Article Summary
Dominando o OCR em Lote para Excel em 2026 No cenário orientado por dados de 2026, a entrada manual tradicional de documentos não estruturados — como faturas, recibos e relatórios de logística — tornou-se um gargalo crítico para o crescimento. Este artigo fornece um guia definitivo para tecnologias de OCR em Lote para Excel, enfatizando que o OCR moderno transcendeu a simples transcrição de texto para se concentrar na reestruturação inteligente de dados e na consciência contextual.
Dominando Grandes Conjuntos de Dados: O Guia Definitivo de OCR em Lote para Excel
Lidar com grandes conjuntos de dados muitas vezes significa enfrentar uma montanha de documentos não estruturados. Seja em finanças, logística ou saúde, o grande volume de faturas, recibos e relatórios pode ser avassalador. O método tradicional de entrada manual de dados não é apenas lento; é um gargalo que sufoca o crescimento e introduz erros dispendiosos. A solução moderna reside em alavancar a extração automatizada de dados através de tecnologias de OCR em Lote para Excel. Mas como navegar no cenário de ferramentas disponíveis e implementar uma solução que realmente escala? Este guia fornece a expertise aprofundada que você precisa para dominar o processamento de documentos em massa e alcançar OCR de alta precisão para seus dados financeiros e operacionais críticos.
Reflexões sobre o Cenário Atual de OCR: Além da Transcrição Básica
Uma análise recente e perspicaz da Lido, intitulada "Melhor Software de OCR para Extração de Dados em 2024", aprofunda as nuances críticas da seleção da ferramenta de Reconhecimento Óptico de Caracteres correta. O autor enfatiza que o OCR moderno transcendeu a simples transcrição de texto, agora exigindo estruturação de dados sofisticada e consciência contextual. Especificamente, o artigo destaca:
"O verdadeiro valor do OCR moderno não está apenas em reconhecer caracteres, mas em entender a estrutura dos dados que ele extrai. Para empresas que lidam com documentos complexos como faturas e demonstrações financeiras, a capacidade de analisar tabelas com precisão e manter relacionamentos de dados é fundamental. Sem isso, os 'dados extraídos' são meramente uma confusão de texto, ainda exigindo um esforço manual significativo para reorganizar e tornar utilizável. Plataformas eficazes de extração de dados devem oferecer detecção robusta de tabelas e capacidades de análise de layout para entregar informações genuinamente acionáveis diretamente em formatos como Excel ou bancos de dados relacionais." (Fonte: https://www.lido.app/blog/best-ocr-software)
Como especialista em marketing de conteúdo SaaS profundamente inserido no espaço de automação de documentos, acho essa perspectiva incrivelmente ressonante. O artigo da Lido identifica corretamente o desafio central que muitas empresas negligenciam: o 'T' em OCR deve significar 'Transformação', não apenas 'Transcrição'. O mercado está inundado com ferramentas de OCR genéricas que podem digitalizar uma página de texto. No entanto, pouquíssimas possuem a inteligência especializada necessária para análise de tabelas financeiras em centenas ou milhares de documentos simultaneamente. É precisamente aqui que o gargalo muda de 'ler' o documento para 'reestruturar' os dados, um passo crítico para análise downstream ou integração com ERP.
Além disso, o artigo ressalta o papel crítico da integração. Em minha experiência, mesmo um motor de OCR altamente preciso se torna um silo se não conseguir injetar dados perfeitamente em fluxos de trabalho existentes. Uma solução robusta de OCR em Lote para Excel deve não apenas se destacar na análise de layout, mas também fornecer APIs robustas ou webhooks para se conectar a plataformas como Salesforce, NetSuite ou software de contabilidade especializado. Isso ecoa o foco da Lido em plataformas que oferecem pipelines de dados abrangentes. A capacidade de lidar com diversos formatos de documentos — desde PDFs e JPEGs até TIFFs complexos e de várias páginas — em lote, mantendo alta precisão e integridade estrutural, não é mais um luxo; é uma necessidade competitiva para qualquer organização orientada por dados.

O Gargalo Multi-Formato: Por Que a Variedade dos Seus Documentos Está Matando a Eficiência
Vamos falar sobre o verdadeiro ponto problemático no processamento de documentos em larga escala. Não é apenas o volume; é a pura e não adulterada [variedade] de formatos e layouts de documentos. Seu departamento financeiro não recebe faturas em um formato padronizado. Eles as recebem como PDFs vetoriais de grandes fornecedores, JPEGs mal digitalizados de fornecedores menores, TIFFs de várias páginas de sistemas de fax antigos e, talvez, até alguns documentos caóticos do Word. Esta é a Incapacidade de Processar em Lote Formatos Variados, e é um matador de produtividade. Métodos convencionais e ferramentas de OCR menos avançadas forçam você a processar cada formato de maneira diferente, muitas vezes exigindo uma tediosa pré-classificação manual ou a criação de modelos para cada layout de fornecedor individual.
- Cada novo layout de fornecedor exige um [novo modelo] ou configuração.
- Documentos digitalizados geralmente exigem [pré-processamento manual de imagem], como endireitamento.
- Combinar diferentes tipos de arquivo em um único lote de processamento é frequentemente [impossível].
- Regras de extração de dados que funcionam para um PDF claro [falham] em uma digitalização granulada.
- O resultado é um fluxo de trabalho fragmentado que [não pode ser verdadeiramente automatizado].
Imagine sua equipe de contas a pagar tentando processar 10.000 faturas por mês. 6.000 são PDFs padrão, mas 4.000 são uma mistura de digitalizações, e-mails com imagens incorporadas e tipos de arquivo estranhos. A abordagem convencional significa que a equipe pode automatizar talvez 60% do fluxo de trabalho, mas os 40% restantes exigem uma intervenção manual lenta e altamente disruptiva. Isso não é apenas ineficiente; é uma [barreira massiva de escalabilidade]. A incapacidade de tratar todos esses formatos variados como um único 'lote' unificado significa que seu processamento de documentos em massa está constantemente encontrando obstáculos. Você não está alcançando a verdadeira automação; você está apenas automatizando as partes fáceis e deixando as partes difíceis e caras para os humanos, o que anula o propósito de adotar a tecnologia em primeiro lugar.
Essa dor se intensifica dramaticamente ao lidar com documentos complexos e de várias páginas, como [contratos legais] ou [relatórios de ensaios clínicos]. Um documento de 50 páginas pode conter tabelas financeiras críticas nas páginas 12, 35 e 48, cada uma formatada de maneira ligeiramente diferente. Uma ferramenta OCR básica pode extrair todo o texto, mas falhará completamente em reconhecer que a tabela na página 35 é uma continuação daquela na página 12, ou que a formatação mudou. Os dados saem como um fluxo incoerente de texto, exigindo horas de corte, colagem e reestruturação manual no Excel. Essa alternância constante e cheia de atrito de contexto e limpeza de dados é o que torna o processamento de documentos em larga escala tão incrivelmente doloroso e caro. Não se trata apenas de ler caracteres; trata-se de conquistar o caos do layout.
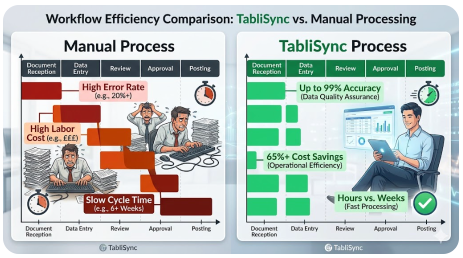
A Lacuna de Eficiência e Custo: Organização Manual vs. Conversão Automatizada TabliSync
Para entender verdadeiramente o valor da OCR de alta precisão e da extração automatizada de dados, precisamos comparar o status quo — organizar manualmente os dados em um arquivo Excel — com a conversão usando TabliSync. A diferença não é apenas marginal; é transformadora em termos de [eficiência, economia de custos e qualidade dos dados]. Vamos detalhar a economia e as realidades operacionais de ambas as abordagens usando benchmarks e cenários reais da indústria.
Os Custos Ocultos do Status Quo Manual
Processar manualmente 10.000 documentos por mês é uma tarefa monumental. Um especialista experiente em entrada de dados pode processar, em média, talvez 40-60 documentos complexos (como faturas com várias linhas) por hora, incluindo verificação. Para lidar com 10.000 documentos, você precisaria de aproximadamente 200 horas de trabalho focado. Com um custo médio total de US$ 30/hora (incluindo benefícios e despesas gerais), seu custo mensal de mão de obra apenas para entrada de dados é de US$ 6.000.
- [Altas Taxas de Erro]: A entrada de dados humana normalmente tem uma taxa de erro de 1-3%. Para 10.000 documentos, isso significa 100-300 documentos com dados incorretos, levando a [problemas de reconciliação] caros, atrasos de pagamento ou problemas de conformidade.
- [Problemas de Escalabilidade]: Para dobrar sua capacidade, você deve dobrar seu quadro de funcionários, levando a aumentos proporcionais de custos e sobrecarga gerencial. [Escalar é linear e caro].
- [Tempos de Ciclo Lentos]: Pode levar dias ou semanas para processar um grande lote, atrasando a visibilidade financeira e a tomada de decisões operacionais. [Dados lentos equivalem a negócios lentos].
- [Baixo Moral dos Funcionários]: A entrada de dados é repetitiva e entorpecente, levando a alta [rotatividade] de funcionários e custos associados de recrutamento.
A Vantagem TabliSync: Eficiência e Economia Realizadas
Agora, vamos analisar os mesmos 10.000 documentos processados com a solução Batch OCR para Excel da TabliSync. A TabliSync pode processar milhares de páginas por hora. O esforço manual muda de 'entrada' para 'tratamento de exceções' e 'verificação'. Normalmente, para documentos de alta qualidade, as taxas de automação podem exceder 90-95%, o que significa que apenas 5-10% dos documentos exigem revisão humana.
Em vez de 200 horas, sua equipe pode gastar 20 horas verificando exceções. Com a mesma taxa de $30/hora, seu custo de mão de obra cai para $600. O custo da plataforma TabliSync (assumindo um nível SaaS típico para este volume) pode ser de cerca de $1.500/mês. Seu custo total agora é de $2.100 — uma [redução de 65%] nos custos operacionais. Mas as economias não param por aí.
- [Taxas de Erro Drasticamente Menores]: O motor baseado em IA do TabliSync oferece até 99% de precisão, reduzindo significativamente os custos associados a erros de dados.
- [Escalabilidade Quase Instantânea]: Para processar 20.000 documentos, basta ajustar sua assinatura. Não há necessidade de contratar ou treinar novos funcionários. [A escalabilidade é exponencial e econômica].
- [Tempos de Ciclo Rápidos]: Lotes que levavam semanas agora são processados em horas, proporcionando [visibilidade financeira em tempo real].
- [Trabalho de Maior Valor]: Sua equipe é liberada para [tarefas analíticas], planejamento estratégico e gerenciamento de relacionamento com fornecedores.
- [Conformidade Aprimorada]: Cada extração é registrada e auditável, criando uma [trilha de auditoria] robusta e reduzindo o risco regulatório.
Considere uma grande empresa de logística que mudou para o TabliSync para processar conhecimentos de embarque. Eles reduziram sua equipe de entrada de dados de 15 para 3 pessoas, enquanto *aumentaram* seu volume de processamento em 40%. Os 12 membros da equipe foram requalificados e realocados para funções de alto valor em planejamento logístico e suporte ao cliente. As economias de custo diretas foram superiores a $450.000 anualmente, sem incluir o valor derivado de ciclos de faturamento mais rápidos e erros reduzidos. Este é o impacto quantificável de passar do caos manual para a precisão automatizada.
Guia Passo a Passo para Executar um Projeto de OCR em Lote em Larga Escala para Excel
Agora que você entende o poderoso caso de negócios para OCR em Lote para Excel, vamos percorrer a execução real usando uma plataforma poderosa como o TabliSync. O processamento de documentos em massa bem-sucedido não se trata apenas de clicar em um botão; envolve uma abordagem metódica para garantir precisão, estrutura e fluxo de dados contínuo. Este guia descreverá as etapas precisas, com detalhes de configuração e melhores práticas operacionais, para levá-lo de uma montanha de documentos a dados estruturados e acionáveis do Excel.
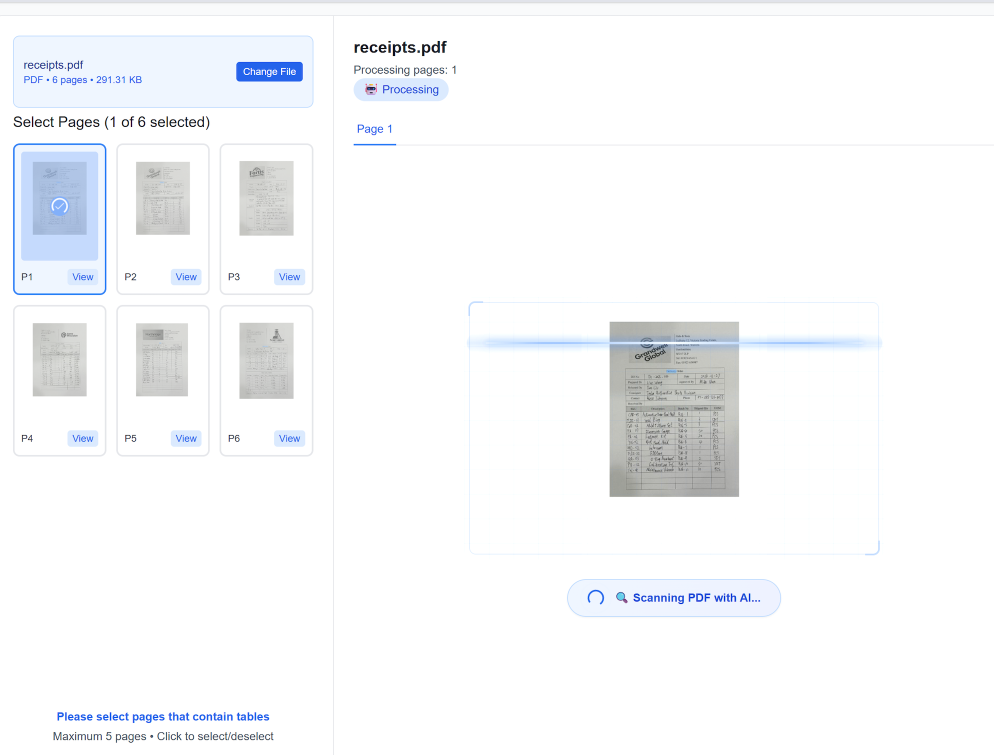
Etapa 1: Configuração do Lote e Ingestão de Documentos
A primeira e talvez mais crítica etapa é configurar seu lote e ingerir seus diversos documentos. É aqui que você supera o gargalo de múltiplos formatos. No TabliSync, você não precisa pré-classificar os arquivos. Você simplesmente faz login em seu painel seguro e cria um novo [Lote de Processamento]. Dentro das configurações de configuração, você especifica o [formato de saída] (neste caso, Excel), suas [configurações de motor OCR] preferidas (por exemplo, equilibrar velocidade vs. precisão para digitalizações particularmente granuladas) e quaisquer [regras de pré-processamento], como rotação automática ou redução de ruído.
Uma vez configurado, você tem várias opções de ingestão para seus grandes conjuntos de dados. Para algumas centenas de arquivos, a interface de [upload direto pela web] é suficiente. Para milhares de documentos, você idealmente usaria nosso [gateway SFTP] seguro ou a poderosa [API TabliSync]. Por exemplo, uma empresa de logística global usa a API para rotear automaticamente e-mails recebidos com anexos diretamente para um lote de processamento, eliminando o manuseio manual completamente. O TabliSync aceita praticamente qualquer formato — PDFs de várias páginas, TIFFs complexos, JPEGs e até arquivos ZIP contendo uma mistura de tipos de arquivo. O sistema [descompacta, padroniza e prepara] automaticamente cada documento para a próxima etapa, fornecendo um log de ingestão em tempo real.
[Nota de Cautela]: Ao configurar seu lote, preste muita atenção à [configuração de idioma do documento]. Embora o TabliSync suporte vários idiomas, selecionar o idioma principal dos documentos aumenta significativamente a precisão, especialmente para variações sutis de caracteres ou símbolos de moeda. Além disso, para documentos digitalizados, certifique-se de que eles tenham uma resolução de pelo menos [300 DPI] para resultados confiáveis; digitalizações de resolução muito baixa são a maior causa de erros de OCR.
Etapa 2: Análise Inteligente de Layout e Análise de Tabela
Com os documentos ingeridos, o motor de IA principal do TabliSync entra em ação. Esta etapa não se trata de ler texto; trata-se de entender a [hierarquia visual e as relações estruturais] dentro de cada página. É aqui que a análise de tabelas financeiras se torna crucial. Nosso motor não procura apenas palavras-chave; ele analisa espaços em branco, alinhamento e pistas de formatação para identificar [tabelas, itens de linha, cabeçalhos e pares de chave-valor] (como 'Data da Fatura' e sua data correspondente).
Este é um processo sem modelo. A IA do TabliSync foi treinada em milhões de documentos diversos, portanto, reconhece automaticamente que uma tabela de itens de linha em uma fatura de fornecedor é uma única entidade, mesmo que se estenda por várias páginas e não tenha linhas de borda claras. Para a análise de tabelas financeiras, ele separa inteligentemente a [quantidade, preço unitário, descrição e total da linha] em colunas discretas e precisas. Você pode monitorar esse progresso através do painel do TabliSync, que mostra exatamente quais documentos estão sendo analisados e sinaliza aqueles em que o layout é ambíguo para revisão humana.
Para garantir resultados de nível profissional para a reconciliação do seu [Razão Geral], use as regras de validação do TabliSync. Você pode configurar regras que verificam se os totais de itens de linha individuais somam o subtotal da fatura, ou se o valor do imposto é calculado corretamente com base em uma taxa especificada. Isso vai além da simples extração e adiciona uma camada de [validação de lógica de negócios], garantindo que os dados que chegam ao seu arquivo Excel não sejam apenas precisos, mas também logicamente consistentes, acelerando significativamente seus processos de Reconciliação posteriores.
Etapa 3: Validação de Dados, Tratamento de Exceções e Exportação para Excel
A etapa final é refinar os dados extraídos, lidar com quaisquer exceções e exportar as informações finalizadas e estruturadas para o Excel. Após a IA concluir sua análise, o TabliSync apresenta uma [Interface de Verificação]. Aqui, os documentos são sinalizados para revisão humana apenas se a pontuação de confiança da IA para campos-chave cair abaixo do seu limite predefinido. Por exemplo, se uma nota manuscrita particularmente confusa obscurecer um 'Valor Total', o sistema sinalizará esse documento específico.
Na tela de verificação, você pode ver a imagem original do documento lado a lado com os dados extraídos. Sua equipe pode [corrigir rapidamente quaisquer erros], adicionando inteligência humana onde a IA teve dificuldades. Para um lote típico, essa revisão é incrivelmente rápida porque você está olhando apenas para as exceções sinalizadas, não para todos os 10.000 documentos. Para processamento de documentos em lote, essa abordagem de "humano no circuito" é fundamental para manter a integridade dos dados próxima de 100%. A interface é otimizada para velocidade, permitindo que os verificadores naveguem pelos campos e usem atalhos de teclado para correções rápidas. Assim que todos os documentos forem verificados, basta clicar em [Exportar para Excel].
O TabliSync não fornece apenas um despejo bruto de texto; ele fornece uma planilha Excel lindamente estruturada e com várias abas. Uma aba pode conter os [dados em nível de cabeçalho] (Número da Fatura, Data, Nome do Fornecedor), enquanto outra aba pode conter todos os [itens de linha detalhados] (SKU do Produto, Descrição, Quantidade, Preço), com um identificador exclusivo os vinculando. Essa estrutura relacional é inestimável para análises complexas e integração com ERP. Além disso, você pode configurar a exportação para usar [tipos de dados Excel] específicos (por exemplo, formatar datas como datas e moeda como números), garantindo que os dados estejam prontos para uso imediato em tabelas dinâmicas ou modelagem financeira, sem a necessidade de qualquer limpeza manual.
O Impacto Estratégico: Por Que OCR em Lote para Excel é uma Competência Essencial, Não um Complemento
Por muito tempo, as empresas trataram o processamento de documentos como uma tarefa administrativa de back-office — um centro de custo necessário. Este é um erro estratégico profundo. Na era digital, sua capacidade de extração automatizada de dados de documentos não estruturados que impulsionam seus negócios é um [determinante direto] da sua velocidade operacional, agilidade financeira e, em última análise, da sua vantagem competitiva. Dominar o OCR em Lote para Excel não se trata apenas de economizar tempo; trata-se de desbloquear o valor latente nos dados da sua organização.
Considere o valor estratégico de ter [dados financeiros quase em tempo real]. Quando você pode processar 10.000 faturas em horas em vez de semanas, sua equipe de contas a pagar não está mais reagindo a eventos passados. Eles estão [gerenciando ativamente o fluxo de caixa], otimizando o capital de giro e aproveitando os descontos de pagamento antecipado. Sua equipe de compras pode analisar dados de itens de linha em milhares de compras para identificar padrões de gastos e negociar melhores condições com os fornecedores. Suas equipes de conformidade e auditoria têm uma [trilha de auditoria instantânea e verificável] para cada transação, reduzindo drasticamente o custo e o risco associados às auditorias. Esse nível de capacidade de resposta só é possível com uma solução robusta, de alta precisão e de processamento em lote.
Além disso, essa agilidade de dados é a base para iniciativas avançadas de análise e IA. Um [Razão Geral] que é atualizado em tempo real com dados de itens de linha precisos e detalhados torna-se uma ferramenta poderosa para previsão e planejamento estratégico. Você pode alimentar esses dados estruturados em modelos de aprendizado de máquina para prever a demanda, otimizar os níveis de estoque ou detectar transações fraudulentas. Os dados não estruturados ocultos em seus documentos são o combustível para sua transformação digital, e o OCR em Lote para Excel é a refinaria que os torna utilizáveis. Ignorar isso é o mesmo que ter um campo de petróleo e se recusar a construir um oleoduto.
FAQ Detalhado: Abordando a Complexidade do OCR em Lote para Excel em Grande Escala
Passar de um processo manual para uma solução complexa e automatizada de OCR em Lote para Excel invariavelmente levanta questões técnicas e operacionais. Esta seção de FAQ baseia-se em profundo conhecimento de implantação de centenas de projetos de automação de documentos em grande escala. Abordamos não apenas o "como", mas o "porquê" e os "e se", fornecendo o entendimento sutil que você precisa para uma implantação bem-sucedida e profissional.
Qual é a Diferença Entre Detecção de Tabela e Extração de Tabela?
Esta é uma distinção crítica que muitas vezes é negligenciada. A [Detecção] de tabelas é simplesmente identificar que uma tabela existe em uma página e desenhar uma caixa ao redor dela. Muitas ferramentas genéricas de OCR param por aqui. A [Extração] de tabelas, no entanto, é a tarefa muito mais complexa de entender a estrutura interna dessa tabela. Envolve identificar com precisão linhas, colunas, cabeçalhos e os dados precisos dentro de cada célula, mesmo que a tabela não tenha bordas ou células complexas e mescladas. Para análise de tabelas financeiras, a extração confiável é inegociável. O TabliSync usa análise avançada de layout para não apenas detectar a tabela, mas para recriar sua estrutura e dados com alta fidelidade no Excel.
O TabliSync Pode Lidar com Documentos Digitalizados, de Baixa Qualidade ou Inclinados?
Sim, mas com ressalvas. O motor do TabliSync é altamente robusto e inclui recursos automáticos de [pré-processamento] de imagem. Ele pode corrigir a inclinação de documentos, reduzir ruído e aguçar o texto para melhorar o reconhecimento. Nosso OCR de alta precisão é particularmente eficaz com layouts complexos e qualidade de impressão variada. No entanto, a regra cardinal do OCR ainda se aplica: [lixo entra, lixo sai]. Documentos com borrões extremos, caligrafia significativa sobre texto crítico ou uma resolução abaixo de [300 DPI] sempre terão menor precisão de extração. Para esses casos, o TabliSync sinaliza o documento para verificação humana para garantir que nenhum dado incorreto chegue ao seu relatório final do Excel.
O TabliSync Está em Conformidade com o GDPR e CCPA?
A privacidade dos dados é fundamental, especialmente ao lidar com documentos financeiros ou pessoais. O TabliSync é construído com segurança e conformidade de nível empresarial em seu núcleo. Estamos em total conformidade com o GDPR, CCPA e outros principais regulamentos de privacidade de dados. Todos os dados são [criptografados] em repouso e em trânsito. Além disso, oferecemos recursos como [redação] automática de PII e políticas de retenção de dados configuráveis, garantindo que você tenha controle total sobre como as informações confidenciais são processadas e armazenadas. Quando você se envolve em processamento de documentos em lote com o TabliSync, você o faz em uma plataforma que prioriza a segurança e a conformidade regulatória.
Como Posso Integrar o TabliSync ao Meu Sistema ERP ou de Contabilidade Existente?
A integração perfeita é fundamental para a automação real. Embora a exportação para o Excel seja poderosa, a integração direta é frequentemente o objetivo final. O TabliSync fornece uma [API robusta e bem documentada] que permite automatizar todo o pipeline. Você pode usar a API para enviar documentos para o TabliSync, monitorar seu status e extrair os dados estruturados e verificados diretamente para seu sistema ERP ou de contabilidade, como NetSuite, Salesforce ou QuickBooks. Também suportamos [Webhooks], para que seus outros sistemas possam ser notificados instantaneamente quando um lote de processamento for concluído, acionando ações automatizadas adicionais em seu fluxo de trabalho.
O que acontece se a IA não conseguir extrair corretamente um ponto de dados crítico?
É aqui que a etapa de validação "humano no circuito" é crucial. O TabliSync não adivinha; ele fornece uma pontuação de confiança para cada ponto de dados extraído. Se a pontuação de confiança para um campo crítico (por exemplo, 'Valor Total') cair abaixo de um limite que você definir, o documento é automaticamente sinalizado e apresentado na [Interface de Verificação]. Sua equipe pode então revisar e corrigir rapidamente esse ponto específico. Isso garante que apenas dados 100% verificados e precisos sejam exportados para seu arquivo Excel final, mantendo a alta integridade dos dados necessária para Reconciliação profissional e relatórios financeiros.
O TabliSync pode processar documentos de várias páginas onde uma tabela se estende por várias páginas?
Sim, essa é uma força central do nosso motor de análise de tabelas financeiras. O TabliSync pode rastrear tabelas de forma inteligente em várias páginas. Ele reconhece os cabeçalhos da tabela na primeira página e entende que as páginas subsequentes são uma continuação da mesma tabela, mesmo que os cabeçalhos não sejam repetidos. Ele consolida todos os dados em uma [tabela única e contínua] na sua saída do Excel, preservando a estrutura relacional dos dados e economizando horas de trabalho manual de consolidação que seriam necessárias de outra forma.
Que tipos de 'exceções' um humano precisa lidar?
As exceções não se limitam a baixa confiança de OCR. Elas também podem envolver [validação de lógica de negócios]. Por exemplo, o TabliSync pode verificar se a soma calculada dos itens de linha extraídos é igual ao total da fatura extraída. Se não for, esse documento se torna uma exceção. Isso pode ser devido a um erro genuíno de extração, ou pode ser um erro de cálculo na própria fatura do fornecedor. Revisores humanos recebem o contexto para resolver rapidamente o problema, seja corrigindo a extração ou sinalizando o documento para a equipe financeira resolver com o fornecedor.
Existe um Limite para o Número de Documentos que Posso Processar em um Lote?
Embora existam limites práticos para um único lote para manter um desempenho gerenciável, o TabliSync é projetado para escala massiva. Para [grandes conjuntos de dados], recomendamos dividir o processamento em lotes lógicos (por exemplo, por fornecedor ou por mês). Nossos planos empresariais são projetados para escalar para [centenas de milhares ou até milhões] de documentos por ano. Para requisitos excepcionalmente grandes e de alto volume, podemos configurar recursos de processamento dedicados para garantir que seus fluxos de trabalho de [extração automatizada de dados] atendam aos seus SLAs precisos de velocidade e volume.
Desbloqueie Agilidade e Eficiência de Dados Sem Precedentes Hoje
Você explorou agora o cenário abrangente de OCR em Lote para Excel, desde os pontos problemáticos profundos do processamento manual até a execução precisa, passo a passo, em uma plataforma como o TabliSync. A capacidade de converter automática e precisamente montanhas de documentos não estruturados e multiformato em dados estruturados e acionáveis não é mais um ganho de eficiência periférico; é um imperativo de negócios central para qualquer organização que almeja excelência operacional e agilidade estratégica em um mundo orientado por dados. Os custos da inação — altos custos de mão de obra, erros de dados generalizados, lentidão nos ciclos e uma completa falta de escalabilidade — são simplesmente altos demais para serem ignorados.
Cada minuto que sua equipe gasta em entrada manual de dados é um minuto [roubado] de análise de alto valor, reconciliação de fornecedores e planejamento financeiro estratégico. O cenário competitivo não esperará que você modernize seu processamento de documentos. Organizações que adotam a extração automatizada de dados agora estão construindo uma base de agilidade operacional que renderá dividendos por muitos anos. Não deixe que seus dados críticos de negócios permaneçam presos em papel ou em arquivos digitais fragmentados. Assuma o controle de seu pipeline de dados e impulsione sua organização. Estamos tão confiantes na capacidade do TabliSync de transformar seus fluxos de trabalho que o convidamos a experimentá-lo em primeira mão. Pare de deixar que gargalos manuais o retenham. Inscreva-se para seu teste gratuito do TabliSync hoje e testemunhe o poder imediato e transformador do OCR de alta precisão. O futuro da agilidade dos seus dados começa agora — não demore.
Todos os Artigos de OCR em Lote para Excel(11)

Como Duplicar uma Planilha no Excel: Guia Passo a Passo
Este guia fornece instruções passo a passo sobre como duplicar uma planilha no Excel, ajudando os usuários a gerenciar suas planilhas de forma eficiente e precisa. Quer você esteja trabalhando com relatórios financeiros, planilhas de inventário ou qualquer outro dado, duplicar planilhas pode economizar tempo e garantir a consistência. Siga nossas instruções claras para dominar esta habilidade essencial do Excel. Ao final deste guia, você será capaz de duplicar planilhas com confiança e manter seu trabalho organizado. Não se esqueça de explorar como o TabliSync pode aprimorar ainda mais suas tarefas de gerenciamento de planilhas depois de aprender esta habilidade!

Solução de Problemas de Fórmulas Bloqueadas no Excel
Este guia de solução de problemas oferece aos usuários soluções práticas para desbloquear fórmulas no Excel, abordando problemas comuns e oferecendo dicas para prevenir problemas futuros. Fórmulas bloqueadas podem ser um obstáculo significativo para usuários de negócios, especialmente aqueles nas áreas de finanças e administração que dependem da manipulação precisa de dados. Através de uma abordagem passo a passo, este artigo ajuda os leitores a entender as causas das fórmulas bloqueadas e oferece estratégias eficazes para resolver esses problemas. Ao implementar as soluções descritas aqui, os usuários podem recuperar o controle de suas planilhas, garantindo que possam editar e gerenciar seus dados de forma eficaz, sem frustrações desnecessárias. O artigo também enfatiza as melhores práticas para prevenir tais problemas no futuro, contribuindo para fluxos de trabalho de planilhas mais suaves e eficientes, permitindo que os usuários se concentrem inteiramente no manuseio preciso de dados.

Como Adicionar um Menu Suspenso ao Excel
A entrada manual repetitiva de dados frequentemente causa inconsistência nos dados e baixa eficiência de trabalho para funcionários de negócios que utilizam o Excel. Este artigo explica as dificuldades na criação de menus suspensos no Excel e apresenta duas soluções, incluindo configuração manual e métodos de extração automatizada de dados. Ele também abrange etapas detalhadas de operação, verificações pré-exportação chave, erros comuns de configuração e FAQs. A construção de menus suspensos padronizados unifica efetivamente os padrões de entrada de dados, reduz erros manuais e otimiza fluxos de trabalho de processamento de dados de escritório diário e relatórios financeiros.

Como Adicionar Marcadores no Excel
"Este guia fornece instruções passo a passo para adicionar marcadores no Excel usando atalhos de teclado e o menu Faixa de Opções, juntamente com exemplos práticos de seu uso em documentos profissionais e dicas para formatação eficaz para melhorar a legibilidade geral."

Como Usar Atalhos de Teclado Colar Valores para Limpar Dados Complexos de Planilhas
Reduza o tempo de limpeza de dados em até 80% usando atalhos de teclado para colar valores diretamente, em vez de remover formatação manualmente. Elimine erros de formatação ocultos, fórmulas quebradas e tipos de dados inconsistentes de conjuntos de dados importados ou legados. Mantenha um pipeline de dados limpo e reproduzível sem macros ou VBA — apenas teclas nativas do Excel. Conecte fluxos de trabalho de dados estruturados e não estruturados combinando a colagem de valores com ferramentas de extração como o TabliSync.

Como Fazer Marcadores no Excel para Tabelas de Dados Limpas
Este guia cobre dois métodos eficientes para adicionar e limpar marcadores no Excel para tabelas de dados estruturadas e analisáveis. Ele explica fluxos de trabalho integrados do Excel, incluindo atalhos de teclado, funções CHAR, Power Query e Tabelas do Excel para tarefas de formatação simples e únicas. Ele também introduz a solução TabliSync, alimentada por IA, para extrair, padronizar e organizar automaticamente listas de marcadores desorganizadas de PDFs, capturas de tela e relatórios externos em linhas limpas do Excel, resolvendo problemas comuns de limpeza de dados e otimizando fluxos de trabalho de dados de negócios recorrentes para filtragem, análise e criação de painéis.

IA: Como Separar Nome Próprio e Sobrenome no Excel
Elimine erros de divisão manual de nomes usando análise baseada em IA, reduzindo o tempo de limpeza de dados em até 85%. Automatize a extração de nomes próprios e sobrenomes de PDFs e relatórios baseados em imagem, economizando mais de 10 horas por semana por analista. Mantenha a formatação consistente de nomes em conjuntos de dados com sincronização em tempo real, reduzindo falhas de reconciliação downstream em 90%.

Como Bloquear Células no Excel: Protegendo Dados Específicos Contra Alterações
Implemente proteção granular de células para garantir 0% de erros de substituição manual de fórmulas. Domine o fluxo de trabalho de bloqueio e proteção em duas etapas para economizar 90% do tempo gasto na auditoria de planilhas. Aproveite a sincronização de OCR impulsionada por IA para transformar dados não estruturados em ativos de negócios bloqueados e imutáveis.

Como Excluir Duplicatas e Originais no Excel: Um Guia Passo a Passo
Elimine 100% do Ruído: Domine a técnica para remover não apenas duplicatas, mas também as entradas originais, deixando apenas dados verdadeiramente exclusivos. Tempo Economizado em 90%: Transição da auditoria manual linha por linha para fluxos de trabalho automatizados de limpeza de dados. 0% Erro de Entrada Manual: Utilize OCR com IA para analisar dados não estruturados em esquemas limpos sem intervenção humana. Higiene de Dados Escalável: Implemente estratégias de alto nível para valores exclusivos no Excel que lidam com conjuntos de dados que excedem 100 mil linhas sem esforço.

Erro na Pasta de Trabalho do Excel: Desculpe, Não Conseguimos Encontrar Guia de Solução
* Corrija erros de inicialização do Excel instantaneamente identificando caminhos temporários locais ocultos. * Reduza o tempo de solução de problemas manuais em 90% usando validação automatizada de caminhos. * Alcance 0% de erro de entrada manual migrando dados não estruturados via OCR com IA. * Transforme links de arquivos quebrados em ativos de dados resilientes sincronizados na nuvem.

Como Desbloquear Planilha Excel sem Saber a Senha
Desbloqueie planilhas Excel sem senhas com 99,9% de integridade de dados; Reduza o tempo manual de recuperação em 90%; Execução perfeita de macros XML e VBA; OCR impulsionado por IA para extração de dados estruturados.
Chega de entrada manual – Extraia tabelas em segundos
Converta qualquer imagem ou tabela PDF para Excel instantaneamente com 99,9% de precisão. O OCR com IA do TabliSync processa formulários manuscritos, recibos e tabelas complexas e sincroniza diretamente com Google Sheets, Notion ou Airtable
Experimente o TabliSync gratuitamente agora