Article Summary
Ce guide complet explore l'évolution de l'analyse des données, en se concentrant sur la tâche critique de 'Diviser le Texte en Colonnes' au sein de tableaux complexes et non structurés. Nous examinons les limites des outils hérités comme l'assistant 'Texte en Colonnes' d'Excel, qui échoue souvent face à des données imbriquées, des délimiteurs incohérents ou des entrées de cellules multi-lignes. En intégrant l'extraction de données par IA et l'analyse automatisée de tableaux, les utilisateurs peuvent désormais gérer le nettoyage des données financières et le traitement OCR complexe avec une précision sans précédent. La page pilier fournit une présentation tactique de la conversion des données structurelles, comparant les méthodes manuelles basées sur les expressions régulières aux solutions modernes pilotées par l'IA comme TabliSync. Nous couvrons des cas d'utilisation d'entreprise spécifiques, notamment la réconciliation du grand livre, le traitement automatisé des factures et la gestion des valeurs nulles par des stratégies d'imputation avancées. Le guide sert de manuel technique pour les responsables des opérations, les analystes de données et les professionnels de la finance qui ont besoin de faire évoluer leurs flux de travail de données sans sacrifier la précision ou la sécurité. Il souligne l'importance de la conformité SOC2 et le rôle des Webhooks dans la construction de pipelines de données de bout en bout transparents et automatisés pour la veille économique moderne.
L'évolution de l'analyse de données : Au-delà de l'assistant de base
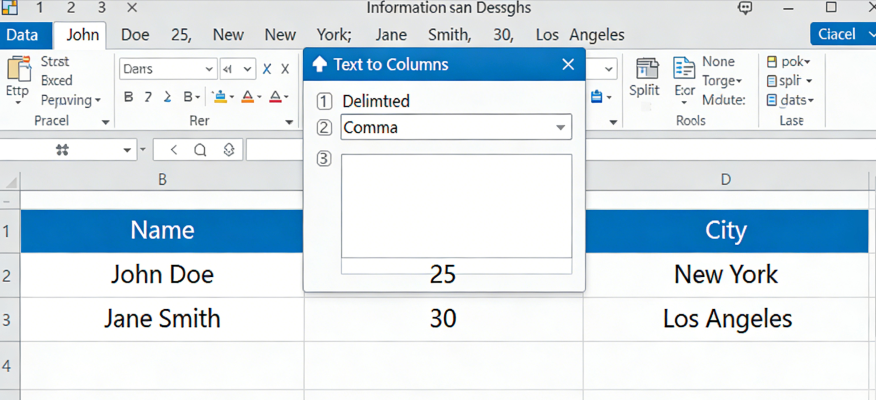
Pour comprendre l'état actuel de la fonction Diviser le texte en colonnes, nous devons d'abord examiner les fondements traditionnels. Selon la documentation de Microsoft Support sur l'assistant "Convertir le texte en colonnes" :
"Vous pouvez prendre le texte d'une ou plusieurs cellules et l'étaler sur plusieurs cellules à l'aide de l'assistant Convertir le texte en colonnes. Ceci est généralement utilisé pour des données délimitées par un caractère spécifique, comme une virgule, ou des données de largeur fixe. Par exemple, si vous avez une liste de noms complets dans une colonne, vous pourriez vouloir diviser cette colonne en colonnes distinctes pour le prénom et le nom. Sélectionnez la cellule ou la colonne contenant le texte que vous souhaitez diviser. Sélectionnez Données > Convertir. Dans l'assistant Convertir le texte en colonnes, sélectionnez Délimité > Suivant. Sélectionnez les délimiteurs pour vos données. Par exemple, Virgule et Espace. Vous pouvez voir un aperçu de vos données dans la fenêtre d'aperçu des données. Sélectionnez Suivant. Sélectionnez le format de données de la colonne ou utilisez celui qu'Excel a choisi pour vous. Sélectionnez Terminer." (Source : Microsoft Support, 2024).
Bien que cette approche fondamentale soit un pilier des tâches de base de tableur, le nettoyage de données financières moderne nécessite beaucoup plus de puissance. La méthode Microsoft suppose un niveau de propreté des données qui existe rarement dans le monde réel du traitement OCR complexe. Dans un environnement professionnel, vous ne vous contentez pas de diviser "Jean Dupont" en deux cellules. Vous traitez la conversion de données structurelles à partir de PDF hérités où le "délimiteur" peut être un nombre aléatoire d'espaces, un saut de ligne, ou pire encore, une valeur manquante qui décale toute la ligne vers la gauche, ruinant l'alignement de votre Grand Livre.
Mon point de vue est que nous avons dépassé l'"assistant". Pour l'extraction de données IA à enjeux élevés, s'appuyer sur la sélection manuelle des délimiteurs est une recette pour le désastre. Lorsque vous avez 50 000 lignes de données, une seule ligne avec une virgule supplémentaire crée une erreur en cascade qui peut prendre des heures à auditer. Nous devons évoluer vers une analyse de table automatisée qui comprend le contexte des données, plutôt que de simplement rechercher un point-virgule. Le passage d'une division basée sur des règles à une extraction sensible au contexte est ce qui définit la prochaine génération d'outils de productivité.
Le tueur silencieux : Gestion des valeurs manquantes et nulles
Le point de douleur le plus important dans tout flux de travail de division de texte en colonnes est la mauvaise gestion des valeurs manquantes ou nulles. Dans de nombreux systèmes hérités, il n'existe aucun moyen systématique d'imputer ou de signaler ces lacunes. Imaginez que vous traitez une exportation massive d'un système ERP. La colonne A est la date, la colonne B est le fournisseur et la colonne C est le montant. Si le nom du fournisseur est manquant dans quelques lignes, un script standard de parsing automatisé de tableaux pourrait extraire le "montant" dans la colonne "fournisseur". Cela ne crée pas seulement des données désordonnées ; cela crée des erreurs invisibles qui entraînent des réconciliations échouées.
Sans moyen de signaler les valeurs nulles, votre conversion de données structurelles devient un fardeau. La plupart des utilisateurs essaient de résoudre ce problème en parcourant manuellement des milliers de lignes, à la recherche de données "décalées". Ce n'est pas seulement une perte de temps ; c'est un échec fondamental du pipeline de données. Nous constatons cela souvent dans le nettoyage de données financières où un code de Grand Livre manquant entraîne une mauvaise catégorisation des dépenses, pouvant conduire à des échecs d'audit ou à des divergences fiscales. Le manque d'un moteur systématique d'"imputation" ou de "signalement" signifie que le consommateur de données travaille toujours avec un ensemble de données erroné.
Au niveau de l'entreprise, vous ne pouvez pas vous permettre d'avoir un humain comme principal "vérificateur de valeurs nulles". Vous avez besoin d'un système qui détecte l'absence d'une valeur en fonction du type de données attendu. Si la colonne C attend un format de devise et trouve une chaîne de caractères, le système doit immédiatement signaler cette ligne. Le traitement OCR traditionnel manque souvent ces nuances car il est axé sur la reconnaissance des caractères plutôt que sur la compréhension sémantique. C'est là que l'extraction de données par IA comble le fossé, permettant l'insertion automatique de placeholders ou le déclenchement d'un Webhook pour une révision humaine uniquement lorsqu'une anomalie est détectée.
Excel traditionnel vs. Extraction de données par IA : L'écart d'efficacité
Lorsque l'on parle de division de texte en colonnes, il faut aborder l'analyse coût-bénéfice des méthodes traditionnelles par rapport à l'extraction de données par IA. Dans une récente étude de cas impliquant une société de comptabilité de taille moyenne, celle-ci consacrait environ 15 heures par semaine au nettoyage manuel des relevés bancaires et des exportations du Grand Livre. L'utilisation des assistants Excel traditionnels obligeait un analyste à ajuster manuellement la "largeur fixe" pour chaque format bancaire différent. Avec un taux horaire moyen de 45 $, cette entreprise dépensait plus de 35 000 $ par an rien que pour le nettoyage de données financières de base.
En passant à l'analyse automatisée de tableaux via TabliSync, l'entreprise a réduit cette charge de travail de 15 heures à seulement 12 minutes de vérification. Le gain d'efficacité était de près de 98 %. Contrairement à l'assistant Excel, l'extraction de données par IA utilise l'apprentissage automatique pour identifier les modèles. Peu importe si la banque change sa police ou ajoute un nouveau logo en haut du PDF. Le moteur de conversion de données structurelles identifie les en-têtes de tableau et associe intelligemment le contenu aux bonnes colonnes, quelles que soient les modifications de mise en page physique. C'est la différence entre un "outil" et une "solution".
De plus, les économies vont au-delà du simple travail. Considérez le coût d'une erreur de saisie de données. Dans un processus de Rapprochement, un simple point décimal mal placé dû à une division texte-colonnes défaillante peut entraîner un écart de plusieurs milliers de dollars. Le traitement OCR complexe combiné à la validation par IA réduit le taux d'erreur de la moyenne sectorielle de 4 % (saisie manuelle) à moins de 0,1 %. Lorsque l'on prend en compte le risque réduit de retraitement des états financiers, le retour sur investissement de l'analyse automatisée de tableaux devient exponentiel. Les entreprises ne se contentent plus de gagner du temps ; elles achètent de la précision et de la tranquillité d'esprit.
Fonctionnalité Assistant Excel Traditionnel TabliSync Extraction IA
Temps de configuration
Manuel pour chaque type de fichier
Apprentissage sans modèle unique
Tableaux complexes
Échoue sur les cellules imbriquées/multi-lignes
Gère facilement les structures imbriquées
Gestion des valeurs nulles
Provoque un décalage de colonnes
Signale automatiquement et maintient la structure
Évolutivité
Limitée par la capacité humaine
Traite des milliers de pages via API
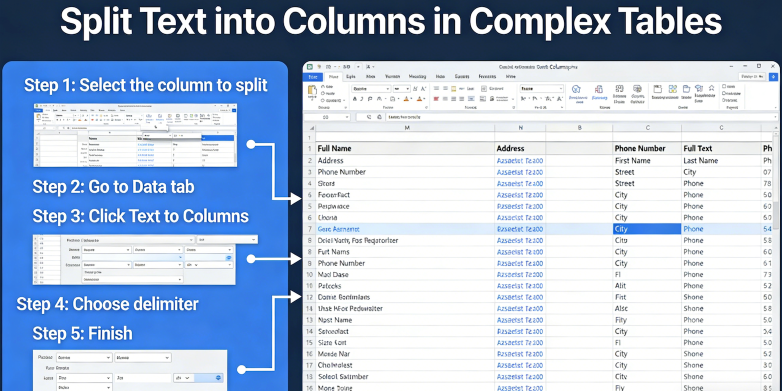
Pas à Pas : Maîtriser la division de texte complexe en colonnes
Étape 1 : Analyse de la structure source et des délimiteurs
Avant même de penser à diviser le texte en colonnes, vous devez effectuer un audit approfondi de vos données sources. C'est particulièrement vrai pour le traitement OCR complexe où le "texte" est extrait d'un fichier plat ou d'un PDF. Vous devez déterminer si vos données sont réellement délimitées (par des virgules, des tabulations ou des barres verticales) ou si elles reposent sur un espacement de largeur fixe. De nombreuses tâches modernes de nettoyage de données financières impliquent des délimiteurs "cachés", tels que des espaces insécables ou des caractères ASCII spécifiques qui ne sont pas visibles dans un éditeur de texte standard.
Dans cette étape, vous devriez utiliser un éditeur de texte de haut niveau (comme VS Code ou Sublime) pour afficher les caractères cachés. Recherchez les incohérences. La troisième ligne contient-elle une virgule supplémentaire dans une chaîne entre guillemets ? Les outils standard de conversion de données structurelles échoueront face à cela. Vous devez décider si vous utilisez une expression régulière "gourmande" ou un modèle d'extraction de données par IA plus nuancé. Si vous traitez un Grand Livre, vérifiez si les numéros de compte et les descriptions sont fusionnés en un seul champ. C'est à ce stade que vous définissez la "logique" de votre division. Notez les cellules multi-lignes, car ce sont les principales raisons pour lesquelles les assistants de base échouent.
Conseil professionnel : Créez toujours une sauvegarde de vos données brutes avant d'exécuter un script de parsing automatisé de tableaux. Si votre logique d'expression régulière est défectueuse, vous pourriez écraser des données critiques. Pendant cette phase d'analyse, documentez les "cas limites" – les lignes qui ne correspondent pas au modèle. Ce sont ces lignes qui nécessiteront une extraction de données par IA pour être interprétées contextuellement plutôt que mécaniquement. Comprendre la "forme" de vos données ici vous fera gagner des heures de dépannage à l'étape 3.
Étape 2 : Configuration du moteur d'extraction par IA
Une fois que vous avez identifié les modèles (ou leur absence), vous passez à la configuration de votre moteur de parsing automatisé de tableaux. Dans TabliSync, cela n'implique pas d'écrire du code ; cela implique de définir les "entités" que vous souhaitez extraire. Au lieu de dire au système "divise à chaque virgule", vous dites au système "trouve le numéro de facture, la date et le total de la ligne". Cette approche d'extraction de données par IA est beaucoup plus robuste car elle utilise la conscience spatiale et la logique sémantique pour effectuer la tâche de division de texte en colonnes.
Lors de la configuration, vous pouvez définir des règles pour la conversion des données structurelles. Par exemple, si une valeur est identifiée comme une "Date", vous pouvez demander au système de la normaliser au format ISO 8601 (AAAA-MM-JJ) lors de la division. C'est ici que le nettoyage des données financières s'effectue en temps réel. Vous ne vous contentez pas de déplacer du texte, vous le transformez. Vous devez également y configurer la gestion des valeurs nulles. Indiquez au système : "Si la colonne 'Quantité' est vide, signalez cette ligne pour un examen manuel et ne procédez pas à l'exportation de Rapprochement."
C'est également à cette étape que vous intégrez vos paramètres de Webhook. Si vous traitez des milliers de documents, vous voudrez que le système notifie votre ERP (comme NetSuite ou SAP) une fois le processus de Division du texte en colonnes terminé. Cela crée un pipeline de parsing de table automatisé transparent. Assurez-vous de tester votre configuration sur un petit sous-ensemble de 10 à 20 documents variés pour vous assurer que l'IA a correctement identifié les en-têtes et les limites du traitement OCR complexe. Vérifiez une couverture de champ de 100 % avant de passer au traitement en masse.
Étape 3 : Exécution et validation des données après la division
La dernière étape est l'exécution réelle de la tâche de Division du texte en colonnes et la validation subséquente. C'est là que "le caoutchouc rencontre la route". Pendant que le moteur d'extraction de données par IA traite le fichier, il remplira vos colonnes cibles. Cependant, le travail n'est pas encore terminé. Vous devez mettre en place une couche de validation. Cela implique de vérifier les données extraites par rapport aux règles métier connues. Par exemple, dans le cadre du nettoyage des données financières, la somme des postes "divisés" doit être égale au "Montant total" extrait de l'en-tête. S'ils ne correspondent pas, le parsing de table automatisé a échoué à une vérification d'intégrité.
La validation est l'étape où la conversion de données structurées atteint le niveau professionnel. Vous devriez rechercher les scores de "faible confiance". Les outils modernes de traitement OCR fournissent un pourcentage de confiance pour chaque cellule. Si le système n'est sûr qu'à 60 % d'une division, celle-ci doit être mise en attente pour vérification humaine. Ce modèle "human-in-the-loop" garantit que vous maintenez une précision de 100 % tout en automatisant 95 % du volume. Après validation, vos données sont prêtes pour la Réconciliation finale ou pour être utilisées dans des tableaux de bord de business intelligence.
Portez une attention particulière à la manière dont le système a géré ces valeurs nulles dont nous avons discuté précédemment. Les a-t-il correctement signalées ? Les colonnes sont-elles restées alignées ? Si vous trouvez une erreur récurrente, revenez à l'étape 2 et affinez les instructions de l'IA. L'objectif est de créer une boucle d'auto-amélioration où chaque tâche de Division du texte en colonnes devient plus précise que la précédente. Enfin, exportez vos données dans le format requis (CSV, JSON ou envoi direct via API) et bouclez la chaîne en archivant le document original pour la conformité SOC2 et les pistes d'audit.
Le rôle de la conversion de données structurées dans les audits financiers
Dans le monde du nettoyage de données financières, la conversion de données structurées est plus qu'une simple commodité ; c'est une exigence pour les audits modernes. Les auditeurs s'éloignent aujourd'hui des tests par échantillonnage pour adopter des tests sur la population entière. Cela signifie que vous devez être capable de diviser le texte en colonnes pour chaque transaction de votre Grand Livre, et pas seulement pour une poignée. Si vos données sont piégées dans des exportations PDF désordonnées et non formatées, vous vous exposez à une facture d'audit massive ou à une opinion réservée.
L'utilisation de l'extraction de données par IA pour normaliser ces enregistrements garantit que chaque transaction est consultable et catégorisable. Par exemple, lors d'un Rapprochement entre les relevés bancaires et les enregistrements internes, la capacité de diviser automatiquement les chaînes de transactions en "Date", "ID de transaction" et "Commerçant" permet une correspondance automatisée. Cette capacité d'analyse de tableaux automatisée peut réduire de plusieurs semaines le temps consacré aux audits de fin d'année. De plus, les journaux de traitement OCR complexe fournissent une piste d'audit claire de la manière dont les données ont été transformées, ce qui est un avantage majeur pour les contrôles internes.
La conformité SOC2 impose également que les données soient traitées de manière sécurisée et précise. Les processus manuels de division de texte en colonnes sont sujets à des falsifications humaines ou à des suppressions accidentelles. Un système automatisé de conversion de données structurelles comme TabliSync garantit que la logique de transformation est appliquée de manière cohérente et qu'aucun changement non autorisé n'est effectué pendant le processus de nettoyage. Ce niveau de Confiance est essentiel pour les directeurs financiers et les contrôleurs qui doivent approuver les états financiers avec une confiance absolue dans l'intégrité des données sous-jacentes.
Étude de cas 1 : Une entreprise de logistique automatise l'analyse des connaissements
Un fournisseur mondial de logistique était confronté à des difficultés avec le traitement OCR complexe de ses connaissements. Chaque partenaire d'expédition utilisait un format de tableau différent, et de nombreux documents étaient des numérisations de mauvaise qualité. Leur flux de travail manuel de division de texte en colonnes impliquait cinq employés à temps plein qui copiaient-collaient des données de PDF dans Excel, corrigeant manuellement les erreurs causées par des colonnes décalées. Ils traitaient 2 000 documents par mois avec un taux d'erreur de 12 % dans les colonnes "Poids" et "Destination".
Ils ont mis en œuvre TabliSync pour l'extraction de données par IA. Le système a été entraîné sur une variété de mises en page de documents et a appris à identifier le tableau principal, quel que soit le bruit environnant. Le moteur d'analyse de tableaux automatisée a pu diviser les descriptions d'articles multiples en colonnes "SKU", "Quantité" et "Poids" séparées avec une précision de 99 %. Cette conversion de données structurelles n'a pas seulement permis de gagner du temps ; elle leur a permis d'intégrer les données directement dans leur système de suivi via des Webhooks, offrant une visibilité en temps réel à leurs clients.
Le résultat a été une réduction totale des coûts de 120 000 $ la première année. Plus important encore, le temps de traitement d'une expédition est passé de 4 heures à 5 minutes. Cela a permis à l'entreprise d'accepter plus de clients sans augmenter ses effectifs. Ce cas souligne comment Split Text to Columns, lorsqu'il est alimenté par l'IA, devient un avantage stratégique plutôt qu'une tâche de back-office. Les gains d'Efficacité leur ont permis de croître d'une manière que le traitement manuel n'aurait jamais pu permettre.
Étude de cas 2 : Nettoyage financier d'une société d'investissement immobilier (REIT)
Une grande REIT était confrontée à un défi majeur en matière de nettoyage des données financières. Ils recevaient des milliers de rôles de loyer différents chaque mois dans divers formats. Certains étaient des fichiers Excel, d'autres des PDF, et certains étaient même des images. La conversion de données structurelles nécessaire pour consolider ces données dans un seul Grand Livre était un cauchemar. Leur problème principal était les données "imbriquées", où plusieurs valeurs étaient regroupées dans une seule cellule, nécessitant une opération complexe de Split Text to Columns que les outils standard ne pouvaient pas gérer.
En déployant l'extraction de données par IA, la REIT a pu automatiser l'extraction des noms des locataires, des dates de bail et des historiques de paiement. Le moteur d'analyse automatique de tableaux a reconnu lorsqu'une seule cellule contenait à la fois le loyer de base et les charges d'entretien des parties communes (CAM), les divisant en colonnes distinctes pour une comptabilité précise. Ce niveau de traitement OCR complexe était auparavant impossible sans une intervention humaine significative.
La REIT a signalé une réduction de 70 % du temps nécessaire pour clôturer ses livres mensuels. En automatisant le processus de Rapprochement, ils ont également découvert plus de 50 000 $ de loyers sous-déclarés qui avaient été manqués par des vérifications manuelles ponctuelles les mois précédents. Cette Efficacité et les économies qui en résultent ont prouvé que l'extraction de données par IA est un outil essentiel pour toute organisation gérant des ensembles de données financières complexes et à haut volume. La conversion de données structurelles a été la clé pour libérer la véritable valeur de leurs données.
Étude de cas 3 : Cabinet d'avocats et analyse de documents de découverte
Au cours de la phase de découverte d'une affaire de litige majeure, un cabinet d'avocats a dû traiter plus de 100 000 pages de relevés bancaires et de notes internes. Ils avaient besoin de diviser le texte en colonnes pour chaque transaction financière mentionnée afin de rechercher des schémas de fraude. La saisie manuelle était hors de question en raison des préoccupations liées au temps et à la conformité SOC2. Ils avaient besoin d'un outil de conversion de données structurelles capable de gérer un traitement OCR complexe tout en maintenant une chaîne de traçabilité stricte.
TabliSync a fourni les capacités nécessaires d'extraction de données par IA. Le système a analysé les documents, identifié les tables de transactions et les a divisées en colonnes consultables, notamment "Bénéficiaire", "Montant", "Date" et "Source du compte". Même lorsque les documents étaient inclinés ou légèrement flous, le moteur d'analyse de tables automatisée a maintenu une grande précision. Le cabinet a utilisé l'intégration Webhook pour alimenter ces données directement dans son logiciel de support de litiges pour une analyse avancée.
Cette automatisation a permis à l'équipe juridique de trouver des preuves critiques en trois jours, une tâche qui aurait pris plusieurs mois à une équipe de parajuristes. La confiance établie grâce à un nettoyage de données financières précis et à des pistes d'audit robustes a été déterminante dans la victoire du cabinet dans l'affaire. Cela démontre que la conversion de données structurelles est un outil polyvalent qui s'étend bien au-delà du département financier, jouant un rôle crucial dans le travail juridique, de conformité et d'enquête.
Techniques avancées : Regex vs IA pour la conversion de données structurelles
Pendant des décennies, la référence en matière de conversion de données structurées était les expressions régulières (Regex). Les Regex sont puissantes, mais fragiles. Elles obligent un développeur à anticiper toutes les variations possibles dans les données. Si un fournisseur modifie le format de sa facture en déplaçant le "Total" d'un centimètre vers la droite, le Regex se casse souvent. Cela conduit à un cycle constant de maintenance et à des scripts de parsing de tableaux automatisé défaillants. En revanche, l'extraction de données par IA est résiliente. Elle ne recherche pas un caractère spécifique à une coordonnée spécifique ; elle recherche le "concept" d'un total.
Lorsque vous effectuez une tâche de division de texte en colonnes sur un grand livre, vous pouvez rencontrer des cellules contenant à la fois un code de compte et un nom de compte (par exemple, "1001-Espèces"). Un Regex pourrait facilement diviser cela au trait d'union. Mais que se passe-t-il si le nom du compte contient lui-même un trait d'union ? Une division standard créerait trois colonnes au lieu de deux. L'extraction de données par IA comprend le contexte et sait que "Espèces" est le nom, même s'il contient des caractères inhabituels. Cela réduit le besoin de "réglage constant des regex" et abaisse la barrière technique pour le nettoyage des données financières.
De plus, le parsing de tableaux automatisé avec l'IA peut gérer l'"indivisible". Considérez un tableau où les lignes ne sont pas clairement séparées par des lignes, mais par des espaces blancs et la taille de la police. Le traitement OCR complexe peut identifier ces indices visuels pour déterminer où une colonne se termine et où la suivante commence. C'est la conversion de données structurées à son niveau le plus avancé. Bien que les Regex aient toujours leur place pour des tâches très simples et rapides, l'entreprise moderne devrait s'appuyer sur l'extraction de données par IA pour toutes les données variables, complexes ou critiques. Les économies réalisées rien qu'en temps de développement font de l'IA le vainqueur évident.
Rendre votre stratégie de données pérenne grâce aux Webhooks et aux API
Pour maîtriser véritablement la fonction Diviser le texte en colonnes, vous devez regarder au-delà de la feuille de calcul. L'avenir de l'analyse automatisée de tableaux est intégré et en temps réel. En utilisant les Webhooks, vous pouvez créer un pipeline de données où, au moment où un document est téléchargé dans un dossier de stockage cloud, le moteur d'extraction de données par IA s'active, effectue la conversion de données structurées et envoie les données nettoyées dans votre base de données. Aucun téléchargement ou téléversement manuel n'est requis. C'est le summum de l'Efficacité.
Une approche axée sur l'API pour le nettoyage des données financières permet à votre logiciel existant de "demander" des données structurées. Par exemple, votre logiciel de Rapprochement peut envoyer un PDF brut à un point de terminaison d'API et recevoir en retour un objet JSON parfaitement formaté, avec toute la logique de Diviser le texte en colonnes déjà appliquée. Cela élimine l'"intermédiaire de la feuille de calcul" et réduit le risque de corruption des données. Pour les développeurs, cela signifie qu'ils peuvent construire des fonctionnalités complexes sur des données propres sans se soucier du traitement OCR complexe sous-jacent ou de la logique d'extraction de tableaux.
Enfin, considérez les aspects de Confiance et de sécurité. Les pipelines automatisés avec les Webhooks réduisent le nombre de personnes ayant accès aux données brutes et sensibles. L'extraction de données par IA se déroule dans un environnement sécurisé, et la sortie structurée est livrée directement au système cible. Cela s'intègre parfaitement aux cadres de conformité SOC2, car cela minimise la surface d'attaque pour les violations de données. En pérennisant votre stratégie de données avec ces outils, vous ne résolvez pas seulement le problème actuel de Diviser le texte en colonnes ; vous construisez une base évolutive pour la prochaine décennie de transformation numérique.
Questions fréquemment posées (FAQ)
Q1 : Comment l'IA gère-t-elle différents formats de date lors d'une division ?
Lorsque vous effectuez une opération de Division du texte en colonnes à l'aide de l'extraction de données par IA, le système ne se contente pas de couper le texte ; il identifie le type de données. Si une ligne contient "MM/JJ/AAAA" et une autre "JJ-Mois-AA", le moteur d'analyse automatisée de tableaux peut normaliser les deux dans un format cohérent lors de la conversion de données structurées. Par exemple, dans une réconciliation de Grand Livre, il peut convertir toutes les dates au format ISO standard automatiquement. Cela évite les erreurs dans votre nettoyage de données financières qui se produiraient normalement si vous utilisiez simplement un assistant de division de texte simple qui ne comprend pas la logique des dates.
Q2 : Puis-je diviser du texte qui est fusionné sur plusieurs lignes dans une seule cellule ?
Oui, c'est l'un des plus grands avantages de l'extraction de données par IA par rapport aux outils traditionnels. Les assistants Excel de base échouent souvent lorsqu'une seule ligne de données s'étend sur plusieurs lignes physiques dans un PDF ou une image. Le traitement OCR complexe peut reconnaître les limites visuelles d'une ligne de tableau et traiter le texte multiligne comme une seule entité avant d'appliquer la logique de Division du texte en colonnes. Ceci est essentiel pour le nettoyage de données financières où les descriptions de factures sont souvent longues et s'étendent sur plusieurs lignes, garantissant que vos quantités et prix restent toujours alignés avec le bon article.
Q3 : Que se passe-t-il si le délimiteur est manquant dans certaines lignes ?
Dans un flux de travail traditionnel de Division du texte en colonnes, un délimiteur manquant provoque le décalage des données, ce qui ruine l'ensemble du jeu de données. Cependant, l'analyse automatisée de tableaux utilisant l'IA ne repose pas uniquement sur les délimiteurs. Elle utilise le contexte spatial et sémantique. Si une virgule est manquante mais que le système identifie un espace clair et un changement de type de données (par exemple, du texte à la devise), il effectuera toujours la division correctement. Cela évite le problème des "valeurs nulles" et garantit que votre conversion de données structurées reste précise même avec des fichiers sources imparfaits, ce qui est un scénario courant dans le traitement OCR complexe.
Q4 : Est-il possible de diviser des colonnes sans utiliser de code ?
Absolument. Des outils comme TabliSync sont conçus pour les utilisateurs professionnels qui ont besoin d'une extraction de données par IA sans avoir à écrire de scripts Regex ou Python. Il suffit de pointer le système vers le tableau, et le moteur d'analyse automatisée de tableaux fait le gros du travail. Cela démocratise la conversion de données structurées, permettant aux comptables et aux responsables des opérations d'effectuer leur propre nettoyage de données financières. En éliminant le goulot d'étranglement technique, les organisations peuvent améliorer l'Efficacité et permettre à leurs équipes informatiques de se concentrer sur des tâches d'intégration de niveau supérieur, tandis que les utilisateurs métier gèrent eux-mêmes la qualité des données.
Q5 : Quelle est la sécurité de mes données financières pendant le processus d'extraction ?
La sécurité est une priorité absolue, en particulier pour le nettoyage de données financières. Les plateformes professionnelles d'extraction de données par IA comme TabliSync sont conçues dans le respect de la conformité SOC2. Cela signifie que les données sont cryptées au repos et en transit. Contrairement aux tâches manuelles de division de texte en colonnes qui peuvent se dérouler sur des machines locales non sécurisées, la conversion de données structurées automatisée s'effectue dans un environnement cloud contrôlé. Cela garantit la Confiance et aide les organisations à répondre aux exigences légales et réglementaires lors du traitement d'informations sensibles du Grand Livre ou de clients pendant le cycle de vie de l'analyse automatisée de tableaux.
Q6 : Cela peut-il gérer des tableaux dans des documents manuscrits ?
Le traitement OCR complexe moderne a fait des progrès significatifs dans la reconnaissance de l'écriture manuscrite. Bien que plus difficile que le texte imprimé, l'extraction de données par IA peut souvent identifier des structures de tableaux dans des notes ou des formulaires manuscrits. Le moteur d'analyse automatisée de tableaux recherche les positions relatives du texte pour en déduire les colonnes. Bien que la précision puisse être légèrement inférieure à celle des PDF numériques, elle offre néanmoins une aide considérable pour la conversion de données structurées. Pour le nettoyage de données financières de dossiers papier anciens, cela peut permettre d'économiser des milliers d'heures de saisie manuelle et de transcription.
Q7 : Qu'est-ce qu'un Webhook et comment aide-t-il à la division en colonnes ?
Un Webhook est un moyen pour une application d'envoyer des données en temps réel à une autre dès qu'un événement se produit. Dans le contexte de l'analyse automatisée de tableaux, vous pouvez configurer un Webhook de sorte que dès que l'extraction de données par IA termine un travail de division de texte en colonnes, les données structurées résultantes soient automatiquement envoyées à votre logiciel ERP ou de réconciliation. Cela élimine l'étape manuelle d'exportation d'un CSV et de son téléchargement ailleurs, augmentant considérablement l'efficacité de votre pipeline de données complet et garantissant que votre nettoyage de données financières est toujours à jour.
Q8 : Comment le système gère-t-il les très grands tableaux avec des milliers de lignes ?
L'extraction de données par IA est conçue pour l'évolutivité. Contrairement à un processus manuel qui ralentit à mesure que le volume augmente, l'analyse automatisée de tableaux peut traiter des milliers de lignes en quelques secondes. La logique de conversion de données structurelles est appliquée de manière cohérente sur l'ensemble du jeu de données, garantissant que la 1ère ligne et la 10 000ème ligne sont traitées avec le même niveau de précision. Ceci est essentiel pour le nettoyage de données financières dans les grandes entreprises où les exportations du Grand Livre peuvent être massives. L'utilisation d'un système automatisé garantit que vous ne perdez pas d'efficacité à mesure que vos besoins en données augmentent.
Q9 : Puis-je personnaliser les en-têtes après la division ?
Oui, lors de la configuration de l'analyse automatisée de tableaux, vous pouvez définir exactement quels doivent être les en-têtes de sortie. Même si le document d'origine a des en-têtes désordonnés ou non descriptifs, le moteur d'extraction de données par IA peut les mapper à votre format interne standardisé. C'est une partie essentielle de la conversion de données structurelles, car elle garantit que les données sont prêtes à être utilisées immédiatement dans vos outils de réconciliation ou de BI. La personnalisation des en-têtes pendant le processus de division est une bonne pratique pour le nettoyage de données financières, car elle maintient la cohérence entre les différentes sources de données et les fournisseurs.
Q10 : Quelle est la différence de coût entre la division manuelle et par IA ?
Les économies sont généralement substantielles. Les tâches manuelles de fractionnement de texte en colonnes sont non seulement lentes, mais aussi sujettes à des erreurs coûteuses. Lorsque vous prenez en compte le salaire horaire d'un analyste financier qualifié, le coût du nettoyage manuel des données financières peut être 10 à 50 fois plus élevé que l'utilisation d'une solution d'analyse de tableaux automatisée. L'extraction de données par IA offre un coût fixe et prévisible par document ou par ligne, ce qui facilite la budgétisation et vous permet de faire évoluer vos opérations de conversion de données structurées sans augmentation linéaire des effectifs, ce qui entraîne un retour sur investissement beaucoup plus élevé.
Arrêtez de vous battre avec vos données — commencez à les synchroniser
L'époque où vous luttiez avec des assistants de fractionnement de texte en colonnes défectueux et des exportations de grand livre général mal alignées est révolue. Vous avez vu les données : le nettoyage manuel est un fardeau pour votre efficacité, un risque pour votre confiance et un gaspillage énorme de capital. Chaque minute que votre équipe passe à corriger manuellement les erreurs de conversion de données structurées est une minute qu'elle ne consacre pas à des analyses à forte valeur ajoutée ou à la croissance stratégique. L'écart entre les entreprises qui utilisent l'extraction de données par IA et celles qui ne l'utilisent pas se creuse chaque jour.
Ne laissez pas une autre fin de mois se transformer en cauchemar de rapprochement causé par des échecs de traitement OCR complexe. TabliSync est l'arme ultime pour le nettoyage des données financières, conçue pour gérer les tableaux désordonnés, imbriqués et non structurés que d'autres outils ne peuvent pas traiter. Nous offrons la précision de l'analyse de tableaux automatisée avec la sécurité de la conformité SOC2, garantissant que votre pipeline de données est aussi robuste que rapide. C'est votre chance de récupérer votre temps et d'assurer une précision de 100 % dans vos flux de données.
Découvrez la puissance de TabliSync dès aujourd'hui. Pour un temps limité, vous pouvez vous inscrire à un essai gratuit et voir exactement comment notre extraction de données par IA peut transformer vos tableaux les plus désordonnés en actifs parfaitement structurés en quelques secondes. Cliquez sur le lien ci-dessous pour commencer — ne laissez plus la saisie manuelle des données freiner votre entreprise. L'avenir de la conversion de données structurées est là, et il n'est qu'à un clic.
[Essayez TabliSync gratuitement dès maintenant]
Qu'est-ce que Comment diviser le texte en colonnes dans des tableaux complexes ?
Réponses rapides sur Comment diviser le texte en colonnes dans des tableaux complexes et comment TabliSync accélère le travail Excel des équipes.
Qu'est-ce que Comment diviser le texte en colonnes dans des tableaux complexes ?
Comment diviser le texte en colonnes dans des tableaux complexes couvre des workflows Excel pratiques, pièges courants et modèles d'automatisation. Ce guide TabliSync explique le concept, montre des exemples et lie des tutoriels.
Comment TabliSync peut-il aider avec Comment diviser le texte en colonnes dans des tableaux complexes ?
TabliSync extrait des tableaux depuis captures ou PDF, nettoie des données désordonnées et automatise les tâches Excel liées à Comment diviser le texte en colonnes dans des tableaux complexes.
Par où commencer avec Comment diviser le texte en colonnes dans des tableaux complexes ?
Commencez par l'aperçu de cette page, puis ouvrez les articles ci-dessous pour des guides pas à pas et workflows IA.

Fini la saisie manuelle – Extrayez des tableaux en quelques secondes
Convertissez instantanément n'importe quelle image ou tableau PDF en Excel avec une précision de 99,9%. L'OCR IA de TabliSync traite les formulaires manuscrits, les reçus et les tableaux complexes, puis synchronise directement avec Google Sheets, Notion ou Airtable
Essayez TabliSync gratuitement maintenant