguridad. TabliSync está construido con una arquitectura de seguridad primero. Utilizamos cifrado estándar de la industria para todos los datos en reposo y en tránsito (SSL/TLS 1.2 y AES-256). Para PII, cumplimos con SOC 2 Tipo II, que es un estándar clave de la industria para la protección de datos. Proporcionamos control de acceso granular, lo que le permite administrar qué usuarios en su organización tienen acceso a canalizaciones y datos específicos. Además, puede configurar sus canalizaciones para enmascarar o incluso redactar permanentemente campos confidenciales (como números de tarjetas de crédito completos o números de seguro social) dentro de la salida de deduplicación, proporcionando una capa adicional de seguridad y ayudándole a mantener el cumplimiento de regulaciones como GDPR o CCPA. Puede confiar en TabliSync con sus datos más sensibles.
Deja de luchar contra las hojas de cálculo, empieza a ganar con datos limpios
Intentar manualmente **Eliminar Duplicados de Datos de Excel** es un desperdicio masivo de sus recursos más valiosos. Es una batalla lenta y propensa a errores contra espacios invisibles, formatos conflictivos y una simple falta de comprensión semántica que está incrustada en herramientas antiguas. Confiar en funciones básicas como `Eliminar Duplicados` ya no es viable para datos de alto volumen y alta integridad. Es una estrategia obsoleta que erosiona la rentabilidad y aumenta el riesgo de cumplimiento.
Necesita transformar sus procesos de datos ahora. Pasar a la **limpieza de datos con IA** con **TabliSync** no es solo una ganancia de eficiencia; es un cambio fundamental en la forma en que su organización maneja la información. Está pasando de un estado de fricción manual y alto riesgo a uno de flujo automatizado y precisión de datos financieros verificada. Recupere las más de 300 horas que su equipo está desperdiciando actualmente, cierre su ciclo financiero de fin de mes 6 días antes y reduzca los errores de nómina a la mitad. Los resultados son claros e inmediatos.
Cada minuto que pospones es un minuto que tu competencia opera con datos más limpios, rápidos y confiables. El dolor de la gestión manual de datos no desaparecerá por sí solo; solo crecerá con el tamaño y la complejidad de tu negocio. No dejes que tus valiosos analistas sigan siendo conserjes de datos. Empodéralos con soluciones inteligentes y escalables. Deja de luchar una batalla perdida y empieza a ganar con datos limpios y verificados que impulsan tu negocio. Estamos listos para ayudarte en este viaje. Esta transformación es sencilla y los resultados están garantizados. La elección es tuya: quédate atascado con herramientas manuales o abraza el futuro de los datos automatizados e inteligentes.
Experimenta la transformación por ti mismo hoy. Este es el momento de actuar. **[Haz clic aquí para comenzar tu prueba gratuita de 3 días de TabliSync.]** Nuestra plataforma no requiere una configuración compleja ni una formación extensa. Te mostraremos cómo conectar tu primer archivo de Excel y lograr una desduplicación precisa impulsada por IA en menos de 30 minutos. El ahorro de tiempo que recuperes en tu primera semana solo superará el costo de todo el año. Toma el control de tus datos y desbloquea el verdadero potencial de tu organización.
¿Qué es Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente?
Respuestas rápidas sobre Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente y cómo TabliSync ayuda a los equipos a trabajar más rápido en Excel.
¿Qué es Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente?
Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente cubre flujos prácticos de Excel, errores comunes y patrones de automatización. Esta guía de TabliSync explica el concepto, muestra ejemplos y enlaza tutoriales relacionados.
¿Cómo puede TabliSync ayudar con Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente?
TabliSync puede extraer tablas de capturas o PDF, limpiar datos desordenados y automatizar tareas repetitivas de Excel relacionadas con Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente.
¿Por dónde empiezo con Cómo Eliminar Duplicados de Datos de Excel con IA Rápidamente?
Empieza con la visión general de esta página y luego abre los artículos relacionados para guías paso a paso, plantillas y flujos con IA.
Todos los Artículos de Eliminar Duplicados Excel(2)

Dominando el Desorden: Cómo Eliminar Duplicados en Excel Sin Pérdida de Datos
Ganancias de Eficiencia: Reduzca el tiempo de limpieza manual de datos en más del 90% utilizando flujos de trabajo automatizados. Integridad de Datos: Logre una tasa de error del 0% en la entrada manual al pasar de 'Buscar y Reemplazar' a la deduplicación basada en esquemas. M itigación de Riesgos: Prevenga el 100% de las eliminaciones accidentales utilizando entornos de Power Query no destructivos. Preparación para el Futuro: Pase de la limpieza reactiva a la Higiene de Datos proactiva a través de la automatización integrada con IA.

Cómo Desproteger una Hoja de Excel Sin Saber la Contraseña
• Omita instantáneamente la protección de hojas de Excel con 0% de pérdida de datos. • Reduzca el tiempo de recuperación manual en un 95% utilizando la manipulación del esquema XML. • Elimine los errores de 'celda bloqueada' y restaure la higiene completa de los datos al instante. • Aproveche la OCR con IA para transformar vistas protegidas estáticas en datos estructurados dinámicos.
Stop Manual Data Entry – Extract Tables in Seconds
Convert any image or PDF table to Excel instantly with 99.9% accuracy. TabliSync's AI-powered OCR handles handwritten forms, receipts, and complex tables – then syncs directly to Google Sheets, Notion, or Airtable
Try TabliSync Free Now