Article Summary
執行摘要:在這份 2026 年手寫識別 (HWR) 的權威指南中,我們彌合了手寫筆記與數位智能之間的鴻溝。隨著美國企業努力實現 100% 的數據數位化,手動轉錄已成為一個成本高昂的瓶頸。此主題頁面探討了由 AI 驅動的 HWR 的演進—從 RNN 和 LSTM 神經網絡到結構化表格重建。無論您是正在數位化手寫的現場報告、醫療機構的登記表單,還是歷史檔案,您都將了解現代 HWR 如何實現 99% 的準確度,確保 HIPAA/SOC2 合規性,並將行政管理費用降低 95%。
數世紀以來,筆一直是捕捉人類思想的主要工具。即使在我們高度數位化的 2026 年經濟中,數百萬個關鍵業務數據點仍以手寫方式記錄——在建築工地日誌、醫療登記表、倉庫揀貨單和法律筆記中。現代企業面臨的挑戰不再僅僅是「儲存」這些文件,而是要解鎖其中的數據。這正是手寫辨識 (HWR) 技術成為數位轉型的終極橋樑之處。
簡介:為何手寫辨識是數據自動化的最後疆域
儘管平板電腦和智慧型手機無處不在,但在高壓或流動的環境中,手寫仍然是記錄資訊最快、最直觀的方式。然而,手寫數據傳統上是「類比」的,這意味著它與您的 ERP、CRM 和分析引擎斷開連接。手動轉錄這些記錄不僅耗費人力資本,而且是造成數據完整性問題的主要來源,手動輸入錯誤率高達 4%。
現代手寫辨識早已超越了簡單的字元比對。利用深度學習和神經網路,TabliSync 等工具現在可以準確度高達 99% 地辨識潦草、草書甚至模糊的手寫字跡。在本綜合指南中,我們將探討這項技術的機制,以及它如何徹底改變那些拒絕放下筆的行業。
---
第一章:HWR 的演變——從模式比對到神經上下文
為了選擇正確的數位化策略,了解從傳統光學字元辨識 (OCR) 到現代智慧手寫辨識 (IHR) 的技術飛躍至關重要。
1. 傳統 OCR 的失敗
傳統 OCR 是為「字體」設計的——例如 Arial 或 Times New Roman 等一致、可預測的字體。當面對人手寫的可變筆劃、傾斜度和壓力時,傳統系統就會失敗。它們將有意義的內容視為「雜訊」。這就是為什麼許多美國公司放棄了早期的自動化嘗試;「清理」工作比打字花費的時間更長。
2. 遞歸神經網路 (RNN) 的興起
今日的手寫辨識利用RNN和長短期記憶 (LSTM) 網路。與標準人工智慧不同,這些模型不僅僅是看一個靜態的形狀;它們理解筆劃的序列。它們會「觀察」數位墨水的流動,以判斷一個圓圈是「o」、「0」還是「g」的一部分。這種序列智慧是解讀草書和潦草筆記的秘密。
3. 語義和語言上下文
頂級的 HWR 引擎現在整合了自然語言處理 (NLP)。如果一個單字難以辨識,但出現在「請簽名」之後,AI 會利用語言機率來判斷這是一個名字或簽名。在手寫表格轉 Excel 的工作流程中,如果一個字元位於「日期」欄位,AI 就知道要將一個垂直筆劃解釋為「1」,而不是「I」或「l」。
---
第二章:TabliSync 引擎——大規模手寫辨識
TabliSync 設計了一個專門的管道,專門針對「工業之手」——在真實專業環境中發現的匆忙、經常雜亂的書寫。

圖 1:TabliSync 的 AI 即時識別和分割複雜的手寫筆劃。
第一階段:影像修復(傾斜與去噪)
在多風的建築工地拍攝的手寫日誌照片永遠不會完美。我們的引擎執行動態對比增強,將模糊的鉛筆痕跡與紙張背景分離,並使用透視校正來拉平以某個角度拍攝的文件的透視。
第二階段:結構重建
大多數手寫內容都存在於表格中。TabliSync 的神經表格重建 (NTR) 首先識別網格線(或隱含的行)。然後,它將每個手寫單詞錨定到特定的單元格坐標 (A1, B2)。這確保了在導出數據時,「材料數量」不會意外地出現在「日期」列中。
階段 3:字符級置信度評分
我們手寫識別引擎處理的每個單詞都會被分配一個置信度分數。如果簽名或塗鴉的置信度低於 95% 的閾值,它將被標記出來,以便在並排編輯器中由人工快速驗證數據,然後再將其輸入數據庫。這種「人機協作」的方法保證了關鍵任務記錄的 100% 準確性。
---
第 3 章:主要用途—HWR 如何推動投資回報率
手寫識別不再是「炫技」——它是美國經濟中一個數十億美元的效率驅動因素。
1. 建築和現場服務
現場技術人員和工頭經常在平板電腦不實用的環境中工作(極端高溫、灰塵或戴手套工作)。他們依賴紙質日誌。
- 影響:將手寫的每日進度報告 (DPR) 轉換為 Excel,使項目經理能夠實時跟踪勞動力成本和材料使用情況,從而防止預算超支。
2. 法律和歷史檔案歸檔
律師事務所和歷史學會處理大量的 كتب 手寫賬本和證詞。
- 轉變:將 50 年的手寫案件筆記轉換為可搜索的 PDF 和有組織的電子表格,以便快速檢索和訴訟支持。
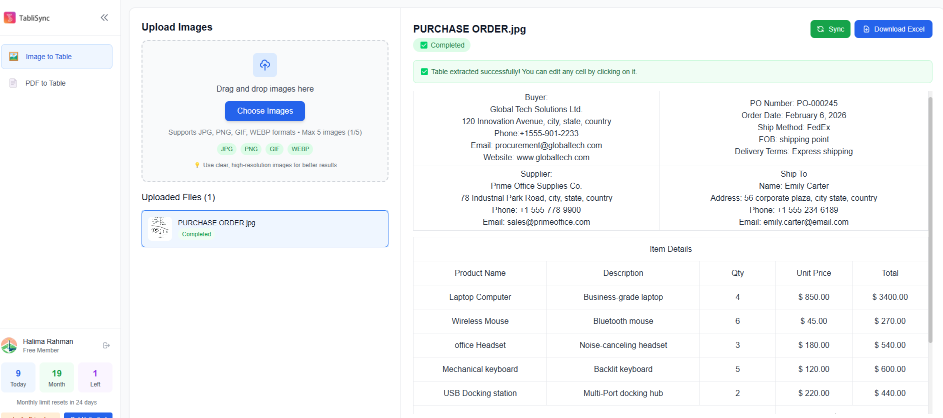
圖 2:專業文檔歸檔,展示高速手寫識別將歷史賬本轉換為可搜索的數字電子表格。
第四章:企業擴展—手寫識別 API
對於大型美國企業而言,目標不僅僅是識別一張手寫紙,而是將手寫識別 (HWR) 整合到全球數據管道中。TabliSync 的 RESTful API 允許開發人員將高精度 HWR 直接嵌入行動應用程式、文件管理系統 (DMS) 和 ERP 平台。
1. 建構「行動到主機」管道
在物流或保險理賠等行業中,數據之旅始於現場。工作人員會拍攝手寫提貨單或損壞理賠表格的照片。透過 TabliSync API,以下操作可在亞秒級內完成:
- 非同步擷取:高解析度 JPG 上傳至 HWR 端點。
- 神經解譯:AI 在識別手寫風格並提取文字的同時,保持表格的結構完整性。
- JSON 輸出:API 不僅返回文字檔案,還會返回結構化 JSON 物件,將手寫欄位對應到特定的資料庫金鑰 (例如,
"claim_amount": "1250.00")。

圖 3:透過 TabliSync API 建構自動化手寫到數據的工作流程。
2. 處理「工業之手」—草書和傾斜校正
美國開發者選擇 TabliSync 的主要原因之一是我們專有的傾斜與扭曲校正。手寫文字很少是水平的。我們的 API 會自動偵測手寫文字的基線,並在辨識前「虛擬拉直」筆劃,這對於在草書和潦草字跡中維持高準確度至關重要。
---
第五章:手寫自動化的投資報酬率——量化效率
高階主管通常認為手寫辨識是「錦上添花」,直到他們看到其對底線的影響。手動資料輸入不僅是一項費用項目;它是一個瓶頸,會延遲計費、減緩專案時程,並因錯誤而產生重大的下游成本。
「轉錄稅」細項分析
假設一家專業醫療診所或律師事務所每月處理 2,000 份手寫的登記表或證據開示表。
- 手動轉錄: 每頁 8 分鐘 x 2,000 頁 = 266 小時。以美國平均行政人員時薪 28 美元計算,每月成本為7,448 美元。
- TabliSync HWR: 每頁 30 秒的人工驗證 = 16.6 小時。總勞動力成本:每月464 美元。
結論: 透過實施自動化的手寫辨識工作流程,該組織每年可節省超過83,000 美元,同時將「訂單到收款」週期從數天縮短至數分鐘。
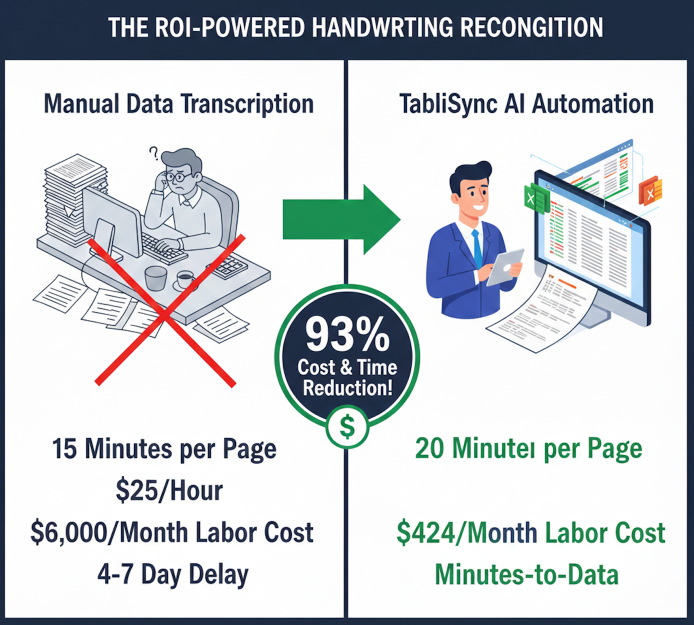
圖 4:自動化手寫數位化的經濟效益分析。
---
第六章:解決 HWR 的「真實世界」挑戰
在受控的實驗室環境中,手寫辨識 (HWR) 很容易。但在真實世界中—無論是在下雨的建築工地或顛簸的貨車上—它卻極其困難。TabliSync 就是為這些「邊緣案例」而設計的。
1. 「摺痕紙張」問題
現場文件經常被摺疊、弄髒或產生摺痕。我們的 陰影移除 和 幾何校正 演算法會將數位影像「攤平」,消除摺痕造成的暗線,否則這些暗線會讓標準 OCR 引擎感到困惑。
2. 多筆跡和多作者偵測
一份表格可能由三個人使用三種不同的筆 (藍色墨水、黑色墨水、鉛筆) 填寫。我們的 AI 使用 多作者正規化,識別每位書寫者的獨特筆劃特徵,以在整個文件中保持一致的辨識準確度。
3. 詮釋「劃線刪除」和註釋
在專業環境中,人們經常劃線刪除內容或在頁邊空白處書寫。TabliSync 的 語義層 能理解這些「修正」。它可以區分故意的劃線刪除 (應忽略或刪除) 和字元筆劃,確保最終的 Excel 或資料庫條目反映書寫者的*最終意圖*。
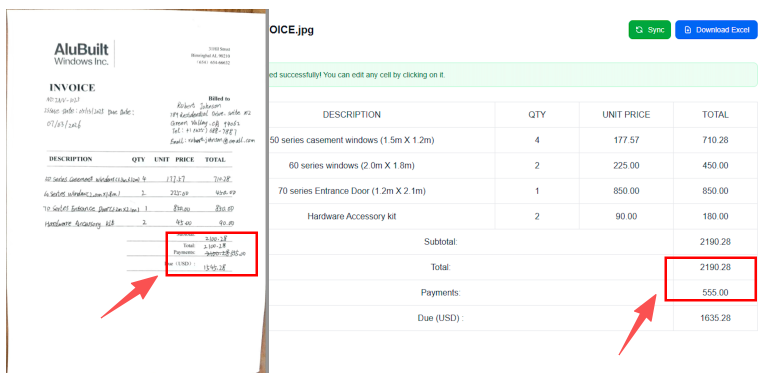
圖 5:TabliSync 能準確識別專業文件中的修正和頁邊空白註釋。
---
第七章:比較—HWR 與標準 OCR
許多美國公司都會犯下一個錯誤,那就是使用「標準」OCR 工具來處理手寫文字。此比較突顯了為何專業工作需要專門的手寫辨識引擎。
| 功能 標準 OCR TabliSync HWR (AI 驅動) | ||
| 草寫辨識 | 準確度幾乎為 0%。 | 透過 RNN/LSTM 達成高準確度。 |
| 筆劃分析 | 僅能辨識像素的「區塊」。 | 分析書寫的「流暢度」和順序。 |
| 上下文推測 | 無。 | 使用 NLP 根據句子邏輯預測單字。 |
| 約束處理 | 受線條和方塊干擾。 | 使用 NTR 將書寫內容錨定到表格儲存格。 |
第 8 章:HWR 中的安全性、合規性和數據主權
在美國,手寫辨識通常涉及高度敏感的文件——病患的醫療記錄、手寫的法律遺囑或聯邦現場報告。由於這些文件包含個人身分資訊 (PII),用於將其數位化的技術必須遵守嚴格的法規框架。
1. HIPAA 和 SOC2 Type II 合規性
對於美國的醫療保健提供者而言,數據隱私受 HIPAA 管轄。TabliSync 提供專門的符合 HIPAA 標準的 HWR 流程。這包括:
- 端對端加密:所有手寫影像在處理過程中均使用 AES-256 標準進行加密。
- 稽核軌跡:記錄與文件互動的每一次操作,確保敏感醫療數據有清晰的保管鏈。
2. 「隱私優先」AI 模型
現代 AI 的一個常見問題是「模型洩漏」。許多免費的 HWR 工具會使用您上傳的手寫樣本來訓練其公開模型。TabliSync 提供私人 AI 環境。您的手寫資料會在「沙盒」中處理,絕不會用於改進全域模型,確保您的專有或私人資料仍由您掌控。
3. 提取時的編輯
我們的 HWR 引擎包含「智慧模糊」功能。如果 AI 偵測到社會安全號碼或私人簽名,可以設定為在最終的手寫轉 Excel 或PDF 輸出中自動編輯這些欄位,從而降低您組織的責任。
---
第九章:終極手寫辨識常見問題解答
為了幫助您順利從紙筆轉向數位資料,我們匯總了來自北美專業社群的 20 個最關鍵問題。
技術與準確性查詢
1. AI 真的能讀懂我潦草的字跡嗎?
可以。雖然沒有 AI 是 100% 完美的,但 TabliSync 使用遞歸神經網路 (RNN) 來觀察書寫的上下文和流程,在處理匆忙寫成的字跡時,其表現常常優於人工抄寫員。
2. 印刷體字母或草書哪種效果更好?
我們的引擎經過雙重訓練。雖然印刷體(塊狀)字母更容易映射,但我們的LSTM(長短期記憶)模型專門用於解碼草書連筆的筆劃。
3. 它如何處理不同顏色的墨水或鉛筆?
我們的預處理層使用亮度標準化來創建高對比度,讓 AI 能夠在白色或黃色背景上「看到」模糊的鉛筆痕跡或淺藍色墨水。
4. 如果一個單字完全無法辨識怎麼辦?
系統會以「低信心」分數標記該單字。在TabliSync 編輯器中,該單字會以紅色高亮顯示,讓人工可以在幾秒鐘內與原始圖像進行核對。
5. 它能辨識數學符號和科學記號嗎?
可以。我們有針對工程和醫學領域的專門模組,可以辨識標準符號(例如 Δ、Ω、μ)和複雜的數字記法。
格式與匯出查詢
6. 我可以直接將手寫表格轉換為 Excel 檔案嗎?
當然可以。我們的 神經表格重建 (NTR) 會識別網格,並將每個手寫的值放入其對應的 Excel 儲存格 (A1、B2 等)。
7. 您如何處理「刪除線」和更正?
該 AI 經過訓練,能夠識別「刪除筆劃」。它會忽略被劃掉的文字,並優先處理寫在上方或旁邊的更正文字。
8. HWR 能維持表單的原始版面配置嗎?
是的。我們提供「空間保留」,確保數位輸出能反映您實體紙本表單的視覺結構。
9. 我可以將手寫筆記匯出為可搜尋的 PDF 嗎?
是的。TabliSync 可以在您的 PDF 上建立 OCR 疊加層,讓您可以使用 Ctrl+F 在掃描文件中尋找手寫的單字。
10. 它支援非英文手寫嗎?
我們目前支援 50 多種語言。這對於擁有跨語言員工或國際業務的美國公司至關重要。
產業與整合查詢
11. 是否有供開發人員使用的 API?
是的。我們的 RESTful HWR API 可輕鬆整合到行動應用程式 (iOS/Android) 和企業 ERP 系統,如 SAP 或 Oracle。
12. 我一次可以處理多少頁的批次?
我們的企業方案支援一次批次上傳最多 1,000 頁,非常適合將數十年的檔案數位化。
13. AI 能區分同一頁上多個人的書寫嗎?
是的。我們的 作者識別 邏輯可以區分不同的書寫風格,這對於多簽名合約至關重要。
14. 它適用於平板電腦,還是只能用於紙張照片?
兩者皆可。它可以處理照片/掃描檔的「靜態墨水」以及觸控筆式平板電腦的「數位墨水」。
15. 這能為我的行政團隊節省多少時間?
平均而言,美國公司在改用自動化 HWR 後,數據輸入時間減少了 90-95%。
安全性與政策查詢
16. TabliSync 是否符合 SOC2 標準?
是的。我們每年都會接受第三方稽核,以確保我們的數據處理符合美國最高的安全標準。
17. 軟體會永遠儲存我的文件嗎?
不會。您可以設定一個自動刪除政策。轉換完成後,原始影像可以立即從我們的伺服器中清除。
18. 我可以將這個手寫辨識引擎託管在我自己的私人伺服器上嗎?
對於高安全性需求的政府或國防客戶,我們提供本地部署選項。
19. 手寫辨識的定價模式是什麼?
我們為小型專案提供「按用量付費」模式,為企業級數位化提供「基於用量的訂閱」模式。
20. 如何開始?
您可以在我們的網站上註冊免費試用,以測試您特定的手寫樣本與我們的引擎的相容性。
---
結論:數據的未來由手寫定義
2026 年手寫辨識的目標不是取代筆,而是賦予它力量。透過消除手動的「轉錄稅」,組織終於可以將手寫文件視為動態數據資產,而不是靜態的紙本負擔。
無論您是建築工地的專案經理、法庭上的律師,還是診所裡的醫生,TabliSync 都提供您將手寫想法轉化為數位行動所需的精確度和安全性。類比世界與數位世界之間的鴻溝終於被彌合。
準備好數位化您的手寫內容了嗎?
體驗市場上最先進的手寫辨識技術。立即開始您的免費試用,將您的筆記轉化為可操作的數據。
什麼是 2026 指南:AI 手寫轉數位資料?
關於 2026 指南:AI 手寫轉數位資料 的快速解答,以及 TabliSync 如何加速 Excel 工作。
什麼是 2026 指南:AI 手寫轉數位資料?
2026 指南:AI 手寫轉數位資料 涵蓋實務 Excel 流程、常見陷阱與自動化模式。本 TabliSync 指南說明概念、範例並連結相關教學。
TabliSync 如何協助 2026 指南:AI 手寫轉數位資料?
TabliSync 可從截圖或 PDF 擷取表格、整理雜亂資料,並自動化與 2026 指南:AI 手寫轉數位資料 相關的重複 Excel 任務。
應從哪裡開始學習 2026 指南:AI 手寫轉數位資料?
先閱讀本頁總覽,再開啟下方相關文章,取得逐步教學與 AI 輔助流程。
所有 手寫識別 文章(19)
How to copy a table from a PDF to Excel: Native Options and AI OCR Workflow
In today's fast-paced business environment, efficiently transferring data from PDFs to Excel is crucial for productivity. Many users face challenges when attempting to copy tables from PDFs due to the cumbersome nature of manual data entry and the limitations of basic OCR tools. This article provides a comprehensive guide on how to effectively copy tables from PDFs into Excel. It covers both native options for those who prefer manual methods, as well as innovative AI OCR solutions like TabliSync that can significantly enhance the efficiency of this process. By following the step-by-step instructions, users will learn how to easily extract data from various types of PDF documents, ensuring a seamless transition to structured Excel formats. Whether you're an accountant, a data entry professional, or someone who frequently deals with financial documents, this guide will equip you with the knowledge to streamline your data extraction tasks.

如何將 PDF 表格複製到 Excel
["將表格資料從 PDF 檔案轉換為可編輯 Excel 電子表格的詳細逐步指南", "檢查和驗證所提取資料內容以確保轉換準確性並避免錯誤的專業技巧", "PDF 表格轉換的實際應用場景,涵蓋發票和財務報告等常見文件", "簡化和優化日常 PDF 資料轉換和排序任務的有效方法和經驗", "關於為日常辦公工作建立高效、省時的 PDF 轉 Excel 資料處理流程的指南"]

如何製作盒狀圖 Excel:將複雜表格轉換為可操作的見解
使用結構化數據準備和動態 Excel 範圍,將手動圖表創建時間縮短 70%。 在生成盒狀圖之前,通過集成 AI OCR 解析,消除來自非結構化數據源的數據輸入錯誤。 通過原始表格和視覺化層之間的實時同步,為統計分析維護單一真相來源。

自動化 Excel 自動調整大型數據集列高
自動調整列高失敗最常見的原因是手動設定的列高或合併儲存格。合併的儲存格直接忽略合併區域的內容,只會查看左上角儲存格的高度。實際的教訓是:避免合併需要動態高度的列,或者接受您必須在文字換行後手動調整合併的列。如果列在自動調整後顯得太高,請檢查隱藏字元或過多的換行符(透過清除格式)。診斷方法很簡單:按兩下列界線沒有反應?懷疑是手動覆寫。列縮小但內容仍被截斷?懷疑是沒有換行文字。

如何移除 Excel 中的空白列:原生 Excel 和 AI 工作流程選項
TabliSync 現在只需點擊一下即可在 Excel 中移除空白列,無需手動清理。 您所在目標地區的所有用戶均可立即使用標準方案,無需額外費用。 支援 Excel 2019 (Windows) 和 Excel 365 (Windows/macOS);無需 VBA 或巨集。 批次處理支援每個工作表最多 10,000 列,並自動偵測完全空白的列。

Excel 方向鍵無法使用:原生修復與 AI 工作流程選項
Excel 中的方向鍵故障很少是硬體問題;它們幾乎總是歸因於 Scroll Lock、凍結窗格或巨集觸發的導覽鎖定。 標準修復(切換 Scroll Lock、Excel 修復)在企業部署中有 30% 的情況會因群組原則限制或舊版增益集衝突而失敗。 TabliSync AI 提供了一個確定性、經過稽核記錄的解決路徑,可繞過 Scroll Lock 狀態並在不禁用安全控制的情況下還原原生方向鍵行為。 [您的目標區域] 的組織必須記錄方向鍵的補救步驟,以符合使用者生產力和資料輸入準確性的[適用合規要求]。

如何在 Excel 中合併兩欄:原生 Excel 和 AI 工作流程方法
請務必將合併後的資料與來源欄位進行驗證,以防止靜默資料損毀。 僅使用提供稽核記錄或基於公式合併的工具,以實現完全歸因。 切勿在未手動驗證邊緣案例的情況下,依賴 AI 生成的合併建議。 請在您的資料治理記錄中記錄合併方法和日期,以準備好合規性。

如何安全地移除 Excel 中的空白列:原生 Excel 與 AI 工作流程指南
Excel 中的空白列通常會因為包含空格或不可見字元等部分內容而被隱藏——刪除前務必取消隱藏並進行掃描。 AI 工具可以生成 VBA 巨集或公式來移除空白列,但每個 AI 輸出的結果都必須先在資料副本上進行測試。 切勿盲目使用「刪除整列」功能;請先篩選或使用「前往特殊」功能,以避免破壞鄰近的資料。 將人工目視檢查與自動化步驟結合——最佳的移除工作流程是人機協作,而非單方面交接。

如何取消隱藏 2026 Excel 中的列:原生 Excel 和 AI 工作流程方法
使用三種主要方法在 2026 Excel 中取消隱藏列:右鍵點選內容功能表、鍵盤快速鍵 (Ctrl+Shift+9) 以及「格式」索引標籤下的「可見度」。 對於由篩選條件導致的隱藏列,請使用「篩選器」下拉式清單清除列欄位上的篩選條件,而不是使用「取消隱藏」指令。 透過選取整個工作表 (Ctrl+A),然後右鍵點選並選擇「取消隱藏」,一次性批次取消隱藏多個列。 在列印或共用之前,透過稽核工作表保護設定並使用「特殊選取」功能來定位隱藏列,以防止意外隱藏。

在 Excel 中插入列的快速鍵:加速資料準備
使用 Ctrl+Shift++ 快捷鍵可將插入列的速度提高 80%,將資料準備時間從數秒縮短至鍵擊。 結合列插入與 Excel 表格結構化參考,可消除手動複製貼上錯誤,確保公式自動擴展。 將快捷鍵與 AI OCR 工作流程配對,可減少資料輸入的摩擦,該工作流程會將 PDF 和圖片解析成即時 Excel 表格,以便插入。 透過對新插入的列使用命名範圍和資料驗證,可維護稽核軌跡和資料治理,防止結構損壞。
_20260527094715A097.png)
使用 TabliSync 精通 Excel 欄位比對
使用 TabliSync 的自動化資料擷取和即時同步功能,將手動欄位比對時間縮短 70%。 透過結構化參照比對,消除因重複、格式不符和遺漏值造成的 VLOOKUP 錯誤。 結合 AI OCR 解析與 Excel 原生驗證工具,確保非結構化來源的資料完整性 100%。

如何在 Excel 中新增項目符號以獲得乾淨的資料表格
本指南涵蓋了在 Excel 中新增和清理項目符號的兩種高效方法,以建立結構化、可分析的資料表格。它解釋了內建的 Excel 工作流程,包括鍵盤快捷鍵、CHAR 函數、Power Query 和 Excel 表格,用於簡單的一次性格式設定任務。它還介紹了由 AI 驅動的 TabliSync 解決方案,可自動從 PDF、螢幕截圖和外部報告中提取、標準化和組織雜亂的項目符號列表,將其轉換為乾淨的 Excel 列,從而解決常見的資料清理問題,並優化經常性的業務資料工作流程,以便進行篩選、分析和儀表板建立。

Excel 插入列快捷鍵:自動化資料輸入
消除 Excel 中重複的手動插入列操作,每筆記錄節省 60-90 秒,適用於數百筆記錄。 結合鍵盤快捷鍵、結構化 Excel 表格和動態命名範圍,將資料輸入錯誤減少 80%。 透過 AI OCR 實現螢幕截圖和 PDF 結構化資料的即時同步,將重新輸入時間降至零。 透過一致的插入模式和持續透過自動化執行的驗證規則,標準化團隊之間的数据治理策略。

AI:如何在 Excel 中分割名字和姓氏
透過使用 AI 驅動的解析,消除手動姓名分割錯誤,將資料清理時間最多減少 85%。 自動化從 PDF 和基於影像的報告中提取名字和姓氏,每位分析師每週可節省 10 小時以上。 透過即時同步在資料集之間維護一致的姓名格式,將下游的協調失敗率降低 90%。

Excel 公式百分比增加:TabliSync
在 Excel 中將數值增加百分比,基本上是將原始值乘以 (1 + 百分比)。實際的重點在於確保百分比的表達方式正確——無論是使用小數還是 Excel 的百分比格式——並且如果百分比是固定值,則要使用絕對參照。此方法適用於正負百分比變動(減少),因此相同的公式可用於加價、折扣或縮減計算。大多數錯誤來自於參照錯誤的儲存格或忘記鎖定固定費率,而不是來自於算術本身。

Excel Online:掌握協同作業並克服關鍵限制 (2026)
• 透過雲端原生資料治理,將即時共同撰寫最佳化,減少 90% 的版本衝突。 • 透過整合 AI 驅動的光學字元辨識 (OCR) 來解析非結構化資料,消除 100% 的手動資料輸入錯誤。 • 運用 2026 Office 365 試算表技巧,繞過舊有檔案大小延遲和瀏覽器式計算節流。

PDF 轉 Excel:2026 年的實證方法對比 AI 自動化
效率提升: 相較於傳統的複製貼上工作流程,導入 AI 原生文件智慧可將手動資料輸入時間縮短高達 95%。 準確度基準: 現代 OCR 資料擷取透過使用基於 LLM 的驗證層而非簡單的模式比對,實現了 0% 的手動輸入錯誤率。 可擴展性: 從 Power Query 轉換為批次 PDF 處理,能夠同時處理數千份非結構化文件,並將其匯入集中式結構。

如何在 Excel 中尋找重複項:專業方法與陷阱規避
精通如何以 99.9% 的準確度在 Excel 中尋找重複項;透過 AI OCR 將資料清理時間減少 90%;從手動輸入轉向自動化資料衛生協議;消除非結構化資料解析中的人為錯誤。

如何移除 Excel 中的重複列:實用指南
將資料清理時間減少 90%;使用 AI OCR 達成 0% 手動輸入錯誤;透過原生和自動化工作流程消除重複的列;優化 B2B 物流和金融的資料品質。
告別手動輸入 – 秒速提取表格數據
將任何圖片或 PDF 表格即時轉換為 Excel,準確率達 99.9%。TabliSync 的 AI OCR 可處理手寫表單、收據和複雜表格,並直接同步到 Google Sheets、Notion 或 Airtable
立即免費試用 TabliSync