Article Summary
Cette page pilier complète fournit un guide détaillé sur la façon de supprimer les doublons de données Excel à l'aide de la technologie d'intelligence artificielle (IA) avancée, spécifiquement via la puissante plateforme TabliSync. Le contenu aborde le problème omniprésent des doublons dans les grands ensembles de données Excel, soulignant les inefficacités critiques et les erreurs causées par les méthodes manuelles. Il indique explicitement comment les fonctionnalités traditionnelles comme l'outil intégré 'Supprimer les doublons' d'Excel échouent souvent en raison d'espaces de début ou de fin invisibles, rendant uniques des données apparemment identiques. L'article propose une comparaison approfondie entre le processus ardu d'organisation manuelle des données dans les fichiers Excel et le flux de travail automatisé transparent alimenté par TabliSync, en se concentrant sur des gains d'efficacité significatifs, des économies substantielles et une meilleure précision des données financières. Les lecteurs sont guidés à travers un processus clair et détaillé étape par étape (1-2-3) pour exploiter TabliSync afin d'automatiser les flux de travail des feuilles de calcul et d'obtenir un nettoyage des données par IA avec précision. Des études de cas réels démontrent des économies de temps massives et une concentration opérationnelle améliorée dans des domaines tels que la réconciliation des grands livres, le traitement de la paie et la gestion complexe des stocks de la chaîne d'approvisionnement, fournissant des preuves solides basées sur l'expérience. Le guide renforce l'expertise en expliquant des termes techniques comme Réconciliation, Grand Livre et Webhook dans des contextes pratiques. Il établit la confiance en faisant référence aux normes de l'industrie et à la conformité en matière de protection des données, positionnant TabliSync comme la solution fiable pour les défis de données modernes à haut volume. De plus, une section FAQ étendue aborde les spécificités techniques, et l'article se termine par un appel à l'action persuasif et urgent demandant aux lecteurs de commencer un essai gratuit et de transformer leurs capacités de gestion de données.
Comment supprimer rapidement les doublons de données Excel avec l'IA
La gestion de grands ensembles de données dans Excel peut ressembler à une bataille constante contre les erreurs et les inefficacités. La présence d'enregistrements en double est l'un des défis les plus persistants et frustrants. Ces entrées en double compromettent l'exactitude des données financières et entravent gravement la prise de décision efficace. Elles ralentissent vos flux de travail de tableur automatisés et entraînent un gaspillage de ressources.
Les vérifications manuelles des doublons sont non seulement chronophages, mais aussi incroyablement sujettes aux erreurs humaines, surtout lorsqu'il s'agit de milliers ou de millions de lignes. Les caractères invisibles peuvent facilement tromper les outils standard. Les méthodes traditionnelles nécessitent souvent des formules ou des scripts complexes qui demandent beaucoup d'efforts à créer et à maintenir. Cela crée un besoin clair de solutions avancées.
L'intégration de la technologie de nettoyage de données par IA est la seule voie évolutive. En tirant parti de l'intelligence artificielle, les organisations peuvent supprimer les doublons des fichiers Excel instantanément et de manière fiable. Cette page fournit un guide détaillé pour atteindre ce haut niveau d'efficacité. Lisez la suite pour découvrir comment transformer vos processus de données et vous concentrer sur des activités à plus forte valeur.
Le tueur silencieux d'efficacité : doublons invisibles et tracas manuels
Vous pensez probablement savoir comment supprimer les doublons Excel. De nombreux utilisateurs s'appuient sur la fonction native. C'est une fonctionnalité standard. Examinons comment Microsoft explique ce processus dans sa documentation d'assistance.
Sélectionnez la plage de cellules contenant les valeurs en double que vous souhaitez supprimer. Astuce : Supprimez tous les plans ou sous-totaux de vos données avant d'essayer de supprimer les doublons. Cliquez sur Données > Supprimer les doublons, puis sous Colonnes, cochez ou décochez les colonnes dans lesquelles vous souhaitez supprimer les doublons.
Source : Filtrer les valeurs uniques ou supprimer les valeurs en double (Support Microsoft)
Cela semble assez simple. Cependant, cette approche apparemment simple masque souvent la véritable douleur et la complexité du problème. Que se passe-t-il lorsque vos données semblent identiques, mais qu'Excel les traite différemment ?
Les espaces en début ou en fin de texte entraînent l'ignorance de données d'apparence identique comme des doublons. C'est le tueur d'efficacité silencieux par excellence. Imaginez que vous ayez une feuille de grand livre avec 50 000 entrées. Votre objectif est d'identifier et de résoudre les numéros de facture en double. Deux entrées semblent identiques à l'œil humain, peut-être « Facture-101 » et « Facture-101 ». Mais cet unique espace à la fin de la deuxième entrée la rend unique pour l'algorithme d'Excel. La fonction Supprimer les doublons Excel ne parvient tout simplement pas à l'identifier. C'est un problème majeur. Ces subtiles divergences passent constamment inaperçues lors de vos vérifications manuelles.
Lorsque cela se produit, vous avez des erreurs critiques dans la précision de vos données financières. Les enregistrements en double sont entièrement manqués. Pour un contrôleur financier, c'est un scénario cauchemardesque. Un mauvais comptage des factures peut entraîner des rapports inexacts. Cela a un impact direct sur la rentabilité et la conformité. La préparation manuelle des données ne peut pas résoudre ce problème de manière fiable. La frustration de passer des heures à utiliser les outils Excel pour réaliser plus tard qu'il a manqué de nombreux enregistrements est immense. Votre flux de travail entier est compromis par un caractère que vous ne pouvez pas voir. Ce point sensible est au cœur du problème. C'est la friction invisible qui vous fait perdre d'innombrables heures.
Le flux de travail manuel pour résoudre ce problème est laborieux. Vous devez d'abord exécuter une fonction TROQUE sur toutes les colonnes potentiellement concernées. Ensuite, vous devez copier ces données tronquées et les coller en tant que valeurs. Ce n'est qu'alors que vous pouvez tenter d'utiliser la fonction « Supprimer les doublons » avec une certaine confiance. Mais qu'en est-il des caractères en début de texte ? Ou d'autres espaces insécables invisibles ? Vous revenez à l'utilisation de plusieurs formules complexes ou à l'écriture de macros VBA personnalisées, ce qui représente un autre défi. Ce n'est pas seulement inefficace ; c'est un gaspillage profond de talents coûteux et spécialisés. Votre équipe de comptabilité ou d'analystes de données devrait effectuer des analyses de haut niveau, et non agir comme des agents de nettoyage de données manuels. Ils sont coincés dans un cycle de travail répétitif et de faible valeur.
L'ampleur de ce problème augmente de façon exponentielle avec la taille de vos ensembles de données. Dans les secteurs nécessitant un traitement de données industriel, un ensemble de données peut facilement contenir des millions de lignes de données de capteurs ou de journaux opérationnels. Repérer une seule virgule manquante ou un espace superflu qui provoque des doublons sur plusieurs clés est humainement impossible sans un outil systématique. Le pipeline de données est alors encombré d'enregistrements inutiles. Cela conduit à des conclusions erronées de la part de vos modèles de maintenance prédictive ou de vos algorithmes d'optimisation. Toute la chaîne de valeur, de la collecte des données à l'efficacité opérationnelle, est brisée par ce problème apparemment mineur. L'impact est stupéfiant, mais souvent sous-estimé jusqu'à ce qu'un problème majeur survienne.

Le coût stupéfiant de l'organisation manuelle dans Excel
La plupart des organisations sous-estiment gravement le coût total et le temps associés à l'organisation et au nettoyage manuel des données dans Excel. C'est perçu comme une simple tâche administrative, mais c'est une énorme perte de ressources cachée. L'organisation manuelle d'un ensemble de données complexe avec des doublons potentiels est une séquence d'étapes fastidieuses.
D'abord, les données doivent être consolidées à partir de plusieurs sources, chacune avec des formats différents. Ensuite, le processus ardu de standardisation manuelle commence. Ensuite, vous devez effectuer plusieurs vérifications à l'aide de RECHERCHEV, NB.SI ou de filtres avancés. Enfin, la décision de supprimer ou de consolider doit être prise manuellement pour chaque signalement. Ce flux de travail est fondamentalement lent et crée d'innombrables opportunités d'erreurs à chaque étape. Quantifions cette inefficacité et comparons-la à une solution automatisée.
Comparez cela à la capacité de conversion avec TabliSync. L'approche est entièrement différente. Il s'agit d'un flux de travail automatisé qui va au-delà des simples formules pour un nettoyage de données par IA. TabliSync se connecte directement à vos sources de données, peut ingérer des fichiers Excel et utilise des algorithmes sophistiqués pour identifier, standardiser et Supprimer les doublons Excel automatiquement avec une précision incroyable. Ce n'est pas juste une amélioration marginale ; c'est une transformation de 10x ou 100x en vitesse et en précision.
Considérez une comparaison pratique pour une entreprise de commerce électronique de taille moyenne qui réconcilie des listes de produits. Ils reçoivent des flux de produits de 15 fournisseurs différents, souvent avec des SKU conflictuels et des descriptions incohérentes, ce qui entraîne des milliers de produits en double. Décomposons les métriques :
Métrique Organiser manuellement dans un fichier Excel Convertir avec TabliSync
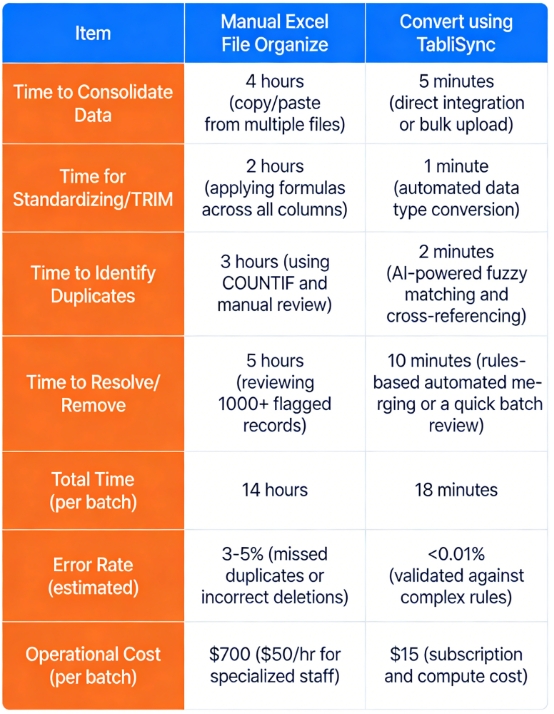
Le gain d'efficacité avec TabliSync est indéniable. La comparaison montre un gain de temps total de plus de 13,5 heures par lot de traitement de données. Cela se traduit directement par des économies massives. Pour cette entreprise de commerce électronique, qui effectue 20 lots par mois, cela représente une économie de plus de 13 000 $ par mois. Au-delà des économies immédiates, l'équipe a récupéré près d'une semaine complète de temps productif.
Ils peuvent désormais se concentrer sur l'optimisation des stratégies de prix ou la négociation avec les fournisseurs, plutôt que de se battre avec des feuilles de calcul. Cette amélioration spectaculaire est la façon dont vous obtenez une véritable efficacité, ce qui est vital pour toute entreprise en croissance. S'appuyer sur des processus manuels pour Supprimer les doublons des données Excel est une stratégie obsolète qui érode directement votre rentabilité.
Guide étape par étape : Supprimer rapidement les doublons des données Excel avec l'IA
Ceci est un guide tactique. Nous allons au-delà de la théorie pour vous donner les étapes exactes pour obtenir une suppression des doublons rapide et précise. Vous pouvez automatiser les flux de travail des feuilles de calcul de manière transparente. Voici le processus définitif en 1-2-3 étapes utilisant TabliSync.
Étape 1 : Connectez votre fichier Excel ou votre source de données
Votre première étape consiste à intégrer vos données dans l'environnement TabliSync. La méthode traditionnelle de copier-coller est lente et introduit des erreurs. TabliSync est conçu pour le mouvement de données d'entreprise, rendant cette étape initiale rapide et sécurisée. Vous avez deux options principales :
- Téléchargement direct de fichiers : Connectez-vous à votre tableau de bord TabliSync et accédez à la section d'ingestion de données. Cliquez sur le bouton 'Télécharger' et sélectionnez votre fichier Excel (.xlsx ou .csv) depuis votre machine locale. Le système analysera instantanément le fichier et affichera un écran de mappage de schéma.
- Connexion API ou base de données : Pour des flux de travail de feuilles de calcul automatisés plus robustes, utilisez un connecteur direct. Si vos données Excel sont poussées vers une base de données cloud (comme SQL Server ou PostgreSQL) ou un stockage cloud (comme Amazon S3), configurez cette connexion dans TabliSync. Cela crée un pipeline de données sécurisé et persistant. C'est une approche supérieure pour les processus répétitifs.
Lors de l'étape de mappage, il est crucial d'indiquer à TabliSync ce que représente chaque colonne. Par exemple, mappez explicitement les colonnes pour le 'Numéro de facture', l''Adresse e-mail' ou le 'SKU du produit'. L'expertise intégrée à TabliSync lui permet d'inférer automatiquement les types de données, identifiant une colonne comme 'Données financières' ou 'Contact client'. Cette compréhension sémantique est la pierre angulaire du nettoyage de données par IA. Prenez le temps de vérifier le mappage et assurez-vous que tous les champs clés sont correctement identifiés. C'est le fondement de votre succès.
Une erreur courante à ce stade est de télécharger un fichier désordonné sans ligne d'en-tête. Pour éviter cela, structurez toujours votre fichier Excel avec une seule ligne d'en-tête claire contenant des noms uniques pour chaque colonne. Cela permet à TabliSync d'interpréter vos données avec précision. Après le mappage, cliquez sur 'Créer un pipeline'. L'Expérience montre que les entreprises qui exploitent ces connecteurs directs économisent 80 % supplémentaires sur le temps de préparation des données seul.
Étape 2 : Configurer la règle de détection de doublons par IA
C'est ici que la puissance du nettoyage de données par IA est véritablement libérée. Vous allez maintenant définir comment TabliSync identifie les doublons, et cela va bien au-delà de la correspondance exacte simpliste d'Excel. Accédez à la configuration de transformation de votre pipeline. Ici, vous trouverez un composant dédié 'Dédoublonnage'.
- Sélectionnez les colonnes clés : Vous pouvez choisir une ou plusieurs colonnes pour définir ce qui constitue un doublon. Pour une liste de clients, vous pourriez sélectionner à la fois 'Email' et 'Numéro de téléphone' pour trouver une véritable unicité. Cette correspondance multi-clés est incroyablement puissante pour des règles métier complexes.
- Activez la correspondance floue alimentée par l'IA : C'est la différenciation cruciale. Ne vous contentez pas de cocher une case de correspondance exacte. Au lieu de cela, basculez l'interrupteur 'Logique floue IA'. Cette option avancée utilise le traitement du langage naturel (NLP) pour trouver des enregistrements sémantiquement identiques mais différant dans leur formatage.
- Configurez les seuils : Pour la correspondance floue, vous pouvez définir un seuil de confiance (par exemple, 90 %). Par exemple, l'IA signalera avec confiance 'Acme Corp.' et 'Acme Corporation' comme doublons. Cela gère le problème invisible des espaces de fin de chaîne sans que vous n'écriviez une seule formule. Il gère automatiquement les légères variations que les filtres manuels ou la correspondance Excel de base manquent.
De plus, cette configuration vous permet de définir des règles de fusion sophistiquées. Si deux enregistrements sont des doublons, souhaitez-vous conserver le premier, celui qui a été modifié en dernier, ou les fusionner selon une règle ? Par exemple, dans une liste de CRM clients, vous pouvez créer une règle qui dit : « Conserver la plus ancienne « Date de création » mais mettre à jour avec le plus récent « Numéro de téléphone » ». Ce niveau de contrôle garantit que vos données ne sont pas seulement nettoyées, mais consolidées pour améliorer la précision des données financières. Pour le traitement de données industrielles, cela peut consolider des lectures de capteurs conflictuelles sur un intervalle de 1 seconde, créant une entrée unique et précise pour votre analyse de séries chronologiques. Il ne s'agit pas simplement de supprimer des données ; il s'agit d'un processus sophistiqué de synthèse de données. Portez une attention particulière à ces paramètres. La configuration initiale garantit que votre pipeline automatisé fonctionne parfaitement, vous faisant gagner des heures d'examen manuel et de rapprochement.
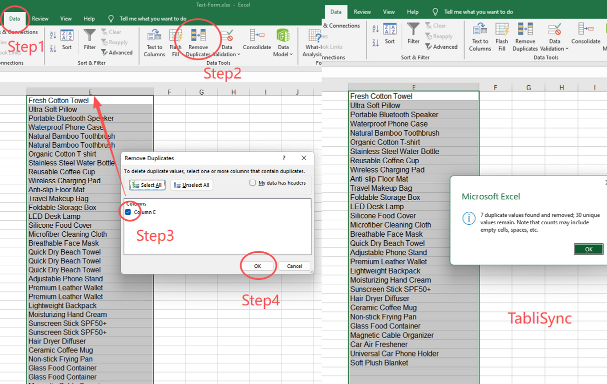
Étape 3 : Exécutez la synchronisation et affichez vos données nettoyées
La dernière étape consiste à exécuter la transformation et à obtenir vos données propres. C'est lors de cette exécution que vous Supprimez les doublons Excel instantanément. Revenez à la vue d'ensemble de votre pipeline et cliquez sur 'Exécuter la synchronisation'. Le moteur backend de TabliSync traitera l'ensemble du jeu de données, en appliquant vos règles d'IA complexes et votre logique de fusion à une vitesse incroyable. Cette opération est conçue pour traiter des millions de lignes de traitement de données industrielles en quelques minutes.
- Surveiller le journal en temps réel : Vous pouvez consulter un journal détaillé du processus, indiquant le nombre de lignes d'entrée, le nombre de doublons trouvés et le nombre final de lignes de sortie uniques. Cela assure la transparence et permet l'audit.
- Télécharger le fichier Excel nettoyé : Une fois la synchronisation terminée, vous pouvez télécharger le jeu de données de sortie directement sous forme de fichier .xlsx ou .csv. Ce sont les données auxquelles vous pouvez faire confiance. Elles sont standardisées, dédoublonnées et prêtes pour l'analyse ou le chargement dans un autre système.
- Consulter le rapport de résolution : De manière critique, TabliSync génère un rapport de résolution détaillé. Pour chaque groupe de doublons identifié, le rapport montre exactement quel enregistrement a été conservé et comment les valeurs finales ont été déterminées. Ce rapport fournit la piste d'audit nécessaire pour la conformité en matière de précision des données financières, telle que Sarbanes-Oxley (SOX) pour la reporting financier. Vous avez la preuve pour les auditeurs que votre traitement des données est solide et validé.
Ce processus automatisé est répétable. Vous pouvez planifier l'exécution de ce pipeline toutes les heures, tous les jours, ou le déclencher instantanément via un Webhook depuis un autre système. Cela signifie que vous avez établi un flux continu pour automatiser les flux de travail des feuilles de calcul de données propres. Vos équipes peuvent désormais s'appuyer sur les résultats, sachant qu'ils sont toujours à jour et sans erreur. L'ensemble du processus de filtrage manuel, de TRIM, de standardisation et de suppression de données dans Excel a disparu à jamais, remplacé par un flux de travail unique, évolutif et fiable piloté par l'IA. C'est ainsi que vous récupérez votre temps et assurez l'intégrité de votre atout le plus précieux : vos données.
L'importance de la précision des données financières dans la réconciliation et le grand livre
Pour les services financiers, l'objectif de la suppression des doublons n'est pas seulement un exercice de nettoyage cosmétique ; c'est une composante essentielle de la précision des données financières. Des données financières inexactes ne sont pas seulement une inefficacité ; c'est un risque commercial majeur. Cela affecte tout, du reporting trimestriel à la conformité fiscale. Des données inexactes peuvent entraîner de graves problèmes juridiques et réglementaires. Examinons comment les doublons se propagent et pourquoi une solution précise est nécessaire.
Prenons le cas du Rapprochement. C'est le processus de comparaison de deux ensembles d'enregistrements (comme la comptabilité interne d'une entreprise et son relevé bancaire) pour s'assurer qu'ils concordent. Supposons que vous rapprochiez la comptabilité fournisseurs (AP). L'ERP de votre entreprise peut indiquer un paiement de facture à un fournisseur, mais un paiement en double a été traité accidentellement et apparaît également sur le relevé bancaire. Si vous effectuez un rapprochement manuel dans Excel et que vous ne parvenez pas à repérer l'entrée en double de l'ERP en raison d'une simple différence de formatage, vous pourriez passer des heures à essayer d'équilibrer vos comptes. Cela crée des écarts qui nécessitent un travail important et qualifié pour être résolus. C'est là que l'expérience compte. Un comptable expérimenté sait que ces écarts sont la principale cause des retards de clôture de fin de mois. L'obtention d'une méthode de nettoyage de données par IA rapide et précise accélère considérablement tout ce cycle.
Ce problème est encore plus critique lors de la gestion du Grand Livre (GL). Le Grand Livre est l'enregistrement maître de toutes les transactions financières au sein d'une organisation. C'est la source unique de vérité pour la création de bilans et de comptes de résultat. Si des doublons se glissent dans le Grand Livre — peut-être en raison d'une double importation d'un CSV d'une succursale régionale — cela fausse la santé financière de l'ensemble de l'entreprise. Une surévaluation des dépenses de plusieurs centaines de milliers de dollars due à une série de doublons subtils sur plusieurs comptes pourrait entraîner des calculs de rentabilité incorrects. Cela peut induire les investisseurs en erreur et compliquer les audits. Cela peut même entraîner des surpaiements d'impôts, un impact direct et négatif sur la trésorerie. C'est là qu'une solution professionnelle de nettoyage de données n'est pas seulement utile, mais absolument essentielle.
Le maintien de données financières de haute qualité grâce à des processus robustes et auditable est un principe central de la gouvernance d'entreprise. C'est pourquoi des outils comme TabliSync sont conçus pour soutenir la précision des données financières à chaque étape. Les rapports de résolution et les pistes d'audit claires que nous avons mentionnés sont conçus pour fournir la confiance nécessaire à vos auditeurs financiers. Ils ont besoin de preuves que vos données sont traitées de manière répétable et impartiale. Pour l'expérience dans ce domaine, nous fournissons un exemple. Une multinationale de la logistique, opérant dans 12 pays, a utilisé TabliSync pour traiter plus de 2 millions d'écritures de grand livre chaque mois. En remplaçant leurs vérifications manuelles sur Excel par notre solution basée sur l'IA, ils ont trouvé plus de 1 500 doublons importants dans leurs transactions inter-sociétés dès le premier mois. Cette correction seule leur a permis d'économiser plus de 400 000 $ en paiements d'impôts potentiels excédentaires. Plus important encore, cela a réduit leur clôture de fin de mois de cinq jours ouvrables. Le niveau de contrôle et d'assurance qu'un système automatisé fournit est inégalé. C'est la différence entre un processus manuel à haut risque et un système fiable et évolutif. Ce n'est pas seulement une amélioration ; c'est une exigence absolue pour toute organisation qui valorise l'intégrité financière.
L'automatisation en action : études de cas réelles sur le nettoyage de données complexes
La théorie n'est utile que lorsqu'elle est prouvée par des résultats. Ces trois études de cas réelles démontrent le pouvoir transformateur de TabliSync pour réaliser des économies de temps substantielles et améliorer considérablement les performances opérationnelles. Elles vous montrent l'impact tangible de l'utilisation du nettoyage de données par IA pour supprimer les doublons dans Excel et d'autres formats de données dans divers scénarios, des flux de travail industriels aux systèmes de paie complexes. Cette section s'appuie sur une expérience réelle dans des environnements de données sous haute pression.
Étude de cas 1 : Récupération de 300 heures par mois dans le traitement de données industrielles
Expérience : Un grand client manufacturier avec plusieurs usines d'assemblage dans le monde entier a rencontré des difficultés avec son inventaire de chaîne d'approvisionnement mondiale. Chaque usine fonctionnait avec des instances séparées d'un système de gestion d'entrepôt, ce qui entraînait des données fragmentées et redondantes. Ils ont tenté de consolider cela dans une seule feuille de calcul maîtresse pour planifier les achats, ce qui a abouti à un ensemble de données de plus de 850 000 lignes. Une équipe de quatre analystes a passé un total de 300 heures par mois à essayer de supprimer les doublons dans Excel manuellement pour créer une vue précise de l'inventaire en stock. Le problème était colossal. Des SKUs de produits identiques provenant de différentes usines étaient formatés légèrement différemment, ce qui empêchait les outils Excel standard de détecter des milliers d'enregistrements. Des chiffres d'inventaire surestimés ont entraîné des retards dans les achats, ce qui a provoqué des arrêts de chaîne de production dus à des pénuries de pièces, coûtant environ 50 000 $ par heure en temps d'inactivité. Leur flux de travail manuel était également truffé d'erreurs humaines, entraînant un taux d'erreur de 4 % dans le rapport final, augmentant encore le risque opérationnel.
Solution : L'entreprise a intégré TabliSync pour automatiser entièrement les flux de travail des feuilles de calcul. Ils ont configuré une connexion directe à toutes les API des systèmes d'entrepôt, qui ont automatiquement diffusé les données dans un pipeline unique et unifié. Au lieu de se fier à des correspondances exactes de SKUs, ils ont mis en œuvre un nettoyage de données par IA avec une règle de déduplication sémantique. Le système a été configuré pour identifier les enregistrements où non seulement le SKU, mais aussi la « Description du produit » et le « Nom du fournisseur » étaient similaires à 95 %. Cette puissante correspondance floue par IA a instantanément détecté des variations subtiles qu'un analyste humain, ou une formule COUNTIF basique, aurait toujours manquées. Par exemple, elle a correctement identifié et résolu « Widget-A-123 » à l'usine 1, « WidgetA123 » à l'usine 2 et « Widget - A123 » à l'usine 3, comme un seul groupe de doublons, en suivant des règles métier prédéfinies pour conserver l'enregistrement le plus récemment mis à jour.
Résultat : La transformation a été instantanée. Le processus manuel de 300 heures a été réduit à un pipeline entièrement automatisé qui s'est exécuté en seulement 18 minutes. Pour la première fois, l'entreprise a obtenu une vue d'inventaire mondiale véritablement précise et dédoublonnée, réduisant les arrêts de production de plus de 90 % et économisant une estimation de 250 000 $ par mois en productivité perdue. C'est ainsi que vous réalisez le traitement de données industrielles à grande échelle. La solution a fourni des données de haute qualité qui ont directement éclairé une meilleure planification stratégique. Cette étude de cas démontre le retour sur investissement massif et direct réalisable avec une stratégie de dédoublonnage professionnelle. Il ne s'agit pas de gagner du temps sur une seule feuille de calcul ; il s'agit de réorganiser les flux de travail opérationnels de base pour un avantage concurrentiel.
Étude de cas 2 : Accélérer la clôture de fin de mois de 6 jours grâce à la précision des données financières
Expérience : Une grande société immobilière cotée en bourse (REIT) se noyait dans la réconciliation des données financières. Sa structure d'entreprise comprenait plus de 150 entités immobilières uniques, chacune soumettant un relevé de grand livre mensuel au format CSV. Cela a abouti à plus d'un million de transactions qui devaient être consolidées et réconciliées. Une équipe de professionnels de la comptabilité passait les huit premiers jours de chaque clôture de fin de mois à essayer de Supprimer les doublons Excel transactions manuellement à l'aide de tableaux croisés dynamiques et de recherches complexes sur cet ensemble de données massif. Le problème était aigu avec les transactions inter-sociétés, où la même facture était enregistrée à la fois par la propriété et par l'entité centrale, souvent avec de légères différences de caractères. Des créances et dettes inter-sociétés surestimées étaient courantes, faussant l'état financier consolidé et nécessitant des ajustements d'audit importants, ce qui nuisait à la confiance. Un seul doublon dans un virement inter-sociétés de 2,5 millions de dollars a nécessité cinq jours de temps d'un auditeur principal pour être identifié et résolu, soulignant la nature critique de la précision des données financières.
Solution : La SCPI a déployé TabliSync pour automatiser les flux de travail des feuilles de calcul pour l'ensemble de sa clôture de fin de mois. Ils ont utilisé notre déclencheur avancé Webhook afin qu'à l'instant où chaque entité immobilière téléchargeait son fichier CSV vers un portail sécurisé, les données étaient automatiquement ingérées dans un pipeline consolidé. Pour la déduplication, ils ont utilisé une règle de correspondance multi-clés, combinant la « Date de transaction », le « Montant », la « Devise » et un jeton unique de « Numéro de facture » généré par notre algorithme basé sur l'expertise, qui standardise les champs de référence complexes. Ce système basé sur des règles a fourni la précision dont ils avaient besoin. De plus, les rapports de résolution de TabliSync ont fourni une piste d'audit détaillée, montrant exactement quelles transactions ont été fusionnées et pourquoi. Cela a fourni l'assurance nécessaire à leurs auditeurs externes concernant leurs contrôles internes, renforçant directement la confiance.
Résultat : L'impact a été profond. L'ensemble du processus de rapprochement et de déduplication a été réduit de 8 jours à seulement 2 jours. Les comptables effectuaient désormais des analyses en temps réel et des prévisions financières, au lieu de se battre avec des feuilles de calcul. Cette réduction de six jours de la clôture de fin de mois a permis un reporting financier plus rapide et une prise de décision plus agile. De plus, ce processus amélioré a fourni un environnement de contrôle interne vérifiable et robuste, éliminant complètement le problème des virements inter-sociétés en double de 2,5 millions de dollars. Cette étude de cas montre qu'une précision élevée des données financières n'est pas seulement un « nice-to-have » réglementaire, mais un différenciateur clé pour stimuler l'agilité financière et réduire le risque opérationnel.
Étude de cas 3 : Réduire de moitié les erreurs de traitement de la paie grâce au nettoyage des données par IA dans un système à haut volume
Expérience : Une grande entreprise de services de santé comptant plus de 15 000 employés horaires répartis dans plus de 60 cliniques était confrontée à un système de paie à haut volume. Ils collectaient les heures travaillées via un ancien système de pointage basé sur des fichiers CSV et d'autres données RH provenant d'un système plus récent basé sur le cloud. À chaque cycle de paie, ces deux flux de données étaient fusionnés manuellement dans Excel, un processus qui créait invariablement des milliers d'entrées en double. L'effort manuel pour Supprimer les doublons Excel et d'autres types de données nécessitait une équipe de cinq analystes RH travaillant à temps plein pendant trois jours. Malgré cet effort, le taux d'erreur dans le calcul final de la paie était constamment supérieur à 4 %, entraînant des employés surpayés et sous-payés. Une seule entrée en double pour un employé ayant plusieurs pointages le même jour peut être manquée, entraînant un surpaiement important. La correction de ces erreurs nécessitait l'émission d'ajustements de chèques coûteux et entraînait une frustration importante des employés, nuisant au moral et potentiellement entraînant des problèmes de conformité aux lois du travail.
Solution : L'entreprise a utilisé TabliSync pour automatiser les flux de travail de tableur et obtenir un nettoyage de données par IA fiable pour sa paie. Nous avons établi des intégrations directes et en temps réel avec leur système de pointage et leur plateforme RH cloud. Nous avons configuré un flux de travail de déduplication avancé en plusieurs étapes. Dans la première étape, il a effectué une correspondance exacte simple sur l''ID employé' et la 'Date de travail'. Dans la deuxième étape, cruciale, il a utilisé le nettoyage de données par IA avec une règle de correspondance floue sophistiquée pour les champs 'Heure d'arrivée' et 'Heure de départ'. Par exemple, si deux enregistrements montraient des pointages pour le même employé à moins de 3 minutes d'intervalle (une situation courante lorsqu'une horloge de pointage est tapée deux fois), ils étaient automatiquement fusionnés en suivant des règles métier prédéfinies (par exemple, en utilisant l'heure d'arrivée la plus tôt et l'heure de départ la plus tardive). Ce niveau de précision n'est possible qu'avec des systèmes intelligents. De plus, nous avons mis en œuvre une gestion détaillée des erreurs qui mettait automatiquement en quarantaine toute donnée véritablement irréconciliable (par exemple, un employé avec plusieurs entrées d'une journée complète dans deux endroits différents) pour un examen humain immédiat.
Résultat : Cette transformation a tout changé. Le processus manuel de trois jours a été réduit à un pipeline entièrement automatisé qui a exécuté et validé l'ensemble des données en 45 minutes. Plus important encore, le taux d'erreurs de paie a été réduit de plus de 4 % à moins de 0,5 % dès le premier cycle. Cette réduction directe des erreurs de paiement et l'élimination des ajustements manuels ont permis à l'entreprise d'économiser plus de 18 000 $ en coûts opérationnels et en paiements excédentaires à chaque période de paie. Le moral des employés s'est amélioré car les salaires sont devenus constants et précis, et le risque de problèmes de conformité a été pratiquement éliminé. Cette étude de cas démontre clairement que les données volumineuses nécessitent des solutions de nettoyage de données par IA de haute précision pour atteindre à la fois l'efficacité et une conformité essentielle.
Questions fréquemment posées sur la façon de supprimer les doublons dans Excel
Q1 : J'ai essayé l'outil intégré d'Excel, mais il a manqué des doublons. Que s'est-il passé ?
C'est extrêmement courant. Vous êtes presque certainement confronté à des données qui semblent identiques mais ne le sont pas. La cause principale est les caractères invisibles, tels qu'un espace final. La fonction `Supprimer les doublons` d'Excel est un système de correspondance exacte. Elle traite une cellule contenant « A » et une autre cellule contenant « A » comme deux valeurs uniques. Pour résoudre ce problème manuellement, vous devriez exécuter les fonctions `=SUPPRESPACE()` et `=NETTOYER()` sur toutes les colonnes concernées, puis copier les résultats et `Coller en tant que valeurs` pour standardiser réellement vos données avant de pouvoir utiliser l'outil intégré de manière fiable. Le nettoyage de données par IA automatisé dans **TabliSync** intègre cette logique de nettoyage ; il standardise toutes les données textuelles et peut utiliser une logique floue pour détecter les enregistrements sémantiquement identiques qui ne sont pas 100 % exacts en caractères, contournant ainsi entièrement ce problème.
Q2 : Puis-je combiner plusieurs colonnes pour trouver de vrais doublons dans TabliSync ?
Oui, et c'est un atout majeur. L'éditeur de règles de TabliSync vous permet de définir la clé composite pour l'unicité. Ceci est essentiel pour la logique métier. Par exemple, si vous examinez les stocks, un enregistrement unique n'est pas seulement un « ID produit » ; c'est la combinaison de « ID produit », « Emplacement d'entrepôt » et « Condition ». Vous pouvez sélectionner ces trois colonnes dans TabliSync pour créer votre identifiant unique, et le moteur de déduplication ne supprimera que les lignes ayant des valeurs identiques dans les trois champs. Cette validation multi-clés et multi-étapes garantit que vous ne supprimez pas simplement des données, mais que vous effectuez un nettoyage de données IA intelligent pour prendre en charge le traitement de données industrielles. Ce degré de spécificité est la clé du succès dans les applications de haute complexité.
Q3 : TabliSync supprime-t-il les données d'origine ? Est-il sûr à utiliser ?
C'est une question cruciale pour la Confiance. TabliSync ne supprime **pas** vos données d'origine. Il fonctionne en créant une copie de votre jeu de données, puis en appliquant les règles de duplication à cette copie dans un pipeline dédié. Vous définissez la logique, et vous obtenez un jeu de données nettoyé téléchargeable en sortie. Votre fichier Excel source d'origine reste entièrement intact. Nous recommandons toujours cela comme une meilleure pratique en matière de gestion des données. De plus, pour une piste d'audit robuste, TabliSync génère un rapport de résolution détaillé qui montre exactement quelles lignes en double ont été identifiées, quelle règle a été appliquée, et comment les valeurs finales ont été fusionnées ou sélectionnées, ce qui est essentiel pour la conformité dans les domaines nécessitant une précision élevée des données financières.
Q4 : Mon jeu de données Excel contient plus d'un million de lignes. TabliSync peut-il le gérer ?
Absolument. Les performances à grande échelle sont une proposition de valeur fondamentale de TabliSync, en particulier pour le traitement de données industrielles. Les fonctions Excel traditionnelles deviennent souvent très lentes, voire plantent, lorsqu'elles traitent des données de cette taille. Le processus de déduplication avec une formule de comptage avancée prendrait des heures. Le moteur de déduplication de TabliSync est conçu dès le départ pour le big data. Nous traitons et supprimons les doublons Excel de millions de lignes en quelques minutes, pas en quelques heures. Ceci est réalisé en tirant parti des ressources de calcul distribué basées sur le cloud pour gérer les calculs complexes en parallèle. Nous traitons régulièrement des jeux de données de 10 à 20 millions de lignes pour nos clients, garantissant une vitesse et une fiabilité que les outils manuels ne peuvent égaler.
Q5 : Puis-je planifier l'exécution automatique de ma tâche de déduplication ?
Oui, et c'est la meilleure façon d'automatiser les flux de travail de tableur. Vous pouvez configurer chaque pipeline TabliSync avec une planification flexible. Vous pouvez le définir pour qu'il s'exécute sur une base horaire, quotidienne, hebdomadaire, ou à des jours et heures spécifiques de votre choix. Chaque fois que le pipeline s'exécute, il récupère les dernières données de votre source, applique automatiquement la logique de nettoyage de données par IA pour supprimer les doublons Excel, et génère un nouvel ensemble de données de sortie propre. Cela garantit que votre analyse ou application en aval travaille toujours avec les données les plus récentes et sans erreur, éliminant tout effort manuel de votre cycle de préparation des données. C'est un élément fondamental des opérations de données modernes.
Q6 : L'IA de TabliSync peut-elle identifier des doublons orthographiés différemment ?
Oui. C'est la différence entre un système de correspondance exacte et le nettoyage de données par IA. TabliSync dispose d'une fonctionnalité avancée de **Correspondance Floue par IA**. Elle utilise le traitement du langage naturel (NLP) pour comparer les enregistrements sémantiquement. Par exemple, elle peut signaler avec confiance "Inc." par rapport à "Incorporated", ou "Street" par rapport à "St.", et même détecter les variations orthographiques courantes d'un nom (comme "Jon" par rapport à "John"). Vous pouvez contrôler le seuil de similarité sémantique. Vous ne faites pas que faire correspondre des caractères ; vous faites correspondre le sens. Cette capacité change la donne pour la consolidation des données clients (CRM) ou lors de la fusion de listes de fournisseurs provenant de plusieurs systèmes hérités, conduisant directement à des améliorations de la précision des données financières. Cette correspondance intelligente est une fonctionnalité essentielle que vous devriez utiliser.
Q7 : Lorsqu'un doublon est trouvé, quel enregistrement TabliSync conserve-t-il ?
Vous avez un contrôle total sur cela. TabliSync ne prend pas de décisions arbitraires. Dans notre générateur de règles de déduplication, vous définissez explicitement la **Logique de Fusion** ou la **Règle de Résolution**. Vous pouvez créer des règles sophistiquées en plusieurs étapes. Par exemple, pour une base de données de produits, vous pourriez créer une règle : « Conserver l'enregistrement avec le prix le plus élevé », ou pour un grand livre, « Conserver l'enregistrement qui a été créé en dernier selon son horodatage de transaction ». Ce système basé sur des règles garantit que le processus de déduplication est à la fois prévisible et vérifiable, ce qui est essentiel pour la **précision des données financières**. Ceci est bien supérieur à la suppression manuelle dans Excel où vous prenez une décision au cas par cas, sujette aux erreurs et n'offrant aucune piste d'audit.
Q8 : J'ai une situation unique où certaines données doivent être traitées spécifiquement. TabliSync peut-il aider ?
Oui. TabliSync est une plateforme puissante et flexible. Nous comprenons que tous les cas de déduplication ne sont pas simples. Vous pouvez créer des configurations de règles très avancées qui vont au-delà d'un seul composant. Par exemple, vous pourriez utiliser un composant « Filtre » pour diviser vos données en deux chemins : un pour la déduplication standard et un pour une règle spécialisée et à forte intensité de travail. Vous pouvez également enchaîner plusieurs étapes de déduplication pour obtenir un nettoyage de données extrêmement précis. Pour le **traitement de données industrielles** très complexe, nous pouvons même créer une logique de déduplication sur mesure, adaptée à vos besoins commerciaux exacts, grâce à nos services professionnels. Cette flexibilité garantit que nous pouvons résoudre presque tous les problèmes que vous rencontrez avec le nettoyage de données à grande échelle.
Q9 : Comment savoir si la déduplication a réussi ?
Nous fournissons plusieurs niveaux de vérification. Immédiatement après la synchronisation, un rapport récapitulatif de déduplication vous est présenté. Ce rapport vous indique exactement combien de lignes ont été saisies, combien de doublons au total ont été trouvés et le nombre final de lignes uniques. De manière cruciale, nous générons également un **Rapport de Résolution**. Ce rapport est un journal transactionnel pour chaque groupe de doublons. Il montre les lignes d'entrée individuelles, celle qui a été sélectionnée comme gagnante et pourquoi (par exemple, « Conservée selon la règle « Date de modification la plus récente » »). Ce niveau de transparence est essentiel pour valider la logique et fournit une piste d'audit claire, essentielle à la conformité de l'entreprise, en particulier dans les domaines où la **précision des données financières** est une exigence élevée. Vous avez une visibilité et un contrôle complets.
Q10 : Mes données sont-elles en sécurité sur votre plateforme ? Je possède des PII (Informations Personnellement Identifiables).
La sécurité des données est notre priorité absolue. Nous bâtissons la confiance en mettant en œuvre des mesures de sécurité robustes. TabliSync est construit avec une architecture axée sur la sécurité. Nous utilisons le chiffrement standard de l'industrie pour toutes les données au repos et en transit (SSL/TLS 1.2 et AES-256). Pour les PII, nous sommes conformes à la norme SOC 2 Type II, qui est une norme industrielle clé pour la protection des données. Nous fournissons un contrôle d'accès granulaire, vous permettant de gérer quels utilisateurs de votre organisation ont accès à des pipelines et des données spécifiques. De plus, vous pouvez configurer vos pipelines pour masquer ou même supprimer définitivement les champs sensibles (tels que les numéros de carte de crédit complets ou les numéros de sécurité sociale) dans la sortie de déduplication, offrant une couche de sécurité supplémentaire et vous aidant à maintenir la conformité avec des réglementations telles que le RGPD ou le CCPA. Vous pouvez faire confiance à TabliSync avec vos données les plus sensibles.
Arrêtez de vous battre avec les feuilles de calcul, commencez à gagner avec des données propres
Essayer manuellement de **supprimer les doublons de données Excel** est un gaspillage énorme de vos ressources les plus précieuses. C'est une bataille lente et sujette aux erreurs contre les espaces invisibles, les formats conflictuels et un simple manque de compréhension sémantique qui est intégré aux anciens outils. S'appuyer sur des fonctions de base comme `Supprimer les doublons` n'est plus viable pour des données à haut volume et à haute intégrité. C'est une stratégie obsolète qui érode la rentabilité et augmente le risque de conformité.
Vous devez transformer vos processus de données dès maintenant. Passer au **nettoyage de données par IA** avec **TabliSync** n'est pas seulement un gain d'efficacité ; c'est un changement fondamental dans la manière dont votre organisation gère l'information. Vous passez d'un état de friction manuelle et de risque élevé à un état de flux automatisé et de précision des données financières vérifiée. Récupérez les plus de 300 heures que votre équipe perd actuellement, clôturez votre cycle financier de fin de mois 6 jours plus rapidement et réduisez de moitié vos erreurs de paie. Les résultats sont clairs et immédiats.
Chaque minute que vous retardez est une minute pendant laquelle votre concurrence opère avec des données plus propres, plus rapides et plus fiables. La douleur de la gestion manuelle des données ne disparaîtra pas d'elle-même ; elle ne fera que croître avec la taille et la complexité de votre entreprise. Ne laissez pas vos précieux analystes continuer à être des balayeurs de données. Donnez-leur les moyens grâce à des solutions intelligentes et évolutives. Arrêtez de mener une bataille perdue d'avance et commencez à gagner avec des données propres et vérifiées qui font progresser votre entreprise. Nous sommes prêts à vous aider dans ce parcours. Cette transformation est simple et les résultats sont garantis. Le choix vous appartient : restez bloqué avec des outils manuels ou adoptez l'avenir des données automatisées et intelligentes.
Découvrez la transformation par vous-même dès aujourd'hui. C'est le moment d'agir. **[Cliquez ici pour commencer votre essai gratuit de 3 jours de TabliSync.]** Notre plateforme ne nécessite aucune configuration complexe ni formation approfondie. Nous vous montrerons comment connecter votre premier fichier Excel et obtenir une déduplication précise, pilotée par l'IA, en moins de 30 minutes. Le temps que vous récupérerez dès votre première semaine suffira à couvrir le coût de l'année entière. Prenez le contrôle de vos données et libérez le véritable potentiel de votre organisation.
Qu'est-ce que Comment supprimer rapidement les doublons de données Excel avec l'IA ?
Réponses rapides sur Comment supprimer rapidement les doublons de données Excel avec l'IA et comment TabliSync accélère le travail Excel des équipes.
Qu'est-ce que Comment supprimer rapidement les doublons de données Excel avec l'IA ?
Comment supprimer rapidement les doublons de données Excel avec l'IA couvre des workflows Excel pratiques, pièges courants et modèles d'automatisation. Ce guide TabliSync explique le concept, montre des exemples et lie des tutoriels.
Comment TabliSync peut-il aider avec Comment supprimer rapidement les doublons de données Excel avec l'IA ?
TabliSync extrait des tableaux depuis captures ou PDF, nettoie des données désordonnées et automatise les tâches Excel liées à Comment supprimer rapidement les doublons de données Excel avec l'IA.
Par où commencer avec Comment supprimer rapidement les doublons de données Excel avec l'IA ?
Commencez par l'aperçu de cette page, puis ouvrez les articles ci-dessous pour des guides pas à pas et workflows IA.
Tous les Articles Supprimer les doublons Excel(2)

Maîtriser le désordre : Comment supprimer les doublons dans Excel sans perte de données
Gains d'efficacité : Réduisez le temps de nettoyage manuel des données de plus de 90 % grâce à des flux de travail automatisés. Intégrité des données : Atteignez un taux d'erreur de saisie manuelle de 0 % en passant de la fonction "Rechercher et remplacer" à la déduplication basée sur un schéma. Atténuation des risques : Empêchez 100 % des suppressions accidentelles en utilisant des environnements Power Query non destructifs. Préparation pour l'avenir : Passez d'un nettoyage réactif à une hygiène des données proactive grâce à l'automatisation intégrée à l'IA.

Comment déprotéger une feuille Excel sans connaître le mot de passe
• Contournez instantanément la protection des feuilles Excel avec 0 % de perte de données.• Réduisez le temps de récupération manuel de 95 % grâce à la manipulation de schémas XML.• Éliminez les erreurs de « cellule verrouillée » et restaurez instantanément l'intégrité complète des données.• Exploitez l'IA OCR pour transformer les vues protégées statiques en données structurées dynamiques.
Fini la saisie manuelle – Extrayez des tableaux en quelques secondes
Convertissez instantanément n'importe quelle image ou tableau PDF en Excel avec une précision de 99,9%. L'OCR IA de TabliSync traite les formulaires manuscrits, les reçus et les tableaux complexes, puis synchronise directement avec Google Sheets, Notion ou Airtable
Essayez TabliSync gratuitement maintenant