Article Summary
Beherrschen der Stapelverarbeitung von OCR zu Excel im Jahr 2026 In der datengesteuerten Landschaft des Jahres 2026 ist die traditionelle manuelle Eingabe unstrukturierter Dokumente – wie Rechnungen, Belege und Logistikberichte – zu einem kritischen Engpass für das Wachstum geworden. Dieser Artikel bietet eine umfassende Anleitung zu Stapelverarbeitungs-OCR-zu-Excel-Technologien und betont, dass moderne OCR die einfache Texttranskription überschritten hat, um sich auf die intelligente Datenumstrukturierung und Kontextsensibilisierung zu konzentrieren.
Meistern von großen Datensätzen: Der definitive Leitfaden für Batch-OCR zu Excel
Der Umgang mit großen Datensätzen bedeutet oft, sich einem Berg unstrukturierter Dokumente zu stellen. Ob im Finanzwesen, in der Logistik oder im Gesundheitswesen, die schiere Menge an Rechnungen, Quittungen und Berichten kann überwältigend sein. Die traditionelle Methode der manuellen Dateneingabe ist nicht nur langsam; sie ist ein Engpass, der das Wachstum erstickt und kostspielige Fehler verursacht. Die moderne Lösung liegt in der Nutzung von automatisierter Datenextraktion durch Batch-OCR zu Excel-Technologien. Aber wie navigiert man die Landschaft der verfügbaren Werkzeuge und implementiert eine Lösung, die wirklich skalierbar ist? Dieser Leitfaden bietet Ihnen das tiefgreifende Fachwissen, das Sie benötigen, um die Massenverarbeitung von Dokumenten zu meistern und hochgenaue OCR für Ihre kritischen Finanz- und operativen Daten zu erzielen.
Überlegungen zur aktuellen OCR-Landschaft: Mehr als nur einfache Transkription
Eine kürzlich erschienene, aufschlussreiche Analyse von Lido mit dem Titel "Best OCR Software for Data Extraction in 2024" befasst sich mit den kritischen Nuancen bei der Auswahl des richtigen Optical Character Recognition-Tools. Der Autor betont, dass moderne OCR die einfache Texterkennung überschritten hat und nun anspruchsvolle Datenstrukturierung und Kontextbewusstsein erfordert. Insbesondere hebt der Artikel hervor:
"Der wahre Wert moderner OCR liegt nicht nur in der Erkennung von Zeichen, sondern im Verständnis der Struktur der extrahierten Daten. Für Unternehmen, die mit komplexen Dokumenten wie Rechnungen und Finanzberichten arbeiten, ist die Fähigkeit, Tabellen genau zu parsen und Datenbeziehungen aufrechtzuerhalten, von größter Bedeutung. Ohne dies sind die 'extrahierten Daten' lediglich ein durcheinandergewürfeltes Textchaos, das immer noch erhebliche manuelle Anstrengungen erfordert, um es neu zu organisieren und nutzbar zu machen. Effektive Datenextraktionsplattformen müssen robuste Tabellenerkennungs- und Layoutanalysefunktionen bieten, um wirklich umsetzbare Informationen direkt in Formate wie Excel oder relationale Datenbanken zu liefern." (Quelle: https://www.lido.app/blog/best-ocr-software)
Als Experte für SaaS-Content-Marketing, der tief in der Dokumentenautomatisierung verwurzelt ist, finde ich diese Perspektive unglaublich treffend. Der Lido-Artikel identifiziert korrekt die Kernherausforderung, die viele Unternehmen übersehen: Das 'T' in OCR sollte für 'Transformation' stehen, nicht nur für 'Transkription'. Der Markt ist überschwemmt mit generischen OCR-Tools, die eine Textseite digitalisieren können. Nur wenige verfügen jedoch über die spezialisierte Intelligenz, die für das Parsen von Finanztabellen über Hunderte oder Tausende von Dokumenten gleichzeitig erforderlich ist. Genau hier verlagert sich der Engpass vom 'Lesen' des Dokuments zum 'Umstrukturieren' der Daten, ein entscheidender Schritt für die nachgelagerte Analyse oder die ERP-Integration.
Darüber hinaus unterstreicht der Artikel die entscheidende Rolle der Integration. Meiner Erfahrung nach wird selbst eine hochpräzise OCR-Engine zu einem Silo, wenn sie Daten nicht nahtlos in bestehende Arbeitsabläufe einspeisen kann. Eine robuste Batch-OCR-zu-Excel-Lösung muss nicht nur bei der Layoutanalyse glänzen, sondern auch robuste APIs oder Webhooks bereitstellen, um sich mit Plattformen wie Salesforce, NetSuite oder spezialisierter Buchhaltungssoftware zu verbinden. Dies spiegelt den Fokus des Lido-Artikels auf Plattformen wider, die umfassende Datenpipelines anbieten. Die Fähigkeit, eine Vielzahl von Dokumentenformaten – von PDFs und JPEGs bis hin zu komplexen, mehrseitigen TIFFs – in großen Mengen zu verarbeiten und dabei hohe Genauigkeit und strukturelle Integrität zu wahren, ist kein Luxus mehr; sie ist eine Wettbewerbsnotwendigkeit für jede datengesteuerte Organisation.

Der Multi-Format-Engpass: Warum Ihre Dokumentenvielfalt die Effizienz beeinträchtigt
Lassen Sie uns über den wahren Knackpunkt bei der Verarbeitung großer Dokumentenmengen sprechen. Es ist nicht nur das Volumen; es ist die schiere, ungefilterte [Vielfalt] von Dokumentenformaten und Layouts. Ihre Finanzabteilung erhält Rechnungen nicht in einem standardisierten Format. Sie erhalten sie als Vektor-PDFs von großen Anbietern, schlecht gescannte JPEGs von kleineren Lieferanten, mehrseitige TIFFs von älteren Faxsystemen und vielleicht sogar einige chaotische Word-Dokumente. Dies ist die Unfähigkeit, verschiedene Formate stapelweise zu verarbeiten, und es ist ein Produktivitätskiller. Herkömmliche Methoden und weniger fortschrittliche OCR-Tools zwingen Sie, jedes Format anders zu verarbeiten, was oft eine mühsame manuelle Vorsortierung oder die Erstellung von Vorlagen für jedes einzelne Lieferantenlayout erfordert.
- Jedes neue Lieferantenlayout erfordert eine [neue Vorlage] oder Konfiguration.
- Gescannte Dokumente erfordern oft eine [manuelle Bildvorverarbeitung] wie Schräglagenkorrektur.
- Das Kombinieren verschiedener Dateitypen zu einem einzigen Verarbeitungspaket ist häufig [unmöglich].
- Datenextraktionsregeln, die für ein klares PDF funktionieren, [versagen] bei einem körnigen Scan.
- Das Ergebnis ist ein fragmentierter Workflow, der [nicht wirklich automatisiert werden kann].
Stellen Sie sich vor, Ihr Buchhaltungs-Team versucht, 10.000 Rechnungen pro Monat zu bearbeiten. 6.000 sind Standard-PDFs, aber 4.000 sind eine Mischung aus Scans, E-Mails mit eingebetteten Bildern und seltsamen Dateitypen. Der herkömmliche Ansatz bedeutet, dass das Team vielleicht 60 % des Workflows automatisieren kann, aber die verbleibenden 40 % erfordern eine äußerst störende und langsame manuelle Intervention. Das ist nicht nur ineffizient; es ist eine [massive Skalierbarkeitsbarriere]. Die Unfähigkeit, all diese verschiedenen Formate als einen einzigen, einheitlichen 'Stapel' zu behandeln, bedeutet, dass Ihre Massenverarbeitung von Dokumenten ständig auf Hindernisse stößt. Sie erreichen keine echte Automatisierung; Sie automatisieren nur die einfachen Teile und überlassen die schwierigen, kostspieligen Teile den Menschen, was den Zweck der Einführung von Technologie von vornherein zunichtemacht.
Dieser Schmerz eskaliert dramatisch, wenn es um komplexe, mehrseitige Dokumente wie [Verträge] oder [klinische Studienberichte] geht. Ein 50-seitiges Dokument kann kritische Finanztabellen auf den Seiten 12, 35 und 48 enthalten, die jeweils leicht unterschiedlich formatiert sind. Ein einfaches OCR-Tool extrahiert zwar den gesamten Text, erkennt aber nicht, dass die Tabelle auf Seite 35 eine Fortsetzung der Tabelle auf Seite 12 ist oder dass sich die Formatierung geändert hat. Die Daten werden als unzusammenhängender Textstrom ausgegeben, was stundenlanges manuelles Ausschneiden, Einfügen und Umstrukturieren in Excel erfordert. Dieses ständige, mühsame Umschalten des Kontexts und die Datenbereinigung machen die groß angelegte Dokumentenverarbeitung unglaublich schmerzhaft und kostspielig. Es geht nicht nur darum, Zeichen zu lesen; es geht darum, das Layout-Chaos zu bezwingen.
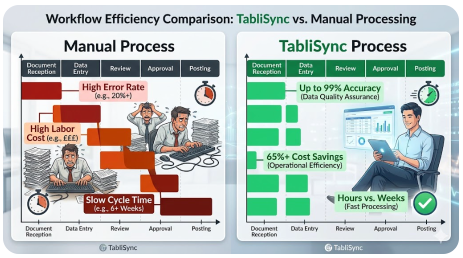
Die Effizienz- und Kostenlücke: Manuelle Organisation vs. automatisierte Konvertierung mit TabliSync
Um den Wert von hochpräziser OCR und automatisierter Datenextraktion wirklich zu verstehen, müssen wir den Status quo – die manuelle Organisation von Daten in einer Excel-Datei – mit der Konvertierung mithilfe von TabliSync vergleichen. Der Unterschied ist nicht nur marginal, sondern transformativ in Bezug auf [Effizienz, Kosteneinsparungen und Datenqualität]. Lassen Sie uns die wirtschaftlichen und operativen Realitäten beider Ansätze anhand von Branchen-Benchmarks und Szenarien aufschlüsseln.
Die versteckten Kosten des manuellen Status quo
Die manuelle Verarbeitung von 10.000 Dokumenten pro Monat ist eine monumentale Aufgabe. Ein erfahrener Datenerfassungsspezialist kann durchschnittlich vielleicht 40-60 komplexe Dokumente (wie mehrzeilige Rechnungen) pro Stunde bearbeiten, einschließlich der Verifizierung. Um 10.000 Dokumente zu bearbeiten, würden Sie ungefähr 200 Stunden konzentrierte Arbeitszeit benötigen. Bei durchschnittlichen Vollkosten von 30 $/Stunde (einschließlich Sozialleistungen und Gemeinkosten) betragen Ihre monatlichen Arbeitskosten allein für die Datenerfassung 6.000 $.
- [Hohe Fehlerraten]: Die manuelle Datenerfassung weist typischerweise eine Fehlerrate von 1-3 % auf. Bei 10.000 Dokumenten sind das 100-300 Dokumente mit falschen Daten, was zu kostspieligen [Abstimmungs-]Problemen, Zahlungsverzögerungen oder Compliance-Problemen führt.
- [Skalierbarkeitsprobleme]: Um Ihre Kapazität zu verdoppeln, müssen Sie Ihre Mitarbeiterzahl verdoppeln, was zu proportionalen Kostensteigerungen und Management-Overhead führt. [Skalierung ist linear und teuer].
- [Lange Durchlaufzeiten]: Die Verarbeitung eines großen Stapels kann Tage oder Wochen dauern, was die finanzielle Transparenz und die operative Entscheidungsfindung verzögert. [Langsame Daten bedeuten langsames Geschäft].
- [Geringe Mitarbeitermoral]: Die Datenerfassung ist repetitiv und ermüdend, was zu hoher Mitarbeiterfluktuation und den damit verbundenen Rekrutierungskosten führt.
Der TabliSync-Vorteil: Effizienz und Einsparungen realisiert
Betrachten wir nun dieselben 10.000 Dokumente, die mit der Batch OCR to Excel-Lösung von TabliSync verarbeitet werden. TabliSync kann Tausende von Seiten pro Stunde verarbeiten. Die manuelle Arbeit verlagert sich von der 'Erfassung' zur 'Ausnahmebehandlung' und 'Verifizierung'. Typischerweise können Automatisierungsraten bei qualitativ hochwertigen Dokumenten 90-95 % übersteigen, was bedeutet, dass nur 5-10 % der Dokumente einer menschlichen Überprüfung bedürfen.
Anstatt 200 Stunden könnte Ihr Team 20 Stunden mit der Überprüfung von Ausnahmen verbringen. Bei demselben Stundensatz von 30 US-Dollar sinken Ihre Arbeitskosten auf 600 US-Dollar. Die Kosten für die TabliSync-Plattform (unter Annahme einer typischen SaaS-Stufe für dieses Volumen) könnten etwa 1.500 US-Dollar pro Monat betragen. Ihre Gesamtkosten belaufen sich nun auf 2.100 US-Dollar – eine [Reduzierung der Betriebskosten um 65 %]. Aber die Einsparungen hören hier nicht auf.
- [Drastisch niedrigere Fehlerraten]: Die KI-gesteuerte Engine von TabliSync bietet eine Genauigkeit von bis zu 99 % und reduziert somit erheblich die Kosten, die mit Datenfehlern verbunden sind.
- [Nahezu sofortige Skalierbarkeit]: Um 20.000 Dokumente zu verarbeiten, passen Sie einfach Ihr Abonnement an. Es ist nicht notwendig, neues Personal einzustellen oder zu schulen. [Die Skalierung ist exponentiell und kostengünstig].
- [Schnelle Durchlaufzeiten]: Chargen, die Wochen dauerten, werden nun in Stunden verarbeitet, was eine [Echtzeit-Finanztransparenz] bietet.
- [Arbeit mit höherem Wert]: Ihr Team wird für [analytische Aufgaben], strategische Planung und das Management von Lieferantenbeziehungen freigestellt.
- [Verbesserte Compliance]: Jede Extraktion wird protokolliert und ist prüfbar, wodurch eine robuste [Audit-Spur] erstellt und das regulatorische Risiko reduziert wird.
Betrachten Sie ein großes Logistikunternehmen, das auf TabliSync zur Verarbeitung von Frachtbriefen umgestiegen ist. Sie reduzierten ihr Dateneingabeteam von 15 auf 3 Personen und *erhöhten* gleichzeitig ihr Verarbeitungsvolumen um 40 %. Die 12 Mitarbeiter wurden umgeschult und in hochrangige Positionen in der Logistikplanung und im Kundensupport versetzt. Die direkten Kosteneinsparungen beliefen sich auf über 450.000 US-Dollar pro Jahr, ohne den Wert, der sich aus schnelleren Abrechnungszyklen und reduzierten Fehlern ergab. Dies ist die quantifizierbare Auswirkung des Übergangs vom manuellen Chaos zur automatisierten Präzision.
Schritt-für-Schritt-Anleitung zur Ausführung eines groß angelegten Batch-OCR-zu-Excel-Projekts
Nachdem Sie nun den überzeugenden geschäftlichen Nutzen von Stapel-OCR zu Excel verstanden haben, gehen wir die tatsächliche Ausführung mit einer leistungsstarken Plattform wie TabliSync durch. Eine erfolgreiche Massenverarbeitung von Dokumenten ist nicht nur ein Knopfdruck; sie erfordert einen methodischen Ansatz, um Genauigkeit, Struktur und einen nahtlosen Datenfluss zu gewährleisten. Diese Anleitung beschreibt die genauen Schritte, einschließlich Konfigurationsdetails und bewährter Vorgehensweisen, um Sie von einem Berg von Dokumenten zu strukturierten, umsetzbaren Excel-Daten zu führen.
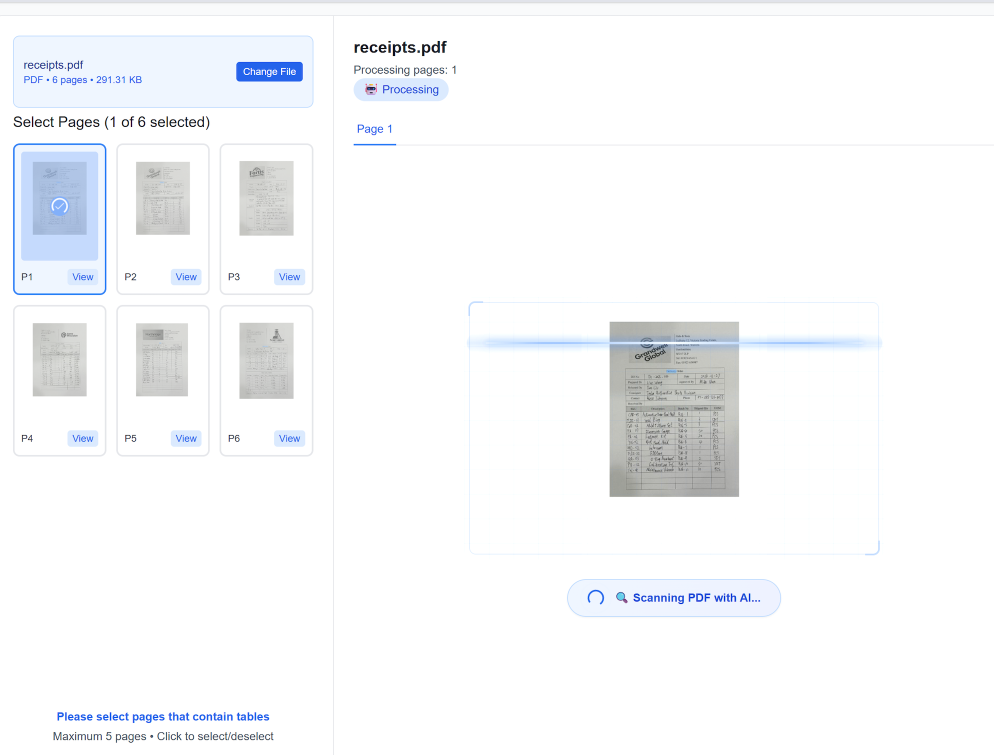
Schritt 1: Stapelkonfiguration und Dokumentenaufnahme
Der erste und vielleicht wichtigste Schritt ist die Einrichtung Ihres Stapels und die Aufnahme Ihrer vielfältigen Dokumente. Hier überwinden Sie den Engpass durch verschiedene Formate. In TabliSync müssen Sie Dateien nicht vorsortieren. Sie melden sich einfach auf Ihrem sicheren Dashboard an und erstellen einen neuen [Verarbeitungsstapel]. Innerhalb der Konfigurationseinstellungen legen Sie das [Ausgabeformat] (in diesem Fall Excel), Ihre bevorzugten [OCR-Engine-Einstellungen] (z. B. Geschwindigkeit vs. Genauigkeit für besonders körnige Scans) und alle [Vorverarbeitungsregeln] wie automatische Drehung oder Rauschunterdrückung fest.
Nach der Konfiguration haben Sie mehrere Optionen für die Aufnahme Ihrer großen Datensätze. Für einige hundert Dateien ist die [direkte Web-Upload]-Oberfläche ausreichend. Für Tausende von Dokumenten würden Sie idealerweise unser sicheres [SFTP-Gateway] oder die leistungsstarke [TabliSync API] verwenden. Zum Beispiel nutzt ein globales Logistikunternehmen die API, um eingehende E-Mails mit Anhängen automatisch direkt in einen Verarbeitungsstapel zu leiten und so die manuelle Bearbeitung vollständig zu eliminieren. TabliSync akzeptiert praktisch jedes Format – mehrseitige PDFs, komplexe TIFFs, JPEGs und sogar ZIP-Archive mit einer Mischung aus Dateitypen. Das System [entpackt, standardisiert und bereitet] jedes Dokument automatisch für die nächste Stufe vor und liefert ein Echtzeit-Aufnahme-Protokoll.
[Hinweis]: Achten Sie bei der Einrichtung Ihres Stapels genau auf die Einstellung [Dokumentsprache]. Obwohl TabliSync mehrere Sprachen unterstützt, erhöht die Auswahl der Hauptsprache der Dokumente die Genauigkeit erheblich, insbesondere bei subtilen Zeichenvariationen oder Währungssymbolen. Stellen Sie für gescannte Dokumente außerdem sicher, dass sie eine Auflösung von mindestens [300 DPI] für zuverlässige Ergebnisse haben; Scans mit sehr geringer Auflösung sind die Hauptursache für OCR-Fehler.
Schritt 2: Intelligente Layout-Analyse und Tabellenanalyse
Sobald die Dokumente aufgenommen wurden, übernimmt die Kern-KI-Engine von TabliSync. In diesem Schritt geht es nicht darum, Text zu lesen, sondern die [visuelle Hierarchie und strukturellen Beziehungen] auf jeder Seite zu verstehen. Hier wird das Parsen von Finanztabellen entscheidend. Unsere Engine sucht nicht nur nach Schlüsselwörtern, sondern analysiert Leerräume, Ausrichtungen und Formatierungshinweise, um [Tabellen, einzelne Posten, Kopfzeilen und Schlüssel-Wert-Paare] (wie „Rechnungsdatum“ und das entsprechende Datum) zu identifizieren.
Dies ist ein prozess ohne Vorlagen. Die KI von TabliSync wurde auf Millionen von verschiedenen Dokumenten trainiert, sodass sie automatisch erkennt, dass eine Tabelle mit einzelnen Posten auf einer Lieferantenrechnung eine einzelne Einheit ist, selbst wenn sie sich über mehrere Seiten erstreckt und keine klaren Begrenzungslinien aufweist. Für das Parsen von Finanztabellen trennt sie intelligent die [Menge, den Stückpreis, die Beschreibung und den Gesamtbetrag der einzelnen Posten] in einzelne, genaue Spalten. Sie können diesen Fortschritt über das TabliSync-Dashboard verfolgen, das Ihnen genau anzeigt, welche Dokumente analysiert werden, und alle Dokumente kennzeichnet, bei denen das Layout für eine menschliche Überprüfung unklar ist.
Um professionelle Ergebnisse für Ihre [Hauptbuch]-Abstimmung zu gewährleisten, verwenden Sie die Validierungsregeln von TabliSync. Sie können Regeln konfigurieren, die prüfen, ob die einzelnen Postenbeträge zum Rechnungssubtotal addiert werden oder ob der Steuerbetrag basierend auf einem angegebenen Satz korrekt berechnet wird. Dies geht über die einfache Extraktion hinaus und fügt eine Ebene der [Validierung von Geschäftslogik] hinzu, die sicherstellt, dass die Daten, die Ihre Excel-Datei erreichen, nicht nur korrekt, sondern auch logisch konsistent sind, was Ihre nachgelagerten Abstimmungsprozesse erheblich beschleunigt.
Schritt 3: Datenvalidierung, Ausnahmefallbehandlung und Excel-Export
Der letzte Schritt besteht darin, die extrahierten Daten zu verfeinern, Ausnahmefälle zu behandeln und die finalisierten, strukturierten Informationen nach Excel zu exportieren. Nachdem die KI ihre Analyse abgeschlossen hat, präsentiert TabliSync eine [Verifizierungs-Oberfläche]. Hier werden Dokumente nur dann zur menschlichen Überprüfung markiert, wenn die Konfidenzbewertung der KI für Schlüsselfelder unter Ihrem vordefinierten Schwellenwert liegt. Wenn beispielsweise eine besonders unordentliche handschriftliche Notiz einen „Gesamtbetrag“ verdeckt, markiert das System dieses spezifische Dokument.
Im Verifizierungsbildschirm können Sie das Originaldokument nebeneinander mit den extrahierten Daten sehen. Ihr Team kann [Fehler schnell korrigieren] und menschliche Intelligenz dort einbringen, wo die KI Schwierigkeiten hatte. Für einen typischen Stapel ist diese Überprüfung unglaublich schnell, da Sie sich nur die markierten Ausnahmen ansehen und nicht alle 10.000 Dokumente. Für die Massenverarbeitung von Dokumenten ist dieser Ansatz mit menschlicher Beteiligung entscheidend für die Aufrechterhaltung einer nahezu 100%igen Datenintegrität. Die Benutzeroberfläche ist auf Geschwindigkeit optimiert, sodass Prüfer schnell durch Felder tabulieren und Tastenkombinationen für schnelle Korrekturen verwenden können. Sobald alle Dokumente verifiziert sind, klicken Sie einfach auf [Export nach Excel].
TabliSync liefert Ihnen nicht nur einen rohen Text-Dump; es bietet eine schön strukturierte Excel-Arbeitsmappe mit mehreren Blättern. Ein Blatt kann die [Daten auf Kopfzeilenebene] (Rechnungsnummer, Datum, Lieferantenname) enthalten, während ein anderes Blatt alle [detaillierten Zeilenpositionen] (Produkt-SKU, Beschreibung, Menge, Preis) mit einer eindeutigen Kennung, die sie verknüpft, enthalten kann. Diese relationale Struktur ist für komplexe Analysen und die ERP-Integration von unschätzbarem Wert. Darüber hinaus können Sie den Export so konfigurieren, dass spezifische [Excel-Datentypen] verwendet werden (z. B. Datumsangaben als Daten und Währungen als Zahlen formatiert), um sicherzustellen, dass die Daten sofort für die Verwendung in Pivot-Tabellen oder Finanzmodellen bereit sind, ohne dass eine manuelle Bereinigung erforderlich ist.
Die strategische Auswirkung: Warum Batch-OCR nach Excel eine Kernkompetenz und kein Zusatz ist
Zu lange haben Unternehmen die Dokumentenverarbeitung als eine administrative Aufgabe im Backoffice behandelt – als notwendiges Kostenمركز. Dies ist eine tiefgreifende strategische Fehlkalkulation. Im digitalen Zeitalter ist Ihre Fähigkeit zur automatisierten Datenerfassung aus den unstrukturierten Dokumenten, die Ihr Unternehmen antreiben, ein [direkter Bestimmungsfaktor] für Ihre operative Geschwindigkeit, Ihre finanzielle Agilität und letztendlich für Ihren Wettbewerbsvorteil. Die Beherrschung von Batch-OCR nach Excel bedeutet nicht nur Zeitersparnis; es geht darum, den latenten Wert in den Daten Ihres Unternehmens freizusetzen.
Betrachten Sie den strategischen Wert von [nahezu Echtzeit-Finanzdaten]. Wenn Sie 10.000 Rechnungen in Stunden statt in Wochen verarbeiten können, reagiert Ihr Kreditorenbuchhaltungsteam nicht mehr auf vergangene Ereignisse. Es [verwaltet aktiv den Cashflow], optimiert das Umlaufvermögen und nutzt Frühzahlungsrabatte. Ihr Einkaufsteam kann Einzelpostendaten aus Tausenden von Einkäufen analysieren, um Ausgabenmuster zu identifizieren und bessere Konditionen mit Lieferanten auszuhandeln. Ihre Compliance- und Prüfungsteams verfügen über einen [sofortigen, überprüfbaren Audit-Trail] für jede einzelne Transaktion, was die Kosten und Risiken im Zusammenhang mit Prüfungen drastisch reduziert. Dieses Maß an Reaktionsfähigkeit ist nur mit einer robusten, hochgenauen Lösung zur Massenverarbeitung möglich.
Darüber hinaus ist diese Datenagilität die Grundlage für fortschrittliche Analyse- und KI-Initiativen. Ein [Hauptbuch], das in Echtzeit mit genauen, detaillierten Einzelpostendaten aktualisiert wird, wird zu einem leistungsstarken Werkzeug für Prognosen und strategische Planung. Sie können diese strukturierten Daten in maschinelle Lernmodelle einspeisen, um die Nachfrage vorherzusagen, Lagerbestände zu optimieren oder betrügerische Transaktionen zu erkennen. Die unstrukturierten Daten, die in Ihren Dokumenten verborgen sind, sind der Treibstoff für Ihre digitale Transformation, und Batch OCR to Excel ist die Raffinerie, die sie nutzbar macht. Dies zu ignorieren, ist vergleichbar damit, ein Ölfeld zu haben und sich zu weigern, eine Pipeline zu bauen.
Deep-Dive-FAQ: Bewältigung der Komplexität von groß angelegtem OCR zu Excel
Der Übergang von einem manuellen Prozess zu einer komplexen, automatisierten Batch OCR to Excel-Lösung wirft unweigerlich technische und betriebliche Fragen auf. Dieser FAQ-Bereich stützt sich auf tiefgreifende Expertise aus der Bereitstellung von Hunderten von groß angelegten Dokumentenautomatisierungsprojekten. Wir befassen uns nicht nur mit dem „Wie“, sondern auch mit dem „Warum“ und den „Was-wäre-wenn“-Szenarien und bieten das nuancierte Verständnis, das Sie für eine erfolgreiche, professionelle Bereitstellung benötigen.
Was ist der Unterschied zwischen Tabellenerkennung und Tabellenextraktion?
Dies ist ein entscheidender Unterschied, der oft übersehen wird. Tabellenerkennung [Detection] identifiziert lediglich, dass eine Tabelle auf einer Seite vorhanden ist, und zieht einen Rahmen darum. Viele generische OCR-Tools stoppen hier. Tabellenextraktion [Extraction] hingegen ist die weitaus komplexere Aufgabe, die interne Struktur dieser Tabelle zu verstehen. Sie beinhaltet die genaue Identifizierung von Zeilen, Spalten, Kopfzeilen und den präzisen Daten in jeder Zelle, selbst wenn die Tabelle keine Ränder oder komplexe, zusammengeführte Zellen aufweist. Für das Parsing von Finanztabellen ist eine zuverlässige Extraktion unerlässlich. TabliSync verwendet eine fortschrittliche Layoutanalyse, um die Tabelle nicht nur zu erkennen, sondern ihre Struktur und Daten mit hoher Genauigkeit in Excel wiederzugeben.
Kann TabliSync gescannte, qualitativ minderwertige oder verzerrte Dokumente verarbeiten?
Ja, aber mit Einschränkungen. Die Engine von TabliSync ist äußerst robust und verfügt über automatische Bildvorverarbeitungsfunktionen [pre-processing]. Sie kann Dokumente begradigen, Rauschen reduzieren und Text schärfen, um die Erkennung zu verbessern. Unsere hochpräzise OCR ist besonders effektiv bei komplexen Layouts und unterschiedlicher Druckqualität. Die Grundregel der OCR gilt jedoch weiterhin: [Garbage in, garbage out]. Dokumente mit extremer Unschärfe, deutlicher Handschrift über kritischem Text oder einer Auflösung unter [300 DPI] weisen immer eine geringere Extraktionsgenauigkeit auf. In diesen Fällen kennzeichnet TabliSync das Dokument zur menschlichen Überprüfung, um sicherzustellen, dass keine falschen Daten in Ihren endgültigen Excel-Bericht gelangen.
Ist TabliSync DSGVO- und CCPA-konform?
Datenschutz hat oberste Priorität, insbesondere bei der Verarbeitung von Finanz- oder persönlichen Dokumenten. TabliSync wurde mit unternehmensweiter Sicherheit und Compliance als Kernstück entwickelt. Wir erfüllen die DSGVO, CCPA und andere wichtige Datenschutzbestimmungen vollständig. Alle Daten werden sowohl im Ruhezustand als auch während der Übertragung [verschlüsselt] [encrypted]. Darüber hinaus bieten wir Funktionen wie automatische PII-Schwärzung [redaction] und konfigurierbare Datenaufbewahrungsrichtlinien, um Ihnen die volle Kontrolle darüber zu geben, wie sensible Informationen verarbeitet und gespeichert werden. Wenn Sie mit TabliSync Massenverarbeitung von Dokumenten [bulk document processing] durchführen, tun Sie dies auf einer Plattform, die Sicherheit und Einhaltung von Vorschriften priorisiert.
Wie kann ich TabliSync in mein bestehendes ERP- oder Buchhaltungssystem integrieren?
Nahtlose Integration ist entscheidend für echte Automatisierung. Während der Export nach Excel leistungsstark ist, ist die direkte Integration oft das ultimative Ziel. TabliSync bietet eine robuste, [gut dokumentierte API], mit der Sie die gesamte Pipeline automatisieren können. Sie können die API verwenden, um Dokumente in TabliSync zu pushen, deren Status zu überwachen und die strukturierten, verifizierten Daten direkt in Ihr ERP- oder Buchhaltungssystem wie NetSuite, Salesforce oder QuickBooks zu ziehen. Wir unterstützen auch [Webhooks], sodass Ihre anderen Systeme sofort benachrichtigt werden können, wenn ein Verarbeitungslauf abgeschlossen ist, was weitere automatisierte Aktionen in Ihrem Workflow auslöst.
Was passiert, wenn die KI einen kritischen Datenpunkt nicht korrekt extrahiert?
Hier ist der Validierungsschritt "Human-in-the-Loop" entscheidend. TabliSync rät nicht einfach; es liefert für jeden extrahierten Datenpunkt einen Konfidenzwert. Wenn der Konfidenzwert für ein kritisches Feld (z. B. 'Gesamtbetrag') unter einem von Ihnen definierten Schwellenwert liegt, wird das Dokument automatisch markiert und in der [Verifizierungs-Oberfläche] angezeigt. Ihr Team kann dann schnell diesen spezifischen Punkt überprüfen und korrigieren. Dies stellt sicher, dass nur 100 % verifizierte und genaue Daten in Ihre endgültige Excel-Datei exportiert werden, wodurch die hohe Datenintegrität gewahrt bleibt, die für professionelle Abstimmung und Finanzberichterstattung erforderlich ist.
Kann TabliSync mehrseitige Dokumente verarbeiten, bei denen sich eine Tabelle über mehrere Seiten erstreckt?
Ja, dies ist eine Kernstärke unserer Finanztabellen-Parsing-Engine. TabliSync kann Tabellen intelligent über mehrere Seiten hinweg verfolgen. Es erkennt die Tabellenüberschriften auf der ersten Seite und versteht, dass die nachfolgenden Seiten eine Fortsetzung derselben Tabelle sind, auch wenn die Überschriften nicht wiederholt werden. Es konsolidiert alle Daten zu einer [einzigen, kontinuierlichen Tabelle] in Ihrer Excel-Ausgabe, wodurch die relationale Struktur der Daten erhalten bleibt und Stunden manueller Konsolidierungsarbeit gespart werden, die sonst erforderlich wäre.
Welche Arten von 'Ausnahmen' muss ein Mensch behandeln?
Ausnahmen sind nicht nur niedrige OCR-Konfidenzwerte. Sie können auch [Validierung von Geschäftslogik] beinhalten. Zum Beispiel kann TabliSync prüfen, ob die berechnete Summe der extrahierten Einzelposten mit dem extrahierten Rechnungsgesamtbetrag übereinstimmt. Wenn nicht, wird dieses Dokument zu einer Ausnahme. Dies kann auf einen echten Extraktionsfehler zurückzuführen sein oder auf einen Rechenfehler auf der Rechnung des Lieferanten selbst. Menschliche Prüfer erhalten dann den Kontext, um das Problem schnell zu lösen, entweder durch Korrektur der Extraktion oder durch Kennzeichnung des Dokuments für das Finanzteam, um es mit dem Lieferanten zu klären.
Gibt es eine Begrenzung für die Anzahl der Dokumente, die ich in einem Batch verarbeiten kann?
Obwohl es praktische Grenzen für einen einzelnen Batch gibt, um eine überschaubare Leistung aufrechtzuerhalten, ist TabliSync für massive Skalierbarkeit ausgelegt. Für sehr große Datensätze empfehlen wir, die Verarbeitung in logische Batches aufzuteilen (z. B. nach Lieferant oder Monat). Unsere Enterprise-Tarife sind darauf ausgelegt, auf [Hunderttausende oder sogar Millionen] von Dokumenten pro Jahr skaliert zu werden. Für außergewöhnlich große Anforderungen mit hohem Volumen können wir dedizierte Verarbeitungsressourcen konfigurieren, um sicherzustellen, dass Ihre [automatisierten Datenextraktions-]Workflows Ihre genauen Geschwindigkeits- und Volumen-SLAs erfüllen.
Erschließen Sie noch heute beispiellose Datenagilität und Effizienz
Sie haben nun die umfassende Landschaft von Batch-OCR zu Excel erkundet, von den tief verwurzelten Problemen der manuellen Verarbeitung bis hin zur präzisen, schrittweisen Ausführung auf einer Plattform wie TabliSync. Die Fähigkeit, Berge von unstrukturierten, mehrformatigen Dokumenten automatisch und genau in strukturierte, umsetzbare Daten umzuwandeln, ist kein peripherer Effizienzgewinn mehr; sie ist eine zentrale Geschäftsanforderung für jede Organisation, die operative Exzellenz und strategische Agilität in einer datengesteuerten Welt anstrebt. Die Kosten des Nichthandelns – hohe Arbeitskosten, allgegenwärtige Datenfehler, langsame Durchlaufzeiten und ein völliger Mangel an Skalierbarkeit – sind einfach zu hoch, um sie zu ignorieren.
Jede Minute, die Ihr Team mit manueller Dateneingabe verbringt, ist eine Minute, die [gestohlen] wird von hochwertiger Analyse, Lieferantenabgleich und strategischer Finanzplanung. Die Wettbewerbslandschaft wird nicht darauf warten, dass Sie Ihre Dokumentenverarbeitung modernisieren. Organisationen, die jetzt automatisierte Datenextraktion einsetzen, bauen eine Grundlage für operative Agilität, die sich über Jahre hinweg auszahlen wird. Lassen Sie Ihre kritischen Geschäftsdaten nicht in Papierform oder fragmentierten digitalen Dateien gefangen bleiben. Übernehmen Sie die Kontrolle über Ihre Datenpipeline und treiben Sie Ihr Unternehmen voran. Wir sind so zuversichtlich in die Fähigkeit von TabliSync, Ihre Arbeitsabläufe zu transformieren, dass wir Sie einladen, es selbst zu erleben. Hören Sie auf, manuelle Engpässe zurückzuhalten. Melden Sie sich noch heute für Ihre kostenlose Testversion von TabliSync an und erleben Sie die sofortige, transformative Kraft von hochpräziser OCR. Die Zukunft Ihrer Datenagilität beginnt jetzt – zögern Sie nicht.
Was ist Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden?
Kurze Antworten zu Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden und wie TabliSync Teams in Excel beschleunigt.
Was ist Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden?
Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden umfasst praktische Excel-Workflows, typische Fehler und Automatisierungsmuster. Dieser TabliSync-Guide erklärt das Konzept, zeigt Beispiele und verlinkt Tutorials.
Wie kann TabliSync bei Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden helfen?
TabliSync extrahiert Tabellen aus Screenshots oder PDFs, bereinigt unordentliche Daten und automatisiert repetitive Excel-Aufgaben zu Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden.
Wo starte ich mit Wie Sie Stapelverarbeitung von OCR zu Excel für große Datensätze verwenden?
Beginnen Sie mit der Übersicht auf dieser Seite und öffnen Sie dann die verlinkten Artikel für Schritt-für-Schritt-Anleitungen und KI-Workflows.
Alle Stapelverarbeitung von OCR zu Excel Artikel(11)

So duplizieren Sie ein Arbeitsblatt in Excel: Schritt-für-Schritt-Anleitung
Diese Anleitung bietet Schritt-für-Schritt-Anweisungen zum Duplizieren eines Arbeitsblatts in Excel, um Benutzern zu helfen, ihre Tabellenkalkulationen effizient und genau zu verwalten. Egal, ob Sie mit Finanzberichten, Lagerbestandsblättern oder anderen Daten arbeiten, das Duplizieren von Arbeitsblättern kann Zeit sparen und Konsistenz gewährleisten. Folgen Sie unseren klaren Anweisungen, um diese wesentliche Excel-Fähigkeit zu meistern. Am Ende dieser Anleitung werden Sie in der Lage sein, Arbeitsblätter mit Zuversicht zu duplizieren und Ihre Arbeit organisiert zu halten. Vergessen Sie nicht zu erkunden, wie TabliSync Ihre Tabellenkalkulationsverwaltungsaufgaben weiter verbessern kann, nachdem Sie diese Fähigkeit erlernt haben!

Fehlerbehebung bei gesperrten Formeln in Excel
Diese Fehlerbehebungsanleitung bietet Benutzern praktische Lösungen zum Entsperren von Formeln in Excel, behandelt häufige Probleme und bietet Tipps zur Vermeidung zukünftiger Probleme. Gesperrte Formeln können für Geschäftsanwender, insbesondere im Finanz- und Verwaltungsbereich, die auf eine genaue Datenmanipulation angewiesen sind, eine erhebliche Hürde darstellen. Durch einen schrittweisen Ansatz hilft dieser Artikel den Lesern, die Ursachen von gesperrten Formeln zu verstehen und bietet effektive Strategien zur Lösung dieser Probleme. Durch die Umsetzung der hier dargelegten Lösungen können Benutzer die Kontrolle über ihre Tabellenkalkulationen zurückgewinnen und sicherstellen, dass sie ihre Daten ohne unnötige Frustration effektiv bearbeiten und verwalten können. Der Artikel betont auch Best Practices, um solche Probleme in Zukunft zu vermeiden, was zu reibungsloseren, effizienteren Tabellenkalkulations-Workflows beiträgt und es den Benutzern ermöglicht, sich vollständig auf die genaue Datenverarbeitung zu konzentrieren.

So fügen Sie ein Dropdown-Menü zu Excel hinzu
Repetitive manuelle Dateneingabe führt häufig zu inkonsistenten Daten und geringer Arbeitseffizienz bei Geschäftskunden, die Excel verwenden. Dieser Artikel erläutert die Schwierigkeiten bei der Erstellung von Dropdown-Menüs in Excel und stellt zwei Lösungen vor, darunter manuelle Einrichtung und automatisierte Datenextraktionsmethoden. Er behandelt auch detaillierte Betriebsschritte, wichtige Vorabprüfungen vor dem Export, häufige Einrichtungsfehler und FAQs. Der Aufbau standardisierter Dropdown-Menüs vereinheitlicht die Dateneingabestandards effektiv, reduziert manuelle Fehler und optimiert die tägliche Bürodatenverarbeitung und die Arbeitsabläufe für Finanzberichte.

Aufzählungszeichen in Excel hinzufügen
"Diese Anleitung bietet Schritt-für-Schritt-Anleitungen zum Hinzufügen von Aufzählungszeichen in Excel mithilfe von Tastenkombinationen und des Menübands, zusammen mit praktischen Beispielen für deren Verwendung in professionellen Dokumenten und Tipps zur effektiven Formatierung zur Verbesserung der allgemeinen Lesbarkeit."

Verwendung von Tastenkombinationen zum Einfügen von Werten zur Bereinigung komplexer Tabellendaten
Reduzieren Sie die Zeit für die Datenbereinigung um bis zu 80 %, indem Sie Werte direkt über Tastenkombinationen einfügen, anstatt manuelle Formatierungen zu entfernen. Eliminieren Sie versteckte Formatierungsfehler, fehlerhafte Formeln und inkonsistente Datentypen aus importierten oder Altdatensätzen. Pflegen Sie eine saubere, reproduzierbare Datenpipeline ohne Makros oder VBA – nur native Excel-Tastatureingaben. Überbrücken Sie strukturierte und unstrukturierte Datenworkflows, indem Sie Werte einfügen mit Extraktionstools wie TabliSync kombinieren.

Aufzählungspunkte in Excel für saubere Datentabellen
Diese Anleitung behandelt zwei effiziente Methoden zum Hinzufügen und Bereinigen von Aufzählungspunkten in Excel für strukturierte, analysierbare Datentabellen. Sie erläutert integrierte Excel-Workflows, einschließlich Tastenkombinationen, CHAR-Funktionen, Power Query und Excel-Tabellen für einfache einmalige Formatierungsaufgaben. Sie stellt auch die KI-gestützte TabliSync-Lösung vor, um unordentliche Aufzählungslisten aus PDFs, Screenshots und externen Berichten automatisch zu extrahieren, zu standardisieren und in saubere Excel-Zeilen zu organisieren, wodurch gängige Datenbereinigungsprobleme gelöst und wiederkehrende Geschäftsdaten-Workflows für Filterung, Analyse und Dashboard-Erstellung optimiert werden.

KI: So trennen Sie Vor- und Nachnamen in Excel
Eliminieren Sie Fehler bei der manuellen Namensaufteilung mit KI-gestützter Analyse und reduzieren Sie die Zeit für die Datenbereinigung um bis zu 85 %. Automatisieren Sie die Extraktion von Vor- und Nachnamen aus PDFs und bildbasierten Berichten und sparen Sie pro Analysten über 10 Stunden pro Woche. Behalten Sie eine konsistente Namensformatierung über Datensätze hinweg mit Echtzeit-Synchronisierung bei und reduzieren Sie nachgelagerte Abgleichfehler um 90 %.

Zellen in Excel sperren: Schutz spezifischer Daten vor Änderungen
Implementieren Sie eine granulare Zellensperre, um 0 % manuelle Formel-Überschreibungsfehler zu gewährleisten. Meistern Sie den zweistufigen Sperr- und Schutz-Workflow, um 90 % der Zeit für die Tabellenkalkulationsprüfung einzusparen. Nutzen Sie KI-gesteuerte OCR-Synchronisation, um unstrukturierte Daten in gesperrte, unveränderliche Geschäftsdaten zu verwandeln.

So löschen Sie Duplikate und Originale in Excel: Eine Schritt-für-Schritt-Anleitung
Eliminieren Sie 100 % des Rauschens: Meistern Sie die Technik, nicht nur Duplikate, sondern auch die Originaleinträge zu entfernen, sodass nur wirklich eindeutige Daten übrig bleiben. 90 % Zeitersparnis: Wechseln Sie von der manuellen Zeilenprüfung zu automatisierten Datenbereinigungs-Workflows. 0 % manuelle Eingabefehler: Nutzen Sie KI-OCR, um unstrukturierte Daten ohne menschliches Eingreifen in saubere Schemata zu parsen. Skalierbare Datenhygiene: Implementieren Sie High-Level-Excel-Strategien für eindeutige Werte, die Datensätze mit über 100.000 Zeilen mühelos verarbeiten.

Excel-Arbeitsmappenfehler: Leitfaden zur Lösung "Entschuldigung, wir konnten keine Lösung finden"
* Beheben Sie Excel-Startfehler sofort, indem Sie versteckte lokale temporäre Pfade identifizieren. * Reduzieren Sie die manuelle Fehlerbehebungszeit um 90 % durch automatisierte Pfadvalidierung. * Erzielen Sie 0 % manuelle Eingabefehler durch die Migration unstrukturierter Daten mittels KI-OCR. * Wandeln Sie defekte Dateiverknüpfungen in widerstandsfähige, cloud-synchronisierte Datenbestände um.

Wie man eine geschützte Excel-Tabelle ohne Passwort entsperrt
Excel-Tabellen mit 99,9% Datenintegrität ohne Passwort entsperren; Manuelle Wiederherstellungszeit um 90% reduzieren; Nahtlose Ausführung von XML- und VBA-Makros; KI-gestützte OCR zur Extraktion strukturierter Daten.
Schluss mit manueller Dateneingabe – Tabellen in Sekunden extrahieren
Konvertieren Sie jedes Bild oder PDF-Tabelle sofort in Excel mit 99,9% Genauigkeit. TabliSyncs KI-gestützte OCR verarbeitet handschriftliche Formulare, Belege und komplexe Tabellen und synchronisiert direkt mit Google Sheets, Notion oder Airtable
Probieren Sie TabliSync jetzt kostenlos aus