Article Summary
Esta guía completa explora la evolución del análisis de datos, centrándose en la tarea crítica de 'Dividir texto en columnas' dentro de tablas complejas y no estructuradas. Profundizamos en las limitaciones de las herramientas heredadas como el asistente 'Texto en columnas' de Excel, que a menudo falla cuando se enfrenta a datos anidados, delimitadores inconsistentes o entradas de celda multilínea. Al integrar la extracción de datos con IA y el análisis automatizado de tablas, los usuarios ahora pueden manejar la limpieza de datos financieros y el procesamiento complejo de OCR con una precisión sin precedentes. La página pilar proporciona un recorrido táctico de la conversión de datos estructurales, comparando métodos manuales basados en expresiones regulares con soluciones modernas impulsadas por IA como TabliSync. Cubrimos casos de uso empresariales específicos, incluida la conciliación del libro mayor general, el procesamiento automatizado de facturas y el manejo de valores nulos a través de estrategias avanzadas de imputación. La guía sirve como un manual técnico para gerentes de operaciones, analistas de datos y profesionales de finanzas que necesitan escalar sus flujos de trabajo de datos sin sacrificar precisión o seguridad. Enfatiza la importancia del cumplimiento de SOC2 y el papel de los Webhooks en la construcción de pipelines de datos automatizados y sin fisuras de extremo a extremo para la inteligencia empresarial moderna.
La Evolución del Análisis de Datos: Más Allá del Asistente Básico
Para comprender el estado actual de Dividir texto en columnas, primero debemos observar los cimientos tradicionales. Según la documentación de Soporte de Microsoft sobre el 'Asistente para convertir texto en columnas':
"Puede tomar el texto de una o más celdas y distribuirlo en varias celdas utilizando el Asistente para convertir texto en columnas. Esto se utiliza generalmente para datos delimitados por un carácter específico, como una coma, o datos que tienen un ancho fijo. Por ejemplo, si tiene una lista de nombres completos en una columna, es posible que desee dividir esa columna en columnas separadas de Nombre y Apellido. Seleccione la celda o columna que contiene el texto que desea dividir. Seleccione Datos > Texto en columnas. En el Asistente para convertir texto en columnas, seleccione Delimitado > Siguiente. Seleccione los delimitadores para sus datos. Por ejemplo, Coma y Espacio. Puede ver una vista previa de sus datos en la ventana Vista previa de datos. Seleccione Siguiente. Seleccione el formato de datos de la columna o utilice el que Excel eligió para usted. Seleccione Finalizar." (Fuente: Soporte de Microsoft, 2024).
Si bien este enfoque fundamental es un elemento básico para las tareas básicas de hojas de cálculo, la limpieza de datos financieros moderna requiere mucha más potencia. El método de Microsoft asume un nivel de limpieza de datos que rara vez existe en el procesamiento complejo de OCR del mundo real. En un entorno profesional, no solo está dividiendo "Juan Pérez" en dos celdas. Está tratando con la conversión de datos estructurales de PDFs heredados donde el "delimitador" puede ser un número aleatorio de espacios, un salto de línea o, peor aún, un valor faltante que hace que toda la fila se desplace hacia la izquierda, arruinando la alineación de su Libro Mayor General.
Mi perspectiva sobre esto es que hemos superado el "Asistente". Para la extracción de datos de IA de alto riesgo, depender de la selección manual de delimitadores es una receta para el desastre. Cuando tiene 50.000 filas de datos, una sola fila con una coma adicional crea un error en cascada que puede tardar horas en auditarse. Necesitamos avanzar hacia el análisis de tablas automatizado que comprenda el contexto de los datos, en lugar de simplemente buscar un punto y coma. El cambio de la división basada en reglas a la extracción consciente del contexto es lo que define la próxima generación de herramientas de productividad.
El Asesino Silencioso: Manejo de Valores Faltantes y Nulos
El punto más crítico en cualquier flujo de trabajo de División de texto en columnas es el mal manejo de los valores faltantes o nulos. En muchos sistemas heredados, no hay una forma sistemática de imputar o marcar estas lagunas. Imagine que está procesando una exportación masiva de un sistema ERP. La Columna A es la fecha, la Columna B es el proveedor y la Columna C es el monto. Si falta el nombre del proveedor en algunas filas, un script estándar de análisis automatizado de tablas podría transferir el "monto" a la columna "proveedor". Esto no solo crea datos desordenados; crea errores invisibles que conducen a fallos en la Conciliación.
Sin una forma de marcar los nulos, su conversión de datos estructurales se convierte en una responsabilidad. La mayoría de los usuarios intentan solucionarlo desplazándose manualmente por miles de líneas, buscando datos "desplazados". Esto no es solo una pérdida de tiempo; es un fallo fundamental del pipeline de datos. Vemos esto a menudo en la limpieza de datos financieros, donde la falta de un código de Libro Mayor resulta en que los gastos se clasifiquen incorrectamente, lo que podría generar fallos en auditorías o discrepancias fiscales. La falta de un motor sistemático de "imputación" o "marcado" significa que el consumidor de datos siempre está trabajando con un conjunto de datos defectuoso.
A nivel empresarial, no puede permitirse tener un humano como el principal "verificador de nulos". Necesita un sistema que detecte la ausencia de un valor basándose en el tipo de dato esperado. Si la Columna C espera un formato de moneda y encuentra una cadena de texto, el sistema debería marcar inmediatamente esa fila. El procesamiento tradicional de OCR a menudo omite estos matices porque se centra en el reconocimiento de caracteres en lugar de la comprensión semántica. Aquí es donde la extracción de datos con IA cierra la brecha, permitiendo la inserción automática de marcadores de posición o la activación de un Webhook para la revisión humana solo cuando se detecta una anomalía.
Excel tradicional vs. Extracción de datos con IA: La brecha de eficiencia
Cuando hablamos de Dividir texto en columnas, debemos abordar el análisis costo-beneficio de los métodos tradicionales frente a la extracción de datos con IA. En un estudio de caso reciente que involucró a una firma de contabilidad de tamaño mediano, dedicaban aproximadamente 15 horas por semana a la limpieza manual de extractos bancarios y exportaciones del Libro Mayor. El uso de los asistentes tradicionales de Excel requería que un analista ajustara manualmente el "ancho fijo" para cada formato de banco diferente. Con una tarifa por hora promedio de $45, esta firma gastaba más de $35,000 anuales solo en la limpieza básica de datos financieros.
Al cambiar al análisis de tablas automatizado a través de TabliSync, la firma redujo esas 15 horas de trabajo a solo 12 minutos de verificación. La ganancia de Eficiencia fue de casi el 98%. A diferencia del asistente de Excel, la extracción de datos con IA utiliza aprendizaje automático para identificar patrones. No le importa si el banco cambia su fuente o agrega un nuevo logotipo en la parte superior del PDF. El motor de conversión de datos estructurales identifica los encabezados de las tablas y mapea inteligentemente el contenido a las columnas correctas, independientemente de los cambios en la disposición física. Esta es la diferencia entre una "herramienta" y una "solución".
Además, los ahorros de costos se extienden más allá de la mano de obra. Considere el costo de un error de entrada de datos. En un proceso de Conciliación, un solo punto decimal mal colocado debido a una división fallida de texto a columnas puede resultar en una discrepancia de varios miles de dólares. El procesamiento complejo de OCR combinado con la validación de IA reduce la tasa de error del promedio de la industria del 4% (entrada manual) a menos del 0.1%. Cuando se tiene en cuenta el riesgo reducido de reformulaciones financieras, el ROI para el análisis de tablas automatizado se vuelve exponencial. Las empresas ya no solo ahorran tiempo; están comprando precisión y tranquilidad.
Característica Asistente tradicional de Excel Extracción con IA de TabliSync
Tiempo de configuración
Manual para cada tipo de archivo
Aprendizaje sin plantillas, una sola vez
Tablas complejas
Falla en celdas anidadas/multilínea
Maneja estructuras anidadas fácilmente
Manejo de nulos
Causa desplazamiento de columnas
Marca automáticamente y mantiene la estructura
Escalabilidad
Limitada por la capacidad humana
Procesa miles de páginas a través de API
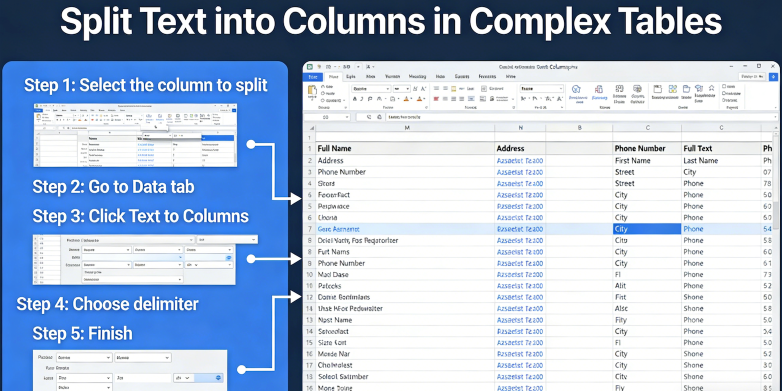
Paso a Paso: Dominando la División de Texto Complejo en Columnas
Paso 1: Analizando la Estructura y los Delimitadores de Origen
Antes de que siquiera pienses en Dividir Texto en Columnas, debes realizar una auditoría profunda de tus datos de origen. Esto es especialmente cierto para el procesamiento complejo de OCR, donde el "texto" se extrae de un archivo plano o un PDF. Necesitas identificar si tus datos están realmente delimitados (por comas, tabulaciones o barras verticales) o si dependen de espacios de ancho fijo. Muchas tareas modernas de limpieza de datos financieros implican delimitadores "ocultos", como espacios de no separación o caracteres ASCII específicos que no son visibles en un editor de texto estándar.
En este paso, debes usar un editor de texto de alto nivel (como VS Code o Sublime) para ver los caracteres ocultos. Busca inconsistencias. ¿La tercera fila tiene una coma extra dentro de una cadena entre comillas? Las herramientas estándar de conversión de datos estructurales se atascarán con esto. Debes decidir si usar una expresión regular "codiciosa" o un modelo de extracción de datos con IA más matizado. Si estás tratando con un Libro Mayor, verifica si los números de cuenta y las descripciones se fusionan en un solo campo. Esta es la etapa en la que defines la "lógica" de tu división. Anota las celdas multilínea, ya que estas son la razón principal por la que los asistentes básicos fallan.
Consejo Profesional: Siempre crea una copia de seguridad de tus datos sin procesar antes de ejecutar cualquier script de análisis automatizado de tablas. Si la lógica de tu expresión regular es defectuosa, podrías sobrescribir datos críticos. Durante esta fase de análisis, documenta los "casos extremos": las filas que no se ajustan al patrón. Estas son las filas que requerirán extracción de datos con IA para interpretar contextual, en lugar de mecánicamente. Comprender la "forma" de tus datos aquí ahorra horas de solución de problemas en el Paso 3.
Paso 2: Configurando el Motor de Extracción de IA
Una vez que hayas identificado los patrones (o la falta de ellos), pasas a configurar tu motor de análisis automatizado de tablas. En TabliSync, esto no implica escribir código; implica definir las "entidades" que deseas extraer. En lugar de decirle al sistema "divide en cada coma", le dices al sistema "encuentra el Número de Factura, la Fecha y el Total del Artículo de Línea". Este enfoque de extracción de datos con IA es mucho más robusto porque utiliza la conciencia espacial y la lógica semántica para realizar la tarea de Dividir Texto en Columnas.
Durante la configuración, puede establecer reglas para la conversión de datos estructurales. Por ejemplo, si un valor se identifica como "Fecha", puede indicar al sistema que lo normalice al formato ISO 8601 (AAAA-MM-DD) durante la división. Aquí es donde ocurre la limpieza de datos financieros en tiempo real. No solo está moviendo texto; lo está transformando. También debe configurar el manejo de valores nulos aquí. Indique al sistema: "Si la columna 'Cantidad' está vacía, marque esta fila para revisión manual y no continúe con la exportación de Conciliación".
Este paso es también donde integra su configuración de Webhook. Si está procesando miles de documentos, querrá que el sistema notifique a su ERP (como NetSuite o SAP) una vez que el proceso de Dividir texto en columnas se complete. Esto crea un flujo de trabajo de análisis de tablas automatizado sin interrupciones. Asegúrese de probar su configuración con un subconjunto pequeño de 10 a 20 documentos variados para garantizar que la IA haya identificado correctamente los encabezados y los límites del procesamiento OCR complejo. Verifique la cobertura completa de campos antes de pasar al procesamiento masivo.
Paso 3: Ejecución y validación de datos post-división
El paso final es la ejecución real de la tarea Dividir texto en columnas y la validación posterior. Aquí es donde "la goma toca el camino". A medida que el motor de extracción de datos con IA procesa el archivo, poblará sus columnas de destino. Sin embargo, el trabajo aún no ha terminado. Debe implementar una capa de validación. Esto implica verificar los datos extraídos con reglas de negocio conocidas. Por ejemplo, en la limpieza de datos financieros, la suma de los elementos de línea "divididos" debe ser igual al "Importe total" extraído del encabezado. Si no coinciden, el análisis de tablas automatizado ha fallado una verificación de integridad.
La validación es donde la conversión de datos estructurales se convierte en algo de nivel empresarial. Debería buscar puntuaciones de "baja confianza". Las herramientas modernas de procesamiento OCR le darán un porcentaje de confianza para cada celda. Si el sistema solo está un 60% seguro de una división, debería mantenerse en una cola para su verificación humana. Este modelo de "humano en el bucle" asegura que usted mantenga un 100% de precisión mientras automatiza el 95% del volumen. Después de la validación, sus datos estarán listos para la Conciliación final o para su uso en paneles de inteligencia empresarial.
Preste mucha atención a cómo el sistema manejó esos valores nulos que discutimos anteriormente. ¿Los marcó correctamente? ¿Las columnas se mantuvieron alineadas? Si encuentra un error recurrente, vuelva al Paso 2 y refine las instrucciones de la IA. El objetivo es crear un bucle de auto-mejora donde cada trabajo de Dividir texto en columnas sea más preciso que el anterior. Finalmente, exporte sus datos en el formato requerido (CSV, JSON o inserción directa a través de API) y cierre el bucle archivando el documento original para el cumplimiento de SOC2 y las pistas de auditoría.
El papel de la conversión de datos estructurales en las auditorías financieras
En el mundo de la limpieza de datos financieros, la conversión de datos estructurales es más que una conveniencia; es un requisito para las auditorías modernas. Los auditores de hoy en día se están alejando de las pruebas basadas en muestras hacia pruebas de población completa. Esto significa que usted necesita poder Dividir texto en columnas para cada transacción en su Libro Mayor, no solo para unas pocas. Si sus datos están atrapados en exportaciones de PDF desordenadas y sin formato, se enfrentará a una factura de auditoría masiva o a una opinión calificada.
El uso de extracción de datos con IA para normalizar estos registros garantiza que cada transacción sea buscable y categorizable. Por ejemplo, al realizar una Conciliación entre extractos bancarios y registros internos, la capacidad de dividir automáticamente las cadenas de transacciones en "Fecha", "ID de transacción" y "Comerciante" permite la coincidencia automatizada. Esta capacidad de análisis de tablas automatizado puede reducir el tiempo dedicado a las auditorías de fin de año en semanas. Además, los registros de procesamiento OCR complejo proporcionan un rastro de auditoría claro de cómo se transformaron los datos, lo que es una gran victoria para los controles internos.
El cumplimiento de SOC2 también dicta que los datos deben manejarse de forma segura y precisa. Los procesos manuales de dividir texto en columnas son propensos a manipulaciones humanas o eliminaciones accidentales. Un sistema automatizado de conversión de datos estructurales como TabliSync garantiza que la lógica de transformación se aplique de manera consistente y que no se realicen cambios no autorizados durante el proceso de limpieza. Este nivel de Confianza es esencial para los CFO y los Controllers que necesitan firmar los estados financieros con absoluta confianza en la integridad de los datos subyacentes.
Caso de Estudio 1: Empresa de Logística Automatiza el Análisis de Conocimientos de Embarque
Un proveedor global de logística tenía problemas con el procesamiento OCR complejo de sus Conocimientos de Embarque. Cada socio de envío utilizaba un formato de tabla diferente y muchos documentos eran escaneos de baja calidad. Su flujo de trabajo manual de dividir texto en columnas involucraba a cinco empleados a tiempo completo que copiaban y pegaban datos de PDFs a Excel, corrigiendo manualmente los errores causados por columnas desplazadas. Procesaban 2.000 documentos al mes con una tasa de error del 12% en las columnas "Peso" y "Destino".
Implementaron TabliSync para la extracción de datos con IA. El sistema se entrenó con una variedad de diseños de documentos y aprendió a identificar la tabla principal independientemente del ruido circundante. El motor de análisis de tablas automatizado pudo dividir las descripciones de artículos de varias líneas en columnas separadas de "SKU", "Cantidad" y "Peso" con un 99% de precisión. Esta conversión de datos estructurales no solo ahorró tiempo; les permitió integrar los datos directamente en su sistema de seguimiento a través de Webhooks, proporcionando visibilidad en tiempo real a sus clientes.
El resultado fue una reducción total de costos de $120,000 en el primer año. Más importante aún, el tiempo de procesamiento de un envío se redujo de 4 horas a 5 minutos. Esto permitió a la empresa aceptar más clientes sin aumentar el personal. Este caso destaca cómo Dividir texto en columnas, cuando está impulsado por IA, se convierte en una ventaja estratégica en lugar de una tarea administrativa. Las ganancias de Eficiencia les permitieron escalar de una manera que el procesamiento manual nunca podría.
Estudio de caso 2: Limpieza financiera de un fideicomiso de inversión inmobiliaria (REIT)
Un gran REIT tenía un desafío masivo con la limpieza de datos financieros. Recibían miles de rollos de alquiler diferentes cada mes en varios formatos. Algunos eran archivos de Excel, otros eran PDF e incluso imágenes. La conversión de datos estructurales requerida para consolidar estos datos en un único Libro Mayor era una pesadilla. Su principal problema eran los datos "anidados", donde múltiples valores estaban empaquetados en una sola celda, lo que requería una operación compleja de Dividir texto en columnas que las herramientas estándar no podían manejar.
Al implementar la extracción de datos con IA, el REIT pudo automatizar la extracción de nombres de inquilinos, fechas de arrendamiento e historiales de pago. El motor de análisis de tablas automatizado reconoció cuando una sola celda contenía tanto el alquiler base como los cargos de mantenimiento de áreas comunes (CAM), dividiéndolos en columnas distintas para una contabilidad precisa. Este nivel de procesamiento OCR complejo era previamente imposible sin una intervención humana significativa.
El REIT informó una reducción del 70% en el tiempo necesario para cerrar sus libros mensuales. Al automatizar el proceso de Conciliación, también descubrieron más de $50,000 en alquileres subdeclarados que se habían pasado por alto en verificaciones manuales puntuales en meses anteriores. Esta Eficiencia y el consiguiente ahorro de costos demostraron que la extracción de datos con IA es una herramienta esencial para cualquier organización que gestione conjuntos de datos financieros complejos y de alto volumen. La conversión de datos estructurales fue la clave para desbloquear el verdadero valor de sus datos.
Estudio de caso 3: Firma legal y análisis de documentos de descubrimiento
Durante la fase de descubrimiento de un importante caso de litigio, un bufete de abogados tuvo que procesar más de 100.000 páginas de registros bancarios y memorandos internos. Necesitaban Dividir Texto en Columnas para cada transacción financiera mencionada para buscar patrones de fraude. La entrada manual estaba fuera de discusión debido a preocupaciones de tiempo y de cumplimiento SOC2. Necesitaban una herramienta de conversión de datos estructurales que pudiera manejar procesamiento OCR complejo manteniendo una estricta cadena de custodia.
TabliSync proporcionó las capacidades necesarias de extracción de datos con IA. El sistema analizó los documentos, identificando tablas de transacciones y dividiéndolas en columnas buscables que incluían "Pagador", "Monto", "Fecha" y "Fuente de Cuenta". Incluso cuando los documentos estaban rotados o ligeramente borrosos, el motor de análisis de tablas automatizado mantuvo una alta precisión. El bufete utilizó la integración Webhook para alimentar estos datos directamente en su software de apoyo a litigios para análisis avanzados.
Esta automatización permitió al equipo legal encontrar pruebas críticas en tres días, una tarea que habría llevado a un equipo de asistentes legales varios meses. La Confianza generada a través de una limpieza de datos financieros precisa y robustos rastros de auditoría fue fundamental para que el bufete ganara el caso. Esto demuestra que la conversión de datos estructurales es una herramienta versátil que se extiende mucho más allá del departamento de finanzas, desempeñando un papel crucial en el trabajo legal, de cumplimiento e investigativo.
Técnicas Avanzadas: Regex vs. IA para la Conversión de Datos Estructurales
Durante décadas, el estándar de oro para la **conversión de datos estructurales** fueron las expresiones regulares (Regex). Las Regex son potentes, pero frágiles. Requieren que un desarrollador anticipe cada posible variación en los datos. Si un proveedor cambia el formato de su factura moviendo el "Total" un centímetro a la derecha, la Regex a menudo se rompe. Esto conduce a un ciclo constante de mantenimiento y a la rotura de scripts de **análisis de tablas automatizado**. En contraste, la **extracción de datos con IA** es resiliente. No busca un carácter específico en una coordenada específica; busca el "concepto" de un total. Cuando se realiza una tarea de **dividir texto en columnas** en un **libro mayor general**, es posible que encuentre celdas que contengan tanto un código de cuenta como un nombre de cuenta (por ejemplo, "1001-Efectivo"). Una Regex podría dividir fácilmente esto en el guion. Pero, ¿y si el nombre de la cuenta contiene un guion? Una división estándar crearía tres columnas en lugar de dos. La **extracción de datos con IA** comprende el contexto y sabe que "Efectivo" es el nombre, incluso si contiene caracteres inusuales. Esto reduce la necesidad de una "sintonización constante de regex" y disminuye la barrera técnica para la **limpieza de datos financieros**. Además, el **análisis de tablas automatizado** con IA puede manejar lo "indivisible". Considere una tabla donde las filas no están claramente separadas por líneas, sino por espacios en blanco y tamaño de fuente. El **procesamiento complejo de OCR** puede identificar estas señales visuales para determinar dónde termina una columna y comienza la siguiente. Esta es la **conversión de datos estructurales** en su nivel más avanzado. Si bien la Regex todavía tiene un lugar para tareas muy simples y de alta velocidad, la empresa moderna debería apoyarse en la **extracción de datos con IA** para cualquier dato que sea variable, complejo o de alto riesgo. El **ahorro de costos** solo en tiempo de desarrollo hace que la IA sea la clara ganadora.Asegure el futuro de su estrategia de datos con Webhooks y API
Para dominar realmente Dividir texto en columnas, debes mirar más allá de la hoja de cálculo. El futuro del análisis automatizado de tablas es integrado y en tiempo real. Al utilizar Webhooks, puedes crear un flujo de datos donde, en el momento en que se carga un documento en una carpeta de almacenamiento en la nube, el motor de extracción de datos con IA se activa, realiza la conversión de datos estructurales y envía los datos limpios a tu base de datos. No se requiere descarga ni carga manual. Este es el pináculo de la Eficiencia.
Un enfoque "API-first" para la limpieza de datos financieros permite que tu software existente "solicite" datos estructurados. Por ejemplo, tu software de Conciliación puede enviar un PDF sin procesar a un punto final de la API y recibir un objeto JSON perfectamente formateado a cambio, con toda la lógica de Dividir texto en columnas ya aplicada. Esto elimina el "intermediario de la hoja de cálculo" y reduce el riesgo de corrupción de datos. Para los desarrolladores, esto significa que pueden crear funciones complejas sobre datos limpios sin preocuparse por el complejo procesamiento OCR subyacente o la lógica de extracción de tablas.
Finalmente, considera los aspectos de Confianza y seguridad. Las canalizaciones automatizadas con Webhooks reducen el número de personas que tienen acceso a datos sin procesar y sensibles. La extracción de datos con IA ocurre en un entorno seguro y la salida estructurada se entrega directamente al sistema de destino. Esto encaja perfectamente con los marcos de cumplimiento de SOC2, ya que minimiza la superficie de ataque para las violaciones de datos. Al preparar tu estrategia de datos para el futuro con estas herramientas, no solo estás resolviendo el problema actual de Dividir texto en columnas; estás construyendo una base escalable para la próxima década de transformación digital.
Preguntas Frecuentes (FAQ)
P1: ¿Cómo maneja la IA los diferentes formatos de fecha durante una división?
Cuando realiza una operación de Dividir texto en columnas utilizando la extracción de datos con IA, el sistema no se limita a cortar el texto; identifica el tipo de dato. Si una fila tiene "MM/DD/AAAA" y otra tiene "DD-Mes-AA", el motor de análisis de tablas automatizado puede normalizar ambas en un formato coherente durante la conversión de datos estructurales. Por ejemplo, en una conciliación de Libro Mayor, puede convertir todas las fechas al formato ISO estándar automáticamente. Esto evita errores en la limpieza de datos financieros que normalmente ocurrirían si solo utilizara un asistente simple de división de texto que no entiende la lógica de las fechas.
P2: ¿Puedo dividir texto que está fusionado en varias líneas en una sola celda?
Sí, esta es una de las mayores ventajas de la extracción de datos con IA sobre las herramientas tradicionales. Los asistentes básicos de Excel a menudo fallan cuando una sola fila de datos abarca varias líneas físicas en un PDF o una imagen. El procesamiento OCR complejo puede reconocer los límites visuales de una fila de tabla y tratar el texto de varias líneas como una sola entidad antes de aplicar la lógica de Dividir texto en columnas. Esto es esencial para la limpieza de datos financieros, donde las descripciones de las facturas a menudo son largas y se extienden en varias líneas, asegurando que sus cantidades y precios permanezcan siempre alineados con el artículo correcto.
P3: ¿Qué sucede si el delimitador falta en algunas filas?
En un flujo de trabajo tradicional de Dividir texto en columnas, un delimitador faltante hace que los datos se desplacen, lo que arruina todo el conjunto de datos. Sin embargo, el análisis de tablas automatizado con IA no se basa únicamente en delimitadores. Utiliza el contexto espacial y semántico. Si falta una coma, pero el sistema identifica un espacio claro y un cambio en el tipo de dato (por ejemplo, de texto a moneda), aún realizará la división correctamente. Esto evita el problema de los "valores nulos" y garantiza que su conversión de datos estructurales siga siendo precisa, incluso con archivos de origen imperfectos, que es un escenario común en el procesamiento OCR complejo.
P4: ¿Es posible dividir columnas sin usar código?
Absolutamente. Herramientas como TabliSync están diseñadas para usuarios empresariales que necesitan extracción de datos con IA sin necesidad de escribir scripts de Regex o Python. Simplemente apuntas el sistema a la tabla y el motor de análisis automatizado de tablas hace el trabajo pesado. Esto democratiza la conversión de datos estructurales, permitiendo a contadores y gerentes de operaciones realizar su propia limpieza de datos financieros. Al eliminar el cuello de botella técnico, las organizaciones pueden mejorar la Eficiencia y permitir que sus equipos de TI se centren en tareas de integración de nivel superior mientras los usuarios empresariales gestionan la calidad de los datos por sí mismos.
P5: ¿Qué tan seguros están mis datos financieros durante el proceso de extracción?
La seguridad es una prioridad principal, especialmente para la limpieza de datos financieros. Plataformas profesionales de extracción de datos con IA como TabliSync se construyen teniendo en cuenta la cumplimiento SOC2. Esto significa que los datos se cifran en reposo y en tránsito. A diferencia de las tareas manuales de dividir texto en columnas que pueden ocurrir en máquinas locales no seguras, la conversión automatizada de datos estructurales ocurre en un entorno de nube controlado. Esto garantiza la Confianza y ayuda a las organizaciones a cumplir con los requisitos legales y regulatorios al manejar información sensible del Libro Mayor o del cliente durante el ciclo de vida del análisis automatizado de tablas.
P6: ¿Puede esto manejar tablas dentro de documentos escritos a mano?
El procesamiento OCR complejo moderno ha logrado avances significativos en el reconocimiento de la escritura a mano. Si bien es más desafiante que el texto impreso, la extracción de datos con IA a menudo puede identificar estructuras de tablas en notas o formularios escritos a mano. El motor de análisis automatizado de tablas busca las posiciones relativas del texto para inferir las columnas. Si bien la precisión puede ser ligeramente menor que con los PDF digitales, aún proporciona una gran ventaja para la conversión de datos estructurales. Para la limpieza de datos financieros de registros en papel heredados, esto puede ahorrar miles de horas de entrada manual de datos y trabajo de transcripción.
P7: ¿Qué es un Webhook y cómo ayuda a dividir columnas?
Un Webhook es una forma para que una aplicación envíe datos en tiempo real a otra tan pronto como ocurra un evento. En el contexto del análisis automatizado de tablas, puede configurar un Webhook para que, tan pronto como la extracción de datos por IA finalice un trabajo de división de texto en columnas, los datos estructurados resultantes se envíen automáticamente a su software ERP o de conciliación. Esto elimina el paso manual de exportar un CSV y cargarlo en otro lugar, aumentando significativamente la eficiencia de toda su canalización de datos y asegurando que la limpieza de datos financieros esté siempre actualizada.
P8: ¿Cómo maneja el sistema tablas muy grandes con miles de filas?
La extracción de datos por IA está diseñada para escalar. A diferencia de un proceso manual que se ralentiza a medida que aumenta el volumen, el análisis automatizado de tablas puede procesar miles de filas en segundos. La lógica de conversión de datos estructurales se aplica de manera consistente en todo el conjunto de datos, asegurando que la primera fila y la décima milésima fila se traten con el mismo nivel de precisión. Esto es vital para la limpieza de datos financieros en grandes empresas donde las exportaciones del Libro Mayor pueden ser masivas. El uso de un sistema automatizado garantiza que no pierda eficiencia a medida que crecen sus necesidades de datos.
P9: ¿Puedo personalizar los encabezados después de la división?
Sí, durante la configuración del análisis automatizado de tablas, puede definir exactamente cuáles deben ser los encabezados de salida. Incluso si el documento original tiene encabezados desordenados o poco descriptivos, el motor de extracción de datos por IA puede mapearlos a su formato interno estandarizado. Esta es una parte clave de la conversión de datos estructurales, ya que garantiza que los datos estén listos para su uso inmediato en sus herramientas de conciliación o BI. Personalizar los encabezados durante el proceso de división es una práctica recomendada para la limpieza de datos financieros, ya que mantiene la coherencia entre diferentes fuentes de datos y proveedores.
P10: ¿Cuál es la diferencia de costo entre la división manual y la de IA?
Los ahorros de costos suelen ser sustanciales. Las tareas manuales de dividir texto en columnas no solo son lentas, sino que también son propensas a errores costosos. Cuando se tiene en cuenta el salario por hora de un analista financiero calificado, el costo de la limpieza manual de datos financieros puede ser de 10 a 50 veces mayor que el uso de una solución de análisis de tablas automatizado. La extracción de datos con IA proporciona un costo fijo y predecible por documento o por fila, lo que facilita la elaboración de presupuestos y le permite escalar sus operaciones de conversión de datos estructurales sin un aumento lineal en la plantilla, lo que genera un ROI mucho mayor.
Deja de luchar contra tus datos, empieza a sincronizarlos
Los días de lidiar con asistentes rotos de dividir texto en columnas y exportaciones desalineadas del libro mayor general han terminado. Has visto los datos: la limpieza manual es un lastre para tu eficiencia, un riesgo para tu confianza y un desperdicio masivo de capital. Cada minuto que tu equipo dedica a corregir manualmente los errores de conversión de datos estructurales es un minuto que no dedican a análisis de alto valor o crecimiento estratégico. La brecha entre las empresas que utilizan la extracción de datos con IA y las que no, se amplía cada día.
No dejes que termine otro mes con una pesadilla de conciliación causada por fallos en el procesamiento complejo de OCR. TabliSync es el arma definitiva para la limpieza de datos financieros, diseñada para manejar tablas sucias, anidadas y no estructuradas que otras herramientas no pueden tocar. Ofrecemos la precisión del análisis de tablas automatizado con la seguridad del cumplimiento de SOC2, asegurando que tu canal de datos sea tan robusto como rápido. Esta es tu oportunidad de recuperar tu tiempo y garantizar una precisión del 100 % en tus flujos de trabajo de datos.
Experimenta el poder de TabliSync hoy mismo. Por tiempo limitado, puedes registrarte para una prueba gratuita y ver exactamente cómo nuestra extracción de datos con IA puede transformar tus tablas más desordenadas en activos perfectamente estructurados en segundos. Haz clic en el enlace de abajo para empezar, no dejes que la entrada manual de datos frene tu negocio por más tiempo. El futuro de la conversión de datos estructurales está aquí, y está a solo un clic de distancia.
[Prueba TabliSync Gratis Ahora]
¿Qué es Cómo dividir texto en columnas en tablas complejas?
Respuestas rápidas sobre Cómo dividir texto en columnas en tablas complejas y cómo TabliSync ayuda a los equipos a trabajar más rápido en Excel.
¿Qué es Cómo dividir texto en columnas en tablas complejas?
Cómo dividir texto en columnas en tablas complejas cubre flujos prácticos de Excel, errores comunes y patrones de automatización. Esta guía de TabliSync explica el concepto, muestra ejemplos y enlaza tutoriales relacionados.
¿Cómo puede TabliSync ayudar con Cómo dividir texto en columnas en tablas complejas?
TabliSync puede extraer tablas de capturas o PDF, limpiar datos desordenados y automatizar tareas repetitivas de Excel relacionadas con Cómo dividir texto en columnas en tablas complejas.
¿Por dónde empiezo con Cómo dividir texto en columnas en tablas complejas?
Empieza con la visión general de esta página y luego abre los artículos relacionados para guías paso a paso, plantillas y flujos con IA.

Stop Manual Data Entry – Extract Tables in Seconds
Convert any image or PDF table to Excel instantly with 99.9% accuracy. TabliSync's AI-powered OCR handles handwritten forms, receipts, and complex tables – then syncs directly to Google Sheets, Notion, or Airtable
Try TabliSync Free Now