Article Summary
Dieser umfassende Leitfaden untersucht die Entwicklung des Datenparsens mit Schwerpunkt auf der kritischen Aufgabe 'Text in Spalten aufteilen' in komplexen, unstrukturierten Tabellen. Wir befassen uns mit den Einschränkungen herkömmlicher Tools wie dem Text-in-Spalten-Assistenten von Excel, der oft versagt, wenn er auf verschachtelte Daten, inkonsistente Trennzeichen oder mehrzeilige Zellen stößt. Durch die Integration von KI-Datenextraktion und automatisiertem Tabellenparsing können Benutzer jetzt die Bereinigung von Finanzdaten und die komplexe OCR-Verarbeitung mit beispielloser Genauigkeit durchführen. Die Pillar-Seite bietet eine taktische Schritt-für-Schritt-Anleitung zur Umwandlung strukturierter Daten und vergleicht manuelle Regex-basierte Methoden mit modernen KI-gesteuerten Lösungen wie TabliSync. Wir behandeln spezifische Enterprise-Anwendungsfälle, darunter die Abstimmung von Hauptbüchern, die automatisierte Rechnungsverarbeitung und die Handhabung von Nullwerten durch fortschrittliche Imputationsstrategien. Der Leitfaden dient als technisches Handbuch für Betriebsleiter, Datenanalysten und Finanzprofis, die ihre Daten-Workflows skalieren müssen, ohne Präzision oder Sicherheit zu opfern. Er betont die Bedeutung der SOC2-Konformität und die Rolle von Webhooks beim Aufbau nahtloser, automatisierter End-to-End-Datenpipelines für moderne Business Intelligence.
Die Evolution des Datenparsens: Jenseits des einfachen Assistenten
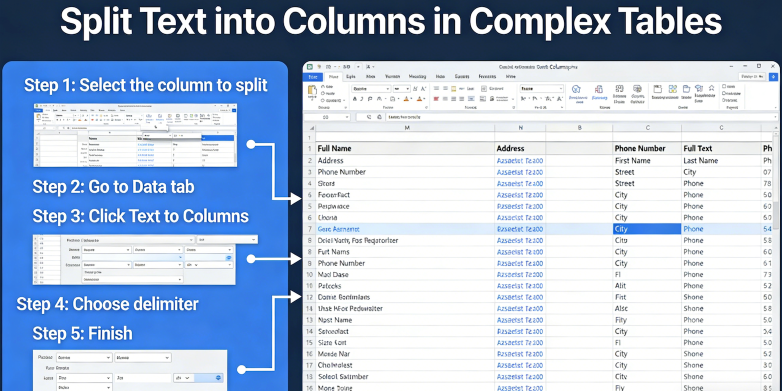
Um den aktuellen Stand von Text in Spalten aufteilen zu verstehen, müssen wir uns zunächst die traditionellen Grundlagen ansehen. Laut der Microsoft Support-Dokumentation zum "Assistenten zum Konvertieren von Text in Spalten":
"Sie können den Text in einer oder mehreren Zellen nehmen und ihn mithilfe des Assistenten zum Konvertieren von Text in Spalten auf mehrere Zellen verteilen. Dies wird im Allgemeinen für Daten verwendet, die durch ein bestimmtes Zeichen, wie z. B. ein Komma, begrenzt sind, oder für Daten mit fester Breite. Wenn Sie beispielsweise eine Liste von vollständigen Namen in einer Spalte haben, möchten Sie diese Spalte möglicherweise in separate Spalten für Vorname und Nachname aufteilen. Wählen Sie die Zelle oder Spalte aus, die den zu teilenden Text enthält. Wählen Sie Daten > Text in Spalten. Wählen Sie im Assistenten zum Konvertieren von Text in Spalten die Option Getrennt > Weiter. Wählen Sie die Trennzeichen für Ihre Daten aus. Zum Beispiel Komma und Leerzeichen. Sie können eine Vorschau Ihrer Daten im Fenster Datenvorschau sehen. Wählen Sie Weiter. Wählen Sie das Format der Spaltendaten aus oder verwenden Sie das, was Excel für Sie ausgewählt hat. Wählen Sie Fertig stellen." (Quelle: Microsoft Support, 2024).
Während dieser grundlegende Ansatz ein fester Bestandteil für einfache Tabellenaufgaben ist, erfordert die moderne Bereinigung von Finanzdaten erheblich mehr Leistung. Die Microsoft-Methode geht von einer Datenbereinigung aus, die in der realen Welt bei der komplexen OCR-Verarbeitung selten vorhanden ist. In einer professionellen Umgebung teilen Sie nicht nur "Max Mustermann" in zwei Zellen auf. Sie befassen sich mit der strukturellen Datenkonvertierung aus älteren PDFs, bei denen das "Trennzeichen" eine zufällige Anzahl von Leerzeichen, ein Zeilenumbruch oder schlimmer noch ein fehlender Wert sein kann, der dazu führt, dass die gesamte Zeile nach links verschoben wird und Ihre Hauptbuch-Ausrichtung ruiniert.
Meine Ansicht dazu ist, dass wir dem "Assistenten" entwachsen sind. Für hochriskante KI-Datenextraktion ist die manuelle Auswahl von Trennzeichen ein Rezept für eine Katastrophe. Wenn Sie 50.000 Datenzeilen haben, verursacht eine einzelne Zeile mit einem zusätzlichen Komma einen kaskadierenden Fehler, dessen Prüfung Stunden dauern kann. Wir müssen uns in Richtung automatisierter Tabellenanalyse bewegen, die den Kontext der Daten versteht, anstatt nur nach einem Semikolon zu suchen. Der Wandel von regelbasierter Aufteilung zu kontextbezogener Extraktion definiert die nächste Generation von Produktivitätstools.
Der stille Killer: Umgang mit fehlenden und Nullwerten
Der bedeutendste Schwachpunkt in jedem Split Text to Columns-Workflow ist der schlechte Umgang mit fehlenden oder Null-Werten. In vielen Altsystemen gibt es keine systematische Möglichkeit, diese Lücken zu imputieren oder zu kennzeichnen. Stellen Sie sich vor, Sie verarbeiten einen massiven Export aus einem ERP-System. Spalte A ist das Datum, Spalte B ist der Lieferant und Spalte C ist der Betrag. Wenn der Lieferantenname in einigen Zeilen fehlt, könnte ein Standard-Skript für die automatisierte Tabellenanalyse den "Betrag" in die Spalte "Lieferant" ziehen. Das schafft nicht nur unordentliche Daten, sondern unsichtbare Fehler, die zu fehlgeschlagenen Abgleichen führen.
Ohne eine Möglichkeit, Nullwerte zu kennzeichnen, wird Ihre strukturelle Datenkonvertierung zu einer Belastung. Die meisten Benutzer versuchen, dies zu beheben, indem sie manuell Tausende von Zeilen durchscrollen und nach "verschobenen" Daten suchen. Das ist nicht nur Zeitverschwendung, sondern ein grundlegendes Versagen der Datenpipeline. Wir sehen dies oft bei der Bereinigung von Finanzdaten, wo ein fehlender Hauptbuch-Code dazu führt, dass Ausgaben falsch kategorisiert werden, was potenziell zu Prüfungsfehlern oder Steuerunklarheiten führen kann. Das Fehlen einer systematischen "Imputations"- oder "Kennzeichnungs"-Engine bedeutet, dass der Datenkonsument immer mit einem fehlerhaften Datensatz arbeitet.
Auf Unternehmensebene können Sie es sich nicht leisten, einen Menschen als primären "Null-Prüfer" zu haben. Sie benötigen ein System, das das Fehlen eines Wertes basierend auf dem erwarteten Datentyp erkennt. Wenn Spalte C ein Währungsformat erwartet und einen String findet, sollte das System diese Zeile sofort kennzeichnen. Die traditionelle OCR-Verarbeitung übersieht oft diese Nuancen, da sie sich auf die Zeichenerkennung und nicht auf das semantische Verständnis konzentriert. Hier schließt die KI-Datenextraktion die Lücke, indem sie die automatische Einfügung von Platzhaltern ermöglicht oder einen Webhook auslöst, der nur bei Erkennung einer Anomalie zur menschlichen Überprüfung dient.
Traditionelles Excel vs. KI-Datenextraktion: Die Effizienzlücke
Wenn wir über Text in Spalten aufteilen sprechen, müssen wir die Kosten-Nutzen-Analyse traditioneller Methoden im Vergleich zur KI-Datenextraktion ansprechen. In einer aktuellen Fallstudie mit einer mittelgroßen Buchhaltungsfirma wurden wöchentlich etwa 15 Stunden für die manuelle Bereinigung von Kontoauszügen und Hauptbuch-Exporten aufgewendet. Die Verwendung traditioneller Excel-Assistenten erforderte, dass ein Analyst die "feste Breite" für jedes verschiedene Bankformat manuell anpasste. Bei einem durchschnittlichen Stundensatz von 45 US-Dollar gab das Unternehmen jährlich über 35.000 US-Dollar nur für die grundlegende Bereinigung von Finanzdaten aus.
Durch den Wechsel zur automatisierten Tabellenanalyse über TabliSync reduzierte das Unternehmen die wöchentliche Arbeitsbelastung von 15 Stunden auf nur 12 Minuten Überprüfung. Die Effizienzsteigerung betrug fast 98 %. Im Gegensatz zum Excel-Assistenten nutzt die KI-Datenextraktion maschinelles Lernen, um Muster zu erkennen. Es spielt keine Rolle, ob die Bank die Schriftart ändert oder ein neues Logo oben auf dem PDF hinzufügt. Die strukturelle Datenkonvertierungs-Engine identifiziert die Tabellenüberschriften und ordnet den Inhalt intelligent den richtigen Spalten zu, unabhängig von Änderungen im physischen Layout. Das ist der Unterschied zwischen einem "Werkzeug" und einer "Lösung".
Darüber hinaus erstrecken sich die Kosteneinsparungen über die reine Arbeitszeit hinaus. Betrachten Sie die Kosten eines Dateneingabefehlers. Bei einem Abgleichprozess kann ein einzelnes falsch platziertes Dezimalkomma aufgrund einer fehlgeschlagenen Text-zu-Spalten-Aufteilung zu einer Diskrepanz von mehreren tausend Dollar führen. Komplexe OCR-Verarbeitung in Kombination mit KI-Validierung reduziert die Fehlerrate von einem branchenüblichen Durchschnitt von 4 % (manuelle Eingabe) auf weniger als 0,1 %. Wenn Sie das reduzierte Risiko von Finanzberichten berücksichtigen, wird der ROI für die automatisierte Tabellenanalyse exponentiell. Unternehmen sparen nicht mehr nur Zeit; sie kaufen Genauigkeit und Seelenfrieden.
Funktion Traditioneller Excel-Assistent TabliSync KI-Extraktion
Einrichtungszeit
Manuell für jeden Dateityp
Einmaliges, vorlagenfreies Lernen
Komplexe Tabellen
Schlägt bei verschachtelten/mehrzeiligen Zellen fehl
Verarbeitet verschachtelte Strukturen problemlos
Null-Handling
Verursacht Spaltenverschiebung
Automatische Kennzeichnung und Beibehaltung der Struktur
Skalierbarkeit
Begrenzt durch menschliche Kapazität
Verarbeitet Tausende von Seiten über API
Schritt-für-Schritt: Komplexe Textaufteilung in Spalten meistern
Schritt 1: Analyse der Quellstruktur und Trennzeichen
Bevor Sie überhaupt an Textaufteilung in Spalten denken, müssen Sie Ihre Quelldaten gründlich prüfen. Dies gilt insbesondere für die komplexe OCR-Verarbeitung, bei der der "Text" aus einer flachen Datei oder einer PDF extrahiert wird. Sie müssen feststellen, ob Ihre Daten wirklich durch Trennzeichen (Kommas, Tabs oder Pipes) getrennt sind oder ob sie auf festen Abständen basieren. Viele moderne Aufgaben zur Bereinigung von Finanzdaten beinhalten "versteckte" Trennzeichen, wie z. B. nicht umbrechende Leerzeichen oder bestimmte ASCII-Zeichen, die in einem Standard-Texteditor nicht sichtbar sind.
In diesem Schritt sollten Sie einen fortgeschrittenen Texteditor (wie VS Code oder Sublime) verwenden, um versteckte Zeichen anzuzeigen. Achten Sie auf Inkonsistenzen. Enthält die dritte Zeile ein zusätzliches Komma innerhalb eines Anführungszeichens? Standard-Tools für die Konvertierung strukturierter Daten werden damit überfordert sein. Sie müssen entscheiden, ob Sie einen "gierigen" Regex oder ein nuancierteres KI-Datenextraktionsmodell verwenden möchten. Wenn Sie mit einem Hauptbuch arbeiten, prüfen Sie, ob die Kontonummern und Beschreibungen in einem Feld zusammengeführt sind. In dieser Phase definieren Sie die "Logik" Ihrer Aufteilung. Notieren Sie alle mehrzeiligen Zellen, da diese der Hauptgrund dafür sind, dass einfache Assistenten fehlschlagen.
Profi-Tipp: Erstellen Sie immer eine Sicherungskopie Ihrer Rohdaten, bevor Sie ein Skript zur automatisierten Tabellenanalyse ausführen. Wenn Ihre Regex-Logik fehlerhaft ist, könnten Sie kritische Daten überschreiben. Dokumentieren Sie während dieser Analysephase die "Grenzfälle" – die Zeilen, die nicht dem Muster entsprechen. Dies sind die Zeilen, die eine KI-Datenextraktion erfordern, um sie kontextbezogen und nicht mechanisch zu interpretieren. Das Verständnis der "Form" Ihrer Daten spart hier Stunden bei der Fehlerbehebung in Schritt 3.
Schritt 2: Konfiguration der KI-Extraktions-Engine
Sobald Sie die Muster (oder deren Fehlen) identifiziert haben, fahren Sie mit der Konfiguration Ihrer automatisierten Tabellenanalyse-Engine fort. In TabliSync bedeutet dies nicht, Code zu schreiben, sondern die "Entitäten" zu definieren, die Sie extrahieren möchten. Anstatt dem System zu sagen "teile bei jedem Komma", sagen Sie dem System "finde die Rechnungsnummer, das Datum und den Gesamtbetrag der Einzelposten". Dieser Ansatz der KI-Datenextraktion ist wesentlich robuster, da er räumliches Bewusstsein und semantische Logik verwendet, um die Aufgabe der Textaufteilung in Spalten durchzuführen.
Während der Konfiguration können Sie Regeln für die Strukturdatenkonvertierung festlegen. Wenn beispielsweise ein Wert als "Datum" identifiziert wird, können Sie das System anweisen, ihn während der Aufteilung in das ISO 8601-Format (JJJJ-MM-TT) zu normalisieren. Hier findet die Bereinigung von Finanzdaten in Echtzeit statt. Sie verschieben nicht nur Text, sondern transformieren ihn. Sie sollten hier auch Ihre Handhabung von Nullwerten konfigurieren. Sagen Sie dem System: "Wenn die Spalte 'Menge' leer ist, kennzeichnen Sie diese Zeile zur manuellen Überprüfung und fahren Sie nicht mit dem Abgleich-Export fort."
In diesem Schritt integrieren Sie auch Ihre Webhook-Einstellungen. Wenn Sie Tausende von Dokumenten verarbeiten, möchten Sie, dass das System Ihr ERP (wie NetSuite oder SAP) benachrichtigt, sobald der Prozess Text in Spalten aufteilen abgeschlossen ist. Dies schafft eine nahtlose automatisierte Tabellenanalyse-Pipeline. Stellen Sie sicher, dass Sie Ihre Konfiguration anhand einer kleinen Teilmenge von 10-20 unterschiedlichen Dokumenten testen, um sicherzustellen, dass die KI die Kopfzeilen und die Grenzen der komplexen OCR-Verarbeitung korrekt identifiziert hat. Überprüfen Sie die vollständige Feldabdeckung (100%), bevor Sie zur Massenverarbeitung übergehen.
Schritt 3: Ausführung und Datenvalidierung nach der Aufteilung
Der letzte Schritt ist die eigentliche Ausführung der Aufgabe Text in Spalten aufteilen und die anschließende Validierung. Hier zeigt sich, was die Technik wirklich kann. Während die KI-Datenextraktions-Engine die Datei verarbeitet, werden Ihre Zielspalten gefüllt. Die Arbeit ist jedoch noch nicht getan. Sie müssen eine Validierungsschicht implementieren. Dies beinhaltet die Überprüfung der extrahierten Daten anhand bekannter Geschäftsregeln. Beispielsweise muss bei der Bereinigung von Finanzdaten die Summe der "aufgeteilten" Einzelposten dem aus der Kopfzeile extrahierten "Gesamtbetrag" entsprechen. Wenn sie nicht übereinstimmen, hat die automatisierte Tabellenanalyse eine Integritätsprüfung nicht bestanden.
Die Validierung ist der Punkt, an dem die strukturelle Datenkonvertierung Enterprise-tauglich wird. Achten Sie auf "niedrige Konfidenzwerte". Moderne OCR-Verarbeitungstools geben für jede Zelle einen Konfidenzprozentsatz an. Wenn das System nur zu 60 % sicher ist, dass eine Aufteilung korrekt ist, sollte sie zur menschlichen Überprüfung in eine Warteschlange gestellt werden. Dieses "Human-in-the-Loop"-Modell stellt sicher, dass Sie eine 100%ige Genauigkeit beibehalten und dennoch 95 % des Volumens automatisieren. Nach der Validierung sind Ihre Daten bereit für die endgültige Abstimmung oder für die Verwendung in Business-Intelligence-Dashboards.
Achten Sie genau darauf, wie das System mit den zuvor besprochenen Nullwerten umgegangen ist. Wurden sie korrekt gekennzeichnet? Blieben die Spalten ausgerichtet? Wenn Sie einen wiederkehrenden Fehler feststellen, gehen Sie zurück zu Schritt 2 und verfeinern Sie die KI-Anweisungen. Ziel ist es, eine sich selbst verbessernde Schleife zu schaffen, bei der jeder Text in Spalten aufteilen-Auftrag genauer wird als der vorherige. Exportieren Sie schließlich Ihre Daten im erforderlichen Format (CSV, JSON oder direkter API-Push) und schließen Sie den Kreislauf, indem Sie das Originaldokument für die SOC2-Konformität und Prüfpfade archivieren.
Die Rolle der strukturellen Datenkonvertierung bei Finanzprüfungen
In der Welt der Finanzdatenbereinigung ist die strukturelle Datenkonvertierung mehr als nur ein Komfort; sie ist eine Voraussetzung für moderne Prüfungen. Wirtschaftsprüfer gehen heute von stichprobenbasierten Tests zu Tests der gesamten Population über. Das bedeutet, dass Sie in der Lage sein müssen, jeden einzelnen Geschäftsvorfall in Ihrem Hauptbuch in Spalten aufzuteilen, nicht nur eine Handvoll. Wenn Ihre Daten in unordentlichen, unformatierten PDF-Exporten gefangen sind, stehen Sie vor einer massiven Prüfungsrechnung oder einer eingeschränkten Stellungnahme.
Die Verwendung von KI-Datenextraktion zur Normalisierung dieser Datensätze stellt sicher, dass jede Transaktion durchsuchbar und kategorisierbar ist. Wenn beispielsweise eine Abgleichung zwischen Kontoauszügen und internen Aufzeichnungen durchgeführt wird, ermöglicht die Fähigkeit, Transaktionszeichenfolgen automatisch in „Datum“, „Transaktions-ID“ und „Händler“ aufzuteilen, eine automatisierte Zuordnung. Diese automatisierte Tabellenanalyse-Funktion kann den Zeitaufwand für Jahresabschlussprüfungen um Wochen reduzieren. Darüber hinaus bieten die Protokolle der komplexen OCR-Verarbeitung eine klare Prüfspur, wie Daten transformiert wurden, was ein großer Vorteil für die internen Kontrollen ist.
Die SOC2-Konformität schreibt auch vor, dass Daten sicher und korrekt behandelt werden müssen. Manuelle Prozesse zum Aufteilen von Text in Spalten sind anfällig für menschliche Manipulationen oder versehentliches Löschen. Ein automatisiertes System zur strukturellen Datenkonvertierung wie TabliSync stellt sicher, dass die Transformationslogik konsistent angewendet wird und während des Bereinigungsprozesses keine unbefugten Änderungen vorgenommen werden. Dieses Maß an Vertrauen ist für CFOs und Controller unerlässlich, die Finanzberichte mit absoluter Sicherheit über die zugrunde liegende Datenintegrität unterzeichnen müssen.
Fallstudie 1: Logistikfirma automatisiert die Analyse von Frachtbriefen
Ein globaler Logistikdienstleister hatte Schwierigkeiten mit der komplexen OCR-Verarbeitung seiner Frachtbriefe. Jeder Versandpartner verwendete ein anderes Tabellenformat, und viele Dokumente waren Scans von schlechter Qualität. Ihr manueller Workflow zum Aufteilen von Text in Spalten umfasste fünf Vollzeitmitarbeiter, die Daten aus PDFs in Excel kopierten und einfügten und dabei manuell Fehler korrigierten, die durch verschobene Spalten verursacht wurden. Sie verarbeiteten 2.000 Dokumente pro Monat mit einer Fehlerrate von 12 % in den Spalten „Gewicht“ und „Ziel“.
Sie implementierten TabliSync für die KI-Datenextraktion. Das System wurde auf einer Vielzahl von Dokumentenlayouts trainiert und lernte, die Kernkante unabhängig vom umgebenden Rauschen zu identifizieren. Die automatisierte Tabellenanalyse-Engine konnte die mehrzeiligen Beschreibungen mit 99%iger Genauigkeit in separate Spalten „Artikelnummer“, „Menge“ und „Gewicht“ aufteilen. Diese strukturelle Datenkonvertierung sparte nicht nur Zeit, sondern ermöglichte auch die direkte Integration der Daten über Webhooks in ihr Tracking-System, wodurch ihren Kunden Echtzeit-Einblicke gewährt wurden.
Das Ergebnis war eine Gesamtkostenreduzierung von 120.000 US-Dollar im ersten Jahr. Wichtiger noch, die Bearbeitungszeit für die Abwicklung einer Sendung sank von 4 Stunden auf 5 Minuten. Dies ermöglichte es dem Unternehmen, mehr Kunden zu gewinnen, ohne die Mitarbeiterzahl zu erhöhen. Dieser Fall unterstreicht, wie Text in Spalten aufteilen, wenn es von KI angetrieben wird, zu einem strategischen Vorteil und nicht zu einer Back-Office-Aufgabe wird. Die erzielten Effizienzsteigerungen ermöglichten es ihnen, auf eine Weise zu skalieren, die mit manueller Verarbeitung niemals möglich gewesen wäre.
Fallstudie 2: Finanzbereinigung eines Real Estate Investment Trust (REIT)
Ein großer REIT stand vor einer gewaltigen Herausforderung bei der Bereinigung von Finanzdaten. Jeden Monat erhielten sie Tausende von verschiedenen Mietlisten in verschiedenen Formaten. Einige waren Excel-Dateien, einige waren PDFs und einige waren sogar Bilder. Die strukturelle Datenkonvertierung, die erforderlich war, um diese Daten in einem einzigen Hauptbuch zu konsolidieren, war ein Albtraum. Ihr Hauptproblem waren "verschachtelte" Daten, bei denen mehrere Werte in einer einzigen Zelle zusammengefasst waren und eine komplexe Operation Text in Spalten aufteilen erforderten, die Standardwerkzeuge nicht bewältigen konnten.
Durch den Einsatz von KI-Datenextraktion konnte der REIT die Extraktion von Mieternamen, Mietvertragsdaten und Zahlungsverläufen automatisieren. Die Engine für die automatisierte Tabellenanalyse erkannte, wenn eine einzelne Zelle sowohl die Grundmiete als auch die Nebenkosten (CAM) enthielt, und teilte sie für eine genaue Buchführung in separate Spalten auf. Dieses Maß an komplexer OCR-Verarbeitung war zuvor ohne erheblichen menschlichen Eingriff unmöglich gewesen.
Der REIT berichtete über eine Reduzierung der Zeit für den Monatsabschluss um 70 %. Durch die Automatisierung des Abgleichprozesses entdeckten sie auch über 50.000 US-Dollar an untererfassten Mieteinnahmen, die in den Vormonaten bei manuellen Stichproben übersehen worden waren. Diese Effizienz und die daraus resultierenden Kosteneinsparungen bewiesen, dass KI-Datenextraktion ein unverzichtbares Werkzeug für jedes Unternehmen ist, das hochvolumige, komplexe Finanzdatensätze verwaltet. Die strukturelle Datenkonvertierung war der Schlüssel zur Erschließung des wahren Werts ihrer Daten.
Fallstudie 3: Anwaltskanzlei und Analyse von Discovery-Dokumenten
Während der Entdeckungsphase eines großen Rechtsstreits musste eine Anwaltskanzlei über 100.000 Seiten von Bankunterlagen und internen Memos verarbeiten. Sie mussten Text in Spalten aufteilen für jede erwähnte Finanztransaktion, um nach Betrugsmustern zu suchen. Manuelle Eingabe war aufgrund von Zeit- und SOC2-Compliance-Bedenken ausgeschlossen. Sie benötigten ein Tool zur strukturellen Datenkonvertierung, das komplexe OCR-Verarbeitung bewältigen und gleichzeitig eine strenge Beweismittelkette aufrechterhalten konnte.
TabliSync bot die notwendigen KI-Datenextraktions-Funktionen. Das System analysierte die Dokumente, identifizierte Transaktionstabellen und teilte sie in durchsuchbare Spalten auf, darunter „Empfänger“, „Betrag“, „Datum“ und „Quellkonto“. Selbst wenn die Dokumente gedreht oder leicht verschwommen waren, behielt die automatisierte Tabellenanalyse-Engine eine hohe Genauigkeit bei. Die Kanzlei nutzte die Webhook-Integration, um diese Daten direkt in ihre Prozessunterstützungssoftware für erweiterte Analysen einzuspeisen.
Diese Automatisierung ermöglichte es dem Rechtsteam, kritische Beweise in drei Tagen zu finden – eine Aufgabe, die ein Team von Rechtsanwaltsfachangestellten mehrere Monate gekostet hätte. Das Vertrauen, das durch genaue Bereinigung von Finanzdaten und robuste Audit-Trails aufgebaut wurde, war entscheidend für den Gewinn des Falls durch die Kanzlei. Dies zeigt, dass die strukturelle Datenkonvertierung ein vielseitiges Werkzeug ist, das weit über die Finanzabteilung hinausgeht und eine entscheidende Rolle bei rechtlichen, Compliance- und Ermittlungsarbeiten spielt.
Fortgeschrittene Techniken: Regex vs. KI für strukturelle Datenkonvertierung
Seit Jahrzehnten war der Goldstandard für die Konvertierung strukturierter Daten reguläre Ausdrücke (Regex). Regex ist mächtig, aber fehleranfällig. Es erfordert von einem Entwickler, jede mögliche Datenvariation vorherzusehen. Wenn ein Anbieter sein Rechnungsformat ändert, indem er die "Summe" einen Zentimeter nach rechts verschiebt, bricht die Regex oft. Dies führt zu einem ständigen Kreislauf von Wartung und fehlerhaften Skripten zur automatischen Tabellenanalyse. Im Gegensatz dazu ist die KI-Datenextraktion widerstandsfähig. Sie sucht nicht nach einem bestimmten Zeichen an einer bestimmten Koordinate; sie sucht nach dem "Konzept" einer Summe. Wenn Sie eine Aufgabe zur Aufteilung von Text in Spalten für ein Hauptbuch durchführen, stoßen Sie möglicherweise auf Zellen, die sowohl einen Kontocode als auch einen Kontonamen enthalten (z. B. "1001-Kasse"). Eine Regex könnte dies leicht am Bindestrich aufteilen. Aber was ist, wenn der Kontoname selbst einen Bindestrich enthält? Eine Standardaufteilung würde drei Spalten anstelle von zwei erstellen. Die KI-Datenextraktion versteht den Kontext und weiß, dass "Kasse" der Name ist, auch wenn er ungewöhnliche Zeichen enthält. Dies reduziert die Notwendigkeit einer ständigen "Regex-Optimierung" und senkt die technische Hürde für die Bereinigung von Finanzdaten. Darüber hinaus kann die automatische Tabellenanalyse mit KI das "Unteilbare" bewältigen. Betrachten Sie eine Tabelle, bei der die Zeilen nicht sauber durch Linien, sondern durch Leerzeichen und Schriftgröße getrennt sind. Komplexe OCR-Verarbeitung kann diese visuellen Hinweise erkennen, um zu bestimmen, wo eine Spalte endet und die nächste beginnt. Dies ist Konvertierung strukturierter Daten auf höchstem Niveau. Während Regex für sehr einfache, schnelle Aufgaben immer noch seinen Platz hat, sollte das moderne Unternehmen für alle variablen, komplexen oder risikoreichen Daten auf die KI-Datenextraktion setzen. Allein die Kosteneinsparungen bei der Entwicklerzeit machen die KI zum klaren Gewinner.Zukunftssichere Datenstrategie mit Webhooks und API
Um Text in Spalten aufteilen wirklich zu meistern, müssen Sie über die Tabellenkalkulation hinausblicken. Die Zukunft des automatisierten Tabellenparsens ist integriert und in Echtzeit. Durch die Nutzung von Webhooks können Sie eine Datenpipeline erstellen, bei der in dem Moment, in dem ein Dokument in einen Cloud-Speicherordner hochgeladen wird, die KI-Datenextraktion-Engine greift, die strukturelle Datenkonvertierung durchführt und die bereinigten Daten in Ihre Datenbank pusht. Es ist kein manuelles Herunter- oder Hochladen erforderlich. Dies ist der Gipfel der Effizienz.
Ein API-first-Ansatz zur Bereinigung von Finanzdaten ermöglicht es Ihrer bestehenden Software, nach strukturierten Daten zu "fragen". Zum Beispiel kann Ihre Abgleichs-Software eine rohe PDF-Datei an einen API-Endpunkt senden und im Gegenzug ein perfekt formatiertes JSON-Objekt erhalten, bei dem die gesamte Logik für Text in Spalten aufteilen bereits angewendet wurde. Dies eliminiert den "Tabellenkalkulations-Mittelsmann" und reduziert das Risiko von Datenbeschädigung. Für Entwickler bedeutet dies, dass sie komplexe Funktionen auf Basis sauberer Daten erstellen können, ohne sich um die zugrunde liegende komplexe OCR-Verarbeitung oder Tabellenextraktionslogik kümmern zu müssen.
Betrachten Sie schließlich die Aspekte Vertrauen und Sicherheit. Automatisierte Pipelines mit Webhooks reduzieren die Anzahl der Personen, die Zugriff auf rohe, sensible Daten haben. Die KI-Datenextraktion erfolgt in einer sicheren Umgebung, und die strukturierte Ausgabe wird direkt an das Zielsystem geliefert. Dies passt perfekt zu SOC2-Compliance-Frameworks, da es die Angriffsfläche für Datenlecks minimiert. Indem Sie Ihre Datenstrategie mit diesen Tools zukunftssicher machen, lösen Sie nicht nur das heutige Problem des Text in Spalten aufteilen, sondern bauen auch eine skalierbare Grundlage für das nächste Jahrzehnt der digitalen Transformation.
Häufig gestellte Fragen (FAQ)
F1: Wie verarbeitet die KI verschiedene Datumsformate während einer Aufteilung?
Wenn Sie eine Text in Spalten aufteilen-Operation mit KI-Datenextraktion durchführen, schneidet das System den Text nicht einfach, sondern identifiziert den Datentyp. Wenn eine Zeile "MM/TT/JJJJ" und eine andere "TT-Mon-JJ" enthält, kann die automatisierte Tabellenanalyse-Engine beide während der strukturellen Datenkonvertierung in ein konsistentes Format normalisieren. Beispielsweise kann sie bei der Abstimmung eines Hauptbuchs alle Daten automatisch in das Standard-ISO-Format konvertieren. Dies verhindert Fehler bei Ihrer Bereinigung von Finanzdaten, die normalerweise auftreten würden, wenn Sie einfach einen einfachen Textaufteilungsassistenten verwenden würden, der die Datumslogik nicht versteht.
F2: Kann ich Text aufteilen, der sich in einer einzelnen Zelle über mehrere Zeilen erstreckt?
Ja, dies ist einer der größten Vorteile der KI-Datenextraktion gegenüber herkömmlichen Werkzeugen. Einfache Excel-Assistenten scheitern oft, wenn sich eine einzelne Datenzeile über mehrere physische Zeilen in einer PDF-Datei oder einem Bild erstreckt. Komplexe OCR-Verarbeitung kann die visuellen Grenzen einer Tabellenzeile erkennen und den mehrzeiligen Text als eine einzige Entität behandeln, bevor die Logik für das Aufteilen von Text in Spalten angewendet wird. Dies ist unerlässlich für die Bereinigung von Finanzdaten, bei der Rechnungsbeschreibungen oft lang sind und sich über mehrere Zeilen erstrecken, um sicherzustellen, dass Ihre Mengen und Preise immer mit dem richtigen Artikel übereinstimmen.
F3: Was passiert, wenn das Trennzeichen in einigen Zeilen fehlt?
In einem herkömmlichen Workflow zum Aufteilen von Text in Spalten führt ein fehlendes Trennzeichen dazu, dass sich die Daten verschieben, was den gesamten Datensatz ruiniert. Die automatisierte Tabellenanalyse mit KI verlässt sich jedoch nicht ausschließlich auf Trennzeichen. Sie verwendet räumlichen und semantischen Kontext. Wenn ein Komma fehlt, das System aber einen deutlichen Abstand und eine Änderung des Datentyps (z. B. von Text zu Währung) erkennt, wird die Aufteilung trotzdem korrekt durchgeführt. Dies verhindert das Problem der "leeren Werte" und stellt sicher, dass Ihre strukturelle Datenkonvertierung auch bei unvollständigen Quelldateien korrekt bleibt, was ein häufiges Szenario bei der komplexen OCR-Verarbeitung ist.
F4: Ist es möglich, Spalten ohne Code aufzuteilen?
Absolut. Tools wie TabliSync sind für Geschäftsanwender konzipiert, die KI-Datenextraktion benötigen, ohne Regex- oder Python-Skripte schreiben zu müssen. Sie weisen das System einfach auf die Tabelle hin, und die automatisierte Tabellenanalyse-Engine erledigt die Hauptarbeit. Dies demokratisiert die strukturelle Datenkonvertierung und ermöglicht es Buchhaltern und Betriebsleitern, ihre eigene Bereinigung von Finanzdaten durchzuführen. Durch die Beseitigung des technischen Engpasses können Unternehmen die Effizienz steigern und ihre IT-Teams entlasten, damit sie sich auf übergeordnete Integrationsaufgaben konzentrieren können, während die Geschäftsanwender die Datenqualität selbst verwalten.
F5: Wie sicher sind meine Finanzdaten während des Extraktionsprozesses?
Sicherheit hat oberste Priorität, insbesondere bei der Bereinigung von Finanzdaten. Professionelle Plattformen für die KI-Datenextraktion wie TabliSync sind mit Blick auf die SOC2-Konformität konzipiert. Das bedeutet, dass die Daten im Ruhezustand und während der Übertragung verschlüsselt sind. Im Gegensatz zu manuellen Aufgaben wie dem Aufteilen von Text in Spalten, die auf unsicheren lokalen Rechnern stattfinden können, erfolgt die automatisierte strukturelle Datenkonvertierung in einer kontrollierten Cloud-Umgebung. Dies gewährleistet Vertrauen und hilft Unternehmen, gesetzliche und behördliche Anforderungen bei der Verarbeitung sensibler Hauptbuch- oder Kundeninformationen während des Lebenszyklus der automatisierten Tabellenanalyse zu erfüllen.
F6: Kann dies Tabellen in handschriftlichen Dokumenten verarbeiten?
Moderne komplexe OCR-Verarbeitung hat erhebliche Fortschritte bei der Erkennung von Handschriften gemacht. Obwohl es schwieriger ist als gedruckter Text, kann die KI-Datenextraktion oft Tabellenstrukturen in handschriftlichen Notizen oder Formularen identifizieren. Die automatisierte Tabellenanalyse-Engine sucht nach der relativen Position von Text, um die Spalten abzuleiten. Obwohl die Genauigkeit etwas geringer sein kann als bei digitalen PDFs, bietet sie dennoch einen enormen Vorsprung für die strukturelle Datenkonvertierung. Für die Bereinigung von Finanzdaten aus alten Papierunterlagen kann dies Tausende von Stunden manueller Dateneingabe und Transkriptionsarbeit einsparen.
F7: Was ist ein Webhook und wie hilft er beim Aufteilen von Spalten?
Ein Webhook ist eine Methode, mit der eine Anwendung Echtzeitdaten an eine andere sendet, sobald ein Ereignis eintritt. Im Kontext der automatisierten Tabellenanalyse können Sie einen Webhook so einrichten, dass die strukturierten Daten, sobald die KI-Datenextraktion einen Text in Spalten aufteilen-Auftrag abgeschlossen hat, automatisch an Ihre ERP- oder Abgleich-Software gesendet werden. Dies entfällt den manuellen Schritt des Exports einer CSV-Datei und des Hochladens an anderer Stelle, was die Effizienz Ihrer gesamten Datenpipeline erheblich steigert und sicherstellt, dass Ihre Bereinigung von Finanzdaten stets auf dem neuesten Stand ist.
F8: Wie verarbeitet das System sehr große Tabellen mit Tausenden von Zeilen?
Die KI-Datenextraktion ist auf Skalierbarkeit ausgelegt. Im Gegensatz zu einem manuellen Prozess, der bei steigendem Volumen langsamer wird, kann die automatisierte Tabellenanalyse Tausende von Zeilen in Sekundenschnelle verarbeiten. Die Logik der strukturellen Datenkonvertierung wird konsistent auf den gesamten Datensatz angewendet, sodass die erste und die 10.000. Zeile mit dem gleichen Maß an Präzision behandelt werden. Dies ist entscheidend für die Bereinigung von Finanzdaten in großen Unternehmen, wo Hauptbuch-Exporte massiv sein können. Die Verwendung eines automatisierten Systems stellt sicher, dass Sie bei wachsendem Datenbedarf keine Effizienz verlieren.
F9: Kann ich die Kopfzeilen nach dem Aufteilen anpassen?
Ja, während der Konfiguration der automatisierten Tabellenanalyse können Sie genau definieren, wie die Ausgabekopfzeilen aussehen sollen. Selbst wenn das Originaldokument unordentliche oder nicht beschreibende Kopfzeilen hat, kann die KI-Datenextraktion diese auf Ihr standardisiertes internes Format abbilden. Dies ist ein wichtiger Teil der strukturellen Datenkonvertierung, da es sicherstellt, dass die Daten für die sofortige Verwendung in Ihren Abgleich- oder BI-Tools bereit sind. Das Anpassen von Kopfzeilen während des Aufteilungsprozesses ist eine bewährte Methode für die Bereinigung von Finanzdaten, da es die Konsistenz über verschiedene Datenquellen und Anbieter hinweg gewährleistet.
F10: Was ist der Kostenunterschied zwischen manuellem und KI-gestütztem Aufteilen?
Die Kosteneinsparungen sind in der Regel beträchtlich. Manuelle Aufgaben zur Textaufteilung in Spalten sind nicht nur langsam, sondern auch fehleranfällig und kostspielig. Wenn man den Stundenlohn eines erfahrenen Finanzanalysten berücksichtigt, können die Kosten für die manuelle Bereinigung von Finanzdaten 10- bis 50-mal höher sein als bei der Verwendung einer automatisierten Tabellenanalyse-Lösung. KI-Datenextraktion bietet feste, vorhersehbare Kosten pro Dokument oder pro Zeile, was die Budgetierung erleichtert und es Ihnen ermöglicht, Ihre strukturellen Datenkonvertierungs-Operationen zu skalieren, ohne dass die Mitarbeiterzahl linear ansteigt, was zu einem deutlich höheren ROI führt.
Hören Sie auf, mit Ihren Daten zu kämpfen – fangen Sie an, sie zu synchronisieren
Die Zeiten des Kampfes mit fehlerhaften Assistenten zur Textaufteilung in Spalten und schlecht ausgerichteten Hauptbuch-Exporten sind vorbei. Sie kennen die Daten: Manuelle Bereinigung ist eine Belastung für Ihre Effizienz, ein Risiko für Ihr Vertrauen und eine massive Verschwendung von Kapital. Jede Minute, die Ihr Team mit der manuellen Korrektur von Fehlern bei der strukturellen Datenkonvertierung verbringt, ist eine Minute, die es nicht für hochwertige Analysen oder strategisches Wachstum nutzen kann. Die Kluft zwischen Unternehmen, die KI-Datenextraktion nutzen, und denen, die es nicht tun, wird jeden Tag größer.
Lassen Sie nicht zu, dass ein weiterer Monatsabschluss zu einem Abstimmungs-Albtraum wird, der durch fehlerhafte komplexe OCR-Verarbeitung verursacht wird. TabliSync ist die ultimative Waffe für die Bereinigung von Finanzdaten, entwickelt, um die unordentlichen, verschachtelten und unstrukturierten Tabellen zu verarbeiten, die andere Tools nicht bewältigen können. Wir bieten die Präzision der automatisierten Tabellenanalyse mit der Sicherheit der SOC2-Konformität und stellen sicher, dass Ihre Datenpipeline ebenso robust wie schnell ist. Dies ist Ihre Chance, Ihre Zeit zurückzugewinnen und 100%ige Genauigkeit in Ihren Datenworkflows zu gewährleisten.
Erleben Sie noch heute die Leistungsfähigkeit von TabliSync. Für eine begrenzte Zeit können Sie sich für eine kostenlose Testversion anmelden und genau sehen, wie unsere KI-Datenextraktion Ihre unordentlichsten Tabellen in Sekundenschnelle in perfekt strukturierte Assets verwandeln kann. Klicken Sie auf den unten stehenden Link, um loszulegen – lassen Sie sich nicht länger von manueller Dateneingabe zurückhalten. Die Zukunft der strukturellen Datenkonvertierung ist da und nur einen Klick entfernt.
[TabliSync jetzt kostenlos ausprobieren]
Was ist Text in komplexen Tabellen in Spalten aufteilen?
Kurze Antworten zu Text in komplexen Tabellen in Spalten aufteilen und wie TabliSync Teams in Excel beschleunigt.
Was ist Text in komplexen Tabellen in Spalten aufteilen?
Text in komplexen Tabellen in Spalten aufteilen umfasst praktische Excel-Workflows, typische Fehler und Automatisierungsmuster. Dieser TabliSync-Guide erklärt das Konzept, zeigt Beispiele und verlinkt Tutorials.
Wie kann TabliSync bei Text in komplexen Tabellen in Spalten aufteilen helfen?
TabliSync extrahiert Tabellen aus Screenshots oder PDFs, bereinigt unordentliche Daten und automatisiert repetitive Excel-Aufgaben zu Text in komplexen Tabellen in Spalten aufteilen.
Wo starte ich mit Text in komplexen Tabellen in Spalten aufteilen?
Beginnen Sie mit der Übersicht auf dieser Seite und öffnen Sie dann die verlinkten Artikel für Schritt-für-Schritt-Anleitungen und KI-Workflows.

Schluss mit manueller Dateneingabe – Tabellen in Sekunden extrahieren
Konvertieren Sie jedes Bild oder PDF-Tabelle sofort in Excel mit 99,9% Genauigkeit. TabliSyncs KI-gestützte OCR verarbeitet handschriftliche Formulare, Belege und komplexe Tabellen und synchronisiert direkt mit Google Sheets, Notion oder Airtable
Probieren Sie TabliSync jetzt kostenlos aus