Article Summary
Maîtriser l'OCR par lot vers Excel en 2026 Dans le paysage axé sur les données de 2026, la saisie manuelle traditionnelle de documents non structurés — tels que les factures, les reçus et les rapports logistiques — est devenue un goulot d'étranglement critique pour la croissance. Cet article fournit un guide définitif des technologies d'OCR par lot vers Excel, soulignant que l'OCR moderne a transcendé la simple transcription de texte pour se concentrer sur la restructuration intelligente des données et la conscience du contexte.
Maîtriser les grands ensembles de données : Le guide définitif de l'OCR par lots vers Excel
Traiter de grands ensembles de données signifie souvent faire face à une montagne de documents non structurés. Que vous soyez dans la finance, la logistique ou les soins de santé, le volume de factures, de reçus et de rapports peut être écrasant. La méthode traditionnelle de saisie manuelle des données n'est pas seulement lente ; c'est un goulot d'étranglement qui freine la croissance et introduit des erreurs coûteuses. La solution moderne réside dans l'exploitation de l'extraction automatisée de données grâce aux technologies d'OCR par lots vers Excel. Mais comment naviguer dans le paysage des outils disponibles et mettre en œuvre une solution qui évolue réellement ? Ce guide vous fournit l'expertise approfondie dont vous avez besoin pour maîtriser le traitement de documents en masse et obtenir une OCR de haute précision pour vos données financières et opérationnelles critiques.
Réflexions sur le paysage actuel de l'OCR : Au-delà de la transcription de base
Une analyse récente et perspicace de Lido, intitulée "Meilleur logiciel OCR pour l'extraction de données en 2024", explore les nuances critiques de la sélection du bon outil de reconnaissance optique de caractères. L'auteur souligne que l'OCR moderne a transcendé la simple transcription de texte, exigeant désormais une structuration sophistiquée des données et une conscience du contexte. Plus précisément, l'article met en évidence :
"La véritable valeur de l'OCR moderne ne réside pas seulement dans la reconnaissance des caractères, mais dans la compréhension de la structure des données qu'elle extrait. Pour les entreprises traitant des documents complexes tels que des factures et des états financiers, la capacité à analyser avec précision les tableaux et à maintenir les relations entre les données est primordiale. Sans cela, les 'données extraites' ne sont qu'un fouillis de texte, nécessitant encore un effort manuel important pour être réorganisées et rendues utilisables. Les plateformes d'extraction de données efficaces doivent offrir des capacités robustes de détection de tableaux et d'analyse de mise en page pour fournir des informations véritablement exploitables directement dans des formats tels qu'Excel ou des bases de données relationnelles." (Source : https://www.lido.app/blog/best-ocr-software)
En tant qu'expert en marketing de contenu SaaS profondément ancré dans l'espace de l'automatisation documentaire, je trouve cette perspective incroyablement pertinente. L'article de Lido identifie correctement le défi principal que de nombreuses entreprises négligent : le 'T' dans OCR devrait signifier 'Transformation', et non pas seulement 'Transcription'. Le marché est inondé d'outils OCR génériques capables de numériser une page de texte. Cependant, très peu possèdent l'intelligence spécialisée requise pour l'analyse de tableaux financiers sur des centaines ou des milliers de documents simultanément. C'est précisément là que le goulot d'étranglement passe de la 'lecture' du document à la 'restructuration' des données, une étape critique pour l'analyse en aval ou l'intégration ERP.
De plus, l'article souligne le rôle essentiel de l'intégration. D'après mon expérience, même un moteur OCR très précis devient un silo s'il ne peut pas injecter de manière transparente les données dans les flux de travail existants. Une solution robuste de traitement OCR par lots vers Excel doit non seulement exceller dans l'analyse de la mise en page, mais également fournir des API ou des webhooks robustes pour se connecter à des plateformes telles que Salesforce, NetSuite ou des logiciels de comptabilité spécialisés. Cela fait écho à l'accent mis par l'article de Lido sur les plateformes qui offrent des pipelines de données complets. La capacité à traiter divers formats de documents – allant des PDF et JPEG aux TIFF complexes multipages – en masse, tout en maintenant une grande précision et une intégrité structurelle, n'est plus un luxe ; c'est une nécessité concurrentielle pour toute organisation axée sur les données.

Le goulot d'étranglement multi-formats : pourquoi la variété de vos documents tue l'efficacité
Parlons du véritable point sensible du traitement de documents à grande échelle. Il ne s'agit pas seulement du volume ; c'est la [variété] pure et simple des formats et des mises en page des documents. Votre service financier ne reçoit pas les factures dans un seul format standardisé. Ils les reçoivent sous forme de PDF vectoriels de grands fournisseurs, de JPEG numérisés de mauvaise qualité de plus petits fournisseurs, de TIFF multipages de systèmes de télécopie plus anciens, et peut-être même de certains documents Word chaotiques. C'est l'Incapacité à traiter par lots des formats variés, et c'est un tueur de productivité. Les méthodes conventionnelles et les outils OCR moins avancés vous obligent à traiter chaque format différemment, nécessitant souvent un tri manuel fastidieux ou la création de modèles pour chaque mise en page de fournisseur.
- Chaque nouvelle mise en page de fournisseur exige un [nouveau modèle] ou une nouvelle configuration.
- Les documents numérisés nécessitent souvent une [pré-traitement manuel de l'image] comme la correction de l'inclinaison.
- La combinaison de différents types de fichiers en un seul lot de traitement est fréquemment [impossible].
- Les règles d'extraction de données qui fonctionnent pour un PDF clair [échouent] sur une numérisation granuleuse.
- Le résultat est un flux de travail fragmenté qui [ne peut pas être véritablement automatisé].
Imaginez votre équipe comptable fournisseurs essayant de traiter 10 000 factures par mois. 6 000 sont des PDF standard, mais 4 000 sont un mélange de numérisations, d'e-mails avec images intégrées et de types de fichiers étranges. L'approche conventionnelle signifie que l'équipe peut automatiser peut-être 60 % du flux de travail, mais les 40 % restants nécessitent une intervention manuelle très perturbatrice et lente. Ce n'est pas seulement inefficace ; c'est une [barrière massive à l'évolutivité]. L'incapacité à traiter tous ces formats variés comme un seul lot unifié signifie que votre traitement de documents en masse heurte constamment des obstacles. Vous n'atteignez pas une véritable automatisation ; vous automatisez seulement les parties faciles et laissez les parties difficiles et coûteuses aux humains, ce qui va à l'encontre de l'objectif d'adopter la technologie en premier lieu.
Cette douleur s'intensifie considérablement lorsqu'il s'agit de documents complexes et de plusieurs pages tels que des [contrats juridiques] ou des [rapports d'essais cliniques]. Un document de 50 pages peut contenir des tableaux financiers critiques aux pages 12, 35 et 48, chacun formaté légèrement différemment. Un outil OCR de base peut extraire tout le texte, mais échouera complètement à reconnaître que le tableau de la page 35 est une continuation de celui de la page 12, ou que le formatage a changé. Les données sortent sous forme d'un flux de texte incohérent, nécessitant des heures de découpage, de collage et de restructuration manuels dans Excel. Ce changement de contexte constant et rempli de frictions, ainsi que le nettoyage des données, rendent le traitement de documents à grande échelle incroyablement pénible et coûteux. Il ne s'agit pas seulement de lire des caractères ; il s'agit de maîtriser le chaos de la mise en page.
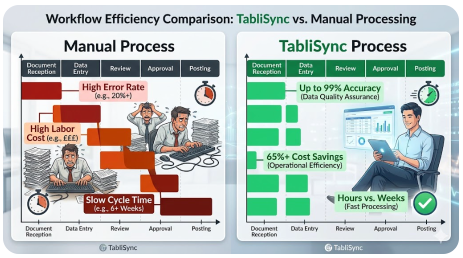
L'écart d'efficacité et de coût : Organisation manuelle vs. Conversion automatisée avec TabliSync
Pour vraiment comprendre la valeur de la **reconnaissance optique de caractères de haute précision** et de l'**extraction automatisée de données**, nous devons comparer le statu quo — organiser manuellement les données dans un fichier Excel — avec la conversion à l'aide de TabliSync. La différence n'est pas seulement marginale ; elle est transformatrice en termes d'[efficacité, d'économies et de qualité des données]. Décomposons les aspects économiques et opérationnels des deux approches en utilisant des repères et des scénarios industriels réels.
Les coûts cachés du statu quo manuel
Le traitement manuel de 10 000 documents par mois est une tâche monumentale. Un spécialiste expérimenté de la saisie de données peut traiter, en moyenne, peut-être 40 à 60 documents complexes (comme des factures multilignes) par heure, y compris la vérification. Pour traiter 10 000 documents, il faudrait environ 200 heures de travail concentré. Avec un coût moyen entièrement chargé de 30 $/heure (y compris les avantages sociaux et les frais généraux), votre coût mensuel de main-d'œuvre pour la seule saisie de données est de 6 000 $.
- [Taux d'erreurs élevés] : La saisie de données humaine présente généralement un taux d'erreur de 1 à 3 %. Pour 10 000 documents, cela représente 100 à 300 documents avec des données incorrectes, entraînant des problèmes coûteux de [rapprochement], des retards de paiement ou des problèmes de conformité.
- [Problèmes d'évolutivité] : Pour doubler votre capacité, vous devez doubler vos effectifs, ce qui entraîne une augmentation proportionnelle des coûts et des frais généraux de gestion. [La mise à l'échelle est linéaire et coûteuse].
- [Temps de cycle lents] : Il peut falloir des jours ou des semaines pour traiter un grand lot, ce qui retarde la visibilité financière et la prise de décision opérationnelle. [Des données lentes signifient une entreprise lente].
- [Faible moral des employés] : La saisie de données est répétitive et abrutissante, ce qui entraîne un [turnover] élevé des employés et des coûts de recrutement associés.
L'avantage TabliSync : Efficacité et économies réalisées
Examinons maintenant les mêmes 10 000 documents traités avec la solution Batch OCR vers Excel de TabliSync. TabliSync peut traiter des milliers de pages par heure. L'effort manuel passe de la « saisie » à la « gestion des exceptions » et à la « vérification ». Généralement, pour des documents de haute qualité, les taux d'automatisation peuvent dépasser 90 à 95 %, ce qui signifie que seulement 5 à 10 % des documents nécessitent un examen humain.
Au lieu de 200 heures, votre équipe pourrait passer 20 heures à vérifier les exceptions. Au même taux de 30 $/heure, votre coût de main-d'œuvre tombe à 600 $. Le coût de la plateforme TabliSync (en supposant un niveau SaaS typique pour ce volume) pourrait être d'environ 1 500 $/mois. Votre coût total est maintenant de 2 100 $, soit une [réduction de 65 %] des coûts opérationnels. Mais les économies ne s'arrêtent pas là.
- [Taux d'erreurs considérablement réduits] : Le moteur basé sur l'IA de TabliSync offre jusqu'à 99 % de précision, réduisant considérablement les coûts associés aux erreurs de données.
- [Extensibilité quasi instantanée] : Pour traiter 20 000 documents, il vous suffit d'ajuster votre abonnement. Il n'est pas nécessaire d'embaucher ou de former de nouveaux employés. [La mise à l'échelle est exponentielle et rentable].
- [Temps de cycle rapides] : Les lots qui prenaient des semaines sont maintenant traités en quelques heures, offrant une [visibilité financière en temps réel].
- [Travail à plus forte valeur ajoutée] : Votre équipe est libérée pour des [tâches analytiques], la planification stratégique et la gestion des relations avec les fournisseurs.
- [Conformité améliorée] : Chaque extraction est enregistrée et auditable, créant une [piste d'audit] robuste et réduisant le risque réglementaire.
Considérez une grande entreprise de logistique qui est passée à TabliSync pour le traitement des connaissements. Ils ont réduit leur équipe de saisie de données de 15 à 3 personnes, tout en *augmentant* leur volume de traitement de 40 %. Les 12 membres du personnel ont été reconvertis et affectés à des postes à forte valeur ajoutée en planification logistique et en support client. Les économies directes ont dépassé 450 000 $ par an, sans compter la valeur tirée des cycles de facturation plus rapides et de la réduction des erreurs. C'est l'impact quantifiable du passage du chaos manuel à la précision automatisée.
Guide étape par étape pour exécuter un projet OCR à grande échelle vers Excel
Maintenant que vous comprenez les avantages commerciaux puissants de la reconnaissance optique de caractères par lots vers Excel, parcourons l'exécution réelle à l'aide d'une plateforme puissante comme TabliSync. Un traitement de documents en masse réussi ne consiste pas seulement à cliquer sur un bouton ; il implique une approche méthodique pour garantir l'exactitude, la structure et un flux de données transparent. Ce guide décrira les étapes précises, avec les détails de configuration et les meilleures pratiques opérationnelles, pour vous faire passer d'une montagne de documents à des données Excel structurées et exploitables.
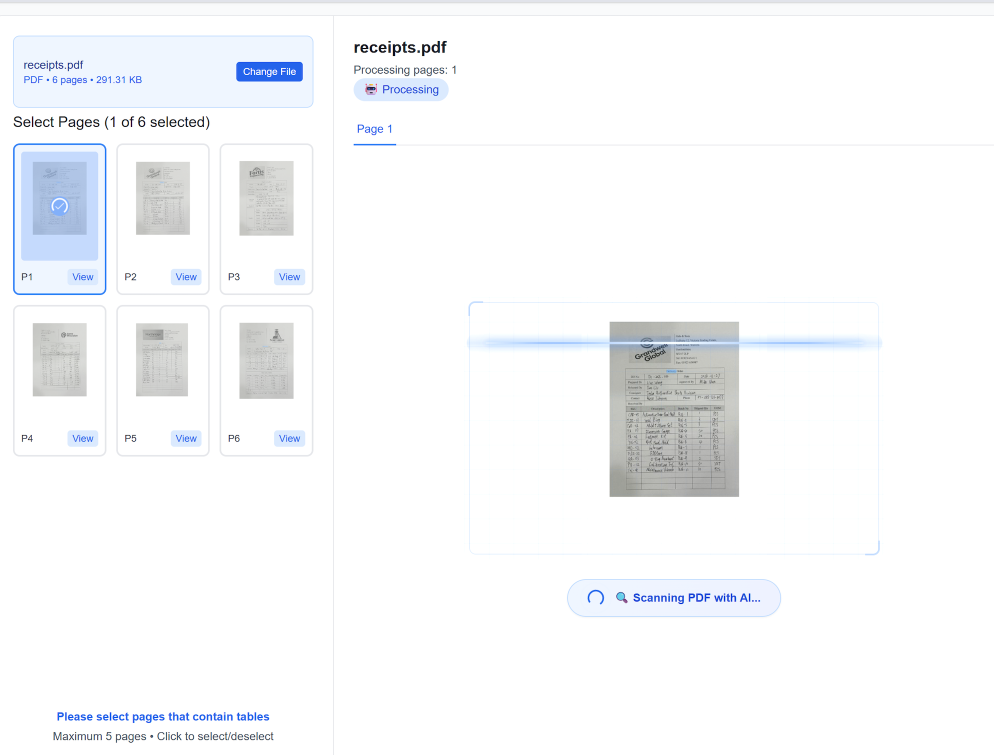
Étape 1 : Configuration du lot et ingestion des documents
La première étape, et peut-être la plus critique, consiste à configurer votre lot et à ingérer vos divers documents. C'est là que vous surmontez le goulot d'étranglement multi-formats. Dans TabliSync, vous n'avez pas besoin de trier les fichiers au préalable. Vous vous connectez simplement à votre tableau de bord sécurisé et créez un nouveau [Lot de traitement]. Dans les paramètres de configuration, vous spécifiez le [format de sortie] (dans ce cas, Excel), vos [paramètres du moteur OCR] préférés (par exemple, équilibrer vitesse et précision pour des numérisations particulièrement granuleuses), et toutes les [règles de pré-traitement] comme la rotation automatique ou la réduction du bruit.
Une fois configuré, vous disposez de plusieurs options d'ingestion pour vos grands ensembles de données. Pour quelques centaines de fichiers, l'interface de [téléchargement web direct] est suffisante. Pour des milliers de documents, vous utiliseriez idéalement notre [passerelle SFTP] sécurisée ou la puissante [API TabliSync]. Par exemple, une entreprise de logistique mondiale utilise l'API pour acheminer automatiquement les e-mails entrants avec des pièces jointes directement dans un lot de traitement, éliminant ainsi entièrement la manipulation manuelle. TabliSync accepte pratiquement tous les formats : PDF multipages, TIFF complexes, JPEG, et même des archives ZIP contenant un mélange de types de fichiers. Le système [décompresse, standardise et prépare] automatiquement chaque document pour l'étape suivante, fournissant un journal d'ingestion en temps réel.
[Note de prudence] : Lors de la configuration de votre lot, portez une attention particulière au [paramètre de langue du document]. Bien que TabliSync prenne en charge plusieurs langues, la sélection de la langue principale des documents améliore considérablement la précision, en particulier pour les variations subtiles de caractères ou les symboles monétaires. De plus, pour les documents numérisés, assurez-vous qu'ils ont une résolution d'au moins [300 DPI] pour des résultats fiables ; les numérisations de très basse résolution sont la principale cause d'erreurs OCR.
Étape 2 : Analyse intelligente de la mise en page et analyse des tableaux
Une fois les documents ingérés, le moteur d'IA principal de TabliSync prend le relais. Cette étape ne consiste pas à lire du texte ; il s'agit de comprendre la [hiérarchie visuelle et les relations structurelles] au sein de chaque page. C'est là que l'analyse des tableaux financiers devient cruciale. Notre moteur ne recherche pas seulement des mots-clés ; il analyse les espaces blancs, l'alignement et les indices de formatage pour identifier les [tableaux, les postes, les en-têtes et les paires clé-valeur] (comme « Date de facture » et sa date correspondante).
Il s'agit d'un processus sans modèle. L'IA de TabliSync a été entraînée sur des millions de documents divers, elle reconnaît donc automatiquement qu'un tableau de postes sur une facture de fournisseur est une entité unique, même s'il s'étend sur plusieurs pages et n'a pas de lignes de bordure claires. Pour l'analyse des tableaux financiers, elle sépare intelligemment la [quantité, le prix unitaire, la description et le total par poste] en colonnes distinctes et précises. Vous pouvez suivre cette progression via le tableau de bord TabliSync, qui vous indique exactement quels documents sont analysés et signale ceux dont la mise en page est ambiguë pour une revue humaine.
Pour garantir des résultats de qualité professionnelle pour votre rapprochement de [Grand Livre], utilisez les règles de validation TabliSync. Vous pouvez configurer des règles qui vérifient si les totaux des postes individuels s'additionnent au sous-total de la facture, ou si le montant de la taxe est calculé correctement sur la base d'un taux spécifié. Cela va au-delà de la simple extraction et ajoute une couche de [validation de la logique métier], garantissant que les données qui parviennent à votre fichier Excel ne sont pas seulement précises mais aussi logiquement cohérentes, ce qui accélère considérablement vos processus de Rapprochement en aval.
Étape 3 : Validation des données, gestion des exceptions et exportation Excel
La dernière étape consiste à affiner les données extraites, à gérer les exceptions et à exporter les informations finalisées et structurées vers Excel. Une fois l'IA terminée son analyse, TabliSync présente une [Interface de vérification]. Ici, les documents sont signalés pour une revue humaine uniquement si le score de confiance de l'IA pour les champs clés tombe en dessous de votre seuil prédéfini. Par exemple, si une note manuscrite particulièrement désordonnée obstrue un « Montant total », le système signalera ce document spécifique.
Dans l'écran de vérification, vous pouvez voir l'image du document original côte à côte avec les données extraites. Votre équipe peut [corriger rapidement toute erreur], ajoutant l'intelligence humaine là où l'IA a eu des difficultés. Pour un lot typique, cette révision est incroyablement rapide car vous ne regardez que les exceptions signalées, pas les 10 000 documents. Pour le traitement de documents en masse, cette approche avec intervention humaine est essentielle pour maintenir une intégrité des données proche de 100 %. L'interface est optimisée pour la vitesse, permettant aux vérificateurs de naviguer entre les champs et d'utiliser des raccourcis clavier pour des corrections rapides. Une fois tous les documents vérifiés, il vous suffit de cliquer sur [Exporter vers Excel].
TabliSync ne vous donne pas seulement un flux brut de texte ; il fournit un classeur Excel magnifiquement structuré et multi-feuilles. Une feuille peut contenir les [données au niveau de l'en-tête] (Numéro de facture, Date, Nom du fournisseur), tandis qu'une autre feuille peut contenir tous les [articles détaillés] (SKU du produit, Description, Quantité, Prix), avec un identifiant unique les reliant. Cette structure relationnelle est inestimable pour l'analyse complexe et l'intégration ERP. De plus, vous pouvez configurer l'exportation pour utiliser des [types de données Excel] spécifiques (par exemple, formater les dates comme des dates et la devise comme des nombres), garantissant que les données sont prêtes à être utilisées immédiatement dans des tableaux croisés dynamiques ou des modèles financiers, sans nécessiter de nettoyage manuel.
L'impact stratégique : pourquoi le traitement OCR par lots vers Excel est une compétence de base, pas un ajout
Trop longtemps, les entreprises ont considéré le traitement des documents comme une tâche administrative de back-office, un centre de coûts nécessaire. C'est une erreur stratégique profonde. À l'ère numérique, votre capacité d'extraction automatisée de données à partir des documents non structurés qui alimentent votre entreprise est un [déterminant direct] de votre vitesse opérationnelle, de votre agilité financière et, finalement, de votre avantage concurrentiel. Maîtriser le traitement OCR par lots vers Excel ne consiste pas seulement à gagner du temps ; il s'agit de libérer la valeur latente au sein des données de votre organisation.
Considérez la valeur stratégique de disposer de [données financières quasi en temps réel]. Lorsque vous pouvez traiter 10 000 factures en quelques heures au lieu de quelques semaines, votre équipe des comptes fournisseurs ne réagit plus aux événements passés. Elle [gère activement les flux de trésorerie], optimise le fonds de roulement et profite des remises pour paiement anticipé. Votre équipe d'approvisionnement peut analyser les données ligne par ligne sur des milliers d'achats pour identifier les modèles de dépenses et négocier de meilleures conditions avec les fournisseurs. Vos équipes de conformité et d'audit disposent d'une [piste d'audit instantanée et vérifiable] pour chaque transaction, réduisant considérablement le coût et le risque associés aux audits. Ce niveau de réactivité n'est possible qu'avec une solution de traitement en masse robuste et de haute précision.
De plus, cette agilité des données est le fondement des initiatives d'analyse avancée et d'IA. Un [Grand Livre] mis à jour en temps réel avec des données ligne par ligne précises et détaillées devient un outil puissant pour la prévision et la planification stratégique. Vous pouvez alimenter ces données structurées dans des modèles d'apprentissage automatique pour prédire la demande, optimiser les niveaux de stock ou détecter les transactions frauduleuses. Les données non structurées cachées dans vos documents sont le carburant de votre transformation numérique, et **Batch OCR to Excel** est la raffinerie qui les rend utilisables. Ignorer cela revient à posséder un champ pétrolifère et refuser de construire un pipeline.
FAQ Approfondie : Aborder la Complexité de l'OCR vers Excel à Grande Échelle
Passer d'un processus manuel à une solution complexe et automatisée de **Batch OCR to Excel** soulève inévitablement des questions techniques et opérationnelles. Cette section FAQ s'appuie sur une expertise approfondie acquise lors du déploiement de centaines de projets d'automatisation de documents à grande échelle. Nous abordons non seulement le « comment », mais aussi le « pourquoi » et les « et si », fournissant la compréhension nuancée dont vous avez besoin pour un déploiement réussi et professionnel.
Quelle est la différence entre la détection de tableau et l'extraction de tableau ?
Ceci est une distinction essentielle qui est souvent négligée. La [détection] de tableau consiste simplement à identifier qu'un tableau existe sur une page et à tracer une boîte autour de celui-ci. De nombreux outils OCR génériques s'arrêtent là. L'[extraction] de tableau, cependant, est la tâche beaucoup plus complexe de comprendre la structure interne de ce tableau. Elle implique d'identifier avec précision les lignes, les colonnes, les en-têtes et les données précises dans chaque cellule, même si le tableau n'a pas de bordures ou des cellules complexes et fusionnées. Pour l'analyse des tableaux financiers, une extraction fiable est non négociable. TabliSync utilise une analyse avancée de la mise en page pour non seulement détecter le tableau, mais aussi pour recréer sa structure et ses données avec une grande fidélité dans Excel.
TabliSync peut-il gérer des documents numérisés, de mauvaise qualité ou inclinés ?
Oui, mais avec des mises en garde. Le moteur de TabliSync est très robuste et comprend des capacités automatiques de [prétraitement] d'images. Il peut redresser les documents, réduire le bruit et affiner le texte pour améliorer la reconnaissance. Notre OCR de haute précision est particulièrement efficace avec des mises en page complexes et une qualité d'impression variée. Cependant, la règle d'or de l'OCR s'applique toujours : [des données d'entrée médiocres donnent des résultats médiocres]. Les documents avec un flou extrême, une écriture manuscrite importante sur du texte critique, ou une résolution inférieure à [300 DPI] auront toujours une précision d'extraction plus faible. Dans ces cas, TabliSync signale le document pour vérification humaine afin de garantir qu'aucune donnée incorrecte ne se retrouve dans votre rapport Excel final.
TabliSync est-il conforme au RGPD et au CCPA ?
La confidentialité des données est primordiale, surtout lorsqu'il s'agit de documents financiers ou personnels. TabliSync est conçu avec une sécurité et une conformité de niveau entreprise en son cœur. Nous sommes pleinement conformes au RGPD, au CCPA et à d'autres réglementations majeures en matière de confidentialité des données. Toutes les données sont [chiffrées] au repos et en transit. De plus, nous proposons des fonctionnalités telles que la [rédaction] automatique des PII et des politiques de conservation des données configurables, vous garantissant un contrôle total sur la manière dont les informations sensibles sont traitées et stockées. Lorsque vous effectuez un traitement de documents en masse avec TabliSync, vous le faites sur une plateforme qui privilégie la sécurité et la conformité réglementaire.
Comment puis-je intégrer TabliSync à mon système ERP ou comptable existant ?
L'intégration transparente est essentielle pour une véritable automatisation. Bien que l'exportation vers Excel soit puissante, l'intégration directe est souvent le but ultime. TabliSync fournit une [API robuste et bien documentée] qui vous permet d'automatiser l'ensemble du pipeline. Vous pouvez utiliser l'API pour pousser des documents dans TabliSync, surveiller leur statut et extraire les données structurées et vérifiées directement dans votre système ERP ou comptable tel que NetSuite, Salesforce ou QuickBooks. Nous prenons également en charge les [Webhooks], de sorte que vos autres systèmes peuvent être instantanément notifiés lorsqu'un lot de traitement est terminé, déclenchant ainsi d'autres actions automatisées dans votre flux de travail.
Que se passe-t-il si l'IA ne parvient pas à extraire correctement un point de données critique ?
C'est là que l'étape de validation "human-in-the-loop" est cruciale. TabliSync ne se contente pas de deviner ; il fournit un score de confiance pour chaque point de données extrait. Si le score de confiance pour un champ critique (par exemple, 'Montant total') tombe en dessous d'un seuil que vous définissez, le document est automatiquement signalé et présenté dans l'[Interface de vérification]. Votre équipe peut alors rapidement examiner et corriger ce point spécifique. Cela garantit que seules des données vérifiées à 100 % et précises sont exportées vers votre fichier Excel final, maintenant ainsi la haute intégrité des données requise pour une **Réconciliation** professionnelle et des rapports financiers.
TabliSync peut-il traiter des documents de plusieurs pages où un tableau s'étend sur plusieurs pages ?
Oui, c'est une force principale de notre moteur de **parsing de tableaux financiers**. TabliSync peut suivre intelligemment les tableaux sur plusieurs pages. Il reconnaît les en-têtes de tableau sur la première page et comprend que les pages suivantes sont une continuation du même tableau, même si les en-têtes ne sont pas répétés. Il consolide toutes les données en un [tableau unique et continu] dans votre sortie Excel, préservant la structure relationnelle des données et vous faisant économiser des heures de travail de consolidation manuelle qui seraient autrement nécessaires.
Quel type d''exceptions' un humain doit-il gérer ?
Les exceptions ne concernent pas seulement une faible confiance OCR. Elles peuvent également impliquer [une validation de la logique métier]. Par exemple, TabliSync peut vérifier si la somme calculée des lignes extraites correspond au total de la facture extraite. Si ce n'est pas le cas, ce document devient une exception. Cela peut être dû à une erreur d'extraction réelle, ou à une erreur de calcul dans la facture du fournisseur elle-même. Les examinateurs humains se voient alors présenter le contexte pour résoudre rapidement le problème, soit en corrigeant l'extraction, soit en signalant le document à l'équipe financière pour qu'elle le traite avec le fournisseur.
Y a-t-il une limite au nombre de documents que je peux traiter dans un lot ?
Bien qu'il existe des limites pratiques pour un seul lot afin de maintenir des performances gérables, TabliSync est conçu pour une évolutivité massive. Pour de très grands ensembles de données, nous recommandons de diviser le traitement en lots logiques (par exemple, par fournisseur ou par mois). Nos niveaux d'entreprise sont conçus pour évoluer vers [des centaines de milliers, voire des millions] de documents par an. Pour des exigences exceptionnellement importantes et à haut volume, nous pouvons configurer des ressources de traitement dédiées pour garantir que vos flux de travail d'[extraction de données automatisée] répondent à vos SLA de vitesse et de volume précis.
Libérez une agilité et une efficacité de données sans précédent dès aujourd'hui
Vous avez maintenant exploré le paysage complet de la conversion OCR par lots vers Excel, des problèmes profonds du traitement manuel à l'exécution précise, étape par étape, sur une plateforme comme TabliSync. La capacité de convertir automatiquement et avec précision des montagnes de documents non structurés et multi-formats en données structurées et exploitables n'est plus un gain d'efficacité périphérique ; c'est un impératif commercial essentiel pour toute organisation visant l'excellence opérationnelle et l'agilité stratégique dans un monde axé sur les données. Les coûts de l'inaction — coûts de main-d'œuvre élevés, erreurs de données généralisées, délais d'exécution lents et manque total d'évolutivité — sont tout simplement trop élevés pour être ignorés.
Chaque minute que votre équipe passe sur la saisie manuelle de données est une minute [volée] à l'analyse de haute valeur, au rapprochement des fournisseurs et à la planification financière stratégique. Le paysage concurrentiel n'attendra pas que vous modernisiez votre traitement de documents. Les organisations qui adoptent dès maintenant l'extraction automatisée de données jettent les bases d'une agilité opérationnelle qui portera ses fruits pendant des années. Ne laissez pas vos données commerciales critiques rester piégées dans du papier ou des fichiers numériques fragmentés. Prenez le contrôle de votre flux de données et propulsez votre organisation vers l'avant. Nous sommes tellement convaincus de la capacité de TabliSync à transformer vos flux de travail que nous vous invitons à en faire l'expérience directe. Cessez de laisser les goulots d'étranglement manuels vous freiner. Inscrivez-vous dès aujourd'hui pour votre essai gratuit de TabliSync et constatez la puissance immédiate et transformatrice de la OCR de haute précision. L'avenir de votre agilité de données commence maintenant, ne tardez pas.
Tous les Articles OCR par lot vers Excel(11)

Comment dupliquer une feuille dans Excel : Guide étape par étape
Ce guide fournit des instructions étape par étape sur la façon de dupliquer une feuille dans Excel, aidant les utilisateurs à gérer leurs feuilles de calcul de manière efficace et précise. Que vous travailliez avec des rapports financiers, des feuilles d'inventaire ou toute autre donnée, la duplication de feuilles peut vous faire gagner du temps et assurer la cohérence. Suivez nos instructions claires pour maîtriser cette compétence essentielle d'Excel. À la fin de ce guide, vous serez en mesure de dupliquer des feuilles en toute confiance et de garder votre travail organisé. N'oubliez pas d'explorer comment TabliSync peut améliorer davantage vos tâches de gestion de feuilles de calcul une fois que vous aurez acquis cette compétence!

Dépannage des formules verrouillées dans Excel
Ce guide de dépannage fournit aux utilisateurs des solutions pratiques pour déverrouiller les formules dans Excel, en abordant les problèmes courants et en offrant des conseils pour prévenir les problèmes futurs. Les formules verrouillées peuvent constituer un obstacle important pour les utilisateurs professionnels, en particulier ceux des services financiers et administratifs qui dépendent de la manipulation précise des données. Grâce à une approche étape par étape, cet article aide les lecteurs à comprendre les causes des formules verrouillées et propose des stratégies efficaces pour résoudre ces problèmes. En mettant en œuvre les solutions décrites ici, les utilisateurs peuvent reprendre le contrôle de leurs feuilles de calcul, s'assurant ainsi qu'ils peuvent modifier et gérer efficacement leurs données sans frustration inutile. L'article souligne également les meilleures pratiques pour prévenir de tels problèmes à l'avenir, contribuant ainsi à des flux de travail de feuilles de calcul plus fluides et plus efficaces, et permettant aux utilisateurs de se concentrer entièrement sur la gestion précise des données.

Comment ajouter un menu déroulant à Excel
La saisie manuelle répétitive des données entraîne souvent des données incohérentes et une faible efficacité de travail pour le personnel utilisant Excel. Cet article explique les difficultés de création de listes déroulantes dans Excel et présente deux solutions, notamment la configuration manuelle et les méthodes d'extraction automatisée des données. Il couvre également les étapes d'exploitation détaillées, les vérifications clés avant exportation, les erreurs de configuration courantes et les FAQ. La création de listes déroulantes standardisées unifie efficacement les normes de saisie des données, réduit les erreurs manuelles et optimise les flux de travail de traitement des données de bureau quotidiennes et les rapports financiers.

Comment ajouter des puces dans Excel
"Ce guide fournit des instructions étape par étape pour ajouter des puces dans Excel à l'aide de raccourcis clavier et du menu Ruban, accompagnées d'exemples pratiques de leur utilisation dans des documents professionnels et de conseils pour un formatage efficace afin d'améliorer la lisibilité globale."

Comment utiliser les raccourcis clavier pour coller les valeurs afin de nettoyer des données de feuilles de calcul complexes
Réduisez le temps de nettoyage des données jusqu'à 80 % en utilisant les raccourcis clavier pour coller les valeurs au lieu de supprimer manuellement le formatage. Éliminez les erreurs de formatage cachées, les formules brisées et les types de données incohérents à partir de jeux de données importés ou existants. Maintenez un pipeline de données propre et reproductible sans macros ni VBA — juste des frappes Excel natives. Reliez les flux de données structurés et non structurés en combinant le collage de valeurs avec des outils d'extraction comme TabliSync.

Comment utiliser les puces dans Excel pour des tables de données propres
Ce guide couvre deux méthodes efficaces pour ajouter et nettoyer des puces dans Excel pour des tables de données structurées et analysables. Il explique les flux de travail intégrés d'Excel, y compris les raccourcis clavier, les fonctions CHAR, Power Query et les Tableaux Excel pour des tâches de formatage ponctuelles simples. Il présente également la solution TabliSync basée sur l'IA pour extraire, normaliser et organiser automatiquement des listes à puces désordonnées à partir de PDF, de captures d'écran et de rapports externes en lignes Excel propres, résolvant ainsi les problèmes courants de nettoyage de données et optimisant les flux de travail récurrents de données métier pour le filtrage, l'analyse et la création de tableaux de bord.

IA : Comment séparer le prénom et le nom de famille dans Excel
Éliminez les erreurs de séparation manuelle des noms grâce à l'analyse pilotée par l'IA, réduisant le temps de nettoyage des données jusqu'à 85 %. Automatisez l'extraction des prénoms et noms de famille à partir de PDF et de rapports basés sur des images, économisant plus de 10 heures par semaine par analyste. Maintenez un formatage de nom cohérent sur tous les ensembles de données grâce à la synchronisation en temps réel, réduisant les échecs de rapprochement en aval de 90 %.

Comment verrouiller des cellules dans Excel : Protéger des données spécifiques contre les modifications
Implémentez une protection granulaire des cellules pour garantir 0 % d'erreurs de remplacement manuel de formules. Maîtrisez le flux de travail de verrouillage et de protection en deux étapes pour économiser 90 % du temps passé à l'audit des feuilles de calcul. Exploitez la synchronisation OCR pilotée par l'IA pour transformer les données non structurées en actifs commerciaux verrouillés et immuables.

Comment supprimer les doublons et les originaux dans Excel : un guide étape par étape
Éliminer 100 % du bruit : maîtrisez la technique pour supprimer non seulement les doublons, mais aussi les entrées d'origine, ne laissant que des données véritablement uniques. Gain de temps de 90 % : passez de l'audit manuel ligne par ligne aux flux de travail automatisés de nettoyage de données. 0 % d'erreur de saisie manuelle : tirez parti de l'OCR par IA pour analyser des données non structurées dans des schémas propres sans intervention humaine. Hygiène des données évolutive : mettez en œuvre des stratégies de valeurs uniques Excel de haut niveau qui gèrent sans effort des ensembles de données dépassant 100 000 lignes.

Classeur Excel Erreur : Désolé, nous n'avons pas trouvé le guide de solution
* Corrigez instantanément les erreurs de démarrage d'Excel en identifiant les chemins temporaires locaux cachés. * Réduisez le temps de dépannage manuel de 90 % grâce à la validation automatisée des chemins. * Atteignez 0 % d'erreurs de saisie manuelle en migrant des données non structurées via OCR IA. * Transformez les liens de fichiers brisés en actifs de données résilients synchronisés dans le cloud.

Comment déverrouiller/déprotéger une feuille Excel sans connaître le mot de passe
Débloquez des feuilles Excel sans mot de passe avec 99,9 % d'intégrité des données ; Réduisez le temps de récupération manuel de 90 % ; Exécution transparente des macros XML et VBA ; OCR basé sur l'IA pour l'extraction de données structurées.
Fini la saisie manuelle – Extrayez des tableaux en quelques secondes
Convertissez instantanément n'importe quelle image ou tableau PDF en Excel avec une précision de 99,9%. L'OCR IA de TabliSync traite les formulaires manuscrits, les reçus et les tableaux complexes, puis synchronise directement avec Google Sheets, Notion ou Airtable
Essayez TabliSync gratuitement maintenant