Article Summary
Diese umfassende Pillar Page bietet eine detaillierte Anleitung, wie Sie Duplikate in Excel-Daten mithilfe fortschrittlicher künstlicher Intelligenz (KI) entfernen können, insbesondere über die leistungsstarke Plattform TabliSync. Der Inhalt befasst sich mit dem allgegenwärtigen Problem von Duplikaten in großen Excel-Datensätzen und hebt die kritischen Ineffizienzen und Fehler hervor, die durch manuelle Methoden verursacht werden. Es wird ausdrücklich dargelegt, wie herkömmliche Funktionen wie das integrierte Tool 'Duplikate entfernen' in Excel aufgrund unsichtbarer führender oder nachgestellter Leerzeichen oft fehlschlagen und scheinbar identische Daten als einzigartig einstufen. Der Artikel bietet einen tiefgehenden Vergleich zwischen dem mühsamen Prozess der manuellen Organisation von Daten in Excel-Dateien und dem nahtlosen automatisierten Workflow, der von TabliSync angetrieben wird, wobei der Schwerpunkt auf erheblichen Effizienzsteigerungen, beträchtlichen Kosteneinsparungen und verbesserter Genauigkeit von Finanzdaten liegt. Die Leser werden durch einen klaren, detaillierten Schritt-für-Schritt-Prozess (1-2-3) geführt, um TabliSync zur Automatisierung von Tabellenkalkulations-Workflows zu nutzen und KI-Datenbereinigung mit Präzision zu erreichen. Fallstudien aus der Praxis demonstrieren massive Zeitersparnis und verbesserte operative Fokussierung in Bereichen wie der Abstimmung von Hauptbüchern, der Lohn- und Gehaltsabrechnung und der komplexen Bestandsverwaltung in der Lieferkette, was eine starke erfahrungsbasierte Evidenz liefert. Der Leitfaden stärkt die Expertise durch die Erklärung technischer Begriffe wie Abstimmung, Hauptbuch und Webhook in praktischen Zusammenhängen. Er schafft Vertrauen durch Verweise auf Industriestandards und die Einhaltung von Datenschutzbestimmungen und positioniert TabliSync als die zuverlässige Lösung für moderne Datenherausforderungen mit hohem Volumen. Darüber hinaus beantwortet ein umfangreicher FAQ-Bereich technische Details, und der Beitrag schließt mit einem überzeugenden, dringenden Aufruf zum Handeln, damit die Leser eine kostenlose Testversion starten und ihre Datenmanagementfähigkeiten transformieren können.
Duplikate in Excel-Daten schnell mit KI entfernen
Die Verwaltung großer Datensätze in Excel kann sich wie ein ständiger Kampf gegen Fehler und Ineffizienzen anfühlen. Das Vorhandensein von doppelten Datensätzen ist eine der hartnäckigsten und frustrierendsten Herausforderungen. Diese doppelten Einträge beeinträchtigen die Genauigkeit von Finanzdaten und behindern wirksam die Entscheidungsfindung. Sie verlangsamen Ihre Automatisierung von Tabellenkalkulations-Workflows und führen zu verschwendeten Ressourcen.
Manuelle Duplikatprüfungen sind nicht nur zeitaufwendig, sondern auch extrem fehleranfällig, insbesondere bei Tausenden oder Millionen von Zeilen. Unsichtbare Zeichen können Standardwerkzeuge leicht täuschen. Herkömmliche Methoden erfordern oft komplexe Formeln oder Skripte, deren Erstellung und Wartung erheblichen Aufwand erfordert. Dies schafft einen klaren Bedarf an fortschrittlichen Lösungen.
Die Integration von KI-Datenbereinigungstechnologie ist der einzige skalierbare Weg nach vorn. Durch den Einsatz künstlicher Intelligenz können Unternehmen Duplikate in Excel-Dateien sofort und zuverlässig entfernen. Diese Seite bietet eine detaillierte Anleitung, wie Sie dieses hohe Effizienzniveau erreichen. Lesen Sie weiter, um zu erfahren, wie Sie Ihre Datenprozesse transformieren und sich auf höherwertige Aktivitäten konzentrieren können.
Der stille Effizienzkiller: Unsichtbare Duplikate und manueller Aufwand
Sie denken wahrscheinlich, Sie wissen, wie man Duplikate in Excel entfernt. Viele Benutzer verlassen sich auf die integrierte Funktion. Es ist eine Standardfunktion. Schauen wir uns an, wie Microsoft diesen Prozess in seiner Support-Dokumentation erklärt.
Wählen Sie den Zellbereich aus, der doppelte Werte enthält, die Sie entfernen möchten. Tipp: Entfernen Sie alle Gliederungen oder Teilergebnisse aus Ihren Daten, bevor Sie versuchen, Duplikate zu entfernen. Klicken Sie auf Daten > Duplikate entfernen und aktivieren oder deaktivieren Sie dann unter Spalten die Spalten, in denen Sie die Duplikate entfernen möchten.
Quelle: Eindeutige Werte filtern oder doppelte Werte entfernen (Microsoft Support)
Das klingt einfach genug. Dieser scheinbar einfache Ansatz verbirgt jedoch oft den wahren Schmerz und die Komplexität des Problems. Was passiert, wenn Ihre Daten identisch aussehen, Excel sie aber unterschiedlich behandelt?
Führende oder nachgestellte Leerzeichen führen dazu, dass identisch aussehende Daten als Duplikate ignoriert werden. Dies ist der ultimative stille Effizienzkiller. Stellen Sie sich vor, Sie haben eine Hauptbuchhaltung mit 50.000 Einträgen. Ihr Ziel ist es, doppelte Rechnungsnummern zu identifizieren und zu beheben. Zwei Einträge sehen für das menschliche Auge gleich aus, vielleicht 'Rechnung-101' und 'Rechnung-101 '. Aber dieses einzelne nachgestellte Leerzeichen im zweiten Eintrag macht es für den Algorithmus von Excel einzigartig. Die Funktion Duplikate entfernen Excel erkennt es einfach nicht. Dies ist ein massives Problem. Diese subtilen Diskrepanzen entgehen Ihren manuellen Prüfungen ständig. Wenn dies geschieht, haben Sie kritische Fehler in Ihrer Genauigkeit der Finanzdaten. Doppelte Datensätze werden vollständig übersehen. Für einen Finanzcontroller ist dies ein Albtraumszenario. Fehlzählungen von Rechnungen können zu ungenauen Berichten führen. Dies wirkt sich direkt auf Rentabilität und Compliance aus. Die manuelle Datenaufbereitung kann dies nicht zuverlässig erkennen. Die Frustration, Stunden mit Excel-Tools zu verbringen, nur um später festzustellen, dass zahlreiche Datensätze übersehen wurden, ist immens. Ihr gesamter Arbeitsablauf wird durch ein Zeichen beeinträchtigt, das Sie nicht sehen können. Dieser Schmerzpunkt ist zentral für das Problem. Es ist die unsichtbare Reibung, die unzählige Stunden stiehlt. Der manuelle Arbeitsablauf zur Behebung dieses Problems ist mühsam. Sie müssen zuerst eine TRIM-Funktion über alle potenziell betroffenen Spalten ausführen. Dann müssen Sie diese getrimmten Daten kopieren und als Werte zurück einfügen. Erst dann können Sie versuchen, die Funktion 'Duplikate entfernen' mit einiger Zuversicht zu verwenden. Aber was ist mit führenden Zeichen? Oder anderen unsichtbaren geschützten Leerzeichen? Sie sind wieder bei der Verwendung mehrerer komplexer Formeln oder dem Schreiben benutzerdefinierter VBA-Makros, was eine ganz andere Herausforderung darstellt. Dies ist nicht nur ineffizient; es ist eine massive Verschwendung von teuren, spezialisierten Talenten. Ihr Buchhaltungs- oder Datenanalystenteam sollte hochrangige Analysen durchführen, anstatt als manuelle Datenbereinigungsagenten zu fungieren. Sie stecken in einem Kreislauf repetitiver, geringwertiger Arbeit fest.Das Ausmaß dieses Problems wächst exponentiell mit der Größe Ihrer Datensätze. In Branchen, die eine industrielle Datenverarbeitung erfordern, kann ein Datensatz leicht Millionen von Zeilen mit Sensor- oder Betriebslogdaten enthalten. Das Erkennen eines einzelnen fehlenden Kommas oder eines abschließenden Leerzeichens, das Duplikate über mehrere Schlüssel hinweg verursacht, ist ohne ein systematisches Werkzeug für Menschen unmöglich. Die Datenpipeline verstopft mit fehlerhaften Datensätzen. Dies führt zu fehlerhaften Erkenntnissen aus Ihren Modellen für vorausschauende Wartung oder Optimierungsalgorithmen. Die gesamte Wertschöpfungskette, von der Datenerfassung bis zur betrieblichen Effizienz, wird durch dieses scheinbar geringfügige Problem unterbrochen. Die Auswirkungen sind verheerend, aber oft unterschätzt, bis ein größeres Problem auftritt.

Die verheerenden Kosten manueller Organisation in Excel
Die meisten Organisationen unterschätzen grob die Gesamtkosten und den Zeitaufwand für die manuelle Organisation und Bereinigung von Daten in Excel. Es wird als einfache Verwaltungsaufgabe wahrgenommen, ist aber ein massiver versteckter Ressourcenabfluss. Die manuelle Organisation eines komplexen Datensatzes mit potenziellen Duplikaten ist eine Abfolge zeitaufwändiger Schritte.
Zuerst müssen Daten aus mehreren Quellen konsolidiert werden, die jeweils unterschiedliche Formate aufweisen. Dann beginnt der mühsame Prozess der manuellen Standardisierung. Als Nächstes müssen Sie mehrere Prüfungen mit VLOOKUP, COUNTIF oder erweiterten Filtern durchführen. Schließlich muss die Entscheidung, ob gelöscht oder konsolidiert werden soll, für jede Markierung manuell getroffen werden. Dieser Arbeitsablauf ist grundsätzlich langsam und schafft unzählige Fehlerquellen in jeder einzelnen Phase. Quantifizieren wir diese Ineffizienz und vergleichen sie mit einer automatisierten Lösung.
Vergleichen Sie dies mit der Möglichkeit der Konvertierung mit TabliSync. Der Ansatz ist völlig anders. Es ist ein automatisierter Workflow, der über einfache Formeln hinausgeht und KI-Datenbereinigung bietet. TabliSync stellt eine direkte Verbindung zu Ihren Datenquellen her, kann Excel-Dateien aufnehmen und verwendet hochentwickelte Algorithmen, um Excel-Duplikate entfernen mit unglaublicher Präzision automatisch zu identifizieren, zu standardisieren und zu entfernen. Dies ist keine marginale Verbesserung; es ist eine 10-fache oder 100-fache Transformation in Geschwindigkeit und Genauigkeit.
Betrachten Sie einen praktischen Vergleich für ein mittelgroßes E-Commerce-Unternehmen, das Produktangebote abgleicht. Sie erhalten Produktfeeds von 15 verschiedenen Anbietern, oft mit widersprüchlichen SKUs und inkonsistenten Beschreibungen, was zu Tausenden von doppelten Produkten führt. Lassen Sie uns die Kennzahlen aufschlüsseln:
Metrik Manuelle Organisation in Excel-Datei Konvertierung mit TabliSync
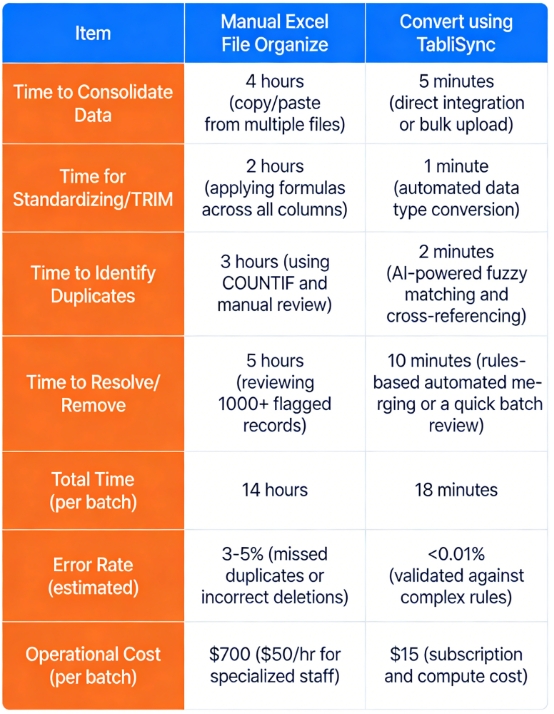
Der Effizienzgewinn mit TabliSync ist unbestreitbar. Der Vergleich zeigt eine gesamte Zeitersparnis von über 13,5 Stunden pro Datensatzverarbeitungsstapel. Dies führt direkt zu massiven Kosteneinsparungen. Für dieses E-Commerce-Unternehmen, das 20 Stapel pro Monat verarbeitet, sind das Einsparungen von über 13.000 US-Dollar pro Monat. Über die unmittelbaren Geldeinsparungen hinaus hat das Team fast eine volle Woche produktiver Zeit zurückgewonnen.
Sie können sich nun auf die Optimierung von Preisstrategien oder Verhandlungen mit Anbietern konzentrieren, anstatt mit Tabellenkalkulationen zu kämpfen. Diese dramatische Verbesserung ist der Weg zu echter Effizienz, die für jedes wachsende Unternehmen unerlässlich ist. Die Abhängigkeit von manuellen Prozessen zur Entfernung von Duplikaten in Excel-Daten ist eine veraltete Strategie, die Ihre Gewinne direkt schmälert.
1-2-3 Schritt-Anleitung: Duplikate in Excel-Daten schnell mit KI entfernen
Dies ist eine taktische Anleitung. Wir gehen über die Theorie hinaus, um Ihnen die genauen Schritte für eine schnelle und hochpräzise Duplikatentfernung zu geben. Sie können Tabellenkalkulations-Workflows automatisieren nahtlos. Hier ist der definitive 1-2-3-Prozess mit TabliSync.
Schritt 1: Verbinden Sie Ihre Excel-Datei oder Datenquelle
Ihr erster Schritt ist es, Ihre Daten in die TabliSync-Umgebung zu bringen. Die herkömmliche Copy-and-Paste-Methode ist langsam und fehleranfällig. TabliSync ist für die Datenübertragung in Unternehmen konzipiert und macht diesen ersten Schritt schnell und sicher. Sie haben zwei Hauptoptionen:
- Direkter Datei-Upload: Melden Sie sich bei Ihrem TabliSync-Dashboard an und navigieren Sie zum Bereich für die Datenaufnahme. Klicken Sie auf die Schaltfläche „Hochladen“ und wählen Sie Ihre Excel-Datei (.xlsx oder .csv) von Ihrem lokalen Rechner aus. Das System analysiert die Datei sofort und zeigt einen Bildschirm zur Schema-Zuordnung an.
- API- oder Datenbankverbindung: Für robustere automatisierte Tabellenkalkulations-Workflows verwenden Sie einen direkten Connector. Wenn Ihre Excel-Daten in eine Cloud-Datenbank (wie SQL Server oder PostgreSQL) oder einen Cloud-Speicher (wie Amazon S3) übertragen werden, konfigurieren Sie diese Verbindung innerhalb von TabliSync. Dies schafft eine sichere, persistente Datenpipeline. Dies ist ein überlegener Ansatz für wiederkehrende Prozesse.
Während der Zuordnungsphase ist es entscheidend, TabliSync mitzuteilen, was jede Spalte darstellt. Ordnen Sie beispielsweise explizit Spalten für „Rechnungsnummer“, „E-Mail-Adresse“ oder „Produkt-SKU“ zu. Die in TabliSync integrierte Expertise ermöglicht es, Datentypen automatisch zu erkennen und eine Spalte als „Finanzdaten“ oder „Kundenkontakt“ zu identifizieren. Dieses semantische Verständnis ist der Eckpfeiler der KI-Datenbereinigung. Nehmen Sie sich Zeit, die Zuordnung zu überprüfen und stellen Sie sicher, dass alle wichtigen Felder korrekt identifiziert sind. Dies ist die Grundlage Ihres Erfolgs.
Ein häufiger Fehler in dieser Phase ist das Hochladen einer unordentlichen Datei ohne Kopfzeile. Um dies zu vermeiden, strukturieren Sie Ihre Excel-Datei immer mit einer einzigen, klaren Kopfzeile, die eindeutige Namen für jede Spalte enthält. Dies ermöglicht es TabliSync, Ihre Daten korrekt zu interpretieren. Klicken Sie nach der Zuordnung auf „Pipeline erstellen“. Die Erfahrung zeigt, dass Unternehmen, die diese direkten Connectoren nutzen, allein bei der Datenaufbereitung weitere 80 % einsparen.
Schritt 2: Konfigurieren Sie die KI-Regel zur Erkennung von Duplikaten
Hier entfaltet sich die wahre Kraft der KI-Datenbereinigung. Sie definieren nun, wie TabliSync Duplikate identifiziert, und das geht weit über das einfache exakte Abgleichen von Excel hinaus. Gehen Sie zur Transformationskonfiguration für Ihre Pipeline. Hier finden Sie eine spezielle Komponente 'Deduplizierung'.
- Schlüsselspalten auswählen: Sie können eine oder mehrere Spalten auswählen, um zu definieren, was ein Duplikat ausmacht. Für eine Kundenliste könnten Sie sowohl 'E-Mail' als auch 'Telefonnummer' auswählen, um echte Einzigartigkeit zu finden. Dieses Abgleichen mehrerer Schlüssel ist für komplexe Geschäftsregeln unglaublich leistungsfähig.
- KI-gestützte Fuzzy-Übereinstimmung aktivieren: Dies ist der entscheidende Unterschied. Aktivieren Sie nicht nur eine Checkbox für exakte Übereinstimmung. Schalten Sie stattdessen den Schalter 'KI-Fuzzy-Logik' um. Diese erweiterte Option verwendet Natural Language Processing (NLP), um Datensätze zu finden, die semantisch identisch sind, sich aber in der Formatierung unterscheiden.
- Schwellenwerte konfigurieren: Für die Fuzzy-Übereinstimmung können Sie einen Konfidenzschwellenwert festlegen (z. B. 90 %). Zum Beispiel wird die KI 'Acme Corp.' und 'Acme Corporation' mit hoher Wahrscheinlichkeit als Duplikate kennzeichnen. Dies löst das Problem unsichtbarer Leerzeichen am Ende, ohne dass Sie eine einzige Formel schreiben müssen. Es werden automatisch leichte Variationen behandelt, die manuelle Filter oder grundlegende Excel-Abgleiche übersehen.
Darüber hinaus ermöglicht diese Konfiguration die Festlegung komplexer Zusammenführungsregeln. Wenn zwei Datensätze Duplikate sind, möchten Sie dann den ersten behalten, den zuletzt geänderten oder sie anhand einer Regel zusammenführen? Sie können beispielsweise in einer Kunden-CRM-Liste eine Regel erstellen, die besagt: „Behalte das älteste ‚Erstellungsdatum‘ bei, aber aktualisiere mit der neuesten ‚Telefonnummer‘“. Dieses Maß an Kontrolle stellt sicher, dass Ihre Daten nicht nur bereinigt, sondern auch konsolidiert werden, um die Genauigkeit von Finanzdaten zu verbessern. Für die industrielle Datenverarbeitung kann dies widersprüchliche Sensorwerte über ein 1-Sekunden-Intervall konsolidieren und einen einzigen, präzisen Eintrag für Ihre Zeitreihenanalyse erstellen. Dies ist nicht nur das Entfernen von Daten; es ist ein hochentwickelter Prozess der Datensynthese. Achten Sie genau auf diese Einstellungen. Die anfängliche Einrichtung stellt sicher, dass Ihre automatisierte Pipeline einwandfrei funktioniert und spart Ihnen Stunden manueller Überprüfung und Abgleichs.
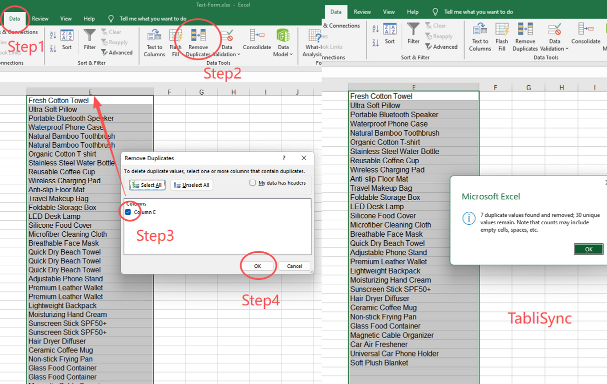
Schritt 3: Führen Sie die Synchronisierung aus und sehen Sie Ihre bereinigten Daten an
Der letzte Schritt ist die Ausführung der Transformation und das Erhalten Ihrer bereinigten Daten. Bei dieser Ausführung können Sie Excel-Dubletten entfernen – und das sofort. Gehen Sie zurück zu Ihrer Pipeline-Übersicht und klicken Sie auf „Sync ausführen“. Die Backend-Engine von TabliSync verarbeitet den gesamten Datensatz und wendet Ihre komplexen KI-Regeln und Zusammenführungslogiken mit unglaublicher Geschwindigkeit an. Diese Operation ist darauf ausgelegt, Millionen von Zeilen industrieller Datenverarbeitung in wenigen Minuten zu verarbeiten.
- Überwachen Sie das Echtzeitprotokoll: Sie können ein detailliertes Protokoll des Prozesses einsehen, das die Anzahl der Eingabezeilen, die Anzahl der gefundenen Duplikate und die endgültige Anzahl der eindeutigen Ausgabezeilen anzeigt. Dies sorgt für Transparenz und ermöglicht die Überprüfung.
- Laden Sie die bereinigte Excel-Datei herunter: Sobald die Synchronisierung abgeschlossen ist, können Sie den Ausgabe-Datensatz direkt als .xlsx- oder .csv-Datei herunterladen. Dies sind die Daten, denen Sie vertrauen können. Sie sind standardisiert, duplikatfrei und bereit für die Analyse oder das Laden in ein anderes System.
- Überprüfen Sie den Auflösungsbericht: Entscheidend ist, dass TabliSync einen detaillierten Auflösungsbericht erstellt. Für jede identifizierte Duplikatgruppe zeigt der Bericht genau an, welcher Datensatz beibehalten wurde und wie die endgültigen Werte ermittelt wurden. Dieser Bericht liefert die Audit-Spur, die für die Einhaltung von Vorschriften zur finanziellen Datenintegrität, wie z. B. Sarbanes-Oxley (SOX) für die Finanzberichterstattung, erforderlich ist. Sie haben den Nachweis für Prüfer, dass Ihre Datenverarbeitung solide und validiert ist.
Dieser automatisierte Prozess ist wiederholbar. Sie können diese Pipeline so planen, dass sie stündlich oder täglich ausgeführt wird, oder sie sofort über einen Webhook von einem anderen System aus auslösen. Das bedeutet, dass Sie einen kontinuierlichen Prozess zur Automatisierung von Tabellenkalkulations-Workflows für saubere Daten etabliert haben. Ihre Teams können sich nun auf die Ergebnisse verlassen, da sie wissen, dass diese immer aktuell und fehlerfrei sind. Der gesamte Prozess des manuellen Filterns, TRIMMens, Standardisierens und Löschens von Daten in Excel ist für immer verschwunden und wurde durch einen einzigen, skalierbaren und vertrauenswürdigen KI-gesteuerten Workflow ersetzt. So gewinnen Sie Ihre Zeit zurück und stellen die Integrität Ihres wertvollsten Guts sicher: Ihrer Daten.
Die Bedeutung der finanziellen Datenintegrität bei Abgleich und Hauptbuch
Für Finanzabteilungen ist das Ziel der Duplikatentfernung nicht nur eine kosmetische Bereinigungsübung; es ist eine entscheidende Komponente der finanziellen Datenintegrität. Ungenaue Finanzdaten sind nicht nur eine Ineffizienz; sie stellen ein erhebliches Geschäftsrisiko dar. Sie beeinflussen alles, von der Quartalsberichterstattung bis zur Steuereinhaltung. Ungenaue Daten können zu ernsthaften rechtlichen und regulatorischen Problemen führen. Lassen Sie uns untersuchen, wie sich Duplikate ausbreiten und warum eine präzise Lösung erforderlich ist.
Betrachten wir den Fall der Abstimmung. Dies ist der Prozess des Vergleichs zweier Datensätze (z. B. der internen Buchhaltung eines Unternehmens und seines Kontoauszugs), um sicherzustellen, dass sie übereinstimmen. Nehmen wir an, Sie stimmen die Kreditorenbuchhaltung (AP) ab. Das ERP Ihres Unternehmens zeigt möglicherweise eine Rechnungszahlung an einen Lieferanten an, aber eine doppelte Zahlung wurde versehentlich verarbeitet und erscheint auch auf dem Kontoauszug. Wenn Sie eine manuelle Abstimmung in Excel durchführen und aufgrund eines einfachen Formatierungsunterschieds den doppelten ERP-Eintrag übersehen, kämpfen Sie möglicherweise stundenlang, um Ihre Konten auszugleichen. Dies führt zu Diskrepanzen, deren Behebung erhebliche, qualifizierte Arbeitskräfte erfordert. Hier zählt Erfahrung. Ein leitender Buchhalter weiß, dass diese Diskrepanzen die Hauptursache für Verzögerungen beim Monatsabschluss sind. Die Erzielung einer schnellen, genauen KI-Datenbereinigungsmethode beschleunigt diesen gesamten Zyklus dramatisch.
Dieses Problem ist noch kritischer bei der Verwaltung des Hauptbuchs (GL). Das Hauptbuch ist der Master-Datensatz aller Finanztransaktionen innerhalb einer Organisation. Es ist die einzige Quelle der Wahrheit für die Erstellung von Bilanzen und Gewinn- und Verlustrechnungen. Wenn Duplikate in das Hauptbuch gelangen – vielleicht durch doppeltes Importieren einer CSV-Datei aus einer regionalen Niederlassung –, verzerrt dies die gesamte finanzielle Gesundheit des Unternehmens. Eine Überbewertung der Ausgaben um einige hunderttausend Dollar aufgrund einer Reihe von subtilen Duplikaten über mehrere Konten hinweg könnte zu falschen Rentabilitätsberechnungen führen. Dies kann Investoren irreführen und Prüfungskomplikationen auslösen. Es kann sogar zu Überzahlungen von Steuern führen, was eine direkte, negative Auswirkung auf den Cashflow hat. Hier ist eine professionelle Datenbereinigungslösung nicht nur nützlich, sondern absolut unerlässlich.
Die Aufrechterhaltung hochwertiger Finanzdaten durch robuste, prüffähige Prozesse ist ein zentraler Grundsatz der Corporate Governance. Deshalb sind Tools wie TabliSync darauf ausgelegt, die Genauigkeit von Finanzdaten in jedem Schritt zu unterstützen. Die von uns erwähnten Berichte zur Fehlerbehebung und klaren Audit-Trails sollen das notwendige Vertrauen für Ihre Finanzprüfer schaffen. Sie benötigen Nachweise dafür, dass Ihre Daten wiederholbar und unvoreingenommen verarbeitet werden. Für Erfahrungen in diesem Bereich liefern wir ein Beispiel. Ein multinationales Logistikunternehmen mit Niederlassungen in 12 Ländern nutzte TabliSync zur Verarbeitung von über 2 Millionen Hauptbuchposten pro Monat. Durch den Ersatz ihrer manuellen Excel-Prüfungen durch unsere KI-gesteuerte Lösung fanden sie im ersten Monat über 1.500 signifikante Duplikate in ihren Intercompany-Transaktionen. Allein diese Korrektur sparte ihnen über 400.000 US-Dollar an potenziellen Steuerüberzahlungen. Wichtiger noch, sie verkürzten ihren Monatsabschluss um fünf Arbeitstage. Das Maß an Kontrolle und Sicherheit, das ein automatisiertes System bietet, ist unübertroffen. Es ist der Unterschied zwischen einem risikoreichen manuellen Prozess und einem zuverlässigen, skalierbaren System. Dies ist nicht nur eine Verbesserung; es ist eine absolute Notwendigkeit für jede Organisation, die Wert auf finanzielle Integrität legt.
Automatisierung in Aktion: Fallstudien aus der Praxis zur Bereinigung komplexer Daten
Theorie ist nur nützlich, wenn sie durch Ergebnisse bewiesen wird. Diese drei Fallstudien aus der Praxis demonstrieren die transformative Kraft von TabliSync bei der Erzielung erheblicher Zeitersparnis und der drastischen Verbesserung der betrieblichen Leistung. Sie zeigen Ihnen die greifbaren Auswirkungen des Einsatzes von KI-Datenbereinigung zur Entfernung von Duplikaten in Excel und anderen Datenformaten in verschiedenen Szenarien, von industriellen Arbeitsabläufen bis hin zu komplexen Gehaltssystemen. Dieser Abschnitt baut auf realen Erfahrungen in datenintensiven Umgebungen auf.
Fallstudie 1: Monatliche Einsparung von 300 Stunden bei der industriellen Datenverarbeitung
Erfahrung: Ein großer Fertigungskunde mit mehreren Montagewerken weltweit hatte Probleme mit seiner globalen Lieferketteninventur. Jedes Werk arbeitete mit separaten Instanzen eines Lagerverwaltungssystems, was zu fragmentierten und überlappenden Daten führte. Sie versuchten, dies in einer einzigen Master-Tabellenkalkulation zur Beschaffungsplanung zu konsolidieren, was zu einem Datensatz von über 850.000 Zeilen führte. Ein Team von vier Analysten verbrachte kumulativ 300 Stunden pro Monat damit, Duplikate in Excel zu entfernen, um manuell eine genaue Übersicht über den Lagerbestand zu erstellen. Das Problem war immens. Identische Produkt-SKUs aus verschiedenen Werken waren leicht unterschiedlich formatiert, was dazu führte, dass Standard-Excel-Tools Tausende von Datensätzen übersahen. Überhöhte Lagerbestandszahlen führten zu verzögerten Beschaffungen, was zu Produktionsunterbrechungen aufgrund von Teileknappheit führte und geschätzte 50.000 US-Dollar pro Stunde an Leerlaufkosten verursachte. Ihr manueller Arbeitsablauf war auch von menschlichen Fehlern durchsetzt, was zu einer Fehlerrate von 4 % im Abschlussbericht führte und das Betriebsrisiko weiter erhöhte.
Lösung: Das Unternehmen integrierte TabliSync, um Tabellenkalkulations-Workflows vollständig zu automatisieren. Sie konfigurierten eine direkte Verbindung zu allen APIs des Lagerverwaltungssystems, die automatisch Daten in eine einzige, einheitliche Pipeline streamten. Anstatt sich auf exakte SKU-Übereinstimmungen zu verlassen, implementierten sie KI-gestützte Datenbereinigung mit einer semantischen Deduplizierungsregel. Das System wurde so konfiguriert, dass Datensätze identifiziert werden, bei denen nicht nur die SKU, sondern auch die 'Produktbeschreibung' und der 'Lieferantenname' zu 95 % ähnlich waren. Dieses leistungsstarke KI-gestützte Fuzzy Matching erkannte sofort subtile Variationen, die ein menschlicher Analyst oder eine einfache COUNTIF-Formel immer übersehen würde. Zum Beispiel wurden 'Widget-A-123' in Werk 1, 'WidgetA123' in Werk 2 und 'Widget - A123' in Werk 3 erfolgreich als eine einzige Duplikatgruppe gekennzeichnet und aufgelöst, wobei die vordefinierten Geschäftsregeln zur Beibehaltung des zuletzt aktualisierten Datensatzes angewendet wurden.
Ergebnis: Die Umwandlung war augenblicklich. Der manuelle Prozess von 300 Stunden wurde zu einer vollständig automatisierten Pipeline reduziert, die in nur 18 Minuten lief. Zum ersten Mal verfügte das Unternehmen über eine wirklich genaue, de-duplizierte globale Bestandsübersicht, die Produktionsstillstände um über 90 % reduzierte und schätzungsweise 250.000 US-Dollar monatlich an verlorener Produktivität einsparte. So erreichen Sie industrielle Datenverarbeitung im großen Maßstab. Die Lösung lieferte qualitativ hochwertige Daten, die direkt zu einer besseren strategischen Planung führten. Diese Fallstudie zeigt den massiven und direkten ROI, der mit einer professionellen De-Duplizierungsstrategie erzielt werden kann. Hier geht es nicht darum, Zeit bei einer einzelnen Tabelle zu sparen; es geht darum, Kernbetriebsabläufe für einen Wettbewerbsvorteil neu zu gestalten.
Fallstudie 2: Beschleunigung des Monatsabschlusses um 6 Tage durch Genauigkeit der Finanzdaten
Erfahrung: Ein großer, börsennotierter Real Estate Investment Trust (REIT) ertrank in der Abstimmung von Finanzdaten. Ihre Unternehmensstruktur umfasste über 150 einzelne Immobiliengesellschaften, von denen jede monatlich eine Gewinn- und Verlustrechnung als CSV einreichte. Dies führte zu über 1 Million Transaktionen, die konsolidiert und abgeglichen werden mussten. Ein Team von Buchhaltungsexperten verbrachte die ersten acht Tage jedes Monatsabschlusses damit, Transaktionen manuell mit Pivot-Tabellen und komplexen Nachschlagevorgängen in diesem riesigen Datensatz zu Entfernen Duplikate Excel. Das Problem war besonders akut bei konzerninternen Transaktionen, bei denen dieselbe Rechnung sowohl von der Immobilie als auch von der zentralen Einheit gebucht wurde, oft mit geringfügigen Zeichenunterschieden. Überhöhte konzerninterne Verbindlichkeiten und Forderungen waren üblich, verzerrten die konsolidierte Finanzübersicht und erforderten erhebliche Prüfungsanpassungen, was das Vertrauen beschädigte. Eine einzige Duplikattransaktion bei einer konzerninternen Überweisung von 2,5 Millionen US-Dollar erforderte fünf Tage Zeit eines leitenden Prüfers zur Identifizierung und Behebung, was die kritische Natur der Genauigkeit von Finanzdaten unterstreicht.
Lösung: Der REIT setzte TabliSync ein, um Tabellenkalkulations-Workflows für seinen gesamten Monatsabschluss zu automatisieren. Sie nutzten unseren fortschrittlichen Webhook-Trigger, sodass die Daten automatisch in eine konsolidierte Pipeline aufgenommen wurden, sobald jede Immobiliengesellschaft ihre CSV-Datei in ein sicheres Portal hochgeladen hatte. Zur Deduplizierung verwendeten sie eine Multi-Key-Matching-Regel, die das 'Transaktionsdatum', den 'Betrag', die 'Währung' und ein eindeutiges 'Rechnungsnummern'-Token kombinierte, das von unserem expertise-gesteuerten Algorithmus generiert wurde, welcher komplexe Referenzfelder standardisiert. Dieses regelbasierte System bot die benötigte Präzision. Darüber hinaus lieferten die Auflösungsberichte von TabliSync eine detaillierte Audit-Trail, die genau zeigte, welche Transaktionen zusammengeführt wurden und warum. Dies bot die notwendige Sicherheit für ihre externen Prüfer bezüglich ihrer internen Kontrollen und schuf direkt Vertrauen.
Ergebnis: Die Auswirkungen waren tiefgreifend. Der gesamte Abgleich- und Deduplizierungsprozess wurde von 8 Tagen auf nur 2 Tage reduziert. Die Buchhalter führten nun Echtzeit-Analysen und Finanzprognosen durch, anstatt mit Tabellenkalkulationen zu kämpfen. Diese Reduzierung des Monatsabschlusses um sechs Tage ermöglichte eine schnellere Finanzberichterstattung und agilere Entscheidungsfindung. Darüber hinaus bot dieser verbesserte Prozess eine überprüfbare und robuste interne Kontrollumgebung, die das Problem der doppelten Intercompany-Überweisungen in Höhe von 2,5 Millionen US-Dollar vollständig beseitigte. Diese Fallstudie zeigt, dass eine hohe Genauigkeit der Finanzdaten nicht nur ein regulatorisches Nice-to-have ist, sondern ein wichtiger Differenzierungsfaktor für finanzielle Agilität und die Reduzierung von Betriebsrisiken.
Fallstudie 3: Halbierung der Fehler im Gehaltsabrechnungsprozess durch KI-Datenbereinigung in einem Hochvolumensystem
Erfahrung: Ein großes Unternehmen im Gesundheitswesen mit über 15.000 Stundenlöhnern in mehr als 60 Kliniken hatte Schwierigkeiten mit einem volumenintensiven Gehaltssystem. Sie erfassten die geleisteten Arbeitsstunden über ein älteres CSV-basiertes Zeiterfassungssystem und andere HR-Daten aus einem neueren Cloud-basierten System. Jeder Abrechnungszyklus wurden diese beiden Datenströme manuell in Excel zusammengeführt, ein Prozess, der unweigerlich Tausende von doppelten Einträgen erzeugte. Der manuelle Aufwand zur Entfernung von Duplikaten in Excel und anderen Datentypen erforderte ein Team von fünf HR-Analysten, die drei Tage lang Vollzeit arbeiteten. Trotz dieses Aufwands lag die Fehlerrate im endgültigen Gehaltslauf konstant über 4 %, was zu über- und unterbezahlten Mitarbeitern führte. Ein einziger doppelter Eintrag für einen Mitarbeiter mit mehreren Stempelungen am selben Tag kann übersehen werden, was zu erheblichen Überzahlungen führt. Die Korrektur dieser Fehler erforderte die Ausstellung kostspieliger Scheckanpassungen und führte zu erheblicher Frustration bei den Mitarbeitern, beeinträchtigte die Moral und birgt potenzielle Probleme bei der Einhaltung von Arbeitsgesetzen.
Lösung: Das Unternehmen nutzte TabliSync, um Tabellenkalkulations-Workflows zu automatisieren und eine zuverlässige KI-Datenbereinigung für seine Gehaltsabrechnung zu erreichen. Wir haben direkte Echtzeit-Integrationen sowohl mit ihrem Zeiterfassungssystem als auch mit ihrer Cloud-HR-Plattform eingerichtet. Wir haben einen fortschrittlichen mehrstufigen Deduplizierungsworkflow konfiguriert. In der ersten Stufe führte er eine einfache exakte Übereinstimmung von 'Mitarbeiter-ID' und 'Arbeitsdatum' durch. In der zweiten, entscheidenden Stufe nutzte er KI-Datenbereinigung mit einer ausgeklügelten Fuzzy-Matching-Regel für die Felder 'Zeit-Ein' und 'Zeit-Aus'. Wenn beispielsweise zwei Datensätze Stempelungen für denselben Mitarbeiter innerhalb von 3 Minuten voneinander zeigten (eine häufige Situation, wenn eine Zeiterfassung doppelt angetippt wird), wurden sie automatisch gemäß vordefinierten Geschäftsregeln zusammengeführt (z. B. unter Verwendung der frühesten 'Zeit-Ein' und der spätesten 'Zeit-Aus'). Dieses Präzisionsniveau ist nur mit intelligenten Systemen möglich. Darüber hinaus implementierten wir eine detaillierte Fehlerbehandlung, die alle wirklich unvereinbaren Daten (z. B. ein Mitarbeiter mit mehreren ganztägigen Einträgen an zwei verschiedenen Standorten) automatisch in Quarantäne stellte, um sie sofort von Menschen überprüfen zu lassen.
Ergebnis: Diese Transformation war bahnbrechend. Der dreitägige manuelle Prozess wurde zu einer vollautomatisierten Pipeline reduziert, die den gesamten Datensatz in 45 Minuten durchlief und validierte. Wichtiger noch, die Fehlerquote bei der Gehaltsabrechnung wurde im ersten Zyklus von über 4 % auf unter 0,5 % gesenkt. Diese direkte Reduzierung von Zahlungsfehlern und die Eliminierung manueller Anpassungen sparten dem Unternehmen über 18.000 US-Dollar an Betriebskosten und Überzahlungen pro Abrechnungszeitraum. Die Mitarbeitermoral verbesserte sich, da die Bezahlung konsistent und korrekt wurde, und das Risiko von Compliance-Problemen wurde praktisch eliminiert. Diese Fallstudie zeigt deutlich, dass große Datenmengen hochpräzise KI-Datenbereinigungslösungen erfordern, um sowohl Effizienz als auch entscheidende Compliance zu erreichen.
Häufig gestellte Fragen zur Entfernung von Duplikaten in Excel
F1: Ich habe das integrierte Tool von Excel ausprobiert, aber es hat Duplikate übersehen. Was ist passiert?
Das ist extrem häufig. Sie haben es mit Daten zu tun, die identisch aussehen, aber nicht sind. Die Hauptursache sind unsichtbare Zeichen, wie z. B. ein nachgestelltes Leerzeichen. Die Funktion `Duplikate entfernen` von Excel ist ein Exakt-Übereinstimmungssystem. Sie behandelt eine Zelle, die 'A ' enthält, und eine andere Zelle mit 'A' als zwei eindeutige Werte. Um dies manuell zu beheben, müssten Sie die Funktionen `=GLÄTTEN()` und `=SÄUBERN()` auf alle betroffenen Spalten anwenden, dann die Ergebnisse kopieren und als Werte einfügen, um Ihre Daten wirklich zu standardisieren, bevor Sie das integrierte Tool zuverlässig verwenden können. Die automatisierte KI-Datenbereinigung in **TabliSync** verfügt über diese Bereinigungslogik; sie standardisiert alle Textdaten und kann Fuzzy-Logik verwenden, um semantisch identische Datensätze zu erfassen, die nicht zu 100 % exakt im Zeichen sind, und umgeht dieses gesamte Problem.
F2: Kann ich mehrere Spalten kombinieren, um echte Duplikate in TabliSync zu finden?
Ja, und das ist eine große Stärke. Der Regel-Editor von TabliSync ermöglicht es Ihnen, den zusammengesetzten Schlüssel für die Eindeutigkeit zu definieren. Dies ist für die Geschäftslogik unerlässlich. Wenn Sie beispielsweise den Lagerbestand betrachten, ist ein eindeutiger Datensatz nicht nur eine 'Produkt-ID'; es ist die Kombination aus 'Produkt-ID', 'Lagerort' und 'Zustand'. Sie können diese drei Spalten in TabliSync auswählen, um Ihren eindeutigen Identifikator zu erstellen, und die Deduplizierungs-Engine entfernt nur Zeilen, die identische Werte in allen drei Feldern aufweisen. Diese mehrschlüssige und mehrstufige Validierung stellt sicher, dass Sie nicht nur Daten löschen, sondern eine intelligente KI-Datenbereinigung zur Unterstützung der industriellen Datenverarbeitung durchführen. Dieser Grad an Spezifität ist entscheidend für den Erfolg in hochkomplexen Anwendungen.
F3: Löscht TabliSync die Originaldaten? Ist es sicher zu verwenden?
Dies ist eine entscheidende Frage für das Vertrauen. TabliSync löscht Ihre Originaldaten **nicht**. Es funktioniert, indem es eine Kopie Ihres Datensatzes erstellt und dann die Duplizierungsregeln auf diese Kopie innerhalb einer dedizierten Pipeline anwendet. Sie definieren die Logik und erhalten als Ergebnis einen herunterladbaren bereinigten Datensatz. Ihre ursprüngliche Excel-Quelldatei bleibt vollständig unberührt. Wir empfehlen dies immer als Best Practice im Datenmanagement. Darüber hinaus generiert TabliSync für eine robuste Audit-Trail einen detaillierten Lösungsbericht, der genau zeigt, welche doppelten Zeilen identifiziert wurden, welche Regel angewendet wurde und wie die endgültigen Werte zusammengeführt oder ausgewählt wurden, was für die Einhaltung von Vorschriften in Bereichen, die eine hohe finanzielle Datengenauigkeit erfordern, unerlässlich ist.
F4: Mein Excel-Datensatz hat über 1 Million Zeilen. Kann TabliSync das bewältigen?
Absolut. Die Leistung im großen Maßstab ist ein Kernwertversprechen von TabliSync, insbesondere für die industrielle Datenverarbeitung. Herkömmliche Excel-Funktionen werden bei Daten dieser Größe oft extrem langsam oder stürzen sogar ab. Der Deduplizierungsprozess mit einer fortschrittlichen Zählformel würde Stunden dauern. Die Deduplizierungs-Engine von TabliSync ist von Grund auf für Big Data konzipiert. Wir verarbeiten und entfernen doppelte Excel-Datensätze aus Millionen von Zeilen in Minuten, nicht in Stunden. Dies geschieht durch die Nutzung cloudbasierter verteilter Computerressourcen, um die komplexen Berechnungen parallel zu verarbeiten. Wir verarbeiten regelmäßig Datensätze mit 10-20 Millionen Zeilen für Kunden und gewährleisten Geschwindigkeit und Zuverlässigkeit, die manuelle Werkzeuge nicht erreichen können.
F7: Kann ich meine Deduplizierungsaufgabe automatisch ausführen lassen?
Ja, und das ist der beste Weg, um Tabellenkalkulations-Workflows zu automatisieren. Sie können jede TabliSync-Pipeline mit einem flexiblen Zeitplan konfigurieren. Sie können sie stündlich, täglich, wöchentlich oder an bestimmten Tagen und zu bestimmten Zeiten ausführen lassen. Jedes Mal, wenn die Pipeline ausgeführt wird, ruft sie die neuesten Daten aus Ihrer Quelle ab, wendet automatisch die KI-Datenbereinigungslogik an, um Excel-Duplikate zu entfernen, und generiert einen neuen, sauberen Ausgabedatensatz. Dies stellt sicher, dass Ihre nachgelagerte Analyse oder Anwendung immer mit den aktuellsten und fehlerfreien Daten arbeitet und jeglichen manuellen Aufwand aus Ihrem Datenaufbereitungsprozess entfernt. Es ist ein grundlegender Bestandteil moderner Datenoperationen.
F8: Kann die KI von TabliSync Duplikate identifizieren, die unterschiedlich geschrieben sind?
Ja. Das ist der Unterschied zwischen einem System mit exakter Übereinstimmung und KI-Datenbereinigung. TabliSync verfügt über eine erweiterte Funktion für **KI-Fuzzy-Matching**. Sie verwendet Natural Language Processing (NLP), um Datensätze semantisch zu vergleichen. Zum Beispiel kann sie "Inc." im Vergleich zu "Incorporated" oder "Street" im Vergleich zu "St." sicher kennzeichnen und sogar gängige Schreibweisen eines Namens (wie "Jon" im Vergleich zu "John") erkennen. Sie können den Schwellenwert für die semantische Ähnlichkeit steuern. Sie vergleichen nicht nur Zeichen, sondern Bedeutung. Diese Fähigkeit ist absolut revolutionär für die Konsolidierung von Kundendaten (CRM) oder beim Zusammenführen von Anbieterlisten aus mehreren Altsystemen, was direkt zu Verbesserungen der Genauigkeit von Finanzdaten führt. Dieses intelligente Abgleichen ist eine Kernfunktion, die Sie nutzen sollten.
F9: Welchen Datensatz behält TabliSync, wenn ein Duplikat gefunden wird?
Sie haben die volle Kontrolle darüber. TabliSync trifft keine willkürlichen Entscheidungen. In unserem Regel-Builder für die Deduplizierung definieren Sie explizit die Zusammenführungslogik oder die Auflösungsregel. Sie können ausgefeilte mehrstufige Regeln erstellen. Zum Beispiel könnten Sie für eine Produktdatenbank eine Regel erstellen: "Behalte den Datensatz mit dem höchsten Preis" oder für ein Hauptbuch: "Behalte den Datensatz, der zuletzt gemäß seinem Transaktionszeitstempel erstellt wurde". Dieses regelbasierte System stellt sicher, dass der Deduplizierungsprozess sowohl vorhersehbar als auch nachvollziehbar ist, was für die Genauigkeit von Finanzdaten unerlässlich ist. Dies ist weitaus besser als die manuelle Löschung in Excel, bei der Sie eine fallweise Entscheidung treffen, die fehleranfällig ist und keine Audit-Spur bietet.
F8: Ich habe eine einzigartige Situation, in der einige Daten speziell behandelt werden müssen. Kann TabliSync helfen?
Ja. TabliSync ist eine leistungsstarke, flexible Plattform. Wir verstehen, dass nicht jeder Deduplizierungsfall einfach ist. Sie können hoch entwickelte Regelkonfigurationen erstellen, die über eine einzelne Komponente hinausgehen. Sie könnten zum Beispiel eine 'Filter'-Komponente verwenden, um Ihre Daten in zwei Pfade aufzuteilen: einen für die Standard-Deduplizierung und einen für eine spezialisierte, aufwändige Regel. Sie können auch mehrere Deduplizierungsschritte miteinander verketten, um eine äußerst präzise Datenbereinigung zu erreichen. Für hochkomplexe industrielle Datenverarbeitung können wir durch unsere professionellen Dienstleistungen sogar maßgeschneiderte Deduplizierungslogiken entwickeln, die genau auf Ihre geschäftlichen Anforderungen zugeschnitten sind. Diese Flexibilität stellt sicher, dass wir fast jedes Problem lösen können, auf das Sie bei der groß angelegten Datenbereinigung stoßen.
F9: Woher weiß ich, dass die Deduplizierung erfolgreich war?
Wir bieten mehrere Verifizierungsebenen. Unmittelbar nach Abschluss einer Synchronisierung erhalten Sie einen Bericht über die Deduplizierungszusammenfassung. Dieser Bericht zeigt Ihnen genau, wie viele Zeilen eingegeben wurden, wie viele Duplikate insgesamt gefunden wurden und die endgültige Anzahl eindeutiger Zeilen. Entscheidend ist, dass wir auch einen Auflösungsbericht generieren. Dieser Bericht ist ein Transaktionsprotokoll für jede Duplikatgruppe. Er zeigt die einzelnen Eingabezeilen, welche als Gewinner ausgewählt wurde und warum (z. B. Regel "Behalten basierend auf dem neuesten 'Geänderten Datum'"). Dieses Maß an Transparenz ist unerlässlich für die Validierung der Logik und bietet eine klare Audit-Spur, die für die Einhaltung von Unternehmensvorschriften unerlässlich ist, insbesondere in Bereichen mit hohen Anforderungen an die Genauigkeit von Finanzdaten. Sie haben vollständige Transparenz und Kontrolle.
F10: Sind meine Daten auf Ihrer Plattform sicher? Ich habe PII (personenbezogene Daten).
Datensicherheit hat für uns oberste Priorität. Wir bauen Vertrauen auf, indem wir robuste Sicherheitsmaßnahmen implementieren. TabliSync ist mit einer Security-First-Architektur aufgebaut. Wir verwenden branchenübliche Verschlüsselung für alle Daten im Ruhezustand und während der Übertragung (SSL/TLS 1.2 und AES-256). Für PII sind wir SOC 2 Type II-konform, ein wichtiger Industriestandard für den Datenschutz. Wir bieten eine granulare Zugriffskontrolle, mit der Sie verwalten können, welche Benutzer in Ihrer Organisation Zugriff auf bestimmte Pipelines und Daten haben. Darüber hinaus können Sie Ihre Pipelines so konfigurieren, dass sensible Felder (wie vollständige Kreditkartennummern oder Sozialversicherungsnummern) in der Deduplizierungsausgabe maskiert oder sogar dauerhaft geschwärzt werden, was eine zusätzliche Sicherheitsebene bietet und Ihnen hilft, die Einhaltung von Vorschriften wie der DSGVO oder CCPA zu gewährleisten. Sie können TabliSync mit Ihren sensibelsten Daten vertrauen.
Hören Sie auf, mit Tabellenkalkulationen zu kämpfen, und gewinnen Sie mit sauberen Daten
Der manuelle Versuch, **Duplikate in Excel zu entfernen**, ist eine massive Verschwendung Ihrer wertvollsten Ressourcen. Es ist ein langsamer, fehleranfälliger Kampf gegen unsichtbare Leerzeichen, widersprüchliche Formate und ein einfaches Fehlen von semantischem Verständnis, das in älteren Tools eingebettet ist. Die Abhängigkeit von einfachen Funktionen wie "Duplikate entfernen" ist für große Datenmengen und Daten mit hoher Integrität nicht mehr praktikabel. Es ist eine veraltete Strategie, die die Rentabilität schmälert und das Compliance-Risiko erhöht.
Sie müssen Ihre Datenprozesse jetzt transformieren. Der Umstieg auf **KI-Datenbereinigung** mit **TabliSync** ist nicht nur eine Effizienzsteigerung; es ist eine grundlegende Änderung der Art und Weise, wie Ihr Unternehmen Informationen verarbeitet. Sie wechseln von manuellen Reibungsverlusten und hohem Risiko zu automatisierten Abläufen und verifizierter finanzieller Datengenauigkeit. Holen Sie sich die über 300 Stunden zurück, die Ihr Team derzeit verschwendet, schließen Sie Ihren Monatsabschluss 6 Tage schneller ab und halbieren Sie Ihre Gehaltsabrechnungsfehler. Die Ergebnisse sind klar und sofort.
Jede Minute, die Sie zögern, ist eine Minute, in der Ihre Konkurrenz mit saubereren, schnelleren und zuverlässigeren Daten arbeitet. Der Schmerz der manuellen Datenverwaltung verschwindet nicht von selbst; er wird nur mit der Größe und Komplexität Ihres Unternehmens wachsen. Lassen Sie nicht zu, dass Ihre wertvollen Analysten weiterhin als Datenreiniger arbeiten. Befähigen Sie sie mit intelligenten, skalierbaren Lösungen. Hören Sie auf, einen aussichtslosen Kampf zu führen, und beginnen Sie zu gewinnen mit sauberen, verifizierten Daten, die Ihr Unternehmen voranbringen. Wir sind bereit, Sie auf dieser Reise zu unterstützen. Diese Transformation ist unkompliziert und die Ergebnisse sind garantiert. Die Wahl liegt bei Ihnen: Bleiben Sie bei manuellen Werkzeugen stecken oder umarmen Sie die Zukunft der automatisierten, intelligenten Daten.
Erleben Sie die Transformation noch heute selbst. Dies ist der Moment zu handeln. **[Klicken Sie hier, um Ihre kostenlose 3-tägige Testversion von TabliSync zu starten.]** Unsere Plattform erfordert keine komplexe Einrichtung oder umfangreiche Schulung. Wir zeigen Ihnen, wie Sie Ihre erste Excel-Datei verbinden und eine präzise, KI-gesteuerte Deduplizierung in weniger als 30 Minuten erreichen. Die Zeitersparnis, die Sie allein in Ihrer ersten Woche zurückgewinnen, wird die Kosten für das gesamte Jahr mehr als decken. Übernehmen Sie die Kontrolle über Ihre Daten und schöpfen Sie das wahre Potenzial Ihrer Organisation aus.
Was ist Duplikate in Excel-Daten schnell mit KI entfernen?
Kurze Antworten zu Duplikate in Excel-Daten schnell mit KI entfernen und wie TabliSync Teams in Excel beschleunigt.
Was ist Duplikate in Excel-Daten schnell mit KI entfernen?
Duplikate in Excel-Daten schnell mit KI entfernen umfasst praktische Excel-Workflows, typische Fehler und Automatisierungsmuster. Dieser TabliSync-Guide erklärt das Konzept, zeigt Beispiele und verlinkt Tutorials.
Wie kann TabliSync bei Duplikate in Excel-Daten schnell mit KI entfernen helfen?
TabliSync extrahiert Tabellen aus Screenshots oder PDFs, bereinigt unordentliche Daten und automatisiert repetitive Excel-Aufgaben zu Duplikate in Excel-Daten schnell mit KI entfernen.
Wo starte ich mit Duplikate in Excel-Daten schnell mit KI entfernen?
Beginnen Sie mit der Übersicht auf dieser Seite und öffnen Sie dann die verlinkten Artikel für Schritt-für-Schritt-Anleitungen und KI-Workflows.
Alle Duplikate in Excel entfernen Artikel(2)

Meistern Sie das Chaos: So entfernen Sie Duplikate in Excel ohne Datenverlust
Effizienzsteigerung: Reduzieren Sie die manuelle Datenbereinigungszeit um über 90 % durch automatisierte Workflows. Datenintegrität: Erzielen Sie eine Fehlerrate von 0 % bei der manuellen Eingabe, indem Sie von 'Suchen und Ersetzen' zur schemabasierten Deduplizierung übergehen. Risikominderung: Verhindern Sie 100 % versehentlicher Löschungen durch die Nutzung nicht-destruktiver Power Query-Umgebungen. Zukunftssicherheit: Wechseln Sie von reaktiver Bereinigung zu proaktiver Datenhygiene durch KI-integrierte Automatisierung.

So entsperren Sie ein Excel-Blatt ohne Passwort
• Excel-Blattschutz sofort mit 0 % Datenverlust umgehen. • Manuelle Wiederherstellungszeit um 95 % reduzieren durch Manipulation des XML-Schemas. • 'Gesperrte Zelle'-Fehler beseitigen und vollständige Datenhygiene sofort wiederherstellen. • KI-OCR nutzen, um statische geschützte Ansichten in dynamische strukturierte Daten umzuwandeln.
Schluss mit manueller Dateneingabe – Tabellen in Sekunden extrahieren
Konvertieren Sie jedes Bild oder PDF-Tabelle sofort in Excel mit 99,9% Genauigkeit. TabliSyncs KI-gestützte OCR verarbeitet handschriftliche Formulare, Belege und komplexe Tabellen und synchronisiert direkt mit Google Sheets, Notion oder Airtable
Probieren Sie TabliSync jetzt kostenlos aus