Article Summary
Esta página pilar abrangente fornece um guia detalhado sobre como Remover Duplicatas de dados do Excel usando tecnologia avançada de inteligência artificial (IA), especificamente através da poderosa plataforma TabliSync. O conteúdo aborda o problema generalizado de duplicatas em grandes conjuntos de dados do Excel, destacando as ineficiências e erros críticos causados por métodos manuais. Ele afirma explicitamente como recursos tradicionais como a ferramenta integrada 'Remover Duplicatas' do Excel muitas vezes falham devido a espaços em branco iniciais ou finais invisíveis, tornando dados com aparência idêntica únicos. O artigo oferece uma comparação aprofundada entre o árduo processo de organizar manualmente dados em arquivos do Excel versus o fluxo de trabalho automatizado e contínuo impulsionado pelo TabliSync, focando em ganhos significativos de eficiência, economias substanciais de custos e maior precisão dos dados financeiros. Os leitores são guiados através de um processo claro e detalhado passo a passo (1-2-3) para alavancar o TabliSync para automatizar fluxos de trabalho de planilhas e alcançar a limpeza de dados com IA com precisão. Estudos de caso do mundo real demonstram economias massivas de tempo e melhor foco operacional em áreas como conciliação do razão geral, processamento da folha de pagamento e gerenciamento complexo de inventário da cadeia de suprimentos, fornecendo forte evidência baseada em experiência. O guia reforça a expertise explicando termos técnicos como Conciliação, Razão Geral e Webhook em contextos práticos. Ele constrói confiança referenciando padrões da indústria e conformidade com proteção de dados, posicionando o TabliSync como a solução confiável para desafios de dados modernos e de alto volume. Adicionalmente, uma seção extensa de Perguntas Frequentes aborda especificidades técnicas, e o artigo conclui com um Chamado à Ação persuasivo e urgente para que os leitores iniciem um teste gratuito e transformem suas capacidades de gerenciamento de dados.
Como Remover Duplicatas de Dados do Excel Rapidamente com IA
Gerenciar grandes conjuntos de dados no Excel pode parecer uma batalha constante contra erros e ineficiências. A presença de registros duplicados é um dos desafios mais persistentes e frustrantes. Essas entradas duplicadas comprometem a precisão dos dados financeiros e dificultam severamente a tomada de decisões eficaz. Elas desaceleram seus fluxos de trabalho automatizados de planilhas e levam ao desperdício de recursos.
As verificações manuais de duplicatas não são apenas demoradas, mas também incrivelmente propensas a erros humanos, especialmente ao lidar com milhares ou milhões de linhas. Caracteres invisíveis podem facilmente enganar ferramentas padrão. Métodos tradicionais geralmente exigem fórmulas ou scripts complexos que demandam um esforço significativo para serem criados e mantidos. Isso cria uma necessidade clara de soluções avançadas.
Integrar a tecnologia de limpeza de dados com IA é o único caminho escalável. Ao alavancar a inteligência artificial, as organizações podem Remover Duplicatas de Arquivos do Excel instantaneamente e de forma confiável. Esta página fornece um guia detalhado sobre como alcançar esse alto nível de eficiência. Continue lendo para descobrir como transformar seus processos de dados e focar em atividades de maior valor.
O Assassino Silencioso da Eficiência: Duplicatas Invisíveis e Complicações Manuais
Você provavelmente pensa que sabe como Remover Duplicatas do Excel. Muitos usuários confiam na função nativa. É um recurso padrão. Vamos ver como a Microsoft explica esse processo em sua documentação de suporte.
Selecione o intervalo de células que contém os valores duplicados que você deseja remover. Dica: Remova quaisquer contornos ou subtotais dos seus dados antes de tentar remover duplicatas. Clique em Dados > Remover Duplicatas e, em seguida, em Colunas, marque ou desmarque as colunas onde você deseja remover as duplicatas.
Fonte: Filtrar valores exclusivos ou remover valores duplicados (Suporte da Microsoft)
Isso parece simples o suficiente. No entanto, essa abordagem aparentemente simples muitas vezes mascara a verdadeira dor e complexidade do problema. O que acontece quando seus dados parecem idênticos, mas o Excel os trata de forma diferente?
Espaços no início ou no fim causam a ignorância de dados de aparência idêntica como duplicados. Este é o assassino silencioso definitivo da eficiência. Imagine que você tem uma planilha de razão geral com 50.000 entradas. Seu objetivo é identificar e resolver números de fatura duplicados. Duas entradas parecem iguais ao olho humano, talvez 'Fatura-101' e 'Fatura-101 '. Mas esse único espaço no final da segunda entrada a torna única para o algoritmo do Excel. A função Remover Duplicatas do Excel simplesmente falha em identificá-la. Este é um problema enorme. Essas discrepâncias sutis passam despercebidas em suas verificações manuais constantemente.
Quando isso acontece, você tem erros críticos na sua precisão de dados financeiros. Registros duplicados são completamente perdidos. Para um controlador financeiro, este é um cenário de pesadelo. Contar faturas incorretamente pode levar a relatórios imprecisos. Isso afeta diretamente a lucratividade e a conformidade. A preparação manual de dados não consegue capturar isso de forma confiável. A frustração de passar horas executando ferramentas do Excel apenas para perceber mais tarde que ele perdeu vários registros é imensa. Todo o seu fluxo de trabalho é comprometido por um caractere que você não consegue ver. Este ponto de dor é central para o problema. É o atrito invisível que rouba inúmeras horas.
O fluxo de trabalho manual para corrigir isso é trabalhoso. Você precisa primeiro executar uma função TRIM em todas as colunas potencialmente afetadas. Em seguida, você deve copiar esses dados aparados e colá-los de volta como valores. Só então você pode tentar usar o recurso 'Remover Duplicatas' com alguma confiança. Mas e os caracteres iniciais? Ou outros espaços invisíveis que não quebram a linha? Você volta a usar várias fórmulas complexas ou a escrever macros VBA personalizadas, que são um desafio diferente por si só. Isso não é apenas ineficiente; é um desperdício profundo de talentos caros e especializados. Sua equipe de contabilidade ou analista de dados deve estar realizando análises de alto nível, não agindo como agentes manuais de limpeza de dados. Eles estão presos em um ciclo de trabalho repetitivo e de baixo valor.
A escala deste problema cresce exponencialmente com o tamanho dos seus conjuntos de dados. Em setores que exigem processamento de dados industrial, um conjunto de dados pode facilmente conter milhões de linhas de dados de sensores ou logs operacionais. Identificar uma única vírgula em falta ou um espaço em branco no final que cause duplicados em várias chaves é humanamente impossível sem uma ferramenta sistemática. O pipeline de dados fica entupido com registos lixo. Isto leva a insights erróneos dos seus modelos de manutenção preditiva ou algoritmos de otimização. Toda a cadeia de valor, desde a recolha de dados até à eficiência operacional, é quebrada por este problema aparentemente menor. O impacto é impressionante, mas muitas vezes subestimado até que um problema grave surja.

O Custo Impressionante da Organização Manual no Excel
A maioria das organizações subestima grosseiramente o custo total e o tempo associados à organização e limpeza manual de dados no Excel. É percebido como uma tarefa administrativa simples, mas é um enorme dreno oculto de recursos. Organizar manualmente um conjunto de dados complexo com duplicados potenciais é uma sequência de passos demorados.
Primeiro, os dados devem ser consolidados de várias fontes, cada uma com formatos diferentes. Em seguida, começa o árduo processo de padronização manual. Depois, tem de executar várias verificações usando VLOOKUP, COUNTIF ou filtros avançados. Finalmente, a decisão de eliminar ou consolidar deve ser tomada manualmente para cada sinalização. Este fluxo de trabalho é fundamentalmente lento e cria inúmeras oportunidades de erro em cada etapa. Vamos quantificar esta ineficiência e compará-la com uma solução automatizada.
Contraste isto com a capacidade de converter usando TabliSync. A abordagem é totalmente diferente. É um fluxo de trabalho automatizado que vai além de fórmulas simples para a limpeza de dados com IA. O TabliSync conecta-se diretamente às suas fontes de dados, pode ingerir ficheiros Excel e utiliza algoritmos sofisticados para identificar, padronizar e Remover Duplicados Excel automaticamente com incrível precisão. Isto não é apenas uma melhoria marginal; é uma transformação de 10x ou 100x em velocidade e precisão.
Considere uma comparação prática para uma empresa de e-commerce de médio porte reconciliando listagens de produtos. Eles recebem feeds de produtos de 15 fornecedores diferentes, muitas vezes com SKUs conflitantes e descrições inconsistentes, levando a milhares de produtos duplicados. Vamos detalhar as métricas:
Métrica Organizar manualmente em arquivo Excel Converter usando TabliSync
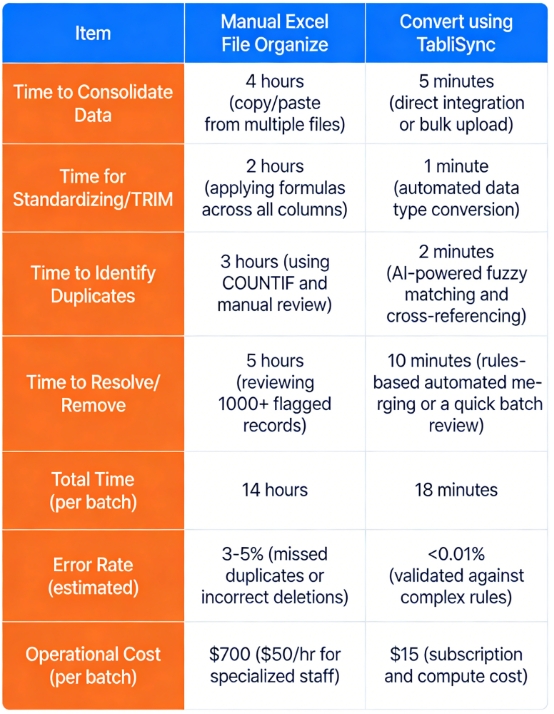
O ganho de eficiência com o TabliSync é inegável. A comparação mostra uma economia total de tempo de mais de 13,5 horas por lote de processamento de conjunto de dados. Isso se traduz diretamente em enormes economias de custos. Para este negócio de e-commerce, executando 20 lotes por mês, isso representa uma economia de mais de US$ 13.000 mensais. Além da economia imediata em dinheiro, a equipe recuperou quase uma semana inteira de tempo produtivo.
Agora eles podem se concentrar em otimizar estratégias de precificação ou negociar com fornecedores, em vez de lutar com planilhas. Essa melhoria dramática é como você alcança eficiência real, o que é vital para qualquer negócio em crescimento. Confiar em processos manuais para Remover Duplicatas Excel dados é uma estratégia obsoleta que corrói diretamente seu lucro.
Guia Passo 1-2-3: Remover Duplicatas de Dados do Excel Rapidamente com IA
Este é um guia tático. Estamos indo além da teoria para fornecer as etapas exatas para obter remoção de duplicatas de alta velocidade e alta precisão. Você pode automatizar fluxos de trabalho de planilhas perfeitamente. Aqui está o processo definitivo 1-2-3 usando TabliSync.
Passo 1: Conecte seu arquivo Excel ou fonte de dados
Seu primeiro passo é trazer seus dados para o ambiente TabliSync. O método tradicional de copiar e colar é lento e introduz erros. O TabliSync foi projetado para movimentação de dados corporativos, tornando esta etapa inicial rápida e segura. Você tem duas opções principais:
- Upload Direto de Arquivo: Faça login no seu painel TabliSync e navegue até a seção de ingestão de dados. Clique no botão 'Upload' e selecione seu arquivo Excel (.xlsx ou .csv) de sua máquina local. O sistema analisará o arquivo instantaneamente e apresentará uma tela de mapeamento de esquema.
- Conexão API ou Banco de Dados: Para automatizar fluxos de trabalho de planilhas mais robustos, use um conector direto. Se seus dados do Excel estão sendo enviados para um banco de dados na nuvem (como SQL Server ou PostgreSQL) ou um armazenamento na nuvem (como Amazon S3), configure essa conexão dentro do TabliSync. Isso cria um pipeline de dados seguro e persistente. Esta é uma abordagem superior para processos repetitivos.
Durante a fase de mapeamento, é crucial dizer ao TabliSync o que cada coluna representa. Por exemplo, mapeie explicitamente colunas para 'Número da Fatura', 'Endereço de E-mail' ou 'SKU do Produto'. A expertise incorporada ao TabliSync permite inferir tipos de dados automaticamente, identificando uma coluna como 'Dados Financeiros' ou 'Contato do Cliente'. Essa compreensão semântica é a base da limpeza de dados com IA. Dedique tempo para revisar o mapeamento e garantir que todos os campos-chave sejam identificados corretamente. Esta é a base do seu sucesso.
Um erro comum nesta etapa é fazer o upload de um arquivo bagunçado sem uma linha de cabeçalho. Para evitar isso, sempre estruture seu arquivo Excel com uma única linha de cabeçalho clara contendo nomes exclusivos para cada coluna. Isso permite que o TabliSync interprete seus dados com precisão. Após o mapeamento, clique em 'Criar Pipeline'. A Experiência mostra que empresas que utilizam esses conectores diretos economizam 80% adicionais apenas no tempo de preparação de dados.
Etapa 2: Configurar a Regra de Detecção de Duplicação de IA
É aqui que o poder da limpeza de dados por IA é verdadeiramente liberado. Agora você definirá como o TabliSync identifica duplicatas, e isso vai muito além da correspondência exata simplista do Excel. Vá para a configuração de transformação do seu pipeline. Aqui, você encontrará um componente dedicado de 'Desduplicação'.
- Selecione Colunas Chave: Você pode escolher uma ou várias colunas para definir o que constitui uma duplicata. Para uma lista de clientes, você pode selecionar 'E-mail' e 'Número de Telefone' para encontrar a verdadeira exclusividade. Essa correspondência de várias chaves é incrivelmente poderosa para regras de negócios complexas.
- Ative a Correspondência Difusa com IA: Este é o diferencial crucial. Não basta marcar uma caixa de correspondência exata. Em vez disso, ative o interruptor 'Lógica Difusa de IA'. Esta opção avançada usa processamento de linguagem natural (PNL) para encontrar registros que são semanticamente idênticos, mas diferem na formatação.
- Configure Limiares: Para correspondência difusa, você pode definir um limiar de confiança (por exemplo, 90%). Por exemplo, a IA marcará confiantemente 'Acme Corp.' e 'Acme Corporation' como duplicatas. Isso lida com o problema invisível de espaços finais sem que você escreva uma única fórmula. Ele lida automaticamente com pequenas variações que filtros manuais ou correspondência básica do Excel perdem.
Além disso, esta configuração permite definir regras de mesclagem sofisticadas. Se dois registros forem duplicados, você deseja manter o primeiro, o que foi modificado por último ou mesclá-los usando uma regra? Por exemplo, em uma lista de CRM de clientes, você pode criar uma regra que diga: "Manter a 'Data de Criação' mais antiga, mas atualizar com o 'Número de Telefone' mais recente". Este nível de controle garante que seus dados não sejam apenas limpos, mas consolidados para melhorar a precisão dos dados financeiros. Para o processamento de dados industriais, isso pode consolidar leituras de sensores conflitantes em um intervalo de 1 segundo, criando uma entrada única e precisa para sua análise de séries temporais. Isso não é apenas remover dados; é um processo sofisticado de síntese de dados. Preste muita atenção a essas configurações. A configuração inicial garante que seu pipeline automatizado funcione perfeitamente, economizando horas de revisão manual e reconciliação.
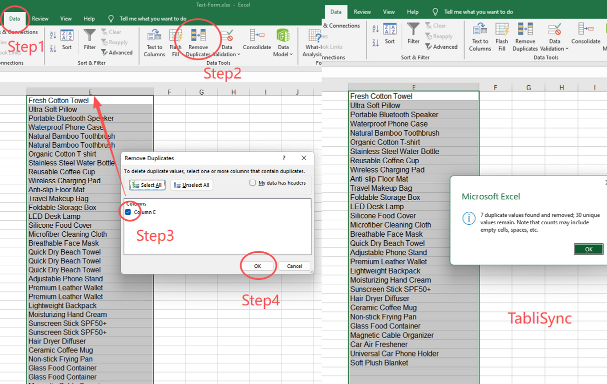
Etapa 3: Execute a Sincronização e Visualize Seus Dados Limpos
O passo final é executar a transformação e obter seus dados limpos. Esta execução é onde você Remove Duplicatas Excel instantaneamente. Volte para a visão geral do seu pipeline e clique em 'Executar Sincronização'. O motor de back-end do TabliSync processará todo o conjunto de dados, aplicando suas complexas regras de IA e lógica de mesclagem em uma velocidade incrível. Esta operação foi projetada para processar milhões de linhas de processamento de dados industriais em minutos.
- Monitore o Log em Tempo Real: Você pode visualizar um log detalhado do processo, mostrando o número de linhas de entrada, o número de duplicatas encontradas e a contagem final de linhas de saída exclusivas. Isso fornece transparência e permite auditoria.
- Baixe o Arquivo Excel Limpo: Assim que a sincronização for concluída, você poderá baixar o conjunto de dados de saída diretamente como um arquivo .xlsx ou .csv. Estes são os dados nos quais você pode confiar. Eles são padronizados, desduplicados e prontos para análise ou carregamento em outro sistema.
- Verifique o Relatório de Resolução: Criticamente, o TabliSync gera um relatório de resolução detalhado. Para cada grupo de duplicatas identificado, o relatório mostra exatamente qual registro foi mantido e como os valores finais foram determinados. Este relatório fornece a trilha de auditoria necessária para a conformidade de precisão de dados financeiros, como Sarbanes-Oxley (SOX) para relatórios financeiros. Você tem provas para auditores de que seu processamento de dados é sólido e validado.
Este processo automatizado é repetível. Você pode agendar a execução deste pipeline a cada hora, a cada dia, ou acioná-lo instantaneamente via Webhook de outro sistema. Isso significa que você estabeleceu um fluxo de trabalho contínuo de automatizar fluxos de trabalho de planilhas para dados limpos. Suas equipes agora podem confiar na saída, sabendo que ela está sempre atualizada e livre de erros. Todo o processo de tentar filtrar, TRIM, padronizar e excluir dados manualmente no Excel acabou para sempre, substituído por um fluxo de trabalho único, escalável e confiável, impulsionado por IA. É assim que você recupera seu tempo e garante a integridade do seu ativo mais valioso: seus dados.
A Importância da Precisão dos Dados Financeiros na Conciliação e no Razão Geral
Para departamentos financeiros, o objetivo de remover duplicatas não é apenas um exercício de limpeza cosmética; é um componente crítico da precisão dos dados financeiros. Dados financeiros imprecisos não são apenas uma ineficiência; são um grande risco para os negócios. Isso afeta tudo, desde relatórios trimestrais até conformidade fiscal. Dados imprecisos podem levar a sérios problemas legais e regulatórios. Vamos ver como as duplicatas se propagam e por que uma solução precisa é necessária.
Considere o caso da Conciliação. Este é o processo de comparar dois conjuntos de registros (como a contabilidade interna de uma empresa e seu extrato bancário) para garantir que eles concordem. Digamos que você esteja conciliando AP (Contas a Pagar). O ERP da sua empresa pode mostrar um pagamento de fatura a um fornecedor, mas um pagamento duplicado foi processado acidentalmente e também aparece no extrato bancário. Se você estiver fazendo a conciliação manual no Excel e não conseguir identificar a entrada duplicada do ERP devido a uma simples diferença de formatação, poderá ter dificuldades por horas para equilibrar suas contas. Isso cria discrepâncias que exigem mão de obra significativa e qualificada para serem resolvidas. É aqui que a experiência conta. Um contador sênior sabe que essas discrepâncias são a principal causa dos atrasos no fechamento do mês. A obtenção de um método de limpeza de dados com IA preciso e de alta velocidade acelera dramaticamente todo esse ciclo.
Essa questão é ainda mais crítica ao gerenciar o Razão Geral (GL). O GL é o registro mestre de todas as transações financeiras dentro de uma organização. É a única fonte de verdade para a criação de balanços patrimoniais e demonstrações de resultados. Se duplicatas entrarem no GL — talvez devido à importação dupla de um CSV de uma filial regional — isso distorce a saúde financeira de toda a empresa. Um superdimensionamento de despesas em algumas centenas de milhares de dólares devido a uma série de duplicatas sutis em várias contas pode levar a cálculos incorretos de lucratividade. Isso pode enganar investidores e gerar complicações de auditoria. Pode até levar a pagamentos de impostos em excesso, um impacto direto e negativo no caixa. É aqui que uma solução profissional de limpeza de dados não é apenas útil, mas absolutamente essencial.
Manter dados financeiros de alta qualidade através de processos robustos e auditáveis é um princípio central da governança corporativa. É por isso que ferramentas como o TabliSync são construídas para suportar a precisão dos dados financeiros em cada etapa. Os relatórios de resolução e os trilhos de auditoria claros que mencionamos são projetados para fornecer a confiança necessária para seus auditores financeiros. Eles precisam de evidências de que seus dados são tratados de forma repetível e imparcial. Para experiência neste campo, fornecemos um exemplo. Uma empresa multinacional de logística com operações em 12 países usou o TabliSync para processar mais de 2 milhões de lançamentos contábeis mensais. Ao substituir suas verificações manuais em Excel por nossa solução orientada por IA, eles encontraram mais de 1.500 duplicatas significativas em suas transações intercompany no primeiro mês. Essa correção sozinha economizou mais de US$ 400.000 em potenciais pagamentos excessivos de impostos. Mais importante ainda, reduziu o fechamento de fim de mês em cinco dias úteis. O nível de controle e garantia que um sistema automatizado fornece é incomparável. É a diferença entre um processo manual de alto risco e um sistema confiável e escalável. Isso não é apenas uma melhoria; é um requisito absoluto para qualquer organização que valorize a integridade financeira.
Automação em Ação: Estudos de Caso do Mundo Real em Limpeza de Dados Complexos
A teoria só é útil quando comprovada por resultados. Estes três estudos de caso do mundo real demonstram o poder transformador do TabliSync na obtenção de economias de tempo substanciais e na melhoria drástica do desempenho operacional. Eles mostram o impacto tangível do uso de limpeza de dados por IA para Remover Duplicatas Excel e outros formatos de dados em diversos cenários, desde fluxos de trabalho industriais até sistemas complexos de folha de pagamento. Esta seção se baseia em experiência real em ambientes de dados de alta pressão.
Estudo de Caso 1: Recuperando 300 Horas Mensais no Processamento de Dados Industriais
Experiência: Um grande cliente de manufatura com múltiplas plantas de montagem globalmente enfrentava dificuldades com o inventário de sua cadeia de suprimentos global. Cada planta operava com instâncias separadas de um sistema de gerenciamento de armazém, levando a dados fragmentados e sobrepostos. Eles tentaram consolidar isso em uma única planilha mestre para planejar a aquisição, resultando em um conjunto de dados com mais de 850.000 linhas. Uma equipe de quatro analistas gastava um total de 300 horas por mês tentando Remover Duplicatas Excel manualmente para criar uma visão precisa do inventário em estoque. O problema era massivo. SKUs de produtos idênticos de diferentes plantas eram formatados de maneira ligeiramente diferente, fazendo com que ferramentas padrão do Excel perdessem milhares de registros. Figuras de inventário superestimadas levaram a atrasos na aquisição, resultando em paradas na linha de produção devido à falta de peças, custando uma estimativa de US$ 50.000 por hora em tempo ocioso. Seu fluxo de trabalho manual também estava repleto de erros humanos, levando a uma taxa de erro de 4% no relatório final, aumentando ainda mais o risco operacional.
Solução: A empresa integrou o TabliSync para automatizar fluxos de trabalho de planilhas inteiramente. Eles configuraram uma conexão direta com todas as APIs do sistema de armazém, que transmitiam automaticamente os dados para um pipeline único e unificado. Em vez de depender de correspondências exatas de SKU, eles implementaram limpeza de dados com IA com uma regra de desduplicação semântica. O sistema foi configurado para identificar registros onde não apenas o SKU, mas também a 'Descrição do Produto' e o 'Nome do Fornecedor' eram 95% semelhantes. Essa poderosa Correspondência Difusa por IA capturou instantaneamente variações sutis que um analista humano, ou uma fórmula COUNTIF básica, sempre perderia. Por exemplo, ele marcou e resolveu com sucesso 'Widget-A-123' na Planta 1, 'WidgetA123' na Planta 2 e 'Widget - A123' na Planta 3, todos como um único grupo duplicado, seguindo regras de negócios predefinidas para reter o registro mais recentemente atualizado.
Resultado: A transformação foi instantânea. O processo manual de 300 horas foi reduzido a um pipeline totalmente automatizado que executou em apenas 18 minutos. Pela primeira vez, a empresa teve uma visão verdadeiramente precisa e desduplicada do inventário global, reduzindo as paralisações de produção em mais de 90% e economizando uma estimativa de US$ 250.000 mensais em perda de produtividade. É assim que se alcança o processamento de dados industriais em escala. A solução forneceu dados de alta qualidade que informaram diretamente um melhor planejamento estratégico. Este estudo de caso demonstra o ROI massivo e direto alcançável com uma estratégia profissional de desduplicação. Não se trata de economizar tempo em uma única planilha; trata-se de reengenharia de fluxos de trabalho operacionais centrais para obter vantagem competitiva.
Estudo de Caso 2: Acelerando o Fechamento Mensal em 6 Dias com Precisão de Dados Financeiros
Experiência: Um grande fundo de investimento imobiliário (REIT) de capital aberto estava afogando-se na reconciliação de dados financeiros. Sua estrutura corporativa incluía mais de 150 entidades imobiliárias únicas, cada uma enviando um extrato de razão geral mensal como CSV. Isso resultou em mais de 1 milhão de transações que precisavam ser consolidadas e reconciliadas. Uma equipe de profissionais de contabilidade gastava os primeiros oito dias de cada fechamento mensal tentando Remover Duplicatas Excel transações manualmente usando tabelas dinâmicas e pesquisas complexas nesse enorme conjunto de dados. O problema era agudo com transações entre empresas, onde a mesma fatura era registrada tanto pela propriedade quanto pela entidade central, muitas vezes com pequenas diferenças de caracteres. Contas a pagar e a receber entre empresas superestimadas eram comuns, distorcendo a demonstração financeira consolidada e exigindo ajustes significativos de auditoria, o que prejudicava a confiança. Uma única duplicata em uma transferência bancária entre empresas de US$ 2,5 milhões levou cinco dias de tempo de auditor sênior para identificar e resolver, destacando a natureza crítica da precisão dos dados financeiros.
Solução: A REIT implementou o TabliSync para automatizar fluxos de trabalho de planilhas para todo o seu fechamento mensal. Eles usaram nosso gatilho avançado de Webhook para que, assim que cada entidade imobiliária carregasse seu CSV para um portal seguro, os dados fossem automaticamente ingeridos em um pipeline consolidado. Para desduplicação, eles usaram uma regra de correspondência de várias chaves, combinando 'Data da Transação', 'Valor', 'Moeda' e um token exclusivo de 'Número da Fatura' gerado por nosso algoritmo baseado em expertise, que padroniza campos de referência complexos. Este sistema baseado em regras forneceu a precisão de que precisavam. Além disso, os relatórios de resolução do TabliSync forneceram uma trilha de auditoria detalhada, mostrando exatamente quais transações foram mescladas e por quê. Isso forneceu a garantia necessária aos seus auditores externos em relação aos seus controles internos, construindo diretamente confiança.
Resultado: O impacto foi profundo. Todo o processo de reconciliação e desduplicação foi reduzido de 8 dias para apenas 2 dias. Os contadores agora estavam realizando análises em tempo real e previsões financeiras, não lutando contra planilhas. Esta redução de seis dias no fechamento mensal permitiu um relatório financeiro mais rápido e uma tomada de decisão mais ágil. Além disso, este processo aprimorado forneceu um ambiente de controle interno verificável e robusto, eliminando completamente o problema de transferência bancária intercompany duplicada de US$ 2,5 milhões. Este estudo de caso mostra que alta precisão de dados financeiros não é apenas um "nice-to-have" regulatório, mas um diferencial chave na condução da agilidade financeira e na redução do risco operacional.
Estudo de Caso 3: Redução pela Metade dos Erros no Processo de Folha de Pagamento com Limpeza de Dados por IA em um Sistema de Alto Volume
Experiência: Uma grande empresa de serviços de saúde com mais de 15.000 funcionários por hora em mais de 60 clínicas enfrentou dificuldades com um sistema de folha de pagamento de alto volume. Eles coletavam as horas trabalhadas por meio de um sistema de ponto baseado em CSV mais antigo e outros dados de RH de um sistema mais novo baseado em nuvem. A cada ciclo de pagamento, esses dois fluxos de dados eram mesclados manualmente no Excel, um processo que invariavelmente criava milhares de entradas duplicadas. O esforço manual para Remover Duplicatas do Excel e outros tipos de dados exigia uma equipe de cinco analistas de RH trabalhando em tempo integral por três dias. Apesar desse esforço, a taxa de erro na folha de pagamento final estava consistentemente acima de 4%, levando a funcionários pagos a mais e a menos. Uma única entrada duplicada para um funcionário com vários registros de ponto no mesmo dia pode passar despercebida, levando a um pagamento excessivo significativo. A correção desses erros exigiu a emissão de ajustes de cheque caros e levou a uma frustração significativa dos funcionários, prejudicando o moral e potencialmente levando a problemas de conformidade com as leis trabalhistas.
Solução: A empresa utilizou o TabliSync para automatizar fluxos de trabalho de planilhas e alcançar limpeza de dados com IA confiável para sua folha de pagamento. Estabelecemos integrações diretas e em tempo real com seu sistema de ponto e sua plataforma de RH em nuvem. Configuramos um fluxo de trabalho avançado de desduplicação em várias etapas. Na primeira etapa, realizou uma correspondência exata simples em 'ID do Funcionário' e 'Data de Trabalho'. Na segunda etapa, crucial, usou limpeza de dados com IA com uma regra sofisticada de correspondência aproximada para os campos 'Hora de Entrada' e 'Hora de Saída'. Por exemplo, se dois registros mostrassem registros de ponto para o mesmo funcionário em um intervalo de 3 minutos um do outro (uma situação comum quando um relógio de ponto é tocado duas vezes), eles eram automaticamente mesclados seguindo regras de negócios pré-definidas (por exemplo, usando a hora de entrada mais cedo e a hora de saída mais tarde). Esse nível de precisão só é possível com sistemas inteligentes. Além disso, implementamos um tratamento de erros detalhado que automaticamente colocava em quarentena quaisquer dados verdadeiramente irreconciliáveis (por exemplo, um funcionário com várias entradas de dia inteiro em dois locais diferentes) para revisão humana imediata.
Resultado: Esta transformação foi revolucionária. O processo manual de três dias foi reduzido a um pipeline totalmente automatizado que executou e validou todo o conjunto de dados em 45 minutos. Mais importante ainda, a taxa de erros na folha de pagamento foi reduzida de mais de 4% para menos de 0,5% no primeiro ciclo. Esta redução direta nos erros de pagamento e a eliminação de ajustes manuais economizaram à empresa mais de US$ 18.000 em custos operacionais e pagamentos em excesso a cada período de pagamento. O moral dos funcionários melhorou, pois os pagamentos tornaram-se consistentes e precisos, e o risco de problemas de conformidade foi virtualmente eliminado. Este estudo de caso demonstra claramente que dados de alto volume exigem soluções de limpeza de dados com IA de alta precisão para alcançar eficiência e conformidade vital.
Perguntas Frequentes sobre Como Remover Duplicatas no Excel
P1: Tentei a ferramenta integrada do Excel, mas ela não detectou duplicatas. O que aconteceu?
Isso é extremamente comum. Você está quase certamente lidando com dados que parecem idênticos, mas não são. A principal causa são os caracteres invisíveis, como um espaço no final. A função `Remover Duplicatas` do Excel é um sistema de correspondência exata. Ela trata uma célula contendo 'A ' e outra célula com 'A' como dois valores únicos. Para corrigir isso manualmente, você precisaria executar as funções `=ARRUMAR()` e `=LIMPAR()` em todas as colunas afetadas, em seguida, copiar os resultados e `Colar como Valores` para padronizar verdadeiramente seus dados antes de poder usar a ferramenta integrada de forma confiável. A limpeza de dados com IA automatizada no **TabliSync** possui essa lógica de limpeza integrada; ela padroniza todos os dados de texto e pode usar lógica fuzzy para capturar registros semanticamente idênticos que não são 100% exatos em caracteres, contornando todo esse problema.
P2: Posso combinar várias colunas para encontrar duplicatas verdadeiras no TabliSync?
Sim, e esta é uma grande vantagem. O editor de regras do TabliSync permite definir a chave composta para exclusividade. Isso é essencial para a lógica de negócios. Por exemplo, se você estiver analisando o inventário, um registro exclusivo não é apenas um 'ID do Produto'; é a combinação de 'ID do Produto', 'Localização do Armazém' e 'Condição'. Você pode selecionar essas três colunas no TabliSync para criar seu identificador exclusivo, e o mecanismo de desduplicação removerá apenas as linhas que tiverem valores idênticos em todos os três campos. Essa validação de várias chaves e várias etapas garante que você não esteja apenas excluindo dados, mas realizando limpeza inteligente de dados com IA para suportar o processamento industrial de dados. Esse grau de especificidade é fundamental para o sucesso em aplicações de alta complexidade.
Q3: O TabliSync exclui os dados originais? É seguro usar?
Esta é uma pergunta crucial para a Confiança. O TabliSync **não** exclui seus dados originais. Ele funciona criando uma cópia do seu conjunto de dados e, em seguida, aplicando as regras de duplicação a essa cópia dentro de um pipeline dedicado. Você define a lógica e obtém um conjunto de dados limpo para download como saída. Seu arquivo Excel de origem original permanece completamente intocado. Sempre recomendamos isso como uma melhor prática em gerenciamento de dados. Além disso, para uma trilha de auditoria robusta, o TabliSync gera um relatório de resolução detalhado que mostra exatamente quais linhas duplicadas foram identificadas, qual regra foi aplicada e como os valores finais foram mesclados ou selecionados, o que é essencial para conformidade em áreas que exigem alta precisão de dados financeiros.
Q4: Meu conjunto de dados do Excel tem mais de 1 milhão de linhas. O TabliSync pode lidar com isso?
Absolutamente. O desempenho em escala é uma proposta de valor central do TabliSync, especialmente para o processamento industrial de dados. Funções tradicionais do Excel geralmente se tornam incrivelmente lentas ou até travam ao lidar com dados desse tamanho. O processo de desduplicação com uma fórmula de contagem avançada levaria horas. O mecanismo de desduplicação do TabliSync foi projetado desde o início para big data. Processamos e Removemos Duplicatas do Excel de milhões de linhas em minutos, não em horas. Isso é feito aproveitando recursos de computação distribuída baseados em nuvem para lidar com os cálculos complexos em paralelo. Processamos regularmente conjuntos de dados de 10 a 20 milhões de linhas para clientes, garantindo velocidade e confiabilidade que as ferramentas manuais não conseguem igualar.
Q5: Posso agendar a minha tarefa de desduplicação para ser executada automaticamente?
Sim, e esta é a melhor forma de automatizar fluxos de trabalho de planilhas. Pode configurar cada pipeline do TabliSync com um agendamento flexível. Pode defini-lo para ser executado a cada hora, diariamente, semanalmente ou em dias e horas específicas à sua escolha. Sempre que o pipeline é executado, ele irá buscar os dados mais recentes da sua origem, aplicar automaticamente a lógica de limpeza de dados com IA para Remover Duplicados Excel e gerar um novo conjunto de dados de saída limpo. Isto garante que a sua análise ou aplicação a jusante está sempre a trabalhar com os dados mais atuais e sem erros, removendo todo o esforço manual do seu ciclo de vida de preparação de dados. É uma parte fundamental das operações de dados modernas.
Q6: A IA do TabliSync consegue identificar duplicados que estão escritos de forma diferente?
Sim. Esta é a diferença entre um sistema de correspondência exata e a limpeza de dados com IA. O TabliSync possui um recurso avançado de **Correspondência Difusa com IA**. Utiliza processamento de linguagem natural (PLN) para comparar registos semanticamente. Por exemplo, pode assinalar com confiança 'Inc.' versus 'Incorporated', ou 'Street' versus 'St.', e até mesmo apanhar variações comuns de grafia de um nome (como 'Jon' versus 'John'). Pode controlar o limiar de similaridade semântica. Não está apenas a corresponder caracteres; está a corresponder significado. Esta capacidade muda o jogo para a consolidação de dados de clientes (CRM) ou ao fundir listas de fornecedores de múltiplos sistemas legados, levando diretamente a melhorias na precisão dos dados financeiros. Esta correspondência inteligente é um recurso central que deve estar a usar.
Q7: Quando uma duplicata é encontrada, qual registo o TabliSync mantém?
Você tem controle total sobre isso. O TabliSync não toma decisões arbitrárias. Em nosso construtor de regras de desduplicação, você define explicitamente a **Lógica de Mesclagem** ou **Regra de Resolução**. Você pode criar regras sofisticadas de várias etapas. Por exemplo, para um banco de dados de produtos, você pode criar uma regra: "Manter o registro com o preço mais alto", ou para um livro razão, "Manter o registro que foi criado por último de acordo com seu timestamp de transação". Este sistema baseado em regras garante que o processo de desduplicação seja previsível e auditável, o que é essencial para a **precisão de dados financeiros**. Isso é muito superior à exclusão manual no Excel, onde você toma uma decisão caso a caso que é propensa a erros e não oferece trilha de auditoria.
Q8: Tenho uma situação única em que alguns dados devem ser tratados especificamente. O TabliSync pode ajudar?
Sim. O TabliSync é uma plataforma poderosa e flexível. Entendemos que nem todos os casos de desduplicação são simples. Você pode criar configurações de regras altamente avançadas que vão além de um único componente. Por exemplo, você pode usar um componente de 'Filtro' para dividir seus dados em dois caminhos: um para desduplicação padrão e outro para uma regra especializada e de alto contato. Você também pode encadear várias etapas de desduplicação para obter uma limpeza de dados extremamente precisa. Para **processamento de dados industriais** altamente complexos, podemos até criar lógica de desduplicação personalizada, adaptada às suas necessidades de negócios exatas, por meio de nossos serviços profissionais. Essa flexibilidade garante que possamos resolver quase qualquer problema que você encontre com a limpeza de dados em larga escala.
Q9: Como sei que a desduplicação foi bem-sucedida?
Fornecemos várias camadas de verificação. Imediatamente após a conclusão de uma sincronização, você recebe um relatório de resumo de desduplicação. Este relatório mostra exatamente quantas linhas foram inseridas, quantos duplicados totais foram encontrados e a contagem final de linhas exclusivas. Crucialmente, também geramos um **Relatório de Resolução**. Este relatório é um log transacional para cada grupo de duplicatas. Ele mostra as linhas de entrada individuais, qual foi selecionada como vencedora e por quê (por exemplo, regra "Mantida com base na regra 'Data de Modificação' mais recente"). Esse nível de transparência é essencial para validar a lógica e fornece uma trilha de auditoria clara que é crítica para a conformidade corporativa, especialmente em áreas com altos requisitos de **precisão de dados financeiros**. Você tem visibilidade e controle completos.
Q10: Meus dados estão seguros na sua plataforma? Tenho PII (Informações de Identificação Pessoal).
A segurança dos dados é nossa principal prioridade. Construímos confiança implementando medidas de segurança robustas. O TabliSync é construído com uma arquitetura focada em segurança. Usamos criptografia padrão da indústria para todos os dados em repouso e em trânsito (SSL/TLS 1.2 e AES-256). Para PII, somos compatíveis com SOC 2 Tipo II, que é um padrão chave da indústria para proteção de dados. Fornecemos controle de acesso granular, permitindo que você gerencie quais usuários em sua organização têm acesso a pipelines e dados específicos. Além disso, você pode configurar seus pipelines para mascarar ou até mesmo redigir permanentemente campos sensíveis (como números completos de cartão de crédito ou números de seguridade social) na saída de desduplicação, fornecendo uma camada adicional de segurança e ajudando você a manter a conformidade com regulamentos como GDPR ou CCPA. Você pode confiar no TabliSync com seus dados mais sensíveis.
Pare de Lutar com Planilhas, Comece a Vencer com Dados Limpos
Tentar manualmente **Remover Duplicatas de Dados do Excel** é um desperdício enorme de seus recursos mais valiosos. É uma batalha lenta e propensa a erros contra espaços invisíveis, formatos conflitantes e uma simples falta de compreensão semântica que está embutida em ferramentas mais antigas. Confiar em funções básicas como `Remover Duplicatas` não é mais viável para dados de alto volume e alta integridade. É uma estratégia obsoleta que corrói a lucratividade e aumenta o risco de conformidade.
Você precisa transformar seus processos de dados agora. Mover-se para a **limpeza de dados com IA** com o **TabliSync** não é apenas um ganho de eficiência; é uma mudança fundamental na forma como sua organização lida com informações. Você está passando de um estado de atrito manual e alto risco para um de fluxo automatizado e precisão de dados financeiros verificada. Recupere as mais de 300 horas que sua equipe está desperdiçando atualmente, feche seu ciclo financeiro de fim de mês 6 dias mais rápido e reduza seus erros de folha de pagamento pela metade. Os resultados são claros e imediatos.
Cada minuto que você atrasa é um minuto que sua concorrência opera com dados mais limpos, rápidos e confiáveis. A dor do gerenciamento manual de dados não desaparecerá por conta própria; ela só crescerá com o tamanho e a complexidade do seu negócio. Não deixe que seus valiosos analistas continuem sendo faxineiros de dados. Capacite-os com soluções inteligentes e escaláveis. Pare de lutar uma batalha perdida e comece a vencer com dados limpos e verificados que impulsionam seu negócio. Estamos prontos para ajudá-lo nesta jornada. Esta transformação é simples e os resultados são garantidos. A escolha é sua: fique preso com ferramentas manuais ou abrace o futuro dos dados automatizados e inteligentes.
Experimente a transformação por si mesmo hoje. Este é o momento de agir. **[Clique aqui para iniciar seu teste gratuito de 3 dias do TabliSync.]** Nossa plataforma não requer configuração complexa ou treinamento extenso. Mostraremos como conectar seu primeiro arquivo Excel e obter desduplicação precisa, impulsionada por IA, em menos de 30 minutos. A economia de tempo que você recuperará em sua primeira semana sozinha pagará mais do que o ano inteiro. Assuma o controle de seus dados e libere o verdadeiro potencial de sua organização.
O que é Como Remover Duplicatas de Dados do Excel com IA Rapidamente?
Respostas rápidas sobre Como Remover Duplicatas de Dados do Excel com IA Rapidamente e como o TabliSync ajuda equipes a trabalhar mais rápido no Excel.
O que é Como Remover Duplicatas de Dados do Excel com IA Rapidamente?
Como Remover Duplicatas de Dados do Excel com IA Rapidamente cobre fluxos práticos de Excel, armadilhas comuns e padrões de automação. Este guia TabliSync explica o conceito, mostra exemplos e liga tutoriais relacionados.
Como o TabliSync pode ajudar com Como Remover Duplicatas de Dados do Excel com IA Rapidamente?
O TabliSync extrai tabelas de capturas ou PDFs, limpa dados bagunçados e automatiza tarefas repetitivas de Excel ligadas a Como Remover Duplicatas de Dados do Excel com IA Rapidamente.
Por onde começo com Como Remover Duplicatas de Dados do Excel com IA Rapidamente?
Comece pela visão geral nesta página e abra os artigos abaixo para guias passo a passo e fluxos com IA.
Todos os Artigos de Remover Duplicatas Excel(2)

Dominando a Bagunça: Como Remover Duplicados no Excel Sem Perda de Dados
Ganhos de Eficiência: Reduza o tempo de limpeza manual de dados em mais de 90% utilizando fluxos de trabalho automatizados. Integridade dos Dados: Alcance uma taxa de erro de entrada manual de 0% ao migrar de 'Localizar e Substituir' para desduplicação baseada em esquema. Mitigação de Riscos: Evite 100% de exclusões acidentais utilizando ambientes não destrutivos do Power Query. Preparação para o Futuro: Mude da limpeza reativa para a Higiene de Dados proativa através de automação integrada por IA.

Como Desproteger uma Planilha do Excel Sem Saber a Senha
• Contorne instantaneamente a proteção de planilhas do Excel com 0% de perda de dados. • Reduza o tempo de recuperação manual em 95% usando manipulação de esquema XML. • Elimine erros de 'célula bloqueada' e restaure a higiene total dos dados instantaneamente. • Utilize OCR com IA para transformar exibições protegidas estáticas em dados estruturados dinâmicos.
Chega de entrada manual – Extraia tabelas em segundos
Converta qualquer imagem ou tabela PDF para Excel instantaneamente com 99,9% de precisão. O OCR com IA do TabliSync processa formulários manuscritos, recibos e tabelas complexas e sincroniza diretamente com Google Sheets, Notion ou Airtable
Experimente o TabliSync gratuitamente agora