Article Summary
Este guia abrangente explora a evolução da análise de dados, com foco na tarefa crítica de 'Dividir Texto em Colunas' em tabelas complexas e não estruturadas. Investigamos as limitações de ferramentas legadas como o assistente "Texto para Colunas" do Excel, que muitas vezes falha ao lidar com dados aninhados, delimitadores inconsistentes ou entradas de células com várias linhas. Ao integrar a extração de dados por IA e a análise automatizada de tabelas, os usuários agora podem lidar com a limpeza de dados financeiros e o processamento complexo de OCR com precisão sem precedentes. A página pilar fornece um passo a passo tático de conversão de dados estruturais, comparando métodos manuais baseados em regex com soluções modernas impulsionadas por IA como o TabliSync. Cobrimos casos de uso empresariais específicos, incluindo reconciliação do Razão Geral, processamento automatizado de faturas e o manuseio de valores nulos por meio de estratégias avançadas de imputação. O guia serve como um manual técnico para gerentes de operações, analistas de dados e profissionais de finanças que precisam escalar seus fluxos de trabalho de dados sem sacrificar a precisão ou a segurança. Ele enfatiza a importância da conformidade com SOC2 e o papel dos Webhooks na construção de pipelines de dados ponta a ponta, contínuos e automatizados para inteligência de negócios moderna.
A Evolução da Análise de Dados: Além do Assistente Básico
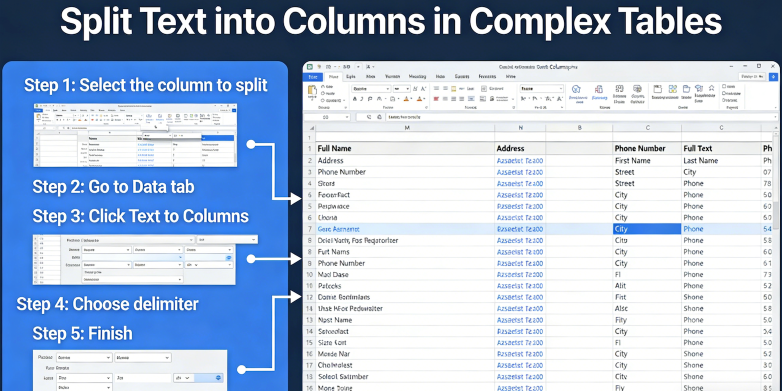
Para entender o estado atual de Dividir Texto em Colunas, devemos primeiro olhar para as bases tradicionais. De acordo com a documentação de Suporte da Microsoft sobre o 'Assistente para Converter Texto em Colunas':
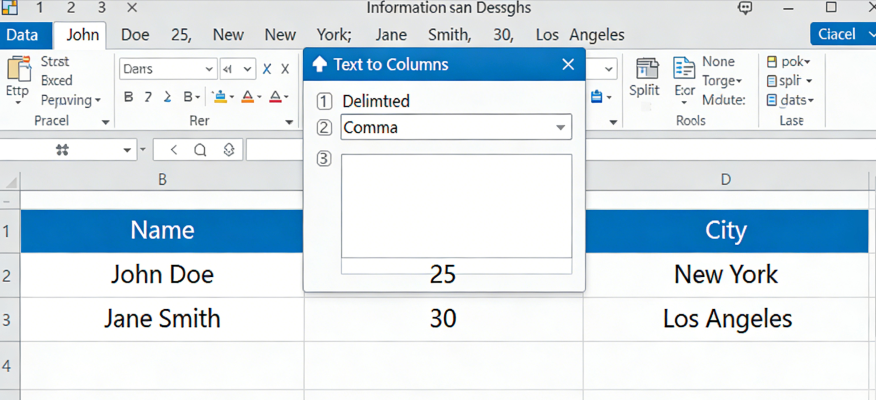
"Você pode pegar o texto em uma ou mais células e espalhá-lo por várias células usando o Assistente para Converter Texto em Colunas. Isso é geralmente usado para dados delimitados por um caractere específico, como uma vírgula, ou dados que têm uma largura fixa. Por exemplo, se você tem uma lista de nomes completos em uma coluna, pode querer dividir essa coluna em colunas separadas de Primeiro Nome e Sobrenome. Selecione a célula ou coluna que contém o texto que você deseja dividir. Selecione Dados > Texto para Colunas. No Assistente para Converter Texto em Colunas, selecione Delimitado > Avançar. Selecione os Delimitadores para seus dados. Por exemplo, Vírgula e Espaço. Você pode ver uma prévia de seus dados na janela de visualização de dados. Selecione Avançar. Selecione o formato de dados da coluna ou use o que o Excel escolheu para você. Selecione Concluir." (Fonte: Microsoft Support, 2024).
Embora essa abordagem fundamental seja um pilar para tarefas básicas de planilha, a limpeza de dados financeiros moderna exige significativamente mais poder. O método da Microsoft assume um nível de limpeza de dados que raramente existe no processamento complexo de OCR do mundo real. Em um ambiente profissional, você não está apenas dividindo "João Silva" em duas células. Você está lidando com a conversão de dados estruturais de PDFs legados onde o "delimitador" pode ser um número aleatório de espaços, uma quebra de linha ou, pior, um valor ausente que faz com que toda a linha se desloque para a esquerda, arruinando o alinhamento do seu Razão Geral.
Minha perspectiva sobre isso é que superamos o "Assistente". Para extração de dados de IA de alto risco, confiar na seleção manual de delimitadores é uma receita para o desastre. Quando você tem 50.000 linhas de dados, uma única linha com uma vírgula extra cria um erro em cascata que pode levar horas para ser auditado. Precisamos avançar para a análise automatizada de tabelas que entenda o contexto dos dados, em vez de apenas procurar por um ponto e vírgula. A mudança da divisão baseada em regras para a extração ciente do contexto é o que define a próxima geração de ferramentas de produtividade.
O Assassino Silencioso: Lidando com Valores Ausentes e Nulos
O ponto de maior dificuldade em qualquer fluxo de trabalho de Divisão de Texto em Colunas é o mau tratamento de valores em falta ou nulos. Em muitos sistemas legados, não existe uma forma sistemática de imputar ou sinalizar essas lacunas. Imagine que está a processar uma exportação massiva de um sistema ERP. A Coluna A é a data, a Coluna B é o fornecedor e a Coluna C é o montante. Se o nome do fornecedor estiver em falta em algumas linhas, um script padrão de análise automatizada de tabelas pode inserir o "montante" na coluna "fornecedor". Isto não cria apenas dados desorganizados; cria erros invisíveis que levam a falhas de Conciliação.
Sem uma forma de sinalizar nulos, a sua conversão de dados estruturais torna-se um risco. A maioria dos utilizadores tenta corrigir isto percorrendo manualmente milhares de linhas, à procura de dados "deslocados". Isto não é apenas uma perda de tempo; é uma falha fundamental do pipeline de dados. Vemos isto frequentemente na limpeza de dados financeiros, onde a falta de um código de Razão Geral resulta na categorização incorreta de despesas, podendo levar a falhas de auditoria ou discrepâncias fiscais. A falta de um motor sistemático de "imputação" ou "sinalização" significa que o consumidor de dados está sempre a trabalhar com um conjunto de dados falho.
A nível empresarial, não pode dar-se ao luxo de ter um ser humano como o principal "verificador de nulos". Precisa de um sistema que detete a ausência de um valor com base no tipo de dados esperado. Se a Coluna C espera um formato de moeda e encontra uma string, o sistema deve sinalizar imediatamente essa linha. O processamento tradicional de OCR muitas vezes falha estas nuances porque se concentra no reconhecimento de caracteres em vez da compreensão semântica. É aqui que a extração de dados por IA preenche a lacuna, permitindo a inserção automática de marcadores de posição ou o acionamento de um Webhook para revisão humana apenas quando uma anomalia é detetada.
Excel Tradicional vs. Extração de Dados por IA: A Lacuna de Eficiência
Quando falamos sobre Dividir Texto em Colunas, devemos abordar a análise de custo-benefício dos métodos tradicionais versus a extração de dados por IA. Em um estudo de caso recente envolvendo uma empresa de contabilidade de médio porte, eles gastavam aproximadamente 15 horas por semana limpando manualmente extratos bancários e exportações do Razão Geral. O uso de assistentes tradicionais do Excel exigia que um analista ajustasse manualmente a "largura fixa" para cada formato de banco diferente. Com uma taxa horária média de US$ 45, essa empresa gastava mais de US$ 35.000 anualmente apenas na limpeza básica de dados financeiros.
Ao mudar para a análise automatizada de tabelas via TabliSync, a empresa reduziu essa carga de trabalho de 15 horas para apenas 12 minutos de verificação. O ganho de Eficiência foi de quase 98%. Diferente do assistente do Excel, a extração de dados por IA usa aprendizado de máquina para identificar padrões. Não importa se o banco muda a fonte ou adiciona um novo logotipo no topo do PDF. O mecanismo de conversão de dados estruturais identifica os cabeçalhos das tabelas e mapeia inteligentemente o conteúdo para as colunas corretas, independentemente das mudanças no layout físico. Essa é a diferença entre uma "ferramenta" e uma "solução".
Além disso, a economia de custos se estende além do trabalho. Considere o custo de um erro de entrada de dados. Em um processo de Conciliação, um único ponto decimal mal colocado devido a uma falha na divisão de texto em colunas pode resultar em uma discrepância de milhares de dólares. O processamento complexo de OCR combinado com a validação por IA reduz a taxa de erro de uma média do setor de 4% (entrada manual) para menos de 0,1%. Quando você considera o risco reduzido de reformulações financeiras, o ROI para a análise automatizada de tabelas se torna exponencial. As empresas não estão mais apenas economizando tempo; estão comprando precisão e tranquilidade.
Recurso Assistente Tradicional do Excel Extração por IA TabliSync
Tempo de Configuração
Manual para cada tipo de arquivo
Aprendizado único sem modelos
Tabelas Complexas
Falha em células aninhadas/multilinha
Lida facilmente com estruturas aninhadas
Tratamento de Nulos
Causa deslocamento de coluna
Marca automaticamente e mantém a estrutura
Escalabilidade
Limitada pela capacidade humana
Processa milhares de páginas via API
Passo a Passo: Dominando a Divisão Complexa de Texto em Colunas
Passo 1: Analisando a Estrutura e os Delimitadores da Fonte
Antes mesmo de pensar em Dividir Texto em Colunas, você deve realizar uma auditoria profunda dos seus dados de origem. Isso é especialmente verdade para processamento complexo de OCR, onde o "texto" é extraído de um arquivo plano ou de um PDF. Você precisa identificar se seus dados são verdadeiramente delimitados (por vírgulas, tabulações ou barras verticais) ou se dependem de espaçamento de largura fixa. Muitas tarefas modernas de limpeza de dados financeiros envolvem delimitadores "ocultos", como espaços inquebráveis ou caracteres ASCII específicos que não são visíveis em um editor de texto padrão.
Neste passo, você deve usar um editor de texto de alto nível (como VS Code ou Sublime) para visualizar caracteres ocultos. Procure por inconsistências. A terceira linha tem uma vírgula extra dentro de uma string entre aspas? Ferramentas padrão de conversão de dados estruturais falharão com isso. Você deve decidir se usará uma regex "gulosa" ou um modelo de extração de dados por IA mais sutil. Se você estiver lidando com um Razão Geral, verifique se os números das contas e as descrições estão mesclados em um único campo. Este é o estágio onde você define a "lógica" da sua divisão. Anote quaisquer células de várias linhas, pois estas são a principal razão pela qual assistentes básicos falham.
Dica Profissional: Sempre crie um backup dos seus dados brutos antes de executar qualquer script de análise automatizada de tabelas. Se a sua lógica de regex for falha, você poderá sobrescrever dados críticos. Durante esta fase de análise, documente os "casos extremos" — as linhas que não se encaixam no padrão. Estas são as linhas que exigirão extração de dados por IA para interpretar contextualmente em vez de mecanicamente. Compreender a "forma" dos seus dados aqui economiza horas de solução de problemas no Passo 3.
Passo 2: Configurando o Motor de Extração por IA
Uma vez que você identificou os padrões (ou a falta deles), você passa para a configuração do seu motor de análise automatizada de tabelas. No TabliSync, isso não envolve escrever código; envolve definir as "entidades" que você deseja extrair. Em vez de dizer ao sistema "divida em cada vírgula", você diz ao sistema "encontre o Número da Fatura, a Data e o Total do Item da Linha". Essa abordagem de extração de dados por IA é muito mais robusta porque usa consciência espacial e lógica semântica para realizar a tarefa de Dividir Texto em Colunas.
Durante a configuração, você pode definir regras para a conversão de dados estruturais. Por exemplo, se um valor for identificado como "Data", você pode instruir o sistema a normalizá-lo para o formato ISO 8601 (AAAA-MM-DD) durante a divisão. É aqui que a limpeza de dados financeiros acontece em tempo real. Você não está apenas movendo texto; você está transformando-o. Você também deve configurar o tratamento de valores nulos aqui. Diga ao sistema: "Se a coluna 'Quantidade' estiver vazia, marque esta linha para revisão manual e não prossiga com a exportação de Reconciliação."
Esta etapa também é onde você integra suas configurações de Webhook. Se você estiver processando milhares de documentos, desejará que o sistema notifique seu ERP (como NetSuite ou SAP) assim que o processo de Dividir Texto em Colunas for concluído. Isso cria um pipeline de análise automatizada de tabelas contínuo. Certifique-se de testar sua configuração contra um pequeno subconjunto de 10 a 20 documentos variados para garantir que a IA identificou corretamente os cabeçalhos e os limites do processamento complexo de OCR. Verifique a cobertura de campo de 100% antes de passar para o processamento em massa.
Etapa 3: Execução e Validação de Dados Pós-Divisão
A etapa final é a execução real da tarefa de Dividir Texto em Colunas e a validação subsequente. É aqui que "o bicho pega". À medida que o mecanismo de extração de dados por IA processa o arquivo, ele preencherá suas colunas de destino. No entanto, o trabalho ainda não acabou. Você deve implementar uma camada de validação. Isso envolve verificar os dados extraídos em relação a regras de negócios conhecidas. Por exemplo, na limpeza de dados financeiros, a soma dos itens de linha "divididos" deve ser igual ao "Valor Total" extraído do cabeçalho. Se não corresponderem, a análise automatizada de tabelas falhou em uma verificação de integridade.
A validação é onde a conversão de dados estruturados se torna de nível empresarial. Você deve procurar por pontuações de "baixa confiança". Ferramentas modernas de processamento de OCR fornecerão uma porcentagem de confiança para cada célula. Se o sistema tiver apenas 60% de certeza sobre uma divisão, ela deverá ser mantida em uma fila para verificação humana. Este modelo "humano no circuito" garante que você mantenha 100% de precisão, automatizando ainda 95% do volume. Após a validação, seus dados estarão prontos para a Conciliação final ou para uso em painéis de business intelligence.
Preste muita atenção em como o sistema lidou com aqueles valores nulos que discutimos anteriormente. Eles foram sinalizados corretamente? As colunas permaneceram alinhadas? Se você encontrar um erro recorrente, volte à Etapa 2 e refine as instruções da IA. O objetivo é criar um loop de autoaperfeiçoamento onde cada trabalho de Dividir Texto em Colunas se torne mais preciso que o anterior. Finalmente, exporte seus dados no formato necessário (CSV, JSON ou push direto via API) e feche o ciclo arquivando o documento original para conformidade com SOC2 e trilhas de auditoria.
O Papel da Conversão de Dados Estruturados em Auditorias Financeiras
No mundo da limpeza de dados financeiros, a conversão de dados estruturados é mais do que uma conveniência; é um requisito para auditorias modernas. Auditores hoje estão se afastando de testes baseados em amostras para testes de população completa. Isso significa que você precisa ser capaz de Dividir Texto em Colunas para cada transação em seu Razão Geral, não apenas algumas. Se seus dados estiverem presos em exportações de PDF desorganizadas e não formatadas, você estará olhando para uma conta de auditoria massiva ou uma opinião qualificada.
Usar extração de dados por IA para normalizar esses registros garante que cada transação seja pesquisável e categorizável. Por exemplo, ao realizar uma Conciliação entre extratos bancários e registros internos, a capacidade de dividir automaticamente strings de transações em "Data", "ID da Transação" e "Comerciante" permite a correspondência automatizada. Essa capacidade de análise de tabelas automatizada pode reduzir o tempo gasto em auditorias de fim de ano em semanas. Além disso, os logs de processamento complexo de OCR fornecem uma trilha de auditoria clara de como os dados foram transformados, o que é uma grande vitória para os controles internos.
A conformidade com SOC2 também dita que os dados devem ser manuseados com segurança e precisão. Processos manuais de Divisão de Texto em Colunas são propensos a adulteração humana ou exclusão acidental. Um sistema automatizado de conversão de dados estruturados como o TabliSync garante que a lógica de transformação seja aplicada de forma consistente e que nenhuma alteração não autorizada seja feita durante o processo de limpeza. Esse nível de Confiança é essencial para CFOs e Controladores que precisam assinar demonstrações financeiras com absoluta confiança na integridade dos dados subjacentes.
Estudo de Caso 1: Empresa de Logística Automatiza a Análise de Conhecimentos de Embarque
Um provedor global de logística estava lutando com o processamento complexo de OCR de seus Conhecimentos de Embarque. Cada parceiro de transporte usava um formato de tabela diferente, e muitos documentos eram digitalizações de baixa qualidade. Seu fluxo de trabalho manual de Divisão de Texto em Colunas envolvia cinco funcionários em tempo integral que copiavam e colavam dados de PDFs no Excel, corrigindo manualmente os erros causados por colunas desalinhadas. Eles processavam 2.000 documentos por mês com uma taxa de erro de 12% nas colunas "Peso" e "Destino".
Eles implementaram o TabliSync para extração de dados por IA. O sistema foi treinado em uma variedade de layouts de documentos e aprendeu a identificar a tabela principal, independentemente do ruído ao redor. O mecanismo de análise de tabelas automatizada foi capaz de dividir as descrições de itens de várias linhas em colunas separadas de "SKU", "Quantidade" e "Peso" com 99% de precisão. Essa conversão de dados estruturados não apenas economizou tempo; permitiu que eles integrassem os dados diretamente em seu sistema de rastreamento via Webhooks, fornecendo visibilidade em tempo real aos seus clientes.
O resultado foi uma redução total de custos de US$ 120.000 no primeiro ano. Mais importante ainda, o tempo de processamento de um envio diminuiu de 4 horas para 5 minutos. Isso permitiu que a empresa assumisse mais clientes sem aumentar o número de funcionários. Este caso destaca como Dividir Texto em Colunas, quando impulsionado por IA, se torna uma vantagem estratégica em vez de uma tarefa administrativa. Os ganhos de Eficiência permitiram que eles escalassem de uma forma que o processamento manual nunca poderia.
Estudo de Caso 2: Limpeza Financeira de um Fundo de Investimento Imobiliário (REIT)
Um grande REIT enfrentava um enorme desafio com a limpeza de dados financeiros. Eles recebiam milhares de diferentes listas de aluguel todos os meses em vários formatos. Alguns eram arquivos Excel, alguns eram PDFs e alguns eram até imagens. A conversão de dados estruturais necessária para consolidar esses dados em um único Razão Geral era um pesadelo. Seu principal problema eram os dados "aninhados", onde vários valores estavam empacotados em uma única célula, exigindo uma complexa operação de Dividir Texto em Colunas que as ferramentas padrão não conseguiam lidar.
Ao implementar a extração de dados por IA, o REIT conseguiu automatizar a extração de nomes de inquilinos, datas de contratos de locação e históricos de pagamento. O motor de análise automatizada de tabelas reconheceu quando uma única célula continha tanto o aluguel base quanto as taxas de manutenção de áreas comuns (CAM), dividindo-as em colunas distintas para uma contabilidade precisa. Esse nível de processamento complexo de OCR era anteriormente impossível sem intervenção humana significativa.
O REIT relatou uma redução de 70% no tempo necessário para fechar seus livros mensais. Ao automatizar o processo de Reconciliação, eles também descobriram mais de US$ 50.000 em aluguéis sub-relatados que haviam sido perdidos por verificações manuais em meses anteriores. Essa Eficiência e a consequente economia de custos provaram que a extração de dados por IA é uma ferramenta essencial para qualquer organização que gerencia conjuntos de dados financeiros complexos e de alto volume. A conversão de dados estruturais foi a chave para desbloquear o verdadeiro valor de seus dados.
Estudo de Caso 3: Escritório de Advocacia e Análise de Documentos de Descoberta
Durante a fase de descoberta de um grande caso de litígio, um escritório de advocacia teve que processar mais de 100.000 páginas de registros bancários e memorandos internos. Eles precisavam Dividir Texto em Colunas para cada transação financeira mencionada para procurar padrões de fraude. A entrada manual estava fora de questão devido a preocupações com tempo e conformidade SOC2. Eles precisavam de uma ferramenta de conversão de dados estruturais que pudesse lidar com processamento OCR complexo, mantendo uma cadeia de custódia rigorosa.
O TabliSync forneceu as capacidades necessárias de extração de dados por IA. O sistema analisou os documentos, identificando tabelas de transações e dividindo-as em colunas pesquisáveis, incluindo "Beneficiário", "Valor", "Data" e "Origem da Conta". Mesmo quando os documentos estavam rotacionados ou ligeiramente borrados, o motor de análise de tabelas automatizada manteve alta precisão. O escritório usou a integração Webhook para alimentar esses dados diretamente em seu software de suporte a litígios para análises avançadas.
Essa automação permitiu que a equipe jurídica encontrasse evidências críticas em três dias — uma tarefa que teria levado vários meses para uma equipe de paralegais. A Confiança construída através da limpeza de dados financeiros precisa e de trilhas de auditoria robustas foi fundamental para o escritório ganhar o caso. Isso demonstra que a conversão de dados estruturais é uma ferramenta versátil que se estende muito além do departamento financeiro, desempenhando um papel crucial no trabalho jurídico, de conformidade e investigativo.
Técnicas Avançadas: Regex vs. IA para Conversão de Dados Estruturais
Por décadas, o padrão ouro para conversão de dados estruturados foram as Expressões Regulares (Regex). Regex é poderoso, mas é frágil. Requer que um desenvolvedor antecipe todas as variações possíveis nos dados. Se um fornecedor alterar o formato de sua fatura movendo o "Total" um centímetro para a direita, a Regex geralmente falha. Isso leva a um ciclo constante de manutenção e a scripts de análise automatizada de tabelas quebrados. Em contraste, a extração de dados por IA é resiliente. Ela não procura um caractere específico em uma coordenada específica; ela procura o "conceito" de um total. Ao realizar uma tarefa de Dividir Texto em Colunas em um Razão Geral, você pode encontrar células que contêm tanto um código de conta quanto um nome de conta (por exemplo, "1001-Caixa"). Uma Regex poderia facilmente dividir isso no hífen. Mas e se o próprio nome da conta contiver um hífen? Uma divisão padrão criaria três colunas em vez de duas. A extração de dados por IA entende o contexto e sabe que "Caixa" é o nome, mesmo que contenha caracteres incomuns. Isso reduz a necessidade de "ajuste constante de regex" e diminui a barreira técnica para a limpeza de dados financeiros. Além disso, a análise automatizada de tabelas com IA pode lidar com o "não divisível". Considere uma tabela onde as linhas não são separadas de forma organizada por linhas, mas por espaço em branco e tamanho da fonte. O processamento complexo de OCR pode identificar essas pistas visuais para determinar onde uma coluna termina e a próxima começa. Esta é a conversão de dados estruturados em seu nível mais avançado. Embora a Regex ainda tenha seu lugar para tarefas muito simples e de alta velocidade, a empresa moderna deve se apoiar na extração de dados por IA para qualquer dado que seja variável, complexo ou de alto risco. A economia de custos apenas em tempo de desenvolvimento torna a IA a vencedora clara.Preparando sua Estratégia de Dados para o Futuro com Webhooks e API
Para dominar verdadeiramente a Divisão de Texto em Colunas, você deve olhar além da planilha. O futuro do processamento automatizado de tabelas é integrado e em tempo real. Ao utilizar Webhooks, você pode criar um pipeline de dados onde, no momento em que um documento é carregado em uma pasta de armazenamento em nuvem, o mecanismo de extração de dados por IA é ativado, realiza a conversão de dados estruturados e envia os dados limpos para o seu banco de dados. Não é necessário download ou upload manual. Este é o auge da Eficiência.
Uma abordagem "API-first" para limpeza de dados financeiros permite que seu software existente "solicite" dados estruturados. Por exemplo, seu software de Reconciliação pode enviar um PDF bruto para um endpoint de API e receber um objeto JSON perfeitamente formatado em troca, com toda a lógica de Divisão de Texto em Colunas já aplicada. Isso elimina o "intermediário de planilha" e reduz o risco de corrupção de dados. Para desenvolvedores, isso significa que eles podem construir recursos complexos sobre dados limpos sem se preocupar com o processamento complexo de OCR subjacente ou a lógica de extração de tabelas.
Finalmente, considere os aspectos de Confiança e segurança. Pipelines automatizados com Webhooks reduzem o número de pessoas que têm acesso a dados brutos e sensíveis. A extração de dados por IA ocorre em um ambiente seguro, e a saída estruturada é entregue diretamente ao sistema de destino. Isso se encaixa perfeitamente com os frameworks de conformidade SOC2, pois minimiza a superfície de ataque para violações de dados. Ao preparar seu futuro de estratégia de dados com essas ferramentas, você não está apenas resolvendo o problema de Divisão de Texto em Colunas de hoje; você está construindo uma base escalável para a próxima década de transformação digital.
Perguntas Frequentes (FAQ)
P1: Como a IA lida com diferentes formatos de data durante uma divisão?
Ao realizar uma operação de Dividir Texto em Colunas usando extração de dados por IA, o sistema não apenas corta o texto; ele identifica o tipo de dado. Se uma linha tiver "MM/DD/AAAA" e outra tiver "DD-Mês-AA", o motor de análise automatizada de tabelas pode normalizar ambos em um formato consistente durante a conversão de dados estruturados. Por exemplo, em uma conciliação de Razão Geral, ele pode converter todas as datas para o formato padrão ISO automaticamente. Isso evita erros na sua limpeza de dados financeiros que normalmente ocorreriam se você usasse apenas um assistente simples de divisão de texto que não entende a lógica de datas.
Q2: Posso dividir texto que está mesclado em várias linhas em uma única célula?
Sim, esta é uma das maiores vantagens da extração de dados por IA em relação às ferramentas tradicionais. Assistentes básicos do Excel geralmente falham quando uma única linha de dados abrange várias linhas físicas em um PDF ou imagem. O processamento complexo de OCR pode reconhecer os limites visuais de uma linha de tabela e tratar o texto de várias linhas como uma única entidade antes de aplicar a lógica de Dividir Texto em Colunas. Isso é essencial para a limpeza de dados financeiros, onde as descrições de faturas são frequentemente longas e se estendem por várias linhas, garantindo que suas quantidades e preços permaneçam sempre alinhados com o item correto.
Q3: O que acontece se o delimitador estiver ausente em algumas linhas?
Em um fluxo de trabalho tradicional de Dividir Texto em Colunas, um delimitador ausente faz com que os dados se desloquem, o que arruína todo o conjunto de dados. No entanto, a análise automatizada de tabelas usando IA não depende apenas de delimitadores. Ela usa contexto espacial e semântico. Se uma vírgula estiver ausente, mas o sistema identificar um espaço claro e uma mudança no tipo de dado (por exemplo, de texto para moeda), ele ainda realizará a divisão corretamente. Isso evita o problema de "valor nulo" e garante que sua conversão de dados estruturados permaneça precisa, mesmo com arquivos de origem imperfeitos, o que é um cenário comum em processamento complexo de OCR.
Q4: É possível dividir colunas sem usar nenhum código?
Absolutamente. Ferramentas como o TabliSync são projetadas para usuários de negócios que precisam de extração de dados por IA sem a necessidade de escrever scripts Regex ou Python. Você simplesmente aponta o sistema para a tabela, e o motor de análise automatizada de tabelas faz o trabalho pesado. Isso democratiza a conversão de dados estruturados, permitindo que contadores e gerentes de operações realizem sua própria limpeza de dados financeiros. Ao remover o gargalo técnico, as organizações podem melhorar a Eficiência e permitir que suas equipes de TI se concentrem em tarefas de integração de nível superior, enquanto os usuários de negócios gerenciam a qualidade dos dados por conta própria.
Q5: Quão seguros estão meus dados financeiros durante o processo de extração?
A segurança é uma prioridade máxima, especialmente para a limpeza de dados financeiros. Plataformas profissionais de extração de dados por IA como o TabliSync são construídas com a conformidade SOC2 em mente. Isso significa que os dados são criptografados em repouso e em trânsito. Ao contrário das tarefas manuais de dividir texto em colunas que podem ocorrer em máquinas locais não seguras, a conversão automatizada de dados estruturados ocorre em um ambiente de nuvem controlado. Isso garante Confiança e ajuda as organizações a atender aos requisitos legais e regulatórios ao lidar com informações confidenciais do Razão Geral ou do cliente durante o ciclo de vida da análise automatizada de tabelas.
Q6: Isso pode lidar com tabelas em documentos manuscritos?
O processamento complexo de OCR moderno fez avanços significativos no reconhecimento de escrita manual. Embora seja mais desafiador do que texto impresso, a extração de dados por IA pode frequentemente identificar estruturas de tabelas em notas ou formulários manuscritos. O motor de análise automatizada de tabelas procura as posições relativas do texto para inferir as colunas. Embora a precisão possa ser ligeiramente menor do que com PDFs digitais, ela ainda fornece um grande impulso para a conversão de dados estruturados. Para a limpeza de dados financeiros de registros de papel legados, isso pode economizar milhares de horas de entrada manual de dados e trabalho de transcrição.
Q7: O que é um Webhook e como ele ajuda na divisão de colunas?
Um Webhook é uma forma de uma aplicação enviar dados em tempo real para outra assim que um evento acontece. No contexto de análise automatizada de tabelas, você pode configurar um Webhook para que, assim que a extração de dados por IA terminar um trabalho de Dividir Texto em Colunas, os dados estruturados resultantes sejam enviados automaticamente para o seu software de ERP ou Reconciliação. Isso remove a etapa manual de exportar um CSV e carregá-lo em outro lugar, aumentando significativamente a Eficiência de todo o seu pipeline de dados e garantindo que a sua limpeza de dados financeiros esteja sempre atualizada.
Q8: Como o sistema lida com tabelas muito grandes com milhares de linhas?
A extração de dados por IA é construída para escalabilidade. Ao contrário de um processo manual que desacelera à medida que o volume aumenta, a análise automatizada de tabelas pode processar milhares de linhas em segundos. A lógica de conversão de dados estruturais é aplicada consistentemente em todo o conjunto de dados, garantindo que a 1ª linha e a 10.000ª linha sejam tratadas com o mesmo nível de precisão. Isso é vital para a limpeza de dados financeiros em grandes empresas onde as exportações do Razão Geral podem ser enormes. Usar um sistema automatizado garante que você não perca Eficiência à medida que suas necessidades de dados crescem.
Q9: Posso personalizar os cabeçalhos após a divisão?
Sim, durante a configuração da análise automatizada de tabelas, você pode definir exatamente quais devem ser os cabeçalhos de saída. Mesmo que o documento original tenha cabeçalhos confusos ou não descritivos, o motor de extração de dados por IA pode mapeá-los para o seu formato interno padronizado. Esta é uma parte fundamental da conversão de dados estruturais, pois garante que os dados estejam prontos para uso imediato em suas ferramentas de Reconciliação ou BI. Personalizar cabeçalhos durante o processo de divisão é uma prática recomendada para a limpeza de dados financeiros, pois mantém a consistência entre diferentes fontes de dados e fornecedores.
Q10: Qual é a diferença de custo entre a divisão manual e por IA?
A economia de custos é geralmente substancial. Tarefas manuais de Dividir Texto em Colunas não são apenas lentas, mas também propensas a erros caros. Quando você considera o salário por hora de um analista financeiro qualificado, o custo da limpeza de dados financeiros manual pode ser 10 a 50 vezes maior do que o uso de uma solução de análise de tabelas automatizada. A extração de dados por IA oferece um custo fixo e previsível por documento ou por linha, o que facilita o orçamento e permite dimensionar suas operações de conversão de dados estruturais sem um aumento linear no número de funcionários, levando a um ROI muito maior.
Pare de Lutar com Seus Dados — Comece a Sincronizá-los
Os dias de luta com assistentes quebrados de Dividir Texto em Colunas e exportações desalinhadas do Razão Geral acabaram. Você já viu os dados: a limpeza manual é um dreno na sua Eficiência, um risco para a sua Confiança e um desperdício massivo de capital. Cada minuto que sua equipe gasta corrigindo manualmente erros de conversão de dados estruturais é um minuto que eles não estão gastando em análises de alto valor ou crescimento estratégico. A lacuna entre as empresas que usam extração de dados por IA e aquelas que não usam está aumentando a cada dia.
Não deixe que mais um fim de mês termine com um pesadelo de Conciliação causado por falhas de processamento complexo de OCR. O TabliSync é a arma definitiva para a limpeza de dados financeiros, projetado para lidar com tabelas confusas, aninhadas e não estruturadas que outras ferramentas não conseguem tocar. Oferecemos a precisão da análise de tabelas automatizada com a segurança da conformidade SOC2, garantindo que seu pipeline de dados seja tão robusto quanto rápido. Esta é a sua chance de recuperar seu tempo e garantir 100% de precisão em seus fluxos de trabalho de dados.
Experimente o poder do TabliSync hoje mesmo. Por tempo limitado, você pode se inscrever para um teste gratuito e ver exatamente como nossa extração de dados por IA pode transformar suas tabelas mais confusas em ativos perfeitamente estruturados em segundos. Clique no link abaixo para começar — não deixe que a entrada manual de dados atrase seu negócio por mais tempo. O futuro da conversão de dados estruturais está aqui, e está a apenas um clique de distância.
[Experimente o TabliSync Grátis Agora]
O que é Como Dividir Texto em Colunas em Tabelas Complexas?
Respostas rápidas sobre Como Dividir Texto em Colunas em Tabelas Complexas e como o TabliSync ajuda equipes a trabalhar mais rápido no Excel.
O que é Como Dividir Texto em Colunas em Tabelas Complexas?
Como Dividir Texto em Colunas em Tabelas Complexas cobre fluxos práticos de Excel, armadilhas comuns e padrões de automação. Este guia TabliSync explica o conceito, mostra exemplos e liga tutoriais relacionados.
Como o TabliSync pode ajudar com Como Dividir Texto em Colunas em Tabelas Complexas?
O TabliSync extrai tabelas de capturas ou PDFs, limpa dados bagunçados e automatiza tarefas repetitivas de Excel ligadas a Como Dividir Texto em Colunas em Tabelas Complexas.
Por onde começo com Como Dividir Texto em Colunas em Tabelas Complexas?
Comece pela visão geral nesta página e abra os artigos abaixo para guias passo a passo e fluxos com IA.

Chega de entrada manual – Extraia tabelas em segundos
Converta qualquer imagem ou tabela PDF para Excel instantaneamente com 99,9% de precisão. O OCR com IA do TabliSync processa formulários manuscritos, recibos e tabelas complexas e sincroniza diretamente com Google Sheets, Notion ou Airtable
Experimente o TabliSync gratuitamente agora