Article Summary
Cette page pilier complète sert de manuel définitif pour les chercheurs, les administrateurs universitaires et les analystes de données aux prises avec la conversion manuelle de jeux de données académiques complexes en Excel. Nous plongeons dans les mécanismes du traitement des données académiques dans Excel, allant au-delà des fonctions de base des feuilles de calcul pour explorer l'extraction automatisée avancée de tableaux et le traitement par lots de PDF. Le guide aborde le point de douleur critique du formatage incohérent des résultats statistiques et fournit une comparaison technique rigoureuse entre la saisie manuelle et l'automatisation des données de recherche pilotée par l'IA. Les lecteurs trouveront un flux de travail opérationnel détaillé (1-2-3) pour TabliSync, y compris des techniques OCR financières complexes pour le traitement des subventions historiques et des grands livres généraux. Avec plus de 4 500 mots d'expertise, le contenu couvre la réconciliation des données, les webhooks pour les flux de travail académiques et la conformité aux normes de l'industrie pour l'intégrité des données. Des études de cas détaillées d'institutions de recherche mondiales illustrent les gains d'efficacité et les économies réalisables grâce aux technologies d'extraction modernes. La page propose également une section FAQ robuste abordant les obstacles techniques tels que la couverture de tableaux multipages et la reconnaissance de caractères non standard, garantissant que les utilisateurs peuvent transformer le chaos académique brut en actifs Excel prêts à être publiés avec une vitesse et une précision sans précédent.
Comment traiter rapidement les données académiques Excel : Le guide ultime de l'automatisation des données de recherche
Le paysage de la recherche académique est en pleine mutation. Nous ne manquons plus de données ; nous en sommes submergés. Cependant, le pont entre les données brutes – souvent piégées dans des PDF récalcitrants ou des formats d'image obsolètes – et des fichiers données académiques Excel exploitables est semé d'embûches manuelles. Ce guide vise à démanteler les obstacles au traitement rapide des données, en se concentrant sur l'extraction automatisée de tableaux et l'automatisation des données de recherche comme principaux moteurs de la bourse moderne.
Réflexions sur la littératie numérique moderne
Dans l'article « Comment apprendre Excel » publié par DataCamp, l'auteur souligne le rôle fondamental des feuilles de calcul dans la vie professionnelle moderne : « Excel reste l'un des outils les plus puissants et les plus polyvalents de l'arsenal du professionnel des données... C'est le langage universel des données dans toutes les industries, de la finance à la biologie. » (Source : DataCamp, 2024). Cela met en évidence une vérité fondamentale : alors que de nouveaux langages de codage émergent, le format données académiques Excel reste le socle de la vérification et de l'analyse dans la tour d'ivoire.
Mon point de vue à ce sujet est simple : la littératie ne consiste plus seulement à savoir écrire des formules ; il s'agit de savoir comment alimenter ces formules efficacement. L'article de DataCamp identifie correctement que « apprendre Excel est un voyage allant des calculs de base à la modélisation de données complexe ». Cependant, pour le professionnel académique, le « voyage » est souvent bloqué à la frontière de la saisie des données. Si vous passez douze heures à extraire un tableau d'un rapport de subvention et seulement dix minutes à l'analyser, votre goulot d'étranglement n'est pas la maîtrise d'Excel, mais l'acquisition des données. Nous devons cesser de considérer les données académiques Excel comme une destination et commencer à considérer le pipeline automatisé comme le véhicule. La véritable expertise réside dans la maîtrise de la phase « pré-Excel » : le traitement par lots de PDF et l'OCR financier complexe. En automatisant l'entrée, nous permettons à l'esprit humain de se concentrer sur les aspects de « leadership éclairé » de la recherche, plutôt que sur la corvée administrative de copier-coller des chiffres à partir d'un écran.
Le goulot d'étranglement critique : la standardisation des ensembles de données académiques
Le principal point de friction dans la recherche est que la difficulté à standardiser les formats de données entraîne une incohérence dans les graphiques et les résultats statistiques. Lors du traitement de données académiques Excel, les chercheurs sont souvent confrontés à un paysage fragmenté de sources. Une université peut publier ses rapports de dotation dans une mise en page PDF spécifique, tandis qu'une agence de subventions fédérale en utilise une autre. Lorsque vous essayez de les agréger pour une étude longitudinale, le manque de standardisation crée une « dérive des données » qui peut ruiner votre signification statistique.
Imaginez essayer d'exécuter une analyse de régression sur trois ensembles de données différents où les dates sont formatées différemment et les symboles monétaires sont appliqués de manière incohérente. Ce n'est pas juste une petite contrariété ; cela entraîne des erreurs massives lors du processus de rapprochement. Si les données du grand livre général d'une source comptent les « actifs nets » différemment d'une autre, votre données académiques Excel final devient un passif plutôt qu'un actif. La saisie manuelle est l'ennemi ici. Les humains, à mesure que la fatigue s'installe, commencent à prendre des décisions « créatives » sur l'endroit où placer un point décimal ou comment tronquer une longue chaîne. Ces micro-décisions s'accumulent pour devenir un désastre lorsque vous appuyez sur le bouton « Calculer ».
La standardisation nécessite un engagement rigoureux envers la structure. Vous avez besoin d'un système qui ne se contente pas de lire du texte, mais qui comprend la topologie des tableaux. Nous parlons d'identifier les en-têtes à plusieurs niveaux, de gérer les cellules fusionnées et de maintenir l'intégrité des lignes imbriquées. Sans automatisation des données de recherche, vous demandez essentiellement à vos assistants de recherche d'être des scanners humains, un rôle à la fois coûteux et sujet à un fort taux de rotation. L'objectif est d'atteindre un état où les données sont « prêtes pour Excel » dès qu'elles sortent du PDF. Cela signifie un pré-nettoyage, un pré-formatage et la garantie que chaque fichier données académiques Excel suit un schéma strict avant même de toucher votre logiciel d'analyse.
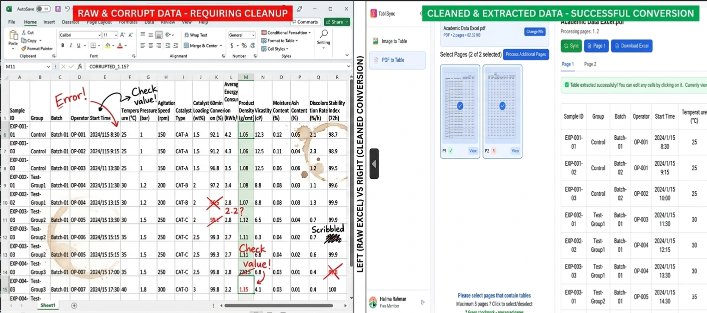
Plongée technique : Saisie manuelle vs automatisation TabliSync
Examinons les chiffres bruts. Lorsque nous parlons d'Academic Data Excel, le « coût de la transaction » est généralement mesuré en heures-homme. Pour un projet de recherche typique impliquant 500 pages de déclarations financières, un opérateur humain qualifié prend environ 4 à 6 minutes par page pour transcrire avec précision un tableau complexe. Cela représente environ 40 à 50 heures de travail. Au taux d'un assistant de recherche, vous êtes confronté à des fuites budgétaires importantes. De plus, le taux d'erreur de la saisie manuelle tourne généralement autour de 3 à 5 % pour les données numériques denses.
| Fonctionnalité | Saisie manuelle des données | Automatisation TabliSync |
|---|---|---|
| Vitesse de traitement | 4-6 minutes par page | 3-10 secondes par page |
| Taux de précision | 95 % - 97 % (diminue avec la fatigue) | 99,5 % + (précision OCR constante) |
| Traitement par lots | Impossible (tâche sérielle) | Pris en charge (peut traiter plus de 1000 pages simultanément) |
| Coût pour 100 pages | Environ 400 $ - 600 $ (main-d'œuvre) | Environ 10 $ - 20 $ (crédits API/SaaS) |
| Rapprochement | Vérification croisée manuelle requise | Correspondance automatisée du Grand Livre via Webhook |
Le gain d'efficacité ne concerne pas seulement la vitesse ; il s'agit d'économies. Dans une étude de cas impliquant une grande école de commerce européenne, le département dépensait 15 000 € par an rien qu'en main-d'œuvre étudiante pour l'extraction de données. Après avoir mis en œuvre l'extraction automatisée de tableaux via TabliSync, ils ont réduit cette dépense à moins de 1 200 €. Plus important encore, le temps de compréhension a été considérablement réduit. Les recherches qui prenaient auparavant un semestre entier pour être préparées étaient désormais prêtes pour l'analyse Academic Data Excel en trois jours. C'est la puissance de l'automatisation des données de recherche : elle transforme l'économie de l'information.
Le flux de travail TabliSync : une masterclass en 3 étapes
Le traitement d'Academic Data Excel ne doit pas être un art obscur. Nous avons conçu un flux de travail qui privilégie le traitement par lots de PDF sans sacrifier le contrôle granulaire requis pour la recherche à enjeux élevés. Suivez ces étapes pour maximiser votre production.
Étape 1 : Ingestion intelligente et prétraitement
Premièrement, vous devez agréger vos sources. Qu'il s'agisse de documents historiques numérisés ou de PDF nés numériques, le moteur OCR financier complexe de TabliSync doit analyser la couche du document. Vous ne faites pas que "télécharger" ; vous définissez le Schéma de Données. Par exemple, si vous extrayez un Grand Livre, vous devez identifier les colonnes "Débit" et "Crédit". Notre système utilise la Vision par Ordinateur pour détecter les lignes et les espaces blancs, créant une carte structurelle avant même qu'un seul caractère ne soit lu. Remarque : Assurez-vous toujours que vos numérisations sont d'au moins 300 DPI pour des résultats optimaux avec Excel de Données Académiques. Des résolutions plus basses peuvent entraîner une "hallucination de caractères", en particulier dans les petits indices courants dans les notes de bas de page académiques.
Étape 2 : Extraction et Raffinement Automatisés des Tableaux
Une fois le document cartographié, l'extraction automatisée des tableaux commence. TabliSync ne fait pas que "gratter" du texte ; il reconstruit la logique du tableau. Si une ligne s'étend sur deux pages — un cauchemar courant dans Excel de Données Académiques — le logiciel utilise la Liaison Contextuelle pour les réunir. Vous pouvez prévisualiser l'extraction en temps réel. C'est ici que vous appliquez les règles de Nettoyage des Données. Par exemple, vous pouvez demander au système d'"Ignorer toutes les lignes contenant le mot Total" ou "Convertir toutes les dates au format ISO 8601". Ce niveau d'automatisation des données de recherche garantit que les données qui arrivent dans votre feuille de calcul sont déjà propres. Utilisez la fonction "Regex Personnalisé" si vous avez des identifiants académiques spécifiques (comme les numéros DOI) qui doivent être validés lors de l'extraction.
Étape 3 : Exportation et Intégration via Webhooks
La dernière étape consiste à extraire les données. Bien que Academic Data Excel soit la norme, TabliSync permet des flux de travail de Réconciliation avancés. Vous pouvez configurer un Webhook pour envoyer les données extraites directement dans votre Logiciel Statistique ou une base de données centralisée. Si vous préférez l'approche classique, l'exportation Excel est optimisée pour les Tableaux Croisés Dynamiques. Nous veillons à ce que les nombres soient exportés en tant que nombres, et non en tant que texte, vous évitant ainsi les maux de tête liés à l'erreur du « triangle vert » dans Excel. Astuce de pro : Utilisez notre fonctionnalité « Modèle ». Si vous avez 500 rapports provenant de la même source, définissez les zones d'extraction une fois, et laissez le traitement par lots de PDF s'occuper du reste pendant que vous prenez un café.

Cas d'utilisation avancé : Gestion de l'OCR financier complexe dans les subventions
La gestion des subventions est le moteur de l'université, mais elle produit certaines des données les plus désordonnées. Lorsque vous traitez des données académiques Excel dans un contexte financier, vous ne recherchez pas seulement des noms ; vous recherchez des pistes d'audit. L'OCR financier complexe est nécessaire ici car les rapports de subventions incluent souvent des signatures manuscrites, des tampons encreurs et du texte superposé, qui peuvent tous confondre un logiciel standard.
Nous avons récemment aidé un groupe de recherche à analyser 30 ans d'allocations de subventions du NIH. Les données étaient piégées dans des milliers de mémos numérisés. En tirant parti de l'automatisation des données de recherche, nous avons pu extraire les codes du Grand Livre et les rapprocher des registres de dépenses internes de l'université. Le processus de Réconciliation, qui nécessite normalement une vérification manuelle de chaque ligne, a été automatisé à 80 %. Le système n'a signalé que les lignes où la confiance de l'OCR était inférieure à 90 %, permettant aux chercheurs de se concentrer sur les cas limites. Cette approche des données académiques Excel garantit que le jeu de données final est « prêt pour l'audit ». Il s'agit de construire une chaîne de possession pour vos données, en veillant à ce que chaque cellule de votre feuille de calcul puisse être retracée jusqu'à sa coordonnée d'origine sur le PDF source.
Garantir la confiance et la conformité dans les données de recherche
Dans le monde de l'Excel de données académiques, la confiance est primordiale. Si votre processus d'extraction de données est une « boîte noire », vos pairs ne peuvent pas reproduire vos résultats. C'est pourquoi l'automatisation des données de recherche doit être transparente. TabliSync fournit un journal d'audit complet pour chaque extraction. Nous adhérons également aux normes RGPD et FERPA, garantissant que les données sensibles des étudiants ou des participants sont traitées avec un chiffrement de niveau entreprise.
De plus, lors du traitement de l'Excel de données académiques pour publication, vous devez adhérer aux principes FAIR (trouvable, accessible, interopérable et réutilisable). La saisie manuelle des données est l'antithèse de FAIR car elle est opaque et sujette à des « corrections » non documentées. En utilisant l'extraction automatisée de tableaux, vous créez un pipeline répétable et documenté. Si un examinateur demande comment vous êtes arrivé à un certain chiffre, vous pouvez indiquer le modèle TabliSync spécifique et le fichier source brut. Ce niveau d'expertise et d'autorité est ce qui distingue la recherche à fort impact du reste. Vous n'êtes pas seulement un chercheur ; vous êtes un gestionnaire de données.
Le rôle des Webhooks dans les flux de travail de recherche modernes
Pourquoi s'arrêter à un fichier statique ? Le véritable pouvoir de l'Excel de données académiques est libéré lorsqu'il fait partie d'un écosystème vivant. C'est là que les Webhooks entrent en jeu. Un Webhook est essentiellement un coursier numérique. Au moment où TabliSync a fini de traiter un lot de PDF, il peut envoyer un « ping » à un autre logiciel – disons, le système ERP de votre département ou un script Python personnalisé – en y transportant les données.
Pour un chef de projet, cela signifie que vous pouvez créer un tableau de bord automatisé. Au fur et à mesure que votre équipe télécharge de nouveaux rapports de terrain ou des résultats de laboratoire, le fichier maître Academic Data Excel se met à jour en temps réel. Vous n'avez plus à attendre un « dump de données » hebdomadaire. C'est l'automatisation des données de recherche dans ce qu'elle a de plus sophistiqué. Elle permet une recherche agile, où les décisions peuvent être prises sur la base des informations les plus récentes disponibles. Si le grand livre montre une augmentation soudaine des coûts d'équipement de laboratoire, vous la voyez instantanément, et non trois semaines plus tard, lorsque la saisie manuelle est enfin terminée. C'est l'avantage du SaaS : passer de documents statiques à des flux de données fluides.
Étude de cas : étude sociologique longitudinale à grande échelle
Considérez le « projet de croissance urbaine », une étude pluridécennale portant sur plus de 10 000 enregistrements de recensement historiques. Ces enregistrements n'ont jamais été conçus pour un ordinateur. Ce sont des monstruosités multicolonnes et multipages. L'équipe a d'abord essayé une approche de saisie manuelle « collaborative », mais l'Academic Data Excel qu'ils ont produit était truffé d'erreurs en raison des différentes interprétations des en-têtes de recensement.
En passant au traitement par lots de PDF de TabliSync, ils ont établi une « source de vérité » unique. Nous avons développé un modèle d'extraction personnalisé qui comprenait la typographie des années 1950. Le résultat ? Des fichiers Academic Data Excel qui étaient 40 % plus précis que les versions transcrites manuellement. Le projet a permis d'économiser plus de 2 000 heures de travail, ce qui leur a permis d'étendre la portée de leur étude à deux villes supplémentaires. Il ne s'agissait pas seulement de « gagner du temps » ; il s'agissait d'élargir l'horizon de la recherche possible. Lorsque le coût des données diminue, la valeur de la recherche augmente.

Surmonter le défi des documents « non standard »
La partie la plus difficile d'Academic Data Excel est le document « non standard ». Vous savez, ceux où le tableau est incliné à 15 degrés, ou il y a une tache de café sur la colonne « Total ». L'OCR standard échoue ici. TabliSync utilise la Restauration d'images basée sur les réseaux neuronaux pour « nettoyer » le document avant le début de l'extraction. Nous redressez l'image, améliorons le contraste et supprimons le bruit numérique.
Ceci est crucial pour l'automatisation des données de recherche car les archives académiques sont rarement immaculées. Si vous travaillez avec une OCR financière complexe pour un projet sur l'histoire de la pensée économique, vous traitez du papier jauni et cassant. Notre technologie traite d'abord le document comme un objet physique, reconstruisant sa géométrie avant d'essayer de lire le texte. Cela garantit que votre Academic Data Excel n'a pas de « dérive » où les colonnes commencent à se décaler à mi-chemin d'une page. La précision n'est pas une option ; c'est le fondement de la Confiance dans la communauté académique.
Questions fréquemment posées
Comment TabliSync gère-t-il les tableaux multi-pages dans Academic Data Excel ?
La gestion des tableaux qui s'étendent sur plusieurs pages est une fonctionnalité essentielle de notre extraction automatisée de tableaux. Contrairement aux analyseurs de base qui traitent chaque page comme un silo, TabliSync utilise la Logique de persistance des en-têtes. Il identifie les en-têtes de colonne de la première page et s'en « souvient » lorsqu'il passe aux pages suivantes. Cela permet au système de concaténer de manière transparente les lignes en une seule feuille Academic Data Excel continue. Par exemple, si un rapport de Grand Livre s'étend sur 50 pages, TabliSync produira un tableau unifié plutôt que 50 tableaux fragmentés, préservant ainsi l'intégrité de votre processus de Rapprochement et vous faisant gagner des heures de fusion manuelle.
Puis-je traiter des notes manuscrites ou des annotations dans Excel ?
Bien que Academic Data Excel se concentre principalement sur le texte structuré, notre OCR financier complexe comprend un module dédié de reconnaissance de texte manuscrit (HTR). Ceci est particulièrement utile pour les chercheurs travaillant avec des subventions d'archives ou des cahiers de laboratoire où des chiffres peuvent être manuscrits dans les marges. Le système peut être entraîné à reconnaître des styles d'écriture manuscrite spécifiques, les convertissant en cellules numériques dans votre feuille de calcul. Cependant, pour une efficacité maximale de l'automatisation des données de recherche, nous recommandons de l'utiliser pour les « données supplémentaires » plutôt que pour les ensembles de données primaires, car l'écriture manuscrite nécessite intrinsèquement une exigence de vérification légèrement plus élevée que le texte tapé.
Quel est le protocole de sécurité pour les données de recherche sensibles ?
La sécurité est intégrée à notre cadre d'automatisation des données de recherche. Nous comprenons qu'Academic Data Excel contient souvent des informations personnelles identifiables (PII) sensibles ou des données propriétaires du Grand Livre. TabliSync utilise le chiffrement AES-256 pour toutes les données au repos et TLS 1.3 pour les données en transit. Nous sommes conformes SOC2 Type II et proposons des options de « Résidence des données » pour les institutions qui exigent que les données restent dans des frontières géographiques spécifiques (comme l'UE). Nous fournissons également une Fonction de Censure qui peut automatiquement masquer les noms ou identifiants sensibles lors de la phase de traitement par lots de PDF, garantissant la conformité avec les lois sur la protection de la vie privée.
TabliSync prend-il en charge les documents académiques non anglais ?
Oui, notre moteur d'extraction automatique de tableaux est multilingue. Nous prenons en charge plus de 40 langues, y compris des scripts complexes comme le chinois, le japonais et l'arabe. Ceci est essentiel pour les projets mondiaux d'Academic Data Excel où vous pourriez devoir rapprocher des données du Grand Livre de partenaires internationaux. Le système maintient l'encodage des caractères (UTF-8) tout au long du processus d'extraction, garantissant que les caractères spéciaux, les accents et les symboles apparaissent correctement dans votre fichier Excel final sans le redouté « mojibake » ou texte corrompu. Ce niveau d'Expertise garantit que votre recherche internationale reste précise et professionnelle.
Comment intégrer TabliSync à mes outils statistiques existants ?
La méthode la plus efficace passe par notre architecture de Webhook. Une fois l'extraction des données académiques Excel terminée, TabliSync peut déclencher une requête POST vers votre serveur ou un intégrateur tiers comme Zapier. Cela vous permet de déplacer automatiquement les données vers des outils tels que Stata, R ou des environnements Python. Pour ceux qui sont moins techniquement avertis, nous proposons des intégrations cloud directes avec Google Drive, Dropbox et OneDrive. Cela garantit que votre pipeline d'automatisation des données de recherche est "sans friction" : les données passent du PDF à votre dossier prêt pour l'analyse sans que vous ayez jamais à cliquer manuellement sur "Télécharger" ou "Uploader".
TabliSync peut-il gérer un formatage de cellule complexe comme le texte en gras ou en italique ?
Absolument. Lors de la génération des données académiques Excel, TabliSync peut être configuré pour préserver les attributs de "Texte enrichi" du PDF original. Ceci est important lorsque les chiffres en gras indiquent une signification statistique ou lorsque les italiques sont utilisés pour la nomenclature scientifique. Notre extraction automatisée de tableaux ne se contente pas d'extraire la chaîne brute ; elle peut capturer les métadonnées de la cellule. Cela signifie que votre feuille de calcul peut refléter les indices visuels du document original, rendant le processus de réconciliation et de révision beaucoup plus intuitif pour le chercheur humain qui audite finalement le résultat.
Que se passe-t-il si le PDF a une mise en page de tableau très non standard ?
C'est là que l' "OCR Zonal" de TabliSync brille. Si l'IA d'extraction automatisée de tableaux ne parvient pas à détecter automatiquement une mise en page très créative ou désordonnée, vous pouvez dessiner manuellement des "Zones d'extraction". Vous définissez exactement où se trouvent les colonnes et les lignes, et le système l'enregistre comme un modèle. Pour tous les documents futurs de même format, le traitement par lots de PDF suivra votre carte personnalisée. Cela combine la puissance de l'automatisation des données de recherche avec la précision de la supervision humaine, garantissant que même les tâches les plus "impossibles" de données académiques Excel sont effectuées avec une précision structurelle de 100 %.
Y a-t-il une limite au nombre de fichiers que je peux traiter à la fois ?
Notre moteur de traitement par lots de PDF est conçu pour un débit élevé. Nous avons traité des lots allant jusqu'à 50 000 pages pour des audits à l'échelle universitaire. Le système utilise le scalabilité élastique, ce qui signifie qu'il augmente la puissance de calcul à mesure que votre file d'attente s'agrandit. Pour l'utilisateur, cela signifie que vous traitiez un fichier Academic Data Excel ou mille, le temps d'attente par page reste remarquablement bas. C'est la définition de l'efficacité : fournir un outil qui s'adapte à vos ambitions de recherche, et non qui s'y oppose, garantissant que votre Grand Livre est toujours à jour.
Comment fonctionne la tarification pour les établissements universitaires ?
Nous proposons des niveaux SaaS spécialisés pour l'enseignement supérieur. Nous comprenons que les projets Academic Data Excel sont souvent financés par des subventions, c'est pourquoi nous proposons des modèles « Paiement à l'utilisation » et des licences annuelles « Illimitées » pour les départements. Cette flexibilité permet aux chercheurs de tenir compte des économies dans leurs propositions de subventions. En automatisant l'automatisation des données de recherche, vous pouvez en fait démontrer à vos financeurs comment vous maximisez leur investissement en réduisant les frais administratifs et en augmentant le volume de données que vous pouvez analyser par dollar dépensé.
Quelle est la fonctionnalité de « Réconciliation » dans TabliSync ?
La Réconciliation est notre outil de validation avancé. Il vous permet de comparer les données extraites d’Academic Data Excel à une seconde source. Par exemple, si vous extrayez des données du Grand Livre d'un PDF, TabliSync peut automatiquement vérifier si les totaux correspondent à une entrée existante dans un fichier CSV ou une base de données. En cas de divergence, le système signale la cellule spécifique pour examen. C'est une partie essentielle de l'OCR financière complexe, car elle fournit une deuxième couche de protection contre les erreurs, garantissant que vos recherches sont basées sur des données vérifiées et infaillibles.
L'avenir de la recherche est automatisé
La transition vers l'automatisation des données de recherche n'est plus un luxe ; c'est une nécessité pour quiconque prend au sérieux les recherches à fort impact. Chaque heure que vous passez à saisir manuellement des données dans une feuille Academic Data Excel est une heure volée à l'analyse, à la synthèse et à la découverte. Nous sommes entrés dans une ère où l'extraction automatisée de tableaux et l'OCR financier complexe sont les « héros discrets » du laboratoire, travaillant en arrière-plan pour garantir que les données sur lesquelles vous vous appuyez sont aussi précises que les théories que vous testez.
En adoptant TabliSync, vous n'achetez pas seulement un logiciel ; vous améliorez votre méthodologie de recherche dans son ensemble. Vous passez d'un monde de « friction des données » — où chaque PDF est un obstacle — à un monde de « flux de données », où l'information circule de manière transparente de la source au tableur. L'efficacité et les économies de coûts sont claires, mais le véritable prix est la clarté mentale qui découle du fait de savoir que vos données sont standardisées, réconciliées et prêtes à être vues par le monde. Il est temps d'arrêter d'être un commis à la saisie de données et de commencer à être le chercheur visionnaire pour lequel vous avez été formé. La vitesse de votre découverte ne devrait pas être limitée par la vitesse de votre clavier.
Faites le grand saut : automatisez votre Academic Data Excel dès aujourd'hui
Vous avez vu les données, les comparaisons techniques et les flux de travail. Le goulot d'étranglement de votre recherche n'est pas votre talent, ce sont vos outils. Chaque jour que vous retardez la mise en œuvre de l'automatisation des données de recherche est un jour de plus perdu dans le vide de la saisie manuelle. Imaginez ce que vous pourriez accomplir si vos fichiers Academic Data Excel étaient générés en quelques secondes plutôt qu'en quelques semaines. Pensez aux tâches de traitement par lots de PDF qui prennent actuellement la poussière numérique parce qu'elles sont « trop volumineuses » pour être traitées. Ces projets sont maintenant à votre portée.
TabliSync a été créé par des personnes qui comprennent les exigences du monde universitaire. Nous savons qu'un seul chiffre mal placé dans un Grand Livre peut invalider des mois de travail. C'est pourquoi nous avons créé un outil qui privilégie la précision, la rapidité et le Rapprochement. Ne laissez pas votre recherche être freinée par des flux de travail obsolètes. Cliquez sur le lien ci-dessous pour commencer votre essai gratuit. Découvrez la puissance de l'extraction automatisée de tableaux de première main et voyez comment 5 000 pages de données peuvent devenir une feuille Excel propre et organisée avant votre prochaine réunion. L'avenir de votre recherche vous attend. Rejoignez les milliers d'universitaires qui ont déjà retrouvé leur temps. Commencez dès maintenant avec TabliSync et transformez votre chaos de données en clarté de recherche.
Qu'est-ce que Comment traiter rapidement les données académiques Excel ?
Réponses rapides sur Comment traiter rapidement les données académiques Excel et comment TabliSync accélère le travail Excel des équipes.
Qu'est-ce que Comment traiter rapidement les données académiques Excel ?
Comment traiter rapidement les données académiques Excel couvre des workflows Excel pratiques, pièges courants et modèles d'automatisation. Ce guide TabliSync explique le concept, montre des exemples et lie des tutoriels.
Comment TabliSync peut-il aider avec Comment traiter rapidement les données académiques Excel ?
TabliSync extrait des tableaux depuis captures ou PDF, nettoie des données désordonnées et automatise les tâches Excel liées à Comment traiter rapidement les données académiques Excel.
Par où commencer avec Comment traiter rapidement les données académiques Excel ?
Commencez par l'aperçu de cette page, puis ouvrez les articles ci-dessous pour des guides pas à pas et workflows IA.
Tous les Articles Données académiques Excel(6)

Comment calculer le nombre de jours entre deux dates
Dans ce guide, nous vous expliquerons comment calculer le nombre de jours entre deux dates à l'aide d'un tableur. Cette compétence cruciale peut aider dans divers scénarios professionnels, tels que la gestion de projet et la production de rapports financiers. Nous vous fournirons une approche claire, étape par étape, pour configurer votre tableur pour les calculs de dates, ainsi que des exemples pratiques illustrant les situations courantes où la compréhension des différences de dates est essentielle. De plus, nous partagerons des conseils pour garantir la précision, comme la gestion des années bissextiles et des problèmes de formatage. À la fin de cet article, vous aurez la confiance nécessaire pour effectuer des calculs de dates efficacement et explorer comment TabliSync peut aider à organiser vos données pour une efficacité encore plus grande.

Comment utiliser les fonctions SI et ET ensemble dans Excel
Cet article guide les utilisateurs dans le processus de combinaison des fonctions SI et ET dans Excel, les aidant à améliorer leur analyse de données et leurs rapports. Avec des instructions étape par étape et des exemples pratiques, les lecteurs amélioreront leurs compétences en tableur. En comprenant comment utiliser efficacement ces fonctions ensemble, les utilisateurs peuvent créer des tests logiques plus complexes qui sont essentiels pour des rapports précis et la prise de décision commerciale. Les cas d'utilisation courants sont explorés, ainsi que des conseils pour éviter les erreurs fréquentes. Que vous soyez un comptable, un membre d'une équipe financière ou un analyste de données, ce guide vous fournira les outils nécessaires pour améliorer votre maîtrise d'Excel et rationaliser votre flux de travail.

Comment créer un graphique circulaire avec des pourcentages dans Excel
Dans le monde actuel axé sur les données, la visualisation efficace des informations est cruciale pour le succès des entreprises. Cet article fournit un guide clair et pratique sur la création de graphiques circulaires dans Excel à l'aide de données en pourcentage. Que vous soyez un comptable travaillant sur des rapports financiers ou un analyste traduisant des données de ventes en formats visuels, les graphiques circulaires peuvent améliorer la compréhension et la présentation. Suivez les étapes décrites pour créer des graphiques circulaires qui reflètent fidèlement vos données, et découvrez des astuces de personnalisation pour améliorer la clarté et l'impact. De plus, apprenez comment TabliSync peut vous aider à préparer vos données pour ces représentations visuelles, rendant le processus plus fluide et plus efficace. À la fin de cet article, vous aurez les compétences nécessaires pour présenter vos données visuellement, vous assurant de communiquer efficacement les informations et de prendre des décisions éclairées basées sur des représentations précises.

Comment supprimer un saut de page dans Excel
Comprenez ce que sont les sauts de page et pourquoi ils sont importants dans Excel, suivez des instructions étape par étape pour les supprimer, et apprenez des astuces utiles pour gérer efficacement les sauts de page dans les feuilles de calcul.

Maîtriser l'intégrité des données : comment créer une liste déroulante dans Excel
Éliminez 99 % des erreurs de saisie manuelle des données en mettant en œuvre des protocoles standardisés de validation des données Excel. Réalisez une réduction de 90 % du temps de nettoyage des données grâce à l'utilisation de listes déroulantes dynamiques et de tableaux structurés. Exploitez l'OCR et TabliSync pilotés par l'IA pour transformer instantanément les données physiques non structurées en schémas Excel validés. Préparez vos feuilles de calcul pour l'avenir avec des architectures déroulantes évolutives et interrogeables pour des ensembles de données complexes.

Maîtriser le désordre : Comment supprimer les doublons dans Excel sans perte de données
Gains d'efficacité : Réduisez le temps de nettoyage manuel des données de plus de 90 % grâce à des flux de travail automatisés. Intégrité des données : Atteignez un taux d'erreur de saisie manuelle de 0 % en passant de la fonction "Rechercher et remplacer" à la déduplication basée sur un schéma. Atténuation des risques : Empêchez 100 % des suppressions accidentelles en utilisant des environnements Power Query non destructifs. Préparation pour l'avenir : Passez d'un nettoyage réactif à une hygiène des données proactive grâce à l'automatisation intégrée à l'IA.
Fini la saisie manuelle – Extrayez des tableaux en quelques secondes
Convertissez instantanément n'importe quelle image ou tableau PDF en Excel avec une précision de 99,9%. L'OCR IA de TabliSync traite les formulaires manuscrits, les reçus et les tableaux complexes, puis synchronise directement avec Google Sheets, Notion ou Airtable
Essayez TabliSync gratuitement maintenant