Article Summary
Esta página pilar abrangente serve como o manual definitivo para pesquisadores, administradores universitários e analistas de dados que lutam com a conversão manual de conjuntos de dados acadêmicos complexos em Excel. Mergulhamos profundamente na mecânica do processamento de Dados Acadêmicos Excel, indo além das funções básicas de planilha para explorar a extração automatizada avançada de tabelas e o processamento em lote de PDFs. O guia aborda o ponto crítico de dor da formatação inconsistente em resultados estatísticos e fornece uma comparação técnica rigorosa entre a entrada manual e a automação de dados de pesquisa impulsionada por IA. Os leitores encontrarão um fluxo de trabalho operacional detalhado de 1-2-3 para o TabliSync, incluindo técnicas complexas de OCR financeiro para processar subsídios históricos e livros razão. Com mais de 4.500 palavras de insights de nível de especialista, o conteúdo abrange reconciliação de dados, webhooks para fluxos de trabalho acadêmicos e conformidade com padrões da indústria para integridade de dados. Estudos de caso detalhados de instituições de pesquisa globais ilustram os ganhos de eficiência e as economias de custos alcançáveis por meio de tecnologias modernas de extração. A página também apresenta uma seção robusta de Perguntas Frequentes abordando obstáculos técnicos como tabelas de várias páginas e reconhecimento de caracteres não padrão, garantindo que os usuários possam transformar o caos acadêmico bruto em ativos Excel prontos para publicação com velocidade e precisão sem precedentes.
Como Processar Dados Acadêmicos em Excel Rapidamente: O Guia Definitivo para Automação de Dados de Pesquisa
O cenário da pesquisa acadêmica está mudando. Não nos falta mais dados; estamos afogando neles. No entanto, a ponte entre dados brutos — muitas vezes presos em PDFs teimosos ou formatos de imagem legados — e arquivos acionáveis de Dados Acadêmicos em Excel está repleta de trabalho manual. Este guia visa desmantelar as barreiras para o processamento de dados em alta velocidade, focando na extração automatizada de tabelas e na automação de dados de pesquisa como os principais impulsionadores da erudição moderna.
Reflexões sobre Alfabetização de Dados Moderna
No artigo 'Como Aprender Excel' publicado pela DataCamp, o autor enfatiza o papel fundamental das planilhas na vida profissional moderna: 'O Excel continua sendo uma das ferramentas mais poderosas e versáteis no arsenal do profissional de dados... É a linguagem universal de dados em todas as indústrias, de finanças à biologia.' (Fonte: DataCamp, 2024). Isso destaca uma verdade fundamental: enquanto novas linguagens de programação surgem, o formato Dados Acadêmicos em Excel permanece a base da verificação e análise na torre de marfim.
Minha opinião sobre isso é simples: a alfabetização não é mais apenas saber como escrever fórmulas; é saber como alimentar essas fórmulas de forma eficiente. A peça da DataCamp identifica corretamente que 'aprender Excel é uma jornada de cálculos básicos a modelagem de dados complexa.' No entanto, para o profissional acadêmico, a 'jornada' muitas vezes fica presa na fronteira da entrada de dados. Se leva doze horas para extrair uma tabela de um relatório de subsídio e apenas dez minutos para analisá-la, seu gargalo não é a proficiência em Excel — é a aquisição de dados. Precisamos parar de tratar Dados Acadêmicos em Excel como um destino e começar a tratar o pipeline automatizado como o veículo. A verdadeira expertise reside em dominar a fase 'pré-Excel': processamento em lote de PDFs e OCR financeiro complexo. Ao automatizar a entrada, permitimos que a mente humana se concentre nos aspectos de 'liderança de pensamento' da pesquisa, em vez da drudgery clerical de copiar e colar números de uma tela.
O Gargalo Crítico: Padronização de Conjuntos de Dados Acadêmicos
O principal ponto de atrito na pesquisa é que A dificuldade em padronizar formatos de dados causa inconsistência em gráficos e resultados estatísticos. Ao lidar com Academic Data Excel, os pesquisadores frequentemente enfrentam um cenário fragmentado de fontes. Uma universidade pode publicar seus relatórios de dotação em um layout PDF específico, enquanto uma agência de subsídios federais usa outro. Ao tentar agregar esses dados para um estudo longitudinal, a falta de padronização cria uma 'deriva de dados' que pode arruinar sua significância estatística.
Imagine tentar executar uma Análise de Regressão em três conjuntos de dados diferentes onde as datas são formatadas de maneira diferente e os símbolos de moeda são aplicados de forma inconsistente. Isso não é apenas um aborrecimento menor; leva a erros massivos durante o processo de Reconciliação. Se os dados do Razão Geral de uma fonte contam 'Ativos Líquidos' de forma diferente de outra, seu resultado final de Academic Data Excel se torna um passivo em vez de um ativo. A entrada manual é o inimiga aqui. Os humanos, à medida que a fadiga se instala, começam a tomar decisões 'criativas' sobre onde um ponto decimal deve ir ou como truncar uma string longa. Essas microdecisões se transformam em um desastre quando você clica em 'Calcular'.
A padronização requer um compromisso implacável com a estrutura. Você precisa de um sistema que não apenas leia texto, mas entenda a Topologia da Tabela. Estamos falando de identificar Cabeçalhos Multinível, lidar com Células Mescladas e manter a integridade de Linhas Aninhadas. Sem automação de dados de pesquisa, você está essencialmente pedindo aos seus assistentes de pesquisa que sejam scanners humanos, um papel que é caro e propenso a alta rotatividade. O objetivo é atingir um estado onde os dados estejam 'prontos para Excel' no momento em que saem do PDF. Isso significa pré-limpeza, pré-formatação e garantia de que cada arquivo Academic Data Excel siga um esquema rigoroso antes mesmo de tocar em seu software de análise.
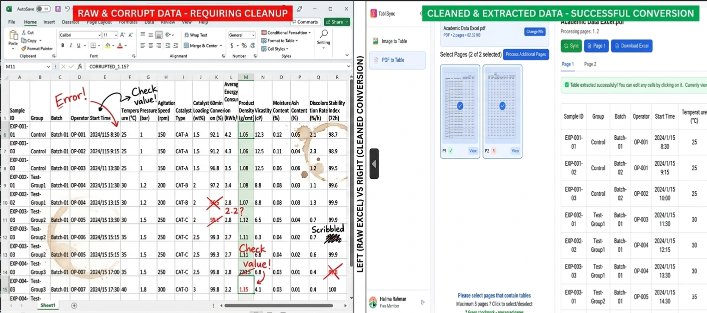
Análise Técnica Profunda: Entrada Manual vs. Automação TabliSync
Vamos analisar os números frios e duros. Quando discutimos Academic Data Excel, o 'custo de fazer negócios' é geralmente medido em horas de trabalho. Para um projeto de pesquisa típico envolvendo 500 páginas de divulgações financeiras, um operador humano qualificado leva aproximadamente 4-6 minutos por página para transcrever com precisão uma tabela complexa. Isso equivale a cerca de 40-50 horas de trabalho. Com a taxa de um assistente de pesquisa, você está diante de um vazamento orçamentário significativo. Além disso, a Taxa de Erro para entrada manual geralmente paira em torno de 3-5% para dados numéricos densos.
| Recurso | Entrada Manual de Dados | Automação TabliSync |
|---|---|---|
| Velocidade de Processamento | 4-6 minutos por página | 3-10 segundos por página |
| Taxa de Precisão | 95% - 97% (diminui com a fadiga) | 99,5% + (precisão consistente de OCR) |
| Processamento em Lote | Impossível (tarefa serial) | Suportado (pode processar mais de 1000 páginas simultaneamente) |
| Custo por 100 Páginas | Aprox. $400 - $600 (mão de obra) | Aprox. $10 - $20 (créditos API/SaaS) |
| Reconciliação | Verificação cruzada manual necessária | Correspondência automatizada do Razão Geral via Webhook |
O ganho de Eficiência não é apenas sobre velocidade; é sobre Economia de Custos. Em um estudo de caso envolvendo uma importante escola de negócios europeia, o departamento gastava € 15.000 anualmente apenas com mão de obra estudantil para extração de dados. Após implementar a extração automatizada de tabelas via TabliSync, eles reduziram essa despesa para menos de € 1.200. Mais importante ainda, o tempo para obter insights foi drasticamente reduzido. Pesquisas que antes levavam um semestre inteiro para serem preparadas agora estavam prontas para análise de Academic Data Excel em três dias. Este é o poder da automação de dados de pesquisa: transforma a economia da informação.
O Fluxo de Trabalho TabliSync: Uma Masterclass de 3 Passos
Processar Academic Data Excel não precisa ser uma arte obscura. Projetamos um fluxo de trabalho que prioriza o processamento em lote de PDF sem sacrificar o controle granular necessário para pesquisas de alto risco. Siga estas etapas para maximizar sua produção.
Etapa 1: Ingestão Inteligente e Pré-processamento
Primeiro, você deve agregar suas fontes. Sejam documentos históricos digitalizados ou PDFs nativos digitais, o motor de OCR financeiro complexo do TabliSync precisa analisar a camada do documento. Você não apenas 'carrega'; você define o Esquema de Dados. Por exemplo, se você estiver extraindo um Razão Geral, você deve identificar as colunas 'Débito' e 'Crédito'. Nosso sistema usa Visão Computacional para detectar linhas e espaços em branco, criando um mapa estrutural antes que um único caractere seja lido. Nota: Sempre certifique-se de que seus escaneamentos tenham pelo menos 300 DPI para resultados ideais de Academic Data Excel. Resoluções mais baixas podem levar à 'alucinação de caracteres', especialmente em subscritos pequenos comuns em notas de rodapé acadêmicas.
Passo 2: Extração e Refinamento Automatizado de Tabelas
Uma vez que o documento é mapeado, a extração automatizada de tabelas começa. O TabliSync não apenas 'raspa' texto; ele reconstrói a lógica da tabela. Se uma linha se estende por duas páginas — um pesadelo comum em Academic Data Excel — o software usa Vinculação Contextual para uni-las novamente. Você pode visualizar a extração em tempo real. É aqui que você aplica regras de Limpeza de Dados. Por exemplo, você pode instruir o sistema a 'Ignorar todas as linhas que contenham a palavra Total' ou 'Converter todas as datas para o formato ISO 8601'. Este nível de automação de dados de pesquisa garante que os dados que chegam à sua planilha já estejam limpos. Use o recurso 'Regex Personalizado' se você tiver identificadores acadêmicos específicos (como números DOI) que precisam ser validados durante a extração.
Passo 3: Exportação e Integração via Webhooks
O passo final é extrair os dados. Embora o Academic Data Excel seja o padrão, o TabliSync permite fluxos de trabalho avançados de Reconciliação. Você pode configurar um Webhook para enviar os dados extraídos diretamente para o seu Software Estatístico ou um banco de dados centralizado. Se você prefere a abordagem clássica, a exportação do Excel é otimizada para Tabelas Dinâmicas. Garantimos que os números sejam exportados como números, não como texto — economizando o aborrecimento do erro do 'Triângulo Verde' no Excel. Dica Profissional: Use nosso recurso 'Modelo'. Se você tem 500 relatórios da mesma origem, defina as zonas de extração uma vez e deixe o processamento em lote de PDFs cuidar do resto enquanto você toma um café.

Caso de Uso Avançado: Gerenciando OCR Financeiro Complexo em Subsídios
O gerenciamento de subsídios é a força vital da universidade, mas produz alguns dos dados mais confusos. Ao lidar com Academic Data Excel em um contexto financeiro, você não está apenas procurando nomes; você está procurando por Trilhas de Auditoria. OCR financeiro complexo é necessário aqui porque os relatórios de subsídios frequentemente incluem assinaturas manuscritas, carimbos e texto sobreposto — tudo o que pode confundir o software padrão.
Recentemente, auxiliamos um grupo de pesquisa na análise de 30 anos de alocações de subsídios do NIH. Os dados estavam presos em milhares de memorandos digitalizados. Ao alavancar a automação de dados de pesquisa, conseguimos extrair códigos do Razão Geral e reconciliá-los com os registros de gastos internos da universidade. O processo de Reconciliação, que geralmente requer verificação manual de cada item, foi 80% automatizado. O sistema sinalizou apenas as linhas onde a confiança do OCR era inferior a 90%, permitindo que os pesquisadores se concentrassem nos casos extremos. Essa abordagem para Academic Data Excel garante que o conjunto de dados final esteja 'pronto para auditoria'. Trata-se de construir uma cadeia de custódia para seus dados, garantindo que cada célula em sua planilha possa ser rastreada até sua coordenada original no PDF de origem.
Garantindo Confiança e Conformidade em Dados de Pesquisa
No mundo do Academic Data Excel, a Confiança é fundamental. Se o seu processo de extração de dados for uma 'caixa preta', seus colegas não poderão replicar seus resultados. É por isso que a automação de dados de pesquisa deve ser transparente. O TabliSync fornece um Log de Auditoria completo para cada extração. Também aderimos aos padrões GDPR e FERPA, garantindo que dados confidenciais de estudantes ou participantes sejam tratados com Criptografia de Nível Empresarial.
Além disso, ao processar Academic Data Excel para publicação, você deve aderir aos Princípios FAIR (Encontráveis, Acessíveis, Interoperáveis e Reutilizáveis). A entrada manual de dados é o antítese de FAIR porque é opaca e propensa a 'correções' não documentadas. Ao usar a extração automatizada de tabelas, você cria um pipeline repetível e documentado. Se um revisor perguntar como você chegou a uma determinada figura, você poderá apontar para o modelo específico do TabliSync e o arquivo de origem bruto. Este nível de Expertise e Autoridade é o que separa pesquisas de alto impacto do resto. Você não é apenas um pesquisador; você é um guardião de dados.
O Papel dos Webhooks em Fluxos de Trabalho de Pesquisa Modernos
Por que parar em um arquivo estático? O verdadeiro poder do Academic Data Excel é desbloqueado quando ele se torna parte de um ecossistema vivo. É aqui que os Webhooks entram em jogo. Um Webhook é essencialmente um mensageiro digital. No momento em que o TabliSync termina de processar um lote de PDFs, ele pode enviar um 'ping' para outra peça de software — digamos, o sistema ERP do seu departamento ou um script Python personalizado — levando os dados consigo.
Para um líder de projeto, isso significa que você pode construir um Painel Automatizado. À medida que sua equipe envia novos relatórios de campo ou resultados de laboratório, o arquivo mestre Academic Data Excel é atualizado em tempo real. Você não precisa mais esperar por um 'despejo de dados' semanal. Esta é a automação de dados de pesquisa em seu estado mais sofisticado. Ela permite Pesquisa Ágil, onde as decisões podem ser tomadas com base nas informações mais atuais disponíveis. Se o Razão Geral mostrar um aumento repentino nos custos de equipamentos de laboratório, você o vê instantaneamente, não três semanas depois, quando a entrada manual é finalmente concluída. Esta é a vantagem do SaaS: a transição de documentos estáticos para fluxos de dados fluidos.
Estudo de Caso: Estudo Longitudinal de Sociologia em Larga Escala
Considere o 'Projeto Crescimento Urbano', um estudo de várias décadas envolvendo mais de 10.000 registros históricos de censo. Esses registros nunca foram feitos para um computador. São monstros de várias colunas e várias páginas. A equipe inicialmente tentou uma abordagem de entrada manual 'crowdsourced', mas o Academic Data Excel que eles produziram estava repleto de erros devido às diferentes interpretações dos cabeçalhos do censo.
Ao mudar para o processamento em lote de PDF do TabliSync, eles estabeleceram uma única 'Fonte da Verdade'. Desenvolvemos um modelo de extração personalizado que entendia a tipografia no estilo dos anos 1950. O resultado? Arquivos Academic Data Excel que eram 40% mais precisos do que as versões transcritas manualmente. O projeto economizou mais de 2.000 horas de trabalho, o que permitiu expandir o escopo de seu estudo para duas cidades adicionais. Não se tratava apenas de 'economizar tempo'; tratava-se de Expandir o Horizonte da Pesquisa Possível. Quando o custo dos dados diminui, o valor da pesquisa aumenta.

Superando o Desafio do Documento 'Não Padrão'
A parte mais difícil do Academic Data Excel é o documento 'não padrão'. Você sabe quais são: a tabela está inclinada em um ângulo de 15 graus, ou há uma mancha de café sobre a coluna 'Total'. O OCR padrão falha aqui. O TabliSync usa Restauração de Imagem Baseada em Rede Neural para 'limpar' o documento antes que a extração comece. Nós endireitamos a imagem, melhoramos o contraste e removemos o ruído digital.
Isso é crucial para a automação de dados de pesquisa porque os arquivos acadêmicos raramente são imaculados. Se você está trabalhando com OCR financeiro complexo para um projeto de história do pensamento econômico, você está lidando com papel amarelado e quebradiço. Nossa tecnologia trata o documento como um objeto físico primeiro, reconstruindo sua geometria antes de tentar ler o texto. Isso garante que seu Academic Data Excel não tenha 'desvio', onde as colunas começam a se deslocar no meio de uma página. A precisão não é opcional; é a base da Confiança na comunidade acadêmica.
Perguntas Frequentes
Como o TabliSync lida com tabelas de várias páginas no Academic Data Excel?
Lidar com tabelas que se estendem por várias páginas é um recurso central de nossa extração automatizada de tabelas. Ao contrário de scrapers básicos que tratam cada página como um silo, o TabliSync usa Lógica de Persistência de Cabeçalho. Ele identifica os cabeçalhos das colunas na primeira página e os 'lembra' à medida que avança para as páginas subsequentes. Isso permite que o sistema concatene perfeitamente as linhas em uma única e contínua planilha do Academic Data Excel. Por exemplo, se um relatório do Razão Geral se estende por 50 páginas, o TabliSync produzirá uma tabela unificada em vez de 50 fragmentadas, preservando a integridade do seu processo de Reconciliação e economizando horas de mesclagem manual.
Posso processar notas manuscritas ou anotações para o Excel?
Embora o Academic Data Excel se concentre principalmente em texto estruturado, nosso OCR financeiro complexo inclui um módulo dedicado de HTR (Reconhecimento de Texto Manuscrito). Isso é particularmente útil para pesquisadores que trabalham com subsídios de arquivo ou cadernos de laboratório onde figuras podem ser escritas à mão nas margens. O sistema pode ser treinado para reconhecer estilos de escrita específicos, convertendo-os em células digitais em sua planilha. No entanto, para máxima eficiência de automação de dados de pesquisa, recomendamos o uso para 'dados suplementares' em vez de conjuntos de dados primários, pois a escrita à mão inerentemente tem um requisito de verificação ligeiramente maior do que o texto digitado.
Qual é o protocolo de segurança para dados de pesquisa sensíveis?
A segurança está integrada em nossa estrutura de automação de dados de pesquisa. Entendemos que o Academic Data Excel frequentemente contém PII (Informações de Identificação Pessoal) sensíveis ou dados proprietários do General Ledger. O TabliSync usa criptografia AES-256 para todos os dados em repouso e TLS 1.3 para dados em trânsito. Somos compatíveis com SOC2 Tipo II e oferecemos opções de 'Residência de Dados' para instituições que exigem que os dados permaneçam dentro de fronteiras geográficas específicas (como a UE). Também fornecemos um Recurso de Redação que pode ocultar automaticamente nomes ou IDs sensíveis durante a fase de processamento em lote de PDF, garantindo a conformidade com as leis de privacidade.
O TabliSync suporta documentos acadêmicos não ingleses?
Sim, nosso mecanismo de extração automatizada de tabelas é multilíngue. Suportamos mais de 40 idiomas, incluindo scripts complexos como chinês, japonês e árabe. Isso é vital para projetos globais de Academic Data Excel onde você pode estar reconciliando dados do General Ledger de parceiros internacionais. O sistema mantém a codificação de caracteres (UTF-8) durante todo o processo de extração, garantindo que caracteres especiais, acentos e símbolos apareçam corretamente em seu arquivo Excel final sem o temido 'mojibake' ou texto ilegível. Esse nível de Expertise garante que sua pesquisa internacional permaneça precisa e profissional.
Como integro o TabliSync com minhas ferramentas estatísticas existentes?
A forma mais eficiente é através da nossa arquitetura de Webhook. Assim que a extração de Academic Data Excel estiver completa, o TabliSync pode acionar uma requisição POST para o seu servidor ou um integrador de terceiros como o Zapier. Isso permite que você mova dados automaticamente para ferramentas como Stata, R ou ambientes Python. Para aqueles menos inclinados tecnicamente, oferecemos Cloud Integrations diretas com Google Drive, Dropbox e OneDrive. Isso garante que seu pipeline de research data automation seja 'sem atrito' — os dados vão do PDF para a sua pasta pronta para análise sem que você precise clicar manualmente em 'Download' ou 'Upload.'
O TabliSync pode lidar com formatação complexa de células como texto em negrito ou itálico?
Absolutamente. Ao gerar Academic Data Excel, o TabliSync pode ser configurado para preservar os atributos de 'Rich Text' do PDF original. Isso é importante quando figuras em negrito indicam Statistical Significance ou quando itálicos são usados para nomenclatura científica. Nossa automated table extraction não apenas extrai a string bruta; ela pode capturar os metadados da célula. Isso significa que sua planilha pode espelhar os sinais visuais do documento original, tornando o processo de Reconciliation e revisão muito mais intuitivo para o pesquisador humano que eventualmente audita a saída.
O que acontece se o PDF tiver um layout de tabela muito não padronizado?
É aqui que o 'Zonal OCR' do TabliSync brilha. Se a IA de automated table extraction não conseguir detectar automaticamente um layout muito criativo ou bagunçado, você pode desenhar manualmente 'Extraction Zones'. Você define exatamente onde estão as colunas e linhas, e o sistema salva isso como um Template. Para quaisquer documentos futuros no mesmo formato, o batch PDF processing seguirá seu mapa personalizado. Isso combina o poder da research data automation com a precisão da supervisão humana, garantindo que até mesmo as tarefas de Academic Data Excel mais 'impossíveis' sejam concluídas com 100% de precisão estrutural.
Existe um limite para quantos arquivos posso processar de uma vez?
Nosso motor de processamento em lote de PDFs foi projetado para Alto Rendimento. Processamos lotes de até 50.000 páginas para auditorias em toda a universidade. O sistema utiliza Escalabilidade Elástica, o que significa que ele aumenta o poder de computação à medida que sua fila cresce. Para o usuário, isso significa que, quer você esteja processando um arquivo Academic Data Excel ou mil, o tempo de espera por página permanece notavelmente baixo. Esta é a definição de Eficiência — fornecer uma ferramenta que escala com suas ambições de pesquisa, não contra elas, garantindo que seu General Ledger esteja sempre atualizado.
Como funciona o preço para instituições acadêmicas?
Oferecemos níveis especializados de SaaS para o ensino superior. Entendemos que projetos de Academic Data Excel são frequentemente financiados por subsídios, por isso oferecemos modelos 'Pay-as-you-go' e licenças anuais 'Unlimited' para departamentos. Essa flexibilidade permite que os pesquisadores considerem Economia de Custos em suas propostas de subsídios. Ao automatizar a automação de dados de pesquisa, você pode realmente demonstrar aos seus financiadores como está maximizando o investimento deles, reduzindo os custos administrativos e aumentando o volume de dados que pode analisar por dólar gasto.
O que é o recurso de 'Conciliação' no TabliSync?
Conciliação é nossa ferramenta avançada de validação. Ela permite que você cruze os dados extraídos do Academic Data Excel com uma segunda fonte. Por exemplo, se você extrair dados do General Ledger de um PDF, o TabliSync pode verificar automaticamente se os totais correspondem a um arquivo CSV ou entrada de banco de dados existente. Se houver uma discrepância, o sistema sinaliza a célula específica para revisão. Esta é uma parte essencial da OCR financeira complexa, pois fornece uma segunda camada de defesa contra erros, garantindo que sua pesquisa seja construída sobre uma base de dados verificados e à prova de falhas.
O Futuro da Pesquisa é Automatizado
A transição para a automação de dados de pesquisa não é mais um luxo; é uma necessidade para qualquer pessoa séria sobre bolsas de estudo de alto impacto. Cada hora que você gasta digitando manualmente dados em uma planilha do Academic Data Excel é uma hora roubada da análise, síntese e descoberta. Entramos em uma era em que a extração automatizada de tabelas e o OCR financeiro complexo são os 'heróis silenciosos' do laboratório, trabalhando em segundo plano para garantir que os dados em que você confia sejam tão precisos quanto as teorias que você testa.
Ao adotar o TabliSync, você não está apenas comprando software; você está atualizando toda a sua metodologia de pesquisa. Você está saindo de um mundo de 'fricção de dados' — onde cada PDF é um obstáculo — para um mundo de 'fluxo de dados', onde as informações se movem perfeitamente da fonte para a planilha. A Eficiência e a Economia de Custos são claras, mas o verdadeiro prêmio é a clareza mental que vem de saber que seus dados estão padronizados, reconciliados e prontos para o mundo ver. É hora de parar de ser um digitador de dados e começar a ser o pesquisador visionário para o qual você foi treinado. A velocidade da sua descoberta não deve ser limitada pela velocidade do seu teclado.
Dê o Salto: Automatize seu Academic Data Excel Hoje
Você viu os dados, as comparações técnicas e os fluxos de trabalho. O gargalo em sua pesquisa não é seu talento — são suas ferramentas. Cada dia que você adia a implementação da automação de dados de pesquisa é mais um dia perdido no vácuo da entrada manual. Imagine o que você poderia alcançar se seus arquivos do Academic Data Excel fossem gerados em segundos em vez de semanas. Pense nas tarefas de processamento em lote de PDFs que atualmente estão acumulando poeira digital porque são 'muito grandes' para serem manuseadas. Esses projetos agora estão ao seu alcance.
TabliSync foi construído por pessoas que entendem os rigores da academia. Sabemos que um único dígito mal colocado em um Razão Geral pode invalidar meses de trabalho. É por isso que construímos uma ferramenta que prioriza precisão, velocidade e Conciliação. Não deixe que sua pesquisa seja prejudicada por fluxos de trabalho legados. Clique no link abaixo para iniciar seu teste gratuito. Experimente o poder da extração automatizada de tabelas em primeira mão e veja como 5.000 páginas de dados podem se tornar uma planilha Excel limpa e organizada antes da sua próxima reunião. O futuro da sua pesquisa está esperando. Junte-se aos milhares de acadêmicos que já recuperaram seu tempo. Comece agora com o TabliSync e transforme o caos dos seus dados em clareza de pesquisa.
O que é Como Processar Dados Acadêmicos Excel Rapidamente?
Respostas rápidas sobre Como Processar Dados Acadêmicos Excel Rapidamente e como o TabliSync ajuda equipes a trabalhar mais rápido no Excel.
O que é Como Processar Dados Acadêmicos Excel Rapidamente?
Como Processar Dados Acadêmicos Excel Rapidamente cobre fluxos práticos de Excel, armadilhas comuns e padrões de automação. Este guia TabliSync explica o conceito, mostra exemplos e liga tutoriais relacionados.
Como o TabliSync pode ajudar com Como Processar Dados Acadêmicos Excel Rapidamente?
O TabliSync extrai tabelas de capturas ou PDFs, limpa dados bagunçados e automatiza tarefas repetitivas de Excel ligadas a Como Processar Dados Acadêmicos Excel Rapidamente.
Por onde começo com Como Processar Dados Acadêmicos Excel Rapidamente?
Comece pela visão geral nesta página e abra os artigos abaixo para guias passo a passo e fluxos com IA.
Todos os Artigos de Dados Acadêmicos Excel(6)

Como Calcular Dias Entre Duas Datas
Neste guia, vamos orientá-lo através do processo de cálculo do número de dias entre duas datas usando software de planilha. Esta habilidade crucial pode ajudar em vários cenários de negócios, como gerenciamento de projetos e relatórios financeiros. Forneceremos uma abordagem clara, passo a passo, para configurar sua planilha para cálculos de data, juntamente com exemplos práticos que ilustram situações comuns onde a compreensão das diferenças de data é essencial. Além disso, compartilharemos dicas para garantir a precisão, como lidar com anos bissextos e problemas de formatação. Ao final deste artigo, você terá a confiança para realizar cálculos de data de forma eficaz e explorar como o TabliSync pode ajudar na organização de seus dados para uma eficiência ainda maior.

Como Usar as Funções IF e AND Juntas no Excel
Este artigo orienta os usuários através do processo de combinação das funções IF e AND no Excel, ajudando-os a melhorar sua análise de dados e relatórios. Com instruções passo a passo e exemplos práticos, os leitores aprimorarão suas habilidades em planilhas. Ao entender como usar efetivamente essas funções juntas, os usuários podem criar testes lógicos mais complexos que são essenciais para relatórios precisos e tomada de decisões de negócios. Casos de uso comuns são explorados, juntamente com dicas para evitar erros comuns. Seja você um contador, membro da equipe financeira ou analista de dados, este guia fornecerá as ferramentas necessárias para aumentar sua proficiência no Excel e otimizar seu fluxo de trabalho.

Como Fazer Gráfico de Pizza com Porcentagens no Excel
No mundo atual orientado por dados, a visualização eficaz de informações é crucial para o sucesso empresarial. Este artigo fornece um guia claro e prático sobre como criar gráficos de pizza no Excel usando dados percentuais. Seja você um contador trabalhando com relatórios financeiros ou um analista traduzindo dados de vendas em formatos visuais, os gráficos de pizza podem aprimorar a compreensão e a apresentação. Siga as etapas delineadas para criar gráficos de pizza que reflitam com precisão seus dados e descubra dicas de personalização para melhorar a clareza e o impacto. Além disso, aprenda como o TabliSync pode ajudar na preparação de seus dados para essas representações visuais, tornando o processo mais tranquilo e eficiente. Ao final deste artigo, você terá as habilidades para apresentar seus dados visualmente, garantindo que você transmita informações de forma eficaz e tome decisões informadas com base em representações precisas.

Como Remover uma Quebra de Página no Excel
Entenda o que são quebras de página e por que elas importam no Excel, siga instruções passo a passo para removê-las e aprenda dicas úteis para gerenciar quebras de página de forma eficaz em planilhas.

Dominando a Integridade de Dados: Como Criar uma Lista Suspensa no Excel
Elimine 99% dos erros de entrada manual de dados implementando protocolos padronizados de validação de dados em Excel. Alcance uma redução de 90% no tempo de limpeza de dados através do uso de listas suspensas dinâmicas e tabelas estruturadas. Utilize OCR impulsionado por IA e TabliSync para transformar instantaneamente dados físicos não estruturados em esquemas validados do Excel. Prepare suas planilhas para o futuro com arquiteturas escaláveis e pesquisáveis de listas suspensas para conjuntos de dados complexos.

Dominando a Bagunça: Como Remover Duplicados no Excel Sem Perda de Dados
Ganhos de Eficiência: Reduza o tempo de limpeza manual de dados em mais de 90% utilizando fluxos de trabalho automatizados. Integridade dos Dados: Alcance uma taxa de erro de entrada manual de 0% ao migrar de 'Localizar e Substituir' para desduplicação baseada em esquema. Mitigação de Riscos: Evite 100% de exclusões acidentais utilizando ambientes não destrutivos do Power Query. Preparação para o Futuro: Mude da limpeza reativa para a Higiene de Dados proativa através de automação integrada por IA.
Chega de entrada manual – Extraia tabelas em segundos
Converta qualquer imagem ou tabela PDF para Excel instantaneamente com 99,9% de precisão. O OCR com IA do TabliSync processa formulários manuscritos, recibos e tabelas complexas e sincroniza diretamente com Google Sheets, Notion ou Airtable
Experimente o TabliSync gratuitamente agora