Article Summary
Esta página pilar integral sirve como el manual definitivo para investigadores, administradores universitarios y analistas de datos que luchan con la conversión manual de conjuntos de datos académicos complejos a Excel. Profundizamos en la mecánica del procesamiento de Datos Académicos Excel, yendo más allá de las funciones básicas de hoja de cálculo para explorar la extracción avanzada de tablas automatizada y el procesamiento por lotes de PDF. La guía aborda el punto crítico de la inconsistencia en el formato de los resultados estadísticos y proporciona una comparación técnica rigurosa entre la entrada manual y la automatización de datos de investigación impulsada por IA. Los lectores encontrarán un flujo de trabajo operativo detallado (paso a paso) para TabliSync, que incluye técnicas complejas de OCR financiero para procesar subvenciones históricas y libros de contabilidad generales. Con más de 4500 palabras de información a nivel de experto, el contenido cubre la conciliación de datos, los webhooks para flujos de trabajo académicos y el cumplimiento de los estándares de la industria para la integridad de los datos. Estudios de caso detallados de instituciones de investigación globales ilustran las mejoras en la eficiencia y el ahorro de costos alcanzables a través de tecnologías de extracción modernas. La página también presenta una sección robusta de preguntas frecuentes que aborda obstáculos técnicos como la extensión de tablas de varias páginas y el reconocimiento de caracteres no estándar, asegurando que los usuarios puedan transformar el caos académico en bruto en activos de Excel listos para publicar con una velocidad y precisión sin precedentes.
Cómo procesar datos académicos de Excel rápidamente: la guía definitiva para la automatización de datos de investigación
El panorama de la investigación académica está cambiando bajo nuestros pies. Ya no carecemos de datos; nos ahogamos en ellos. Sin embargo, el puente entre los datos brutos —a menudo atrapados en PDF obstinados o formatos de imagen heredados— y los archivos accionables de Datos Académicos en Excel está plagado de trabajo manual. Esta guía tiene como objetivo desmantelar las barreras para el procesamiento de datos a alta velocidad, centrándose en la extracción automatizada de tablas y la automatización de datos de investigación como los principales impulsores de la erudición moderna.
Reflexiones sobre la alfabetización de datos moderna
En el artículo 'Cómo aprender Excel' publicado por DataCamp, el autor enfatiza el papel fundamental de las hojas de cálculo en la vida profesional moderna: 'Excel sigue siendo una de las herramientas más potentes y versátiles en el arsenal del profesional de datos... Es el lenguaje universal de los datos en todas las industrias, desde las finanzas hasta la biología.' (Fuente: DataCamp, 2024). Esto resalta una verdad fundamental: mientras surgen nuevos lenguajes de codificación, el formato de Datos Académicos en Excel sigue siendo la base de la verificación y el análisis en la torre de marfil.
Mi opinión al respecto es simple: la alfabetización ya no se trata solo de saber cómo escribir fórmulas; se trata de saber cómo alimentar esas fórmulas de manera eficiente. La pieza de DataCamp identifica correctamente que 'aprender Excel es un viaje desde cálculos básicos hasta modelado de datos complejos'. Sin embargo, para el profesional académico, el 'viaje' a menudo se atasca en la frontera de la entrada de datos. Si te lleva doce horas extraer una tabla de un informe de subvención y solo diez minutos analizarla, tu cuello de botella no es la competencia en Excel, es la adquisición de datos. Necesitamos dejar de tratar los Datos Académicos en Excel como un destino y empezar a tratar el pipeline automatizado como el vehículo. La verdadera experiencia radica en dominar la fase de 'pre-Excel': el procesamiento por lotes de PDF y el OCR financiero complejo. Al automatizar la entrada, permitimos que la mente humana se centre en los aspectos de 'liderazgo de pensamiento' de la investigación, en lugar de la monotonía clerical de copiar y pegar números de una pantalla.
El cuello de botella crítico: estandarización de conjuntos de datos académicos
El principal punto de fricción en la investigación es que la dificultad para estandarizar los formatos de datos causa inconsistencias en los gráficos y resultados estadísticos. Al tratar con Academic Data Excel, los investigadores a menudo se enfrentan a un panorama fragmentado de fuentes. Una universidad puede publicar sus informes de dotación en un diseño de PDF específico, mientras que una agencia federal de subvenciones utiliza otro. Cuando intentas agregar estos para un estudio longitudinal, la falta de estandarización crea una "deriva de datos" que puede arruinar tu significancia estadística.
Imagina intentar ejecutar un Análisis de Regresión en tres conjuntos de datos diferentes donde las fechas tienen formatos distintos y los símbolos de moneda se aplican de manera inconsistente. Esto no es solo una molestia menor; conduce a errores masivos durante el proceso de Conciliación. Si los datos del Libro Mayor de una fuente cuentan los "Activos Netos" de manera diferente a otra, tu resultado final de Academic Data Excel se convierte en una responsabilidad en lugar de un activo. La entrada manual es el enemigo aquí. Los humanos, a medida que la fatiga se instala, comienzan a tomar decisiones "creativas" sobre dónde debe ir un punto decimal o cómo truncar una cadena larga. Estas microdecisiones se convierten en un desastre cuando presionas el botón "Calcular".
La estandarización requiere un compromiso implacable con la estructura. Necesitas un sistema que no solo lea texto, sino que comprenda la Topología de Tabla. Estamos hablando de identificar Encabezados Multinivel, manejar Celdas Combinadas y mantener la integridad de las Filas Anidadas. Sin la automatización de datos de investigación, esencialmente estás pidiendo a tus asistentes de investigación que sean escáneres humanos, un rol que es costoso y propenso a una alta rotación. El objetivo es alcanzar un estado en el que los datos estén "listos para Excel" en el momento en que salgan del PDF. Esto significa pre-limpieza, pre-formateo y asegurar que cada archivo de Academic Data Excel siga un esquema estricto antes de que toque tu software de análisis.
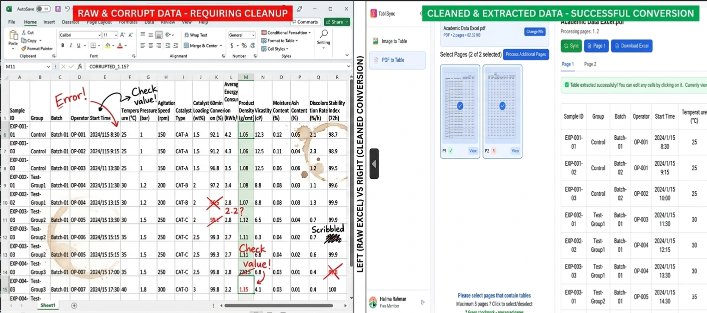
Inmersión Técnica Profunda: Entrada Manual vs. Automatización de TabliSync
Veamos los números fríos y duros. Cuando hablamos de Academic Data Excel, el 'costo de hacer negocios' se mide generalmente en horas-hombre. Para un proyecto de investigación típico que involucra 500 páginas de divulgaciones financieras, un operador humano calificado tarda aproximadamente de 4 a 6 minutos por página en transcribir con precisión una tabla compleja. Eso es aproximadamente de 40 a 50 horas de trabajo. A la tarifa de un asistente de investigación, te enfrentas a una fuga presupuestaria significativa. Además, la Tasa de Error para la entrada manual generalmente ronda el 3-5% para datos numéricos densos.
| Característica | Entrada Manual de Datos | Automatización TabliSync |
|---|---|---|
| Velocidad de Procesamiento | 4-6 minutos por página | 3-10 segundos por página |
| Tasa de Precisión | 95% - 97% (disminuye con la fatiga) | 99.5% + (precisión constante de OCR) |
| Procesamiento por Lotes | Imposible (tarea serial) | Admitido (puede procesar más de 1000 páginas simultáneamente) |
| Costo por 100 Páginas | Aprox. $400 - $600 (mano de obra) | Aprox. $10 - $20 (créditos API/SaaS) |
| Conciliación | Se requiere verificación cruzada manual | Coincidencia automatizada del Libro Mayor General a través de Webhook |
La ganancia de Eficiencia no se trata solo de velocidad; se trata de Ahorro de Costos. En un estudio de caso que involucra una importante escuela de negocios europea, el departamento gastaba 15.000 € anuales solo en mano de obra estudiantil para la extracción de datos. Después de implementar la extracción automatizada de tablas a través de TabliSync, redujeron este gasto a menos de 1.200 €. Más importante aún, el tiempo hasta la obtención de información se redujo drásticamente. La investigación que solía tardar un semestre completo en prepararse ahora estaba lista para el análisis de Academic Data Excel en tres días. Este es el poder de la automatización de datos de investigación: transforma la economía de la información.
El Flujo de Trabajo de TabliSync: Una Clase Magistral de 3 Pasos
Procesar Academic Data Excel no tiene por qué ser un arte oscuro. Hemos diseñado un flujo de trabajo que prioriza el procesamiento por lotes de PDF sin sacrificar el control granular requerido para la investigación de alto riesgo. Siga estos pasos para maximizar su producción.
Paso 1: Ingesta Inteligente y Preprocesamiento
Primero, debe agregar sus fuentes. Ya sean documentos históricos escaneados o PDFs nacidos digitalmente, el motor de complejo OCR financiero de TabliSync necesita analizar la capa del documento. No solo 'carga'; define el Esquema de Datos. Por ejemplo, si está extrayendo un Libro Mayor, debe identificar las columnas 'Débito' y 'Crédito'. Nuestro sistema utiliza Visión por Computadora para detectar líneas y espacios en blanco, creando un mapa estructural antes de leer un solo carácter. Nota: Asegúrese siempre de que sus escaneos tengan al menos 300 DPI para obtener resultados óptimos de Excel de Datos Académicos. Las resoluciones más bajas pueden provocar 'alucinaciones de caracteres', especialmente en subíndices pequeños comunes en las notas a pie de página académicas.
Paso 2: Extracción y Refinamiento Automatizado de Tablas
Una vez que el documento está mapeado, comienza la extracción automatizada de tablas. TabliSync no solo 'raspa' texto; reconstruye la lógica de la tabla. Si una fila se extiende a través de dos páginas, una pesadilla común en Excel de Datos Académicos, el software utiliza Vinculación Contextual para unirlas nuevamente. Puede previsualizar la extracción en tiempo real. Aquí es donde aplica las reglas de Limpieza de Datos. Por ejemplo, puede indicar al sistema que 'Ignore todas las filas que contengan la palabra Total' o 'Convierta todas las fechas al formato ISO 8601'. Este nivel de automatización de datos de investigación garantiza que los datos que llegan a su hoja de cálculo ya estén limpios. Utilice la función 'Regex Personalizado' si tiene identificadores académicos específicos (como números DOI) que deben validarse durante la extracción.
Paso 3: Exportación e Integración a través de Webhooks
El paso final es extraer los datos. Si bien Academic Data Excel es el estándar, TabliSync permite flujos de trabajo avanzados de Reconciliación. Puede configurar un Webhook para enviar los datos extraídos directamente a su Software Estadístico o a una base de datos centralizada. Si prefiere el enfoque clásico, la exportación de Excel está optimizada para Tablas Dinámicas. Nos aseguramos de que los números se exporten como números, no como texto, lo que le ahorrará el dolor de cabeza del error del 'Triángulo Verde' en Excel. Consejo Profesional: Utilice nuestra función 'Plantilla'. Si tiene 500 informes de la misma fuente, defina las zonas de extracción una vez y deje que el procesamiento por lotes de PDF se encargue del resto mientras usted toma un café.

Caso de Uso Avanzado: Gestión de OCR Financiero Complejo en Subvenciones
La gestión de subvenciones es el alma de la universidad, pero produce algunos de los datos más desordenados. Al tratar con Academic Data Excel en un contexto financiero, no solo busca nombres; busca Pistas de Auditoría. Aquí se requiere OCR financiero complejo porque los informes de subvenciones a menudo incluyen firmas manuscritas, sellos de goma y texto superpuesto, todo lo cual puede confundir al software estándar.
Recientemente, ayudamos a un grupo de investigación a analizar 30 años de asignaciones de subvenciones de los NIH. Los datos estaban atrapados en miles de memorandos escaneados. Al aprovechar la automatización de datos de investigación, pudimos extraer códigos de Libro Mayor y reconciliarlos con los registros de gastos internos de la universidad. El proceso de Reconciliación, que normalmente requiere la verificación manual de cada línea de artículo, se automatizó en un 80%. El sistema marcó solo las filas donde la confianza del OCR era inferior al 90%, lo que permitió a los investigadores centrarse en los casos extremos. Este enfoque de Academic Data Excel garantiza que el conjunto de datos final esté 'listo para auditoría'. Se trata de construir una cadena de custodia para sus datos, asegurando que cada celda de su hoja de cálculo pueda rastrearse hasta su coordenada original en el PDF de origen.
Garantizar la Confianza y el Cumplimiento en los Datos de Investigación
En el mundo de Academic Data Excel, la Confianza es primordial. Si su proceso de extracción de datos es una 'caja negra', sus colegas no podrán replicar sus resultados. Es por eso que la automatización de datos de investigación debe ser transparente. TabliSync proporciona un Registro de Auditoría completo para cada extracción. También cumplimos con los estándares GDPR y FERPA, lo que garantiza que los datos sensibles de estudiantes o participantes se manejen con Cifrado de Nivel Empresarial.
Además, al procesar Academic Data Excel para su publicación, debe cumplir con los Principios FAIR (Localizables, Accesibles, Interoperables y Reutilizables). La entrada manual de datos es la antítesis de FAIR porque es opaca y propensa a 'correcciones' no documentadas. Al utilizar la extracción automatizada de tablas, crea un flujo de trabajo repetible y documentado. Si un revisor pregunta cómo llegó a una determinada cifra, puede señalar la plantilla específica de TabliSync y el archivo fuente sin procesar. Este nivel de Experiencia y Autoridad es lo que separa la investigación de alto impacto del resto. Usted no es solo un investigador; es un administrador de datos.
El Papel de los Webhooks en los Flujos de Trabajo de Investigación Modernos
¿Por qué detenerse en un archivo estático? El verdadero poder de Academic Data Excel se desbloquea cuando se convierte en parte de un ecosistema vivo. Aquí es donde entran en juego los Webhooks. Un Webhook es esencialmente un mensajero digital. En el momento en que TabliSync termina de procesar un lote de PDF, puede enviar una 'señal' a otro software, como el sistema ERP de su departamento o un script de Python personalizado, transportando los datos con él.
Para un líder de proyecto, esto significa que puedes crear un Panel Automatizado. A medida que tu equipo carga nuevos informes de campo o resultados de laboratorio, el archivo maestro Excel de Datos Académicos se actualiza en tiempo real. Ya no tienes que esperar un 'volcado de datos' semanal. Esto es automatización de datos de investigación en su máxima expresión. Permite la Investigación Ágil, donde las decisiones se pueden tomar basándose en la información más actualizada disponible. Si el Libro Mayor muestra un aumento repentino en los costos de equipos de laboratorio, lo ves al instante, no tres semanas después cuando la entrada manual finalmente se completa. Esta es la ventaja del SaaS: pasar de documentos estáticos a flujos de datos fluidos.
Estudio de Caso: Estudio Longitudinal de Sociología a Gran Escala
Considera el 'Proyecto de Crecimiento Urbano', un estudio de varias décadas que involucra más de 10.000 registros históricos de censo. Estos registros nunca fueron pensados para una computadora. Son monstruosidades de varias columnas y varias páginas. El equipo inicialmente intentó un enfoque de entrada manual 'crowdsourced', pero el Excel de Datos Académicos que produjeron estaba plagado de errores debido a las diferentes interpretaciones de los encabezados del censo.
Al cambiar al procesamiento por lotes de PDF de TabliSync, establecieron una única 'Fuente de Verdad'. Desarrollamos un modelo de extracción personalizado que entendía la tipografía al estilo de los años 50. ¿El resultado? Archivos de Excel de Datos Académicos que eran un 40% más precisos que las versiones transcritas por humanos. El proyecto ahorró más de 2.000 horas de trabajo, lo que les permitió expandir el alcance de su estudio a dos ciudades adicionales. Esto no se trataba solo de 'ahorrar tiempo'; se trataba de Expandir el Horizonte de la Investigación Posible. Cuando el costo de los datos disminuye, el valor de la investigación aumenta.

Superando el Desafío de los Documentos 'No Estándar'
La parte más difícil de Academic Data Excel es el documento 'no estándar'. Ya sabes, esos: la tabla está inclinada en un ángulo de 15 grados, o hay una mancha de café sobre la columna 'Total'. El OCR estándar falla aquí. TabliSync utiliza Restauración de Imágenes Basada en Redes Neuronales para 'limpiar' el documento antes de que comience la extracción. Enderezamos la imagen, mejoramos el contraste y eliminamos el ruido digital.
Esto es crucial para la automatización de datos de investigación porque los archivos académicos rara vez están en perfecto estado. Si estás trabajando con OCR financiero complejo para un proyecto de historia del pensamiento económico, estás lidiando con papel amarillento y quebradizo. Nuestra tecnología trata el documento como un objeto físico primero, reconstruyendo su geometría antes de intentar leer el texto. Esto asegura que tu Academic Data Excel no tenga 'deriva', donde las columnas comienzan a desplazarse a mitad de página. La precisión no es opcional; es la base de la Confianza en la comunidad académica.
Preguntas Frecuentes
¿Cómo maneja TabliSync las tablas de varias páginas en Academic Data Excel?
El manejo de tablas que abarcan varias páginas es una característica principal de nuestra extracción automatizada de tablas. A diferencia de los raspadores básicos que tratan cada página como un silo, TabliSync utiliza Lógica de Persistencia de Encabezados. Identifica los encabezados de columna en la página uno y los 'recuerda' a medida que avanza a las páginas subsiguientes. Esto permite que el sistema concatene sin problemas las filas en una única hoja continua de Academic Data Excel. Por ejemplo, si un informe de Libro Mayor abarca 50 páginas, TabliSync producirá una tabla unificada en lugar de 50 fragmentadas, preservando la integridad de tu proceso de Conciliación y ahorrando horas de fusión manual.
¿Puedo procesar notas o anotaciones escritas a mano en Excel?
Si bien Academic Data Excel se enfoca principalmente en texto estructurado, nuestro OCR financiero complejo incluye un módulo dedicado de HTR (Reconocimiento de Texto Manuscrito). Esto es particularmente útil para investigadores que trabajan con subvenciones de archivo o cuadernos de laboratorio donde las figuras pueden estar escritas a mano en los márgenes. El sistema se puede entrenar para reconocer estilos de escritura específicos, convirtiéndolos en celdas digitales dentro de su hoja de cálculo. Sin embargo, para una máxima eficiencia en la automatización de datos de investigación, recomendamos usar esto para 'datos suplementarios' en lugar de conjuntos de datos primarios, ya que la escritura a mano inherentemente tiene un requisito de verificación ligeramente mayor que el texto escrito.
¿Cuál es el protocolo de seguridad para datos de investigación sensibles?
La seguridad está integrada en nuestro marco de automatización de datos de investigación. Entendemos que Academic Data Excel a menudo contiene PII (Información de Identificación Personal) sensible o datos propietarios del Libro Mayor General. TabliSync utiliza cifrado AES-256 para todos los datos en reposo y TLS 1.3 para los datos en tránsito. Cumplimos con SOC2 Tipo II y ofrecemos opciones de 'Residencia de Datos' para instituciones que requieren que los datos permanezcan dentro de fronteras geográficas específicas (como la UE). También proporcionamos una Función de Redacción que puede oscurecer automáticamente nombres o identificaciones sensibles durante la fase de procesamiento de PDF por lotes, garantizando el cumplimiento de las leyes de privacidad.
¿TabliSync admite documentos académicos no ingleses?
Sí, nuestro motor de extracción automática de tablas es multilingüe. Soportamos más de 40 idiomas, incluyendo escrituras complejas como chino, japonés y árabe. Esto es vital para proyectos globales de Academic Data Excel donde podría estar reconciliando datos del Libro Mayor General de socios internacionales. El sistema mantiene la codificación de caracteres (UTF-8) durante todo el proceso de extracción, asegurando que los caracteres especiales, acentos y símbolos aparezcan correctamente en su archivo Excel final sin el temido 'mojibake' o texto ilegible. Este nivel de Experiencia garantiza que su investigación internacional siga siendo precisa y profesional.
¿Cómo integro TabliSync con mis herramientas estadísticas existentes?
La forma más eficiente es a través de nuestra arquitectura de Webhook. Una vez que la extracción de Academic Data Excel se completa, TabliSync puede activar una solicitud POST a su servidor o a un integrador de terceros como Zapier. Esto le permite mover datos automáticamente a herramientas como Stata, R o entornos de Python. Para aquellos menos inclinados técnicamente, ofrecemos Cloud Integrations directas con Google Drive, Dropbox y OneDrive. Esto asegura que su canalización de research data automation sea "sin fricciones": los datos van del PDF a su carpeta lista para el análisis sin que usted tenga que hacer clic manualmente en 'Descargar' o 'Subir'.
¿Puede TabliSync manejar formatos de celda complejos como texto en negrita o cursiva?
Absolutamente. Al generar Academic Data Excel, TabliSync se puede configurar para preservar los atributos de 'Texto enriquecido' del PDF original. Esto es importante cuando las cifras en negrita indican Statistical Significance o cuando se utilizan cursivas para la nomenclatura científica. Nuestra automated table extraction no solo extrae la cadena de texto sin formato; puede capturar los metadatos de la celda. Esto significa que su hoja de cálculo puede reflejar las señales visuales del documento original, haciendo que el proceso de Reconciliation y revisión sea mucho más intuitivo para el investigador humano que finalmente audita la salida.
¿Qué sucede si el PDF tiene un diseño de tabla muy no estándar?
Aquí es donde brilla el 'Zonal OCR' de TabliSync. Si la IA de automated table extraction no puede detectar automáticamente un diseño muy creativo o desordenado, puede dibujar manualmente 'Extraction Zones'. Usted define exactamente dónde están las columnas y las filas, y el sistema lo guarda como una Template. Para cualquier documento futuro en el mismo formato, el batch PDF processing seguirá su mapa personalizado. Esto combina el poder de research data automation con la precisión de la supervisión humana, asegurando que incluso las tareas de Academic Data Excel más "imposibles" se completen con un 100% de precisión estructural.
¿Hay un límite en la cantidad de archivos que puedo procesar a la vez?
Nuestro motor de procesamiento por lotes de PDF está diseñado para alto rendimiento. Hemos procesado lotes de hasta 50.000 páginas para auditorías universitarias. El sistema utiliza escalado elástico, lo que significa que aumenta la potencia de cálculo a medida que crece su cola. Para el usuario, esto significa que, ya sea que esté procesando un archivo Academic Data Excel o mil, el tiempo de espera por página sigue siendo notablemente bajo. Esta es la definición de eficiencia: proporcionar una herramienta que se escala con sus ambiciones de investigación, no en su contra, asegurando que su libro mayor esté siempre actualizado.
¿Cómo funciona el precio para las instituciones académicas?
Ofrecemos niveles especializados de SaaS para la educación superior. Entendemos que los proyectos de Academic Data Excel a menudo se financian con subvenciones, por lo que ofrecemos modelos de 'pago por uso' y licencias anuales 'ilimitadas' para departamentos. Esta flexibilidad permite a los investigadores tener en cuenta el ahorro de costos en sus propuestas de subvención. Al automatizar la automatización de datos de investigación, puede demostrar a sus patrocinadores cómo está maximizando su inversión al reducir los gastos administrativos y aumentar el volumen de datos que puede analizar por dólar gastado.
¿Qué es la función de 'Conciliación' en TabliSync?
Conciliación es nuestra herramienta avanzada de validación. Le permite cotejar los datos extraídos de Academic Data Excel con una segunda fuente. Por ejemplo, si extrae datos del libro mayor de un PDF, TabliSync puede verificar automáticamente si los totales coinciden con una entrada existente en un archivo CSV o una base de datos. Si hay una discrepancia, el sistema marca la celda específica para su revisión. Esta es una parte esencial de la OCR financiera compleja, ya que proporciona una segunda capa de defensa contra errores, asegurando que su investigación se base en datos verificados y a prueba de balas.
El futuro de la investigación es automatizado
La transición a la automatización de datos de investigación ya no es un lujo; es una necesidad para cualquiera que se tome en serio la investigación de alto impacto. Cada hora que dedica a escribir datos manualmente en una hoja de Excel de datos académicos es una hora robada al análisis, la síntesis y el descubrimiento. Hemos entrado en una era en la que la extracción automatizada de tablas y el OCR financiero complejo son los "héroes silenciosos" del laboratorio, trabajando en segundo plano para garantizar que los datos en los que confía sean tan precisos como las teorías que pone a prueba.
Al adoptar TabliSync, no solo está comprando software; está actualizando toda su metodología de investigación. Está pasando de un mundo de "fricción de datos", donde cada PDF es un obstáculo, a un mundo de "flujo de datos", donde la información se mueve sin problemas de la fuente a la hoja de cálculo. La eficiencia y el ahorro de costos son claros, pero el verdadero premio es la claridad mental que proviene de saber que sus datos están estandarizados, reconciliados y listos para que el mundo los vea. Es hora de dejar de ser un empleado de entrada de datos y empezar a ser el investigador visionario para el que fue formado. La velocidad de su descubrimiento no debe limitarse por la velocidad de su teclado.
Dé el Salto: Automatice su Excel de Datos Académicos Hoy
Ha visto los datos, las comparaciones técnicas y los flujos de trabajo. El cuello de botella en su investigación no es su talento, son sus herramientas. Cada día que retrasa la implementación de la automatización de datos de investigación es un día más perdido en el vacío de la entrada manual. Imagine lo que podría lograr si sus archivos de Excel de datos académicos se generaran en segundos en lugar de semanas. Piense en las tareas de procesamiento por lotes de PDF que actualmente acumulan polvo digital porque son "demasiado grandes" para manejarlas. Esos proyectos ahora están a su alcance.
TabliSync fue creado por personas que entienden los rigores de la academia. Sabemos que un solo dígito mal colocado en un Libro Mayor puede invalidar meses de trabajo. Es por eso que creamos una herramienta que prioriza la precisión, la velocidad y la Conciliación. No permita que su investigación se vea frenada por flujos de trabajo obsoletos. Haga clic en el enlace de abajo para comenzar su prueba gratuita. Experimente de primera mano el poder de la extracción automatizada de tablas y vea cómo 5.000 páginas de datos pueden convertirse en una hoja de Excel limpia y organizada antes de su próxima reunión. El futuro de su investigación le está esperando. Únase a los miles de académicos que ya han recuperado su tiempo. Comience ahora con TabliSync y transforme el caos de sus datos en claridad para su investigación.
¿Qué es Cómo procesar Datos Académicos Excel rápidamente?
Respuestas rápidas sobre Cómo procesar Datos Académicos Excel rápidamente y cómo TabliSync ayuda a los equipos a trabajar más rápido en Excel.
¿Qué es Cómo procesar Datos Académicos Excel rápidamente?
Cómo procesar Datos Académicos Excel rápidamente cubre flujos prácticos de Excel, errores comunes y patrones de automatización. Esta guía de TabliSync explica el concepto, muestra ejemplos y enlaza tutoriales relacionados.
¿Cómo puede TabliSync ayudar con Cómo procesar Datos Académicos Excel rápidamente?
TabliSync puede extraer tablas de capturas o PDF, limpiar datos desordenados y automatizar tareas repetitivas de Excel relacionadas con Cómo procesar Datos Académicos Excel rápidamente.
¿Por dónde empiezo con Cómo procesar Datos Académicos Excel rápidamente?
Empieza con la visión general de esta página y luego abre los artículos relacionados para guías paso a paso, plantillas y flujos con IA.
Todos los Artículos de Datos Académicos Excel(6)

Cómo calcular los días entre dos fechas
En esta guía, le guiaremos a través del proceso de cálculo del número de días entre dos fechas utilizando software de hoja de cálculo. Esta habilidad crucial puede ayudar en varios escenarios empresariales, como la gestión de proyectos y la elaboración de informes financieros. Le proporcionaremos un enfoque claro paso a paso para configurar su hoja de cálculo para cálculos de fechas, junto con ejemplos prácticos que ilustran situaciones comunes en las que la comprensión de las diferencias de fechas es esencial. Además, compartiremos consejos para garantizar la precisión, como cómo manejar los años bisiestos y los problemas de formato. Al final de este artículo, tendrá la confianza para realizar cálculos de fechas de manera efectiva y explorar cómo TabliSync puede ayudar a organizar sus datos para una mayor eficiencia.

Cómo usar las funciones IF y AND juntas en Excel
Este artículo guía a los usuarios a través del proceso de combinar las funciones IF y AND en Excel, ayudándoles a mejorar su análisis de datos y la generación de informes. Con instrucciones paso a paso y ejemplos prácticos, los lectores mejorarán sus habilidades en hojas de cálculo. Al comprender cómo utilizar estas funciones juntas de manera efectiva, los usuarios pueden crear pruebas lógicas más complejas que son esenciales para la generación precisa de informes y la toma de decisiones empresariales. Se exploran casos de uso comunes, junto con consejos para evitar errores frecuentes. Ya sea usted un contable, miembro de un equipo de finanzas o analista de datos, esta guía proporcionará las herramientas necesarias para potenciar su dominio de Excel y optimizar su flujo de trabajo.

Cómo hacer un gráfico circular con porcentajes en Excel
En el mundo actual impulsado por los datos, la visualización eficaz de la información es crucial para el éxito empresarial. Este artículo proporciona una guía clara y práctica sobre cómo crear gráficos circulares en Excel utilizando datos porcentuales. Ya sea que sea un contador que trabaja con informes financieros o un analista que traduce datos de ventas en formatos visuales, los gráficos circulares pueden mejorar la comprensión y la presentación. Siga los pasos descritos para crear gráficos circulares que reflejen con precisión sus datos y descubra consejos de personalización para mejorar la claridad y el impacto. Además, aprenda cómo TabliSync puede ayudar a preparar sus datos para estas representaciones visuales, haciendo que el proceso sea más fluido y eficiente. Al final de este artículo, tendrá las habilidades para presentar sus datos visualmente, asegurándose de transmitir información de manera efectiva y tomar decisiones informadas basadas en representaciones precisas.

Cómo eliminar un salto de página en Excel
Comprenda qué son los saltos de página y por qué son importantes en Excel, siga instrucciones paso a paso para eliminarlos y aprenda consejos útiles para administrar saltos de página de manera efectiva en hojas de cálculo.

Dominando la Integridad de Datos: Cómo Crear una Lista Desplegable en Excel
Elimine el 99% de los errores de entrada manual de datos implementando protocolos estandarizados de validación de datos en Excel. Logre una reducción del 90% en el tiempo de limpieza de datos mediante el uso de listas desplegables dinámicas y tablas estructuradas. Aproveche la OCR impulsada por IA y TabliSync para transformar datos físicos no estructurados en esquemas de Excel validados al instante. Prepare sus hojas de cálculo para el futuro con arquitecturas de caída escalables y buscables para conjuntos de datos complejos.

Dominando el Desorden: Cómo Eliminar Duplicados en Excel Sin Pérdida de Datos
Ganancias de Eficiencia: Reduzca el tiempo de limpieza manual de datos en más del 90% utilizando flujos de trabajo automatizados. Integridad de Datos: Logre una tasa de error del 0% en la entrada manual al pasar de 'Buscar y Reemplazar' a la deduplicación basada en esquemas. M itigación de Riesgos: Prevenga el 100% de las eliminaciones accidentales utilizando entornos de Power Query no destructivos. Preparación para el Futuro: Pase de la limpieza reactiva a la Higiene de Datos proactiva a través de la automatización integrada con IA.
Stop Manual Data Entry – Extract Tables in Seconds
Convert any image or PDF table to Excel instantly with 99.9% accuracy. TabliSync's AI-powered OCR handles handwritten forms, receipts, and complex tables – then syncs directly to Google Sheets, Notion, or Airtable
Try TabliSync Free Now