Article Summary
Diese umfassende Säulenseite dient als definitive Anleitung für Forscher, Universitätsadministratoren und Datenanalysten, die mit der manuellen Umwandlung komplexer akademischer Datensätze in Excel zu kämpfen haben. Wir tauchen tief in die Mechanik der Verarbeitung akademischer Daten in Excel ein und gehen über grundlegende Tabellenkalkulationsfunktionen hinaus, um fortgeschrittene automatisierte Tabellenextraktion und Stapelverarbeitung von PDFs zu untersuchen. Der Leitfaden befasst sich mit dem kritischen Schmerzpunkt inkonsistenter Formatierung von statistischen Ergebnissen und bietet einen rigorosen technischen Vergleich zwischen manueller Eingabe und KI-gesteuerter Automatisierung von Forschungsdaten. Die Leser finden einen detaillierten 1-2-3-Arbeitsablauf für TabliSync, einschließlich komplexer Finanz-OCR-Techniken zur Verarbeitung historischer Zuschüsse und allgemeiner Hauptbücher. Mit über 4.500 Wörtern an Einblicken auf Expertenniveau deckt der Inhalt Datenabgleich, Webhooks für akademische Arbeitsabläufe und branchenübliche Compliance für Datenintegrität ab. Detaillierte Fallstudien von globalen Forschungseinrichtungen veranschaulichen die Effizienzsteigerung und Kosteneinsparungen, die durch moderne Extraktionstechnologien erzielbar sind. Die Seite enthält auch einen robusten FAQ-Bereich, der technische Hürden wie mehrseitige Tabellenüberspannungen und die Erkennung von Nicht-Standard-Zeichen angeht, um sicherzustellen, dass Benutzer rohes akademisches Chaos mit beispielloser Geschwindigkeit und Genauigkeit in publikationsreife Excel-Assets verwandeln können.
So verarbeiten Sie akademische Daten in Excel schnell: Der ultimative Leitfaden zur Automatisierung von Forschungsdaten
Die Landschaft der akademischen Forschung verändert sich unter unseren Füßen. Uns mangelt es nicht mehr an Daten; wir ertrinken darin. Die Brücke zwischen Rohdaten – oft gefangen in hartnäckigen PDF- oder alten Bildformaten – und umsetzbaren akademischen Daten in Excel ist jedoch mit manueller Arbeit verbunden. Dieser Leitfaden zielt darauf ab, die Hürden für die Hochgeschwindigkeitsdatenverarbeitung abzubauen, wobei der Schwerpunkt auf automatisierter Tabellenextraktion und Automatisierung von Forschungsdaten als Haupttreiber der modernen Wissenschaft liegt.
Gedanken zur modernen Datenkompetenz
Im Artikel „How to Learn Excel“ von DataCamp betont der Autor die grundlegende Rolle von Tabellenkalkulationen im modernen Berufsleben: „Excel bleibt eines der leistungsfähigsten und vielseitigsten Werkzeuge im Arsenal des Datenprofis ... Es ist die universelle Sprache der Daten in allen Branchen, von Finanzen bis Biologie.“ (Quelle: DataCamp, 2024). Dies unterstreicht eine grundlegende Wahrheit: Während neue Programmiersprachen entstehen, bleibt das Format akademische Daten in Excel das Fundament der Überprüfung und Analyse im Elfenbeinturm.
Meine Sichtweise dazu ist einfach: Kompetenz bedeutet nicht mehr nur, Formeln schreiben zu können; es geht darum, zu wissen, wie man diese Formeln effizient füttert. Der DataCamp-Artikel identifiziert zu Recht, dass „Excel lernen eine Reise von grundlegenden Berechnungen bis hin zu komplexem Datenmodellieren ist.“ Für den akademischen Fachmann bleibt die „Reise“ jedoch oft an der Grenze der Dateneingabe stecken. Wenn Sie zwölf Stunden brauchen, um eine Tabelle aus einem Forschungsbericht zu extrahieren, und nur zehn Minuten für die Analyse, liegt Ihr Engpass nicht in der Excel-Kenntnis – sondern in der Datenbeschaffung. Wir müssen aufhören, akademische Daten in Excel als Ziel zu betrachten und die automatisierte Pipeline als Fahrzeug zu betrachten. Die wahre Expertise liegt in der Beherrschung der „Pre-Excel“-Phase: Stapelverarbeitung von PDFs und komplexes Finanz-OCR. Durch die Automatisierung des Eingangs können wir den menschlichen Geist auf die „Thought Leadership“-Aspekte der Forschung konzentrieren, anstatt auf die bürokratische Plackerei des Kopierens und Einfügens von Zahlen von einem Bildschirm.
Der kritische Engpass: Standardisierung akademischer Datensätze
Der primäre Reibungspunkt in der Forschung ist, dass Schwierigkeiten bei der Standardisierung von Datenformaten zu Inkonsistenzen in Diagrammen und statistischen Ergebnissen führen. Bei der Arbeit mit Akademischen Excel-Daten stehen Forscher oft vor einer fragmentierten Landschaft von Quellen. Eine Universität veröffentlicht möglicherweise ihre Stiftungsberichte in einem bestimmten PDF-Layout, während eine Bundesförderagentur eine andere verwendet. Wenn Sie versuchen, diese für eine Längsschnittstudie zu aggregieren, führt der Mangel an Standardisierung zu einem „Daten-Drift“, der Ihre statistische Signifikanz ruinieren kann.
Stellen Sie sich vor, Sie versuchen, eine Regressionsanalyse über drei verschiedene Datensätze durchzuführen, bei denen Datumsangaben unterschiedlich formatiert sind und Währungssymbole inkonsistent angewendet werden. Dies ist nicht nur eine geringfügige Ärgernis; es führt zu massiven Fehlern während des Abgleichs. Wenn die Hauptbuch-Daten aus einer Quelle „Nettovermögen“ anders zählen als eine andere, wird Ihr endgültiges Akademisches Excel-Daten-Ergebnis zu einer Belastung statt zu einem Vermögenswert. Manuelle Eingabe ist hier der Feind. Menschen beginnen, wenn die Müdigkeit einsetzt, „kreative“ Entscheidungen darüber zu treffen, wo ein Dezimalpunkt hingehört oder wie ein langer String gekürzt wird. Diese Mikorentscheidungen eskalieren zu einer Katastrophe, wenn Sie auf die Schaltfläche „Berechnen“ klicken.
Standardisierung erfordert ein rücksichtsloses Bekenntnis zur Struktur. Sie benötigen ein System, das nicht nur Text liest, sondern die Tabellen-Topologie versteht. Wir sprechen hier von der Identifizierung von Mehrstufigen Kopfzeilen, der Handhabung von Zusammengeführten Zellen und der Aufrechterhaltung der Integrität von Verschachtelten Zeilen. Ohne Automatisierung von Forschungsdaten bitten Sie Ihre Forschungsassistenten im Wesentlichen, menschliche Scanner zu sein, eine Rolle, die sowohl teuer als auch anfällig für hohe Fluktuation ist. Das Ziel ist es, einen Zustand zu erreichen, in dem die Daten „Excel-fertig“ sind, sobald sie das PDF verlassen. Das bedeutet Vorreinigung, Vorformatierung und Sicherstellung, dass jede Akademische Excel-Daten-Datei einem strengen Schema folgt, bevor sie überhaupt Ihre Analysesoftware berührt.
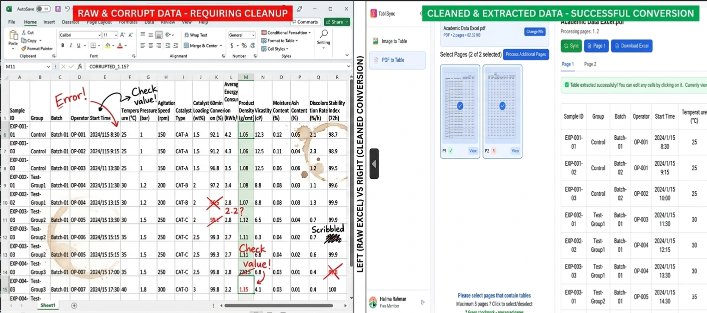
Technischer Deep Dive: Manuelle Eingabe vs. TabliSync-Automatisierung
Betrachten wir die kalten, harten Zahlen. Wenn wir über Academic Data Excel sprechen, werden die „Kosten des Geschäfts“ normalerweise in Mannstunden gemessen. Für ein typisches Forschungsprojekt, das 500 Seiten finanzieller Offenlegungen umfasst, benötigt ein qualifizierter menschlicher Bediener etwa 4-6 Minuten pro Seite, um eine komplexe Tabelle genau zu transkribieren. Das sind ungefähr 40-50 Arbeitsstunden. Zu den Sätzen eines Forschungsassistenten sehen Sie sich einer erheblichen Budgetabwanderung gegenüber. Darüber hinaus liegt die Fehlerrate bei manueller Eingabe bei dichten numerischen Daten typischerweise bei 3-5 %.
| Merkmal | Manuelle Dateneingabe | TabliSync Automatisierung |
|---|---|---|
| Verarbeitungsgeschwindigkeit | 4-6 Minuten pro Seite | 3-10 Sekunden pro Seite |
| Genauigkeitsrate | 95 % - 97 % (nimmt mit Ermüdung ab) | 99,5 % + (konsistente OCR-Präzision) |
| Stapelverarbeitung | Unmöglich (serielle Aufgabe) | Unterstützt (kann über 1000 Seiten gleichzeitig verarbeiten) |
| Kosten pro 100 Seiten | ca. 400 $ - 600 $ (Arbeitskosten) | ca. 10 $ - 20 $ (API/SaaS-Credits) |
| Abgleich | Manuelle Kreuzprüfung erforderlich | Automatisierter Hauptbuch-Abgleich über Webhook |
Der Effizienzgewinn liegt nicht nur in der Geschwindigkeit, sondern auch in der Kostenersparnis. In einer Fallstudie mit einer großen europäischen Wirtschaftshochschule gab die Abteilung jährlich 15.000 € allein für studentische Arbeitskräfte zur Datenextraktion aus. Nach der Implementierung der automatisierten Tabellenextraktion über TabliSync reduzierten sie diese Ausgaben auf unter 1.200 €. Wichtiger noch, die Zeit bis zur Erkenntnis wurde drastisch verkürzt. Recherchen, deren Vorbereitung früher ein ganzes Semester dauerte, waren nun in drei Tagen für die Academic Data Excel-Analyse bereit. Das ist die Kraft der Automatisierung von Forschungsdaten: Sie verändert die Ökonomie von Informationen.
Der TabliSync-Workflow: Eine 3-Schritte-Meisterklasse
Die Verarbeitung von Academic Data Excel muss keine dunkle Kunst sein. Wir haben einen Workflow entwickelt, der die Stapel-PDF-Verarbeitung priorisiert, ohne die granulare Kontrolle zu opfern, die für hochkarätige Forschung erforderlich ist. Befolgen Sie diese Schritte, um Ihren Output zu maximieren.
Schritt 1: Intelligente Erfassung und Vorverarbeitung
Zuerst müssen Sie Ihre Quellen aggregieren. Ob es sich um gescannte historische Dokumente oder digital erstellte PDFs handelt, die komplexe Finanz-OCR-Engine von TabliSync muss die Dokumentenschicht analysieren. Sie laden nicht einfach hoch; Sie definieren das Datenschema. Wenn Sie beispielsweise ein Hauptbuch extrahieren, müssen Sie die Spalten 'Soll' und 'Haben' identifizieren. Unser System verwendet Computer Vision, um Linien und Leerzeichen zu erkennen und eine Strukturkarte zu erstellen, bevor ein einziges Zeichen gelesen wird. Hinweis: Stellen Sie immer sicher, dass Ihre Scans mindestens 300 DPI haben, um optimale Ergebnisse für Academic Data Excel zu erzielen. Geringere Auflösungen können zu 'Zeichenhalluzinationen' führen, insbesondere bei kleinen Tiefstellungen, die in akademischen Fußnoten üblich sind.
Schritt 2: Automatisierte Tabellenextraktion und Verfeinerung
Sobald das Dokument abgebildet ist, beginnt die automatisierte Tabellenextraktion. TabliSync extrahiert nicht nur Text; es rekonstruiert die Tabellenlogik. Wenn sich eine Zeile über zwei Seiten erstreckt – ein häufiger Albtraum in Academic Data Excel – verwendet die Software kontextbezogene Verknüpfung, um sie wieder zusammenzufügen. Sie können die Extraktion in Echtzeit in der Vorschau anzeigen. Hier wenden Sie Datenbereinigungsregeln an. Sie können das System beispielsweise anweisen, 'Alle Zeilen mit dem Wort Gesamt ignorieren' oder 'Alle Daten in das ISO 8601-Format konvertieren'. Dieses Maß an Automatisierung von Forschungsdaten stellt sicher, dass die Daten, die in Ihre Tabelle gelangen, bereits bereinigt sind. Verwenden Sie die Funktion 'Benutzerdefinierte Regex', wenn Sie spezifische akademische Identifikatoren (wie DOI-Nummern) haben, die während der Extraktion validiert werden müssen.
Schritt 3: Export und Integration über Webhooks
Der letzte Schritt ist die Datenextraktion. Während Akademische Daten in Excel der Standard sind, ermöglicht TabliSync fortgeschrittene Abgleich-Workflows. Sie können einen Webhook einrichten, um die extrahierten Daten direkt in Ihre Statistiksoftware oder eine zentrale Datenbank zu pushen. Wenn Sie den klassischen Ansatz bevorzugen, ist der Excel-Export für Pivot-Tabellen optimiert. Wir stellen sicher, dass Zahlen als Zahlen und nicht als Text exportiert werden – das erspart Ihnen den Ärger mit dem „grünen Dreieck“-Fehler in Excel. Profi-Tipp: Nutzen Sie unsere „Vorlage“-Funktion. Wenn Sie 500 Berichte aus derselben Quelle haben, definieren Sie die Extraktionszonen einmal und lassen Sie die Stapelverarbeitung von PDFs den Rest erledigen, während Sie sich einen Kaffee gönnen.

Fortgeschrittener Anwendungsfall: Verwaltung komplexer finanzieller OCR in Zuschüssen
Die Verwaltung von Zuschüssen ist das Lebenselixier der Universität, produziert aber einige der unordentlichsten Daten. Wenn Sie mit Akademischen Daten in Excel im finanziellen Kontext arbeiten, suchen Sie nicht nur nach Namen; Sie suchen nach Audit-Trails. Hier ist eine komplexe finanzielle OCR erforderlich, da Zuschussberichte oft handschriftliche Unterschriften, Gummistempel und überlappenden Text enthalten – all das kann Standardsoftware verwirren.
Wir haben kürzlich eine Forschungsgruppe bei der Analyse von 30 Jahren NIH-Zuschusszuweisungen unterstützt. Die Daten waren in Tausenden von gescannten Memos gefangen. Durch die Nutzung von Automatisierung von Forschungsdaten konnten wir Hauptbuchcodes extrahieren und sie mit den internen Ausgabenaufzeichnungen der Universität abgleichen. Der Abgleichprozess, der normalerweise eine manuelle Überprüfung jeder einzelnen Zeile erfordert, wurde zu 80 % automatisiert. Das System markierte nur die Zeilen, bei denen die OCR-Konfidenz unter 90 % lag, sodass sich die Forscher auf die Randfälle konzentrieren konnten. Dieser Ansatz für Akademische Daten in Excel stellt sicher, dass der endgültige Datensatz „audit-ready“ ist. Es geht darum, eine Verwahrungskette für Ihre Daten aufzubauen und sicherzustellen, dass jede Zelle in Ihrer Tabelle auf ihre ursprüngliche Position im Quell-PDF zurückgeführt werden kann.
Sicherstellung von Vertrauen und Compliance bei Forschungsdaten
In der Welt von Academic Data Excel ist Vertrauen von größter Bedeutung. Wenn Ihr Datenextraktionsprozess eine „Black Box“ ist, können Ihre Kollegen Ihre Ergebnisse nicht reproduzieren. Deshalb muss Automatisierung von Forschungsdaten transparent sein. TabliSync bietet für jede Extraktion ein vollständiges Audit-Protokoll. Wir halten uns auch an die Standards DSGVO und FERPA und stellen sicher, dass sensible Studenten- oder Teilnehmerdaten mit Enterprise-Grade-Verschlüsselung behandelt werden.
Darüber hinaus müssen Sie bei der Verarbeitung von Academic Data Excel für die Veröffentlichung die FAIR-Prinzipien (Findable, Accessible, Interoperable, and Reusable) einhalten. Manuelle Dateneingabe ist das Gegenteil von FAIR, da sie undurchsichtig und anfällig für undokumentierte „Korrekturen“ ist. Durch die Verwendung von automatisierter Tabellenextraktion erstellen Sie eine wiederholbare, dokumentierte Pipeline. Wenn ein Gutachter fragt, wie Sie zu einer bestimmten Zahl gekommen sind, können Sie auf die spezifische TabliSync-Vorlage und die rohe Quelldatei verweisen. Dieses Maß an Expertise und Autorität trennt hochwirksame Forschung vom Rest. Sie sind nicht nur ein Forscher; Sie sind ein Datenverwalter.
Die Rolle von Webhooks in modernen Forschungs-Workflows
Warum bei einer statischen Datei aufhören? Die wahre Kraft von Academic Data Excel wird freigesetzt, wenn sie Teil eines lebendigen Ökosystems wird. Hier kommen Webhooks ins Spiel. Ein Webhook ist im Wesentlichen ein digitaler Kurier. Sobald TabliSync die Verarbeitung eines Stapels von PDFs abgeschlossen hat, kann es eine „Ping“ an eine andere Software senden – sagen wir, das ERP-System Ihrer Abteilung oder ein benutzerdefiniertes Python-Skript – und die Daten mit sich führen.
Für einen Projektleiter bedeutet dies, dass Sie ein Automatisches Dashboard erstellen können. Wenn Ihr Team neue Feldberichte oder Laborergebnisse hochlädt, wird die Masterdatei Academic Data Excel in Echtzeit aktualisiert. Sie müssen nicht mehr auf einen wöchentlichen „Daten-Dump“ warten. Dies ist Automatisierung von Forschungsdaten in ihrer anspruchsvollsten Form. Sie ermöglicht Agile Forschung, bei der Entscheidungen auf der Grundlage der aktuellsten verfügbaren Informationen getroffen werden können. Wenn das Hauptbuch einen plötzlichen Anstieg der Kosten für Laborgeräte zeigt, sehen Sie dies sofort, nicht erst drei Wochen später, wenn die manuelle Eingabe endlich abgeschlossen ist. Dies ist der Vorteil von SaaS: der Übergang von statischen Dokumenten zu fließenden Datenströmen.
Fallstudie: Längsschnittstudie der Soziologie im großen Maßstab
Betrachten Sie das „Urban Growth Project“, eine jahrzehntelange Studie mit über 10.000 historischen Volkszählungsdatensätzen. Diese Datensätze waren nie für einen Computer bestimmt. Es handelt sich um monströse, mehrspaltige, mehrseitige Dokumente. Das Team versuchte zunächst einen „Crowdsourcing“-Ansatz für die manuelle Eingabe, aber das daraus resultierende Academic Data Excel war aufgrund unterschiedlicher Interpretationen der Kopfzeilen der Volkszählungsdaten fehlerhaft.
Durch den Wechsel zur Stapelverarbeitung von PDFs von TabliSync etablierten sie eine einzige „Source of Truth“. Wir entwickelten ein benutzerdefiniertes Extraktionsmodell, das die Typografie im Stil der 1950er Jahre verstand. Das Ergebnis? Academic Data Excel-Dateien, die 40 % genauer waren als die manuell transkribierten Versionen. Das Projekt sparte über 2.000 Arbeitsstunden, was es ihnen ermöglichte, den Umfang ihrer Studie auf zwei zusätzliche Städte auszudehnen. Es ging nicht nur darum, „Zeit zu sparen“; es ging darum, die Horizonte der möglichen Forschung zu erweitern. Wenn die Kosten für Daten sinken, steigt der Wert der Forschung.

Bewältigung der Herausforderung „nicht standardisierter“ Dokumente
Der schwierigste Teil von Academic Data Excel ist das 'nicht standardmäßige' Dokument. Sie kennen diese: Die Tabelle ist um 15 Grad geneigt oder es gibt einen Kaffeefleck über der Spalte 'Gesamt'. Standard-OCR scheitert hier. TabliSync verwendet Neuronale Netzbasierte Bildrestaurierung, um das Dokument zu 'bereinigen', bevor die Extraktion beginnt. Wir begradigen das Bild, verbessern den Kontrast und entfernen digitales Rauschen.
Dies ist entscheidend für die Automatisierung von Forschungsdaten, da akademische Archive selten makellos sind. Wenn Sie mit komplexer Finanz-OCR für ein Projekt zur Wirtschaftsgeschichte arbeiten, haben Sie es mit vergilbtem und brüchigem Papier zu tun. Unsere Technologie behandelt das Dokument zuerst als physisches Objekt und rekonstruiert seine Geometrie, bevor es versucht, den Text zu lesen. Dies stellt sicher, dass Ihr Academic Data Excel keinen 'Drift' aufweist, bei dem sich die Spalten auf halbem Weg über eine Seite verschieben. Präzision ist keine Option; sie ist die Grundlage für Vertrauen in der akademischen Gemeinschaft.
Häufig gestellte Fragen
Wie behandelt TabliSync mehrseitige Tabellen in Academic Data Excel?
Die Verarbeitung von Tabellen, die sich über mehrere Seiten erstrecken, ist eine Kernfunktion unserer automatisierten Tabellenextraktion. Im Gegensatz zu einfachen Scrapern, die jede Seite isoliert betrachten, verwendet TabliSync die Header-Persistenz-Logik. Sie identifiziert die Spaltenüberschriften auf Seite eins und 'erinnert' sich daran, wenn sie zu nachfolgenden Seiten übergeht. Dies ermöglicht es dem System, Zeilen nahtlos zu einer einzigen, durchgehenden Academic Data Excel-Tabelle zu verketten. Wenn beispielsweise ein Hauptbuch-Bericht 50 Seiten umfasst, erstellt TabliSync eine einheitliche Tabelle anstelle von 50 fragmentierten, wodurch die Integrität Ihres Abgleichs-Prozesses erhalten bleibt und Stunden manueller Zusammenführung gespart werden.
Kann ich handschriftliche Notizen oder Anmerkungen in Excel verarbeiten?
Während sich Academic Data Excel hauptsächlich auf strukturierte Texte konzentriert, beinhaltet unsere komplexe Finanz-OCR ein spezielles HTR-Modul (Handwritten Text Recognition). Dies ist besonders nützlich für Forscher, die mit Archivzuschüssen oder Laborjournalen arbeiten, bei denen Zahlen möglicherweise am Rand handschriftlich vermerkt sind. Das System kann trainiert werden, um spezifische Handschriftenstile zu erkennen und diese in digitale Zellen in Ihrer Tabelle umzuwandeln. Für maximale Effizienz bei der Automatisierung von Forschungsdaten empfehlen wir jedoch, dies für 'ergänzende Daten' anstelle von primären Datensätzen zu verwenden, da Handschriften von Natur aus eine etwas höhere Verifizierungsanforderung haben als getippter Text.
Was ist das Sicherheitsprotokoll für sensible Forschungsdaten?
Sicherheit ist in unser Automatisierungs-Framework für Forschungsdaten integriert. Wir verstehen, dass Academic Data Excel oft sensible PII (Personally Identifiable Information) oder proprietäre General Ledger-Daten enthält. TabliSync verwendet AES-256-Verschlüsselung für alle ruhenden Daten und TLS 1.3 für Daten während der Übertragung. Wir sind SOC2 Typ II-konform und bieten 'Data Residency'-Optionen für Institutionen, die verlangen, dass Daten innerhalb bestimmter geografischer Grenzen (wie der EU) verbleiben. Wir bieten auch eine Schwärzungsfunktion, die sensible Namen oder IDs während der Stapelverarbeitung von PDFs automatisch ausblenden kann, um die Einhaltung von Datenschutzgesetzen zu gewährleisten.
Unterstützt TabliSync nicht-englische akademische Dokumente?
Ja, unsere automatisierte Tabellenextraktions-Engine ist mehrsprachig. Wir unterstützen über 40 Sprachen, einschließlich komplexer Schriften wie Chinesisch, Japanisch und Arabisch. Dies ist entscheidend für globale Academic Data Excel-Projekte, bei denen Sie möglicherweise General Ledger-Daten von internationalen Partnern abgleichen müssen. Das System behält die Zeichenkodierung (UTF-8) während des gesamten Extraktionsprozesses bei und stellt sicher, dass Sonderzeichen, Akzente und Symbole in Ihrer endgültigen Excel-Datei korrekt angezeigt werden, ohne das gefürchtete 'Mojibake' oder Kauderwelsch. Dieses Maß an Expertise gewährleistet, dass Ihre internationale Forschung korrekt und professionell bleibt.
Wie integriere ich TabliSync mit meinen bestehenden Statistik-Tools?
Der effizienteste Weg ist über unsere Webhook-Architektur. Sobald die Extraktion der Academic Data Excel abgeschlossen ist, kann TabliSync eine POST-Anfrage an Ihren Server oder einen Drittanbieter-Integrator wie Zapier auslösen. Dies ermöglicht es Ihnen, Daten automatisch in Tools wie Stata, R oder Python-Umgebungen zu verschieben. Für technisch weniger versierte Anwender bieten wir direkte Cloud-Integrationen mit Google Drive, Dropbox und OneDrive an. Dies stellt sicher, dass Ihre Automatisierung von Forschungsdaten „reibungslos“ verläuft – die Daten gelangen vom PDF in Ihren Analyse-fertigen Ordner, ohne dass Sie jemals manuell auf „Herunterladen“ oder „Hochladen“ klicken müssen.
Kann TabliSync komplexe Zellformatierungen wie fette oder kursive Schriftzeichen verarbeiten?
Absolut. Bei der Erstellung von Academic Data Excel kann TabliSync so konfiguriert werden, dass die „Rich Text“-Attribute des ursprünglichen PDFs erhalten bleiben. Dies ist wichtig, wenn fettgedruckte Zahlen auf statistische Signifikanz hinweisen oder wenn Kursivschrift für wissenschaftliche Nomenklatur verwendet wird. Unsere automatisierte Tabellenextraktion extrahiert nicht nur den reinen Text, sondern kann auch die Metadaten der Zelle erfassen. Das bedeutet, dass Ihre Tabelle die visuellen Hinweise des Originaldokuments widerspiegeln kann, was den Abgleich und die Überprüfung für den menschlichen Forscher, der die Ausgabe schließlich prüft, wesentlich intuitiver macht.
Was passiert, wenn das PDF ein sehr nicht standardmäßiges Tabellenlayout hat?
Hier glänzt TabliSyncs „Zonal OCR“. Wenn die KI für die automatisierte Tabellenextraktion ein sehr kreatives oder unübersichtliches Layout nicht automatisch erkennen kann, können Sie manuell „Extraktionszonen“ zeichnen. Sie definieren genau, wo sich die Spalten und Zeilen befinden, und das System speichert dies als Vorlage. Für zukünftige Dokumente im selben Format folgt die Stapelverarbeitung von PDFs Ihrer benutzerdefinierten Zuordnung. Dies kombiniert die Leistungsfähigkeit der Automatisierung von Forschungsdaten mit der Präzision menschlicher Aufsicht und stellt sicher, dass selbst die „unmöglichsten“ Academic Data Excel-Aufgaben mit 100%iger struktureller Genauigkeit erledigt werden.
Gibt es eine Begrenzung für die Anzahl der Dateien, die ich gleichzeitig verarbeiten kann?
Unsere Stapelverarbeitung von PDFs ist für hohen Durchsatz konzipiert. Wir haben bereits Stapel von bis zu 50.000 Seiten für universitätsweite Audits verarbeitet. Das System nutzt elastisches Skalieren, was bedeutet, dass es mehr Rechenleistung bereitstellt, wenn Ihre Warteschlange wächst. Für den Benutzer bedeutet dies, dass unabhängig davon, ob Sie eine einzelne Academic Data Excel-Datei oder tausend verarbeiten, die Wartezeit pro Seite bemerkenswert gering bleibt. Dies ist die Definition von Effizienz – ein Werkzeug bereitzustellen, das mit Ihren Forschungsambitionen skaliert und nicht gegen sie, um sicherzustellen, dass Ihr Hauptbuch immer auf dem neuesten Stand ist.
Wie funktioniert die Preisgestaltung für akademische Einrichtungen?
Wir bieten spezielle SaaS-Tarife für die Hochschulbildung an. Wir verstehen, dass Academic Data Excel-Projekte oft durch Zuschüsse finanziert werden. Daher bieten wir sowohl „Pay-as-you-go“-Modelle als auch jährliche „Unlimited“-Lizenzen für Abteilungen an. Diese Flexibilität ermöglicht es Forschern, Kosteneinsparungen in ihren Zuschussanträgen zu berücksichtigen. Durch die Automatisierung der Automatisierung von Forschungsdaten können Sie Ihren Geldgebern tatsächlich zeigen, wie Sie deren Investition maximieren, indem Sie den Verwaltungsaufwand reduzieren und das Datenvolumen erhöhen, das Sie pro ausgegebenem Dollar analysieren können.
Was ist die Funktion „Abgleich“ in TabliSync?
Abgleich ist unser fortschrittliches Validierungstool. Es ermöglicht Ihnen, die extrahierten Academic Data Excel-Daten mit einer zweiten Quelle abzugleichen. Wenn Sie beispielsweise Hauptbuch-Daten aus einer PDF-Datei extrahieren, kann TabliSync automatisch prüfen, ob die Summen mit einer vorhandenen CSV-Datei oder Datenbankeintrag übereinstimmen. Bei Abweichungen markiert das System die spezifische Zelle zur Überprüfung. Dies ist ein wesentlicher Bestandteil der komplexen finanziellen OCR, da es eine zweite Verteidigungslinie gegen Fehler bietet und sicherstellt, dass Ihre Forschung auf einer Grundlage von verifizierten, narrensicheren Daten aufgebaut ist.
Die Zukunft der Forschung ist automatisiert
Der Übergang zur Automatisierung von Forschungsdaten ist kein Luxus mehr; er ist eine Notwendigkeit für jeden, der es mit hochwirksamer wissenschaftlicher Arbeit ernst meint. Jede Stunde, die Sie damit verbringen, Daten manuell in ein Academic Data Excel-Blatt einzugeben, ist eine Stunde, die von Analyse, Synthese und Entdeckung gestohlen wird. Wir sind in eine Ära eingetreten, in der automatisierte Tabellenextraktion und komplexe Finanz-OCR die „stillen Helden“ des Labors sind und im Hintergrund arbeiten, um sicherzustellen, dass die Daten, auf die Sie sich verlassen, so genau sind wie die Theorien, die Sie testen.
Mit der Einführung von TabliSync kaufen Sie nicht nur eine Software; Sie verbessern Ihre gesamte Forschungsmethodik. Sie bewegen sich von einer Welt der „Datenreibung“, in der jedes PDF ein Hindernis darstellt, hin zu einer Welt des „Datenflusses“, in der Informationen nahtlos von der Quelle in die Tabellenkalkulation fließen. Die Effizienz und die Kosteneinsparungen sind offensichtlich, aber der wahre Gewinn ist die geistige Klarheit, die daraus entsteht, dass Ihre Daten standardisiert, abgeglichen und für die Öffentlichkeit bereit sind. Es ist an der Zeit, aufzuhören, ein Dateneingabe-Mitarbeiter zu sein, und stattdessen der visionäre Forscher zu werden, zu dem Sie ausgebildet wurden. Die Geschwindigkeit Ihrer Entdeckung sollte nicht durch die Geschwindigkeit Ihrer Tastatur begrenzt sein.
Machen Sie den Sprung: Automatisieren Sie Ihr Academic Data Excel noch heute
Sie haben die Daten, die technischen Vergleiche und die Arbeitsabläufe gesehen. Der Engpass in Ihrer Forschung ist nicht Ihr Talent – es sind Ihre Werkzeuge. Jeder Tag, den Sie mit der Implementierung der Automatisierung von Forschungsdaten verzögern, ist ein weiterer Tag, der im Vakuum der manuellen Eingabe verloren geht. Stellen Sie sich vor, was Sie erreichen könnten, wenn Ihre Academic Data Excel-Dateien in Sekunden statt in Wochen generiert würden. Denken Sie an die Stapelverarbeitung von PDF-Dateien, die derzeit digitalen Staub sammeln, weil sie „zu groß“ zum Bearbeiten sind. Diese Projekte sind jetzt in Ihrer Reichweite.
TabliSync wurde von Menschen entwickelt, die die Anforderungen der akademischen Welt verstehen. Wir wissen, dass eine einzige falsch platzierte Ziffer in einem Hauptbuch monatelange Arbeit zunichte machen kann. Deshalb haben wir ein Werkzeug entwickelt, das Präzision, Geschwindigkeit und Abgleich priorisiert. Lassen Sie Ihre Forschung nicht durch veraltete Arbeitsabläufe zurückhalten. Klicken Sie auf den Link unten, um Ihre kostenlose Testversion zu starten. Erleben Sie die Leistungsfähigkeit der automatisierten Tabellenextraktion aus erster Hand und sehen Sie, wie 5.000 Seiten Daten vor Ihrem nächsten Meeting zu einer sauberen, organisierten Excel-Tabelle werden können. Die Zukunft Ihrer Forschung wartet. Schließen Sie sich den Tausenden von Akademikern an, die ihre Zeit bereits zurückgewonnen haben. Starten Sie jetzt mit TabliSync und verwandeln Sie Ihr Datenchaos in Forschungsklarheit.
Was ist Akademische Daten Excel schnell verarbeiten?
Kurze Antworten zu Akademische Daten Excel schnell verarbeiten und wie TabliSync Teams in Excel beschleunigt.
Was ist Akademische Daten Excel schnell verarbeiten?
Akademische Daten Excel schnell verarbeiten umfasst praktische Excel-Workflows, typische Fehler und Automatisierungsmuster. Dieser TabliSync-Guide erklärt das Konzept, zeigt Beispiele und verlinkt Tutorials.
Wie kann TabliSync bei Akademische Daten Excel schnell verarbeiten helfen?
TabliSync extrahiert Tabellen aus Screenshots oder PDFs, bereinigt unordentliche Daten und automatisiert repetitive Excel-Aufgaben zu Akademische Daten Excel schnell verarbeiten.
Wo starte ich mit Akademische Daten Excel schnell verarbeiten?
Beginnen Sie mit der Übersicht auf dieser Seite und öffnen Sie dann die verlinkten Artikel für Schritt-für-Schritt-Anleitungen und KI-Workflows.
Alle Akademische Daten Excel Artikel(6)

So berechnen Sie die Tage zwischen zwei Daten
In diesem Leitfaden führen wir Sie durch den Prozess der Berechnung der Anzahl der Tage zwischen zwei Daten mithilfe von Tabellenkalkulationssoftware. Diese entscheidende Fähigkeit kann in verschiedenen Geschäftsszenarien helfen, wie z. B. im Projektmanagement und im Finanzberichtswesen. Wir bieten Ihnen einen klaren, schrittweisen Ansatz zur Einrichtung Ihrer Tabellenkalkulation für Datumsberechnungen sowie praktische Beispiele, die gängige Situationen veranschaulichen, in denen das Verständnis von Datumsunterschieden unerlässlich ist. Darüber hinaus geben wir Tipps zur Gewährleistung der Genauigkeit, z. B. wie mit Schaltjahren und Formatierungsproblemen umgegangen wird. Am Ende dieses Artikels werden Sie zuversichtlich sein, Datumsberechnungen effektiv durchzuführen und zu erfahren, wie TabliSync bei der Organisation Ihrer Daten für noch mehr Effizienz helfen kann.

Wie man die WENN- und UND-Funktionen in Excel kombiniert
Dieser Artikel führt Benutzer durch den Prozess der Kombination von WENN- und UND-Funktionen in Excel und hilft ihnen, ihre Datenanalyse und Berichterstellung zu verbessern. Mit Schritt-für-Schritt-Anleitungen und praktischen Beispielen werden die Leser ihre Tabellenkalkulationskenntnisse verbessern. Durch das Verständnis, wie diese Funktionen effektiv zusammen genutzt werden, können Benutzer komplexere logische Tests erstellen, die für eine genaue Berichterstellung und Geschäftsentscheidungen unerlässlich sind. Häufige Anwendungsfälle werden ebenso untersucht wie Tipps zur Vermeidung gängiger Fehler. Egal, ob Sie Buchhalter, Mitglied eines Finanzteams oder Datenanalyst sind, dieser Leitfaden bietet die notwendigen Werkzeuge, um Ihre Excel-Kenntnisse zu verbessern und Ihren Arbeitsablauf zu optimieren.

So erstellen Sie ein Tortendiagramm mit Prozenten in Excel
In der heutigen datengesteuerten Welt ist die effektive Visualisierung von Informationen entscheidend für den Geschäftserfolg. Dieser Artikel bietet eine klare und praktische Anleitung zur Erstellung von Tortendiagrammen in Excel mithilfe von Prozentdaten. Ob Sie ein Buchhalter sind, der mit Finanzberichten arbeitet, oder ein Analyst, der Verkaufsdaten in visuelle Formate umwandelt, Tortendiagramme können das Verständnis und die Präsentation verbessern. Befolgen Sie die beschriebenen Schritte, um Tortendiagramme zu erstellen, die Ihre Daten genau widerspiegeln, und entdecken Sie Tipps zur Anpassung, um Klarheit und Wirkung zu erzielen. Darüber hinaus erfahren Sie, wie TabliSync bei der Vorbereitung Ihrer Daten für diese visuellen Darstellungen helfen kann, wodurch der Prozess reibungsloser und effizienter wird. Am Ende dieses Artikels verfügen Sie über die Fähigkeiten, Ihre Daten visuell darzustellen und sicherzustellen, dass Sie Informationen effektiv vermitteln und fundierte Entscheidungen auf der Grundlage genauer Darstellungen treffen.

So entfernen Sie einen Seitenumbruch in Excel
Erfahren Sie, was Seitenumbrüche sind und warum sie in Excel wichtig sind, folgen Sie Schritt-für-Schritt-Anleitungen, um sie zu entfernen, und lernen Sie nützliche Tipps zur effektiven Verwaltung von Seitenumbrüchen in Tabellenkalkulationen.

Datenintegrität meistern: So erstellen Sie eine Dropdown-Liste in Excel
Eliminieren Sie 99 % der manuellen Dateneingabefehler durch Implementierung standardisierter Excel-Datenvalidierungsprotokolle. Erzielen Sie eine Reduzierung der Datenbereinigungszeit um 90 % durch die Verwendung dynamischer Dropdown-Listen und strukturierter Tabellen. Nutzen Sie KI-gesteuertes OCR und TabliSync, um unstrukturierte physische Daten sofort in validierte Excel-Schemata umzuwandeln. Zukunftssichere Ihre Tabellenkalkulationen mit skalierbaren, durchsuchbaren Dropdown-Architekturen für komplexe Datensätze.

Meistern Sie das Chaos: So entfernen Sie Duplikate in Excel ohne Datenverlust
Effizienzsteigerung: Reduzieren Sie die manuelle Datenbereinigungszeit um über 90 % durch automatisierte Workflows. Datenintegrität: Erzielen Sie eine Fehlerrate von 0 % bei der manuellen Eingabe, indem Sie von 'Suchen und Ersetzen' zur schemabasierten Deduplizierung übergehen. Risikominderung: Verhindern Sie 100 % versehentlicher Löschungen durch die Nutzung nicht-destruktiver Power Query-Umgebungen. Zukunftssicherheit: Wechseln Sie von reaktiver Bereinigung zu proaktiver Datenhygiene durch KI-integrierte Automatisierung.
Schluss mit manueller Dateneingabe – Tabellen in Sekunden extrahieren
Konvertieren Sie jedes Bild oder PDF-Tabelle sofort in Excel mit 99,9% Genauigkeit. TabliSyncs KI-gestützte OCR verarbeitet handschriftliche Formulare, Belege und komplexe Tabellen und synchronisiert direkt mit Google Sheets, Notion oder Airtable
Probieren Sie TabliSync jetzt kostenlos aus