Article Summary
這份全面的支柱頁面是為在手動將複雜學術數據集轉換為 Excel 時面臨困難的研究人員、大學管理員和數據分析師準備的最終指南。我們深入探討學術數據 Excel 處理的機制,超越基本的電子表格功能,探索進階的自動化表格提取和批次 PDF 處理。本指南解決了統計結果格式不一致的關鍵痛點,並對手動輸入與 AI 驅動的研究數據自動化進行了嚴格的技術比較。讀者將找到 TabliSync 的詳細 1-2-3 操作流程,包括用於處理歷史撥款和總帳的複雜金融 OCR 技術。內容涵蓋超過 4,500 字的專家級見解,涵蓋數據協調、用於學術工作流程的 Webhook 以及數據完整性的行業標準合規性。來自全球研究機構的詳細案例研究說明了透過現代提取技術可實現的效率提升和成本節省。本頁面還設有一個強大的常見問題解答部分,解決了多頁表格跨接和非標準字符識別等技術難題,確保使用者能夠以前所未有的速度和準確性將混亂的原始學術數據轉換為可發表的 Excel 資產。
如何快速處理學術數據 Excel:研究數據自動化的終極指南
學術研究的格局正在發生變化。我們不再缺乏數據;我們正被數據淹沒。然而,原始數據——通常被鎖在頑固的 PDF 或舊圖像格式中——與可操作的學術數據 Excel 文件之間的橋樑充滿了手動勞動。本指南旨在打破高速數據處理的障礙,重點關注自動表格提取和研究數據自動化,將它們作為現代學術的主要驅動力。
對現代數據素養的反思
在 DataCamp 發表的文章《如何學習 Excel》中,作者強調了電子表格在現代職業生涯中的基礎作用:「Excel 仍然是數據專業人士工具箱中最強大、最多功能的工具之一……它是從金融到生物學的各個行業數據的通用語言。」(來源:DataCamp,2024)。這突顯了一個基本事實:儘管新的編程語言不斷湧現,但學術數據 Excel 格式仍然是學術界驗證和分析的基石。
我的看法很簡單:素養不再僅僅是關於知道如何編寫公式;而是關於知道如何有效地輸入這些公式。DataCamp 的文章正確地指出,「學習 Excel 是從基本計算到複雜數據建模的旅程。」然而,對於學術專業人士來說,「旅程」經常在數據輸入的邊界停滯不前。如果你花十二小時從一份研究報告中提取一個表格,而只花十分鐘來分析它,那麼你的瓶頸不是 Excel 的熟練程度——而是數據獲取。我們需要停止將學術數據 Excel 視為目的地,而是開始將自動化管道視為載體。真正的專業知識在於掌握「Excel 前」階段:批量 PDF 處理和複雜金融 OCR。通過自動化數據導入,我們可以讓人類思維專注於研究的「思想領導力」方面,而不是從屏幕上複製粘貼數字的文書工作。
關鍵瓶頸:學術數據集的標準化
研究中的主要痛點是資料格式標準化困難,導致圖表和統計結果不一致。在處理學術資料 Excel 時,研究人員經常面臨來源零散的局面。一所大學可能以特定的 PDF 格式發布其捐贈基金報告,而聯邦撥款機構則使用另一種格式。當您嘗試為縱向研究匯總這些資料時,缺乏標準化會產生「資料漂移」,這可能會破壞您的統計顯著性。
想像一下,試圖在三個不同的資料集中運行迴歸分析,其中日期的格式不同,貨幣符號的應用也不一致。這不僅僅是小麻煩;它會在對帳過程中導致巨大錯誤。如果一個來源的總帳資料對「淨資產」的計算方式與另一個來源不同,那麼您最終的學術資料 Excel 輸出將成為負擔,而不是資產。手動輸入是這裡的敵人。隨著疲勞的累積,人類開始對小數點的位置或如何截斷長字串做出「創意」決定。當您按下「計算」按鈕時,這些微小的決定會滾雪球般地變成一場災難。
標準化需要對結構的堅定承諾。您需要一個不僅能讀取文字,還能理解表格拓撲結構的系統。我們正在討論識別多層標題、處理合併儲存格以及維護巢狀列的完整性。沒有研究資料自動化,您基本上是在要求您的研究助理充當人類掃描器,這是一個既昂貴又容易導致高離職率的角色。目標是達到這樣一種狀態,即資料在離開 PDF 的那一刻就已經「Excel 就緒」。這意味著在資料觸及您的分析軟體之前,就進行預先清理、預先格式化,並確保每個學術資料 Excel 檔案都遵循嚴格的結構描述。
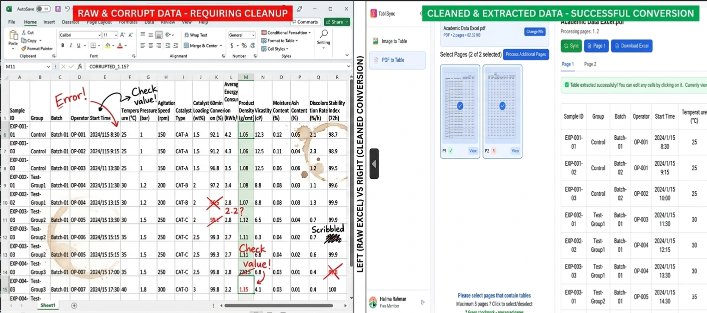
技術深入探討:手動輸入與 TabliSync 自動化
讓我們看看冷酷的數字。當我們討論 Academic Data Excel 時,「營運成本」通常以工時計。對於一個典型的研究項目,涉及 500 頁的財務披露,熟練的人工操作員每頁需要大約 4-6 分鐘來準確轉錄一個複雜的表格。這大約是 40-50 小時的工作。以研究助理的費率計算,這將導致顯著的預算損失。此外,手動輸入的 Error Rate 對於密集數值數據通常在 3-5% 之間。
| 功能 | 手動數據輸入 | TabliSync 自動化 |
|---|---|---|
| 處理速度 | 每頁 4-6 分鐘 | 每頁 3-10 秒 |
| 準確率 | 95% - 97% (疲勞時下降) | 99.5% + (一致的 OCR 精確度) |
| 批次處理 | 不可能 (串聯任務) | 支援 (可同時處理 1000+ 頁) |
| 每 100 頁成本 | 約 $400 - $600 (勞力) | 約 $10 - $20 (API/SaaS 點數) |
| 核對 | 需要手動交叉檢查 | 透過 Webhook 自動化 General Ledger 匹配 |
Efficiency 的提升不僅僅是速度;而是 Cost Savings。在一項涉及一所主要歐洲商學院的案例研究中,該部門每年僅在學生勞力數據提取上就花費了 15,000 歐元。在透過 TabliSync 實施 automated table extraction 後,他們將此支出減少到 1,200 歐元以下。更重要的是,洞察時間被大大縮短。過去需要一個學期才能完成的準備工作,現在可以在三天內準備好進行 Academic Data Excel 分析。這就是 research data automation 的力量:它改變了資訊的經濟學。
TabliSync 工作流程:3 步驟大師班
處理 Academic Data Excel 不必是一門黑暗藝術。我們設計了一個工作流程,優先考慮 Batch PDF processing,同時不犧牲高風險研究所需的細粒度控制。請遵循以下步驟來最大化您的產出。
步驟 1:智能導入和預處理
首先,您必須匯總您的來源。無論它們是掃描的歷史文件還是數位原生 PDF,TabliSync 的 複雜財務 OCR 引擎都需要分析文件層。您不只是「上傳」;您需要定義 資料結構。例如,如果您正在提取 總帳,您必須識別「借方」和「貸方」欄。我們的系統使用 電腦視覺 來偵測線條和空白,在讀取任何字元之前建立結構圖。注意:為獲得最佳 學術資料 Excel 結果,請務必確保您的掃描解析度至少為 300 DPI。較低的解析度可能導致「字元幻覺」,尤其是在學術註腳中常見的小字體中。
步驟 2:自動化表格擷取與精煉
一旦文件被映射,自動化表格擷取 就開始了。TabliSync 不僅僅是「抓取」文字;它會重建表格邏輯。如果一行跨越兩頁——這是 學術資料 Excel 中常見的噩夢——軟體會使用 上下文連結 將它們重新組合起來。您可以即時預覽擷取結果。在這裡,您可以套用 資料清理 規則。例如,您可以指示系統「忽略所有包含 Total 字元的行」或「將所有日期轉換為 ISO 8601 格式」。這種程度的 研究資料自動化 確保進入您試算表的資料已經是乾淨的。如果您有需要在擷取過程中驗證的特定學術識別碼(例如 DOI 編號),請使用「自訂 Regex」功能。
步驟 3:透過 Webhook 匯出與整合
最後一步是提取資料。雖然學術資料 Excel 是標準,但 TabliSync 支援進階的對帳工作流程。您可以設定Webhook,將提取的資料直接推送至您的統計軟體或集中式資料庫。如果您偏好傳統方法,Excel 匯出功能已針對樞紐分析表進行優化。我們確保數字以數字形式匯出,而非文字,從而省去 Excel 中「綠色三角形」錯誤的麻煩。專業提示:使用我們的「範本」功能。如果您有來自同一來源的 500 份報告,只需定義一次提取區域,然後讓批次 PDF 處理處理其餘部分,您就可以去喝杯咖啡了。

進階用例:管理補助金中的複雜財務 OCR
補助金管理是大學的命脈,但它也產生了一些最混亂的資料。在財務背景下處理學術資料 Excel 時,您不僅僅是尋找姓名;您還在尋找稽核軌跡。這裡需要複雜的財務 OCR,因為補助金報告通常包含手寫簽名、橡皮圖章和重疊的文字——所有這些都可能讓標準軟體感到困惑。
我們最近協助一個研究小組分析了 30 年的 NIH 補助金分配。這些資料被鎖在數千份掃描的備忘錄中。透過利用研究資料自動化,我們能夠提取總帳代碼並將其與大學的內部支出記錄進行對帳。通常需要手動驗證每一行的對帳流程,現在自動化了 80%。系統僅標記 OCR 信賴度低於 90% 的行,讓研究人員能夠專注於邊緣案例。這種處理學術資料 Excel 的方法確保最終資料集是「稽核就緒」的。這關乎為您的資料建立保管鏈,確保您試算表中的每個儲存格都可以追溯到原始 PDF 來源上的對應位置。
確保研究資料的信任與合規性
在學術數據 Excel的世界裡,信任至關重要。如果您的數據提取過程是一個「黑盒子」,您的同行就無法複製您的結果。這就是為什麼研究數據自動化必須透明。TabliSync 為每次提取提供完整的審計日誌。我們還遵守GDPR和FERPA標準,確保敏感的學生或參與者數據以企業級加密處理。 此外,在處理用於發表的學術數據 Excel時,您必須遵守FAIR原則(可查找、可訪問、可互操作和可重用)。手動數據輸入是 FAIR 的反面,因為它是模糊的,並且容易出現未記錄的「修復」。通過使用自動化表格提取,您可以創建一個可重複、已記錄的管道。如果審稿人詢問您如何得出某個數字,您可以指出特定的 TabliSync 模板和原始源文件。這種程度的專業知識和權威性是區分高影響力研究與其他研究的關鍵。您不僅僅是一名研究人員;您還是一名數據管理者。Webhook 在現代研究工作流程中的作用
為什麼要停留在靜態文件?當學術數據 Excel成為一個活躍生態系統的一部分時,其真正的力量才能被釋放。這就是Webhook發揮作用的地方。Webhook本質上是一個數字信使。TabliSync 完成一批 PDF 處理的瞬間,就可以將「ping」發送到另一款軟件——例如,您部門的ERP系統或自定義的 Python 腳本——並攜帶數據。對於專案負責人來說,這意味著您可以建置一個自動化儀表板。當您的團隊上傳新的現場報告或實驗室結果時,學術資料 Excel 主檔會即時更新。您不再需要等待每週的「資料傾印」。這是最先進的研究資料自動化。它實現了敏捷研究,可以根據可用的最新資訊做出決策。如果總帳顯示實驗室設備成本突然飆升,您會立即看到,而不是在手動輸入最終完成三週後才看到。這就是SaaS 的優勢:從靜態文件轉向流動的數據流。
案例研究:大規模縱向社會學研究
考慮「城市成長專案」,這是一項涉及 10,000 多筆歷史人口普查記錄的跨數十年研究。這些記錄原本並非為電腦設計。它們是多欄、多頁的龐然大物。該團隊最初嘗試了「眾包」手動輸入方法,但他們產生的學術資料 Excel 由於對人口普查標題的解釋不同而充滿錯誤。
透過切換到 TabliSync 的批次 PDF 處理,他們建立了一個單一的「真相來源」。我們開發了一個自訂的提取模型,能夠理解 1950 年代的排版風格。結果如何?學術資料 Excel 檔案的準確性比人工抄寫的版本高出 40%。該專案節省了超過 2,000 小時的勞力,這使他們能夠將研究範圍擴展到另外兩個城市。這不僅僅是「節省時間」;而是關於擴展研究的可能範圍。當資料成本下降時,研究價值就會上升。

克服「非標準」文件挑戰
學術數據 Excel 最困難的部分是「非標準」文件。您知道的,就是那種表格傾斜 15 度,或者「總計」欄位上有咖啡漬。標準的 OCR 在這裡會失效。TabliSync 使用 基於神經網絡的圖像修復 在提取開始前「清理」文件。我們校正圖像傾斜,增強對比度,並去除數字噪點。
這對於 研究數據自動化 至關重要,因為學術檔案很少是完美的。如果您正在為經濟思想史項目處理 複雜的金融 OCR,您將面對泛黃且脆弱的紙張。我們的技術首先將文件視為實體對象,在嘗試讀取文本之前重建其幾何結構。這確保您的 學術數據 Excel 不會出現頁面中間欄位開始偏移的「漂移」現象。精確性不是可選項;它是學術界 信任 的基石。
常見問題
TabliSync 如何處理學術數據 Excel 中的多頁表格?
處理跨越多頁的表格是我們 自動表格提取 的核心功能。與將每頁視為獨立個體的基礎爬蟲不同,TabliSync 使用 標頭持久性邏輯。它識別第一頁的欄位標頭,並在處理後續頁面時「記住」它們。這使得系統能夠無縫地將行合併為一個單一、連續的 學術數據 Excel 工作表。例如,如果一份 總帳 報告跨越 50 頁,TabliSync 將生成一個統一的表格,而不是 50 個零散的表格,從而保持您的 對帳 流程的完整性,並節省數小時的手動合併時間。
我能將手寫筆記或註釋處理到 Excel 中嗎?
雖然 Academic Data Excel 主要專注於結構化文本,但我們的 複雜金融 OCR 包含一個專用的 HTR(手寫文字辨識)模組。這對於處理檔案補助金或實驗室筆記的研究人員特別有用,因為圖表可能手寫在邊緣。該系統可以針對特定書寫風格進行訓練,將其轉換為試算表中的數位儲存格。然而,為了達到最高的 研究資料自動化 效率,我們建議將其用於「補充資料」,而不是主要資料集,因為手寫文字本質上比打字文字需要更高的驗證要求。
敏感研究資料的安全協定是什麼?
安全性已內建於我們的 研究資料自動化 框架中。我們了解 Academic Data Excel 通常包含敏感的 PII(個人識別資訊)或專有的 總帳 資料。TabliSync 在靜態資料和傳輸中資料都使用 AES-256 加密 和 TLS 1.3。我們符合 SOC2 Type II 標準,並為要求資料保留在特定地理邊界(如歐盟)內的機構提供「資料駐留」選項。我們還提供一個 塗銷功能,可以在 批次 PDF 處理 階段自動塗銷敏感姓名或 ID,確保符合隱私權法律。
TabliSync 是否支援非英文學術文件?
是的,我們的 自動化表格擷取 引擎支援多種語言。我們支援超過 40 種語言,包括中文、日文和阿拉伯文等複雜腳本。這對於您可能正在與國際合作夥伴對帳 總帳 資料的全球性 Academic Data Excel 專案至關重要。該系統在整個擷取過程中都會維護字元編碼 (UTF-8),確保特殊字元、重音符號和符號在最終的 Excel 檔案中正確顯示,而不會出現可怕的「亂碼」或亂碼文字。這種程度的 專業知識 可確保您的國際研究保持準確和專業。
如何將 TabliSync 與我現有的統計工具整合?
最有效的方法是透過我們的Webhook架構。一旦學術資料 Excel提取完成,TabliSync 即可觸發 POST 要求至您的伺服器或 Zapier 等第三方整合器。這讓您可以自動將資料移至 Stata、R 或 Python 環境等工具。對於技術較不熟悉的使用者,我們提供與 Google Drive、Dropbox 和 OneDrive 的直接雲端整合。這確保您的研究資料自動化流程是「無縫的」—資料從 PDF 直接進入您的分析就緒資料夾,而無需您手動點擊「下載」或「上傳」。
TabliSync 能否處理像粗體或斜體文字等複雜的儲存格格式?
絕對可以。在生成學術資料 Excel時,TabliSync 可以設定為保留原始 PDF 的「富文本」屬性。這在粗體數字表示統計顯著性或斜體用於科學命名法時非常重要。我們的自動表格提取不僅僅是提取原始字串;它可以捕捉儲存格的元數據。這意味著您的試算表可以反映原始文件的視覺線索,使最終審核輸出的研究人員的對帳和審查過程更加直觀。
如果 PDF 的表格佈局非常不標準,會發生什麼情況?
這就是 TabliSync 的「區域 OCR」發揮作用的地方。如果自動表格提取 AI 無法自動偵測到非常創意或混亂的佈局,您可以手動繪製「提取區域」。您可以精確定義欄和列的位置,系統會將其儲存為範本。對於未來具有相同格式的任何文件,批次 PDF 處理將遵循您的自訂映射。這將研究資料自動化的強大功能與人工監督的精確性相結合,確保即使是最「不可能」的學術資料 Excel任務也能以 100% 的結構準確性完成。
一次可以處理的檔案數量有限制嗎?
我們的批次 PDF 處理引擎專為高吞吐量而設計。我們曾為全校範圍的審計處理過多達 50,000 頁的批次。該系統利用彈性擴展,這意味著它會隨著佇列的增長而啟動更多的計算能力。對使用者而言,這意味著無論您是處理一個學術資料 Excel 檔案還是一千個,每頁的等待時間都保持在非常低的水平。這就是效率的定義——提供一個與您的研究抱負同步擴展的工具,而不是阻礙它們,確保您的總帳始終保持最新。
學術機構的定價如何運作?
我們為高等教育提供專門的SaaS級別。我們理解學術資料 Excel 專案通常由補助金資助,因此我們為各部門提供「即用即付」模式和年度「無限」授權。這種靈活性使研究人員能夠在他們的補助金提案中考慮節省成本。透過自動化研究資料自動化,您可以向資助者展示您如何透過減少管理開銷和增加每花費一美元可分析的資料量來最大化他們的投資。
TabliSync 中的「對帳」功能是什麼?
對帳是我們的高級驗證工具。它允許您將提取的學術資料 Excel 資料與第二個來源進行交叉比對。例如,如果您從 PDF 中提取總帳資料,TabliSync 可以自動檢查總計是否與現有的 CSV 檔案或資料庫條目相符。如果存在差異,系統會標記特定儲存格以供審查。這是複雜金融 OCR 的重要組成部分,因為它提供了第二層防禦,防止錯誤,確保您的研究建立在經過驗證、萬無一失的資料基礎之上。
研究的未來是自動化的
轉向研究數據自動化不再是奢侈品;對於任何認真追求高影響力學術研究的人來說,這都是必需的。您花在手動將數據鍵入學術數據 Excel 表格中的每一小時,都是從分析、綜合和發現中竊取的時間。我們已經進入了一個自動表格提取和複雜金融 OCR 是實驗室的「無聲英雄」的時代,它們在後台工作,確保您依賴的數據與您測試的理論一樣準確。
採用 TabliSync,您不僅僅是購買軟體;您是在升級您的整個研究方法。您正在從一個「數據摩擦」的世界——其中每個 PDF 都是一個障礙——轉變為一個「數據流」的世界,其中信息無縫地從源頭流向電子表格。效率和成本節約是顯而易見的,但真正的獎勵是知道您的數據經過標準化、核對並準備好供世界查看所帶來的清晰思維。是時候停止做數據錄入員,開始做您被培養成的有遠見的研究者了。您的發現速度不應受鍵盤速度的限制。
抓住機會:立即自動化您的學術數據 Excel
您已經看到了數據、技術比較和工作流程。您研究中的瓶頸不是您的才能——而是您的工具。您延遲實施研究數據自動化的每一天,都是在手動輸入的真空中又損失一天。想像一下,如果您的學術數據 Excel 文件能在幾秒鐘內而不是幾週內生成,您能取得什麼成就。想想那些由於「太大」而無法處理的批量 PDF 處理任務,它們目前正在積滿數字灰塵。那些項目現在觸手可及。
TabliSync 由了解學術界嚴謹性的人們打造。我們知道,總帳中一個微小的數字錯誤就可能使數月的工作無效。這就是為什麼我們打造了一個重視精確性、速度和對帳的工具。不要讓您的研究被傳統的工作流程所阻礙。點擊下方連結開始免費試用。親身體驗自動表格擷取的力量,看看如何在下次會議前將 5,000 頁的資料轉換為乾淨、有條理的 Excel 表格。您的研究未來正等待著您。加入數千名已經找回時間的學術界人士的行列。立即開始使用 TabliSync,將您的資料混亂轉化為研究清晰。
什麼是 如何快速處理學術數據 Excel?
關於 如何快速處理學術數據 Excel 的快速解答,以及 TabliSync 如何加速 Excel 工作。
什麼是 如何快速處理學術數據 Excel?
如何快速處理學術數據 Excel 涵蓋實務 Excel 流程、常見陷阱與自動化模式。本 TabliSync 指南說明概念、範例並連結相關教學。
TabliSync 如何協助 如何快速處理學術數據 Excel?
TabliSync 可從截圖或 PDF 擷取表格、整理雜亂資料,並自動化與 如何快速處理學術數據 Excel 相關的重複 Excel 任務。
應從哪裡開始學習 如何快速處理學術數據 Excel?
先閱讀本頁總覽,再開啟下方相關文章,取得逐步教學與 AI 輔助流程。
所有 學術數據 Excel 文章(6)

如何計算兩個日期之間的差異天數
在本指南中,我們將引導您完成使用試算表軟體計算兩個日期之間天數的過程。這項關鍵技能可應用於各種商業情境,例如專案管理和財務報告。我們將為您提供清晰的分步方法,以設置您的試算表進行日期計算,並附帶實用範例,說明理解日期差異至關重要的常見情況。此外,我們還將分享確保準確性的技巧,例如如何處理閏年和格式化問題。閱讀本文後,您將有信心有效地執行日期計算,並探索 TabliSync 如何協助您組織數據以獲得更高的效率。

如何在 Excel 中同時使用 IF 和 AND 函數
本文將引導使用者完成在 Excel 中合併 IF 和 AND 函數的流程,協助他們提升數據分析和報告能力。透過逐步說明和實際範例,讀者將能增強其試算表技能。透過了解如何有效地將這些函數結合使用,使用者可以創建更複雜的邏輯測試,這對於準確的報告和商業決策至關重要。文章將探討常見的用途,並提供避免常見錯誤的技巧。無論您是會計師、財務團隊成員還是數據分析師,本指南都將提供必要的工具,以提升您的 Excel 熟練度並簡化您的工作流程。

如何在 Excel 中製作帶有百分比的圓餅圖
在當今數據驅動的世界中,有效可視化信息對於企業成功至關重要。本文將提供一份清晰實用的指南,介紹如何使用 Excel 中的百分比數據創建圓餅圖。無論您是處理財務報告的會計師,還是將銷售數據轉換為視覺格式的分析師,圓餅圖都能增強理解和呈現效果。請按照概述的步驟創建準確反映您數據的圓餅圖,並發現自定義技巧以提高清晰度和影響力。此外,還可以了解 TabliSync 如何協助準備這些視覺化表示的數據,從而使過程更順暢、更有效。閱讀本文後,您將具備視覺化呈現數據的技能,確保您能有效傳達信息,並基於準確的表示做出明智的決策。

如何在 Excel 中移除分頁符
了解分頁符是什麼以及它們在 Excel 中為何重要,遵循逐步說明移除它們,並學習管理試算表中分頁符的實用技巧。

掌握資料完整性:如何在 Excel 中建立下拉式清單
透過實施標準化的 Excel 資料驗證協定,消除 99% 的手動資料輸入錯誤。 透過使用動態下拉式清單和結構化表格,將資料清理時間減少 90%。 利用由 AI 驅動的光學字元辨識 (OCR) 和 TabliSync,將非結構化的實體資料即時轉換為已驗證的 Excel 結構描述。 為您的試算表打造可擴展、可搜尋的下拉式結構,以處理複雜的資料集,實現未來就緒。

掌握混亂:如何在 Excel 中移除重複資料且不遺失資料
效率提升:利用自動化工作流程,將手動資料清理時間減少 90% 以上。 資料完整性:透過從「尋找與取代」轉向基於結構描述的重複資料刪除,實現 0% 的手動輸入錯誤率。 風險緩解:利用非破壞性的 Power Query 環境,防止 100% 的意外刪除。 未來保障:透過 AI 整合自動化,從被動清理轉向主動資料衛生。
告別手動輸入 – 秒速提取表格數據
將任何圖片或 PDF 表格即時轉換為 Excel,準確率達 99.9%。TabliSync 的 AI OCR 可處理手寫表單、收據和複雜表格,並直接同步到 Google Sheets、Notion 或 Airtable
立即免費試用 TabliSync