Article Summary
2026年におけるバッチOCRからExcelへのマスター 2026年のデータ主導型環境において、請求書、領収書、物流レポートなどの非構造化ドキュメントを手動で入力する従来の方法は、成長の重大なボトルネックとなっています。この記事では、バッチOCRからExcelへのテクノロジーに関する決定版ガイドを提供し、最新のOCRは単純なテキスト転写を超えて、インテリジェントなデータ再構築とコンテキスト認識に焦点を当てていることを強調します。
大規模データセットのマスター:OCRからExcelへのバッチ処理の決定版ガイド
大規模なデータセットを扱うということは、しばしば構造化されていない文書の山に直面することを意味します。金融、物流、ヘルスケアのいずれの分野であっても、請求書、領収書、レポートの膨大な量は圧倒される可能性があります。手作業によるデータ入力という従来の方法は、単に遅いだけでなく、成長を妨げ、コストのかかるエラーを招くボトルネックとなります。現代的な解決策は、OCRからExcelへのバッチ処理技術を通じた自動データ抽出を活用することにあります。しかし、利用可能なツールの状況をどのようにナビゲートし、真にスケーラブルなソリューションを実装できるでしょうか?このガイドは、大量の文書処理をマスターし、重要な財務および運用データに対して高精度OCRを達成するために必要な深い専門知識を提供します。
現在のOCRの状況に関する考察:基本的な文字起こしを超えて
Lidoによる「2024年データ抽出に最適なOCRソフトウェア」と題された最近の洞察に富んだ分析は、適切な光学文字認識ツールの選択における重要なニュアンスを掘り下げています。著者は、現代のOCRは単純なテキスト文字起こしを超えており、現在では洗練されたデータ構造化とコンテキスト認識が求められていると強調しています。具体的には、この記事は次のように強調しています。
「現代のOCRの真の価値は、文字を認識するだけでなく、抽出されたデータの構造を理解することにあります。請求書や財務諸表のような複雑な文書を扱う企業にとって、テーブルを正確に解析し、データ関係を維持する能力は最も重要です。これがなければ、「抽出されたデータ」は単なるテキストの混乱した山であり、再編成して利用可能にするためには依然としてかなりの手作業が必要となります。効果的なデータ抽出プラットフォームは、Excelやリレーショナルデータベースのような形式に直接、真に実行可能な情報を提供する、堅牢なテーブル検出とレイアウト分析機能を提供する必要があります。」(出典: https://www.lido.app/blog/best-ocr-software)SaaSコンテンツマーケティングの専門家として、ドキュメント自動化の分野に深く携わっている私にとって、この視点は非常に共感を呼びます。Lidoの記事は、多くの企業が見落としている中心的な課題を正しく特定しています。OCRの「T」は、単なる「Transcription(文字起こし)」ではなく、「Transformation(変換)」を意味すべきなのです。市場には、1ページのテキストをデジタル化できる一般的なOCRツールが溢れています。しかし、数百、数千ものドキュメントにまたがる財務テーブルの解析に必要な特殊なインテリジェンスを備えたものはごくわずかです。まさにここで、ボトルネックはドキュメントを「読む」ことから、下流の分析やERP統合に不可欠な「データの再構築」へと移行します。 さらに、この記事は統合の重要な役割を強調しています。私の経験では、たとえ非常に精度の高いOCRエンジンであっても、既存のワークフローにシームレスにデータを注入できなければサイロ化してしまいます。堅牢なバッチOCRからExcelへの変換ソリューションは、レイアウト分析に優れているだけでなく、Salesforce、NetSuite、または専門の会計ソフトウェアのようなプラットフォームに接続するための堅牢なAPIやWebhookを提供する必要があります。これは、包括的なデータパイプラインを提供するプラットフォームにLidoの記事が焦点を当てていることと一致します。PDFやJPEGから複雑な複数ページのTIFFまで、多様なドキュメント形式を大量に処理し、高い精度と構造的整合性を維持する能力は、もはや贅沢ではなく、データ駆動型組織にとって競争上の必須条件となっています。

マルチフォーマットのボトルネック:ドキュメントの多様性が効率を低下させる理由
大規模なドキュメント処理における本当のペインポイントについて話しましょう。それは単なる量ではありません。それは、ドキュメントのフォーマットとレイアウトの、純粋で混じりけのない[多様性]です。あなたの財務部門は、単一の標準化されたフォーマットで請求書を受け取るわけではありません。主要ベンダーからはベクターPDFで、小規模サプライヤーからはスキャンが不十分なJPEGで、古いファックスシステムからは複数ページのTIFFで、そしておそらくは混沌としたWord文書でさえ受け取ります。これが多様なフォーマットのバッチ処理の不可能性であり、生産性を低下させる要因です。従来のメソッドや、それほど高度ではないOCRツールでは、フォーマットごとに異なる処理が必要となり、しばしば、すべてのベンダーレイアウトに対して、手間のかかる手動での事前ソートやテンプレート作成が必要になります。
- 新しいベンダーレイアウトごとに、[新しいテンプレート]または設定が必要です。
- スキャンされたドキュメントには、傾き補正などの[手動画像前処理]が必要な場合が多くあります。
- 異なるファイルタイプを単一の処理バッチに結合することは、しばしば[不可能]です。
- クリアなPDFでは機能するデータ抽出ルールが、ザラザラしたスキャンでは[失敗]します。
- その結果、[真に自動化できない]断片化されたワークフローになります。
毎月10,000件の請求書を処理しようとする経理チームを想像してみてください。6,000件は標準的なPDFですが、4,000件はスキャン、画像が埋め込まれたメール、奇妙なファイルタイプの混合です。従来のやり方では、チームはワークフローの約60%を自動化できるかもしれませんが、残りの40%は、非常に手間のかかる遅い手動介入を必要とします。これは単に非効率的なだけでなく、[大規模なスケーラビリティの障壁]です。これらの多様なフォーマットを単一の統合された「バッチ」として扱えないということは、あなたのバルクドキュメント処理が常にスピードバンプにぶつかっていることを意味します。真の自動化を達成しているのではなく、簡単な部分だけを自動化し、困難でコストのかかる部分は人間に任せているのです。これは、そもそもテクノロジーを採用した目的を損なうものです。
この問題は、[契約書]や[臨床試験報告書]のような複雑で複数ページのドキュメントを扱う際に劇的に悪化します。50ページのドキュメントには、12ページ、35ページ、48ページに重要な財務テーブルが含まれている可能性がありますが、それぞれフォーマットがわずかに異なります。基本的なOCRツールはすべてのテキストを抽出できますが、35ページのテーブルが12ページのテーブルの続きであることや、フォーマットが変更されていることを認識することに完全に失敗します。データは一貫性のないテキストのストリームとして出力され、Excelでの手動での切り取り、貼り付け、再構築に数時間かかります。この絶え間ない、摩擦の多いコンテキストスイッチングとデータクリーニングが、大規模なドキュメント処理を非常に苦痛でコストのかかるものにしています。それは単に文字を読むことではなく、レイアウトの混乱を克服することです。
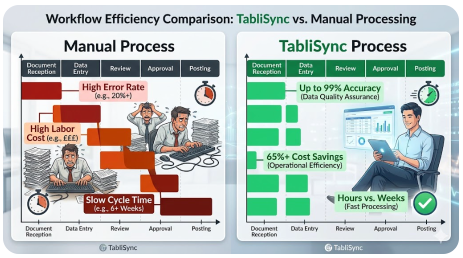
効率とコストのギャップ:手動整理 vs. TabliSync自動変換
高精度OCRと自動データ抽出の価値を真に理解するには、現状(データをExcelファイルに手動で整理すること)とTabliSyncを使用した変換を比較する必要があります。その違いは些細なものではなく、[効率、コスト削減、データ品質]全体で変革的です。実際の業界ベンチマークとシナリオを使用して、両アプローチの経済性と運用上の現実を分析しましょう。
手動による現状の隠れたコスト
毎月10,000件の文書を手作業で処理するのは、大変な作業です。経験豊富なデータ入力担当者は、検証を含めて、複雑な文書(複数行の請求書など)を1時間あたり平均40〜60件処理できます。10,000件の文書を処理するには、約200時間の集中した労働力が必要です。平均的な総人件費(福利厚生や諸経費を含む)を時給30ドルとすると、データ入力のみの月額人件費は6,000ドルになります。
- [高いエラー率]: 人手によるデータ入力は、通常1〜3%のエラー率が発生します。10,000件の文書では、100〜300件のデータが不正確になり、高額な[照合]問題、支払い遅延、またはコンプライアンス問題につながります。
- [スケーラビリティの問題]: 容量を2倍にするには、人員を2倍にする必要があり、それに比例してコストが増加し、管理上の負担が増大します。[スケーリングは線形的で高コストです]。
- [遅いサイクルタイム]: 大量のバッチを処理するには数日から数週間かかる場合があり、財務の可視性や業務上の意思決定が遅れます。[遅いデータは遅いビジネスにつながります]。
- [従業員の士気の低下]: データ入力は反復的で退屈な作業であり、高い[離職率]とそれに伴う採用コストにつながります。
TabliSyncの利点:効率とコスト削減を実現
次に、TabliSyncのバッチOCRからExcelへの変換ソリューションで処理された同じ10,000件の文書を見てみましょう。TabliSyncは、1時間あたり数千ページを処理できます。手作業による労力は、「入力」から「例外処理」と「検証」に移行します。通常、高品質の文書では、自動化率は90〜95%を超えることがあり、人間のレビューを必要とするのは文書の5〜10%のみです。
200時間ではなく、チームは例外の検証に20時間しか費やさないかもしれません。同じ時給30ドルで、人件費は600ドルに下がります。TabliSyncプラットフォームのコスト(このボリュームの典型的なSaaSティアを想定)は月額約1,500ドルになる可能性があります。合計コストは2,100ドルとなり、運用コストは[65%削減]されます。しかし、節約はそれだけではありません。
- [エラー率の大幅な低下]:TabliSyncのAI駆動エンジンは最大99%の精度を提供し、データエラーに関連するコストを大幅に削減します。
- [ほぼ瞬時のスケーラビリティ]:20,000件のドキュメントを処理するには、サブスクリプションを調整するだけです。新しいスタッフを雇用したりトレーニングしたりする必要はありません。[スケーリングは指数関数的かつ費用対効果が高い]です。
- [迅速なサイクルタイム]:数週間かかっていたバッチが数時間で処理されるようになり、[リアルタイムの財務可視性]を提供します。
- [より価値の高い業務]:チームは[分析タスク]、戦略計画、ベンダー関係管理に解放されます。
- [コンプライアンスの向上]:すべての抽出は記録され、監査可能であり、堅牢な[監査証跡]を作成し、規制リスクを低減します。
船荷証券の処理のためにTabliSyncに切り替えた大手物流会社を考えてみましょう。彼らはデータ入力チームを15人から3人に削減しましたが、処理量は40%増加しました。12人のスタッフは再スキル化され、物流計画やカスタマーサポートの価値の高い役割に異動しました。直接的なコスト削減は年間450,000ドルを超え、請求サイクルの迅速化やエラー削減から得られる価値は含まれていません。これは、手作業による混乱から自動化された精度への移行による定量化可能な影響です。
大規模バッチOCRからExcelへのプロジェクト実行ステップバイステップガイド
バッチOCRからExcelへの変換の強力なビジネスケースをご理解いただけたところで、TabliSyncのような強力なプラットフォームを使用した実際の実行方法を見ていきましょう。成功する一括ドキュメント処理は、単にボタンをクリックするだけではありません。正確性、構造、そしてシームレスなデータフローを確保するための体系的なアプローチが必要です。このガイドでは、ドキュメントの山から構造化された、実行可能なExcelデータへと移行するための、設定の詳細と運用上のベストプラクティスを網羅した正確な手順を概説します。
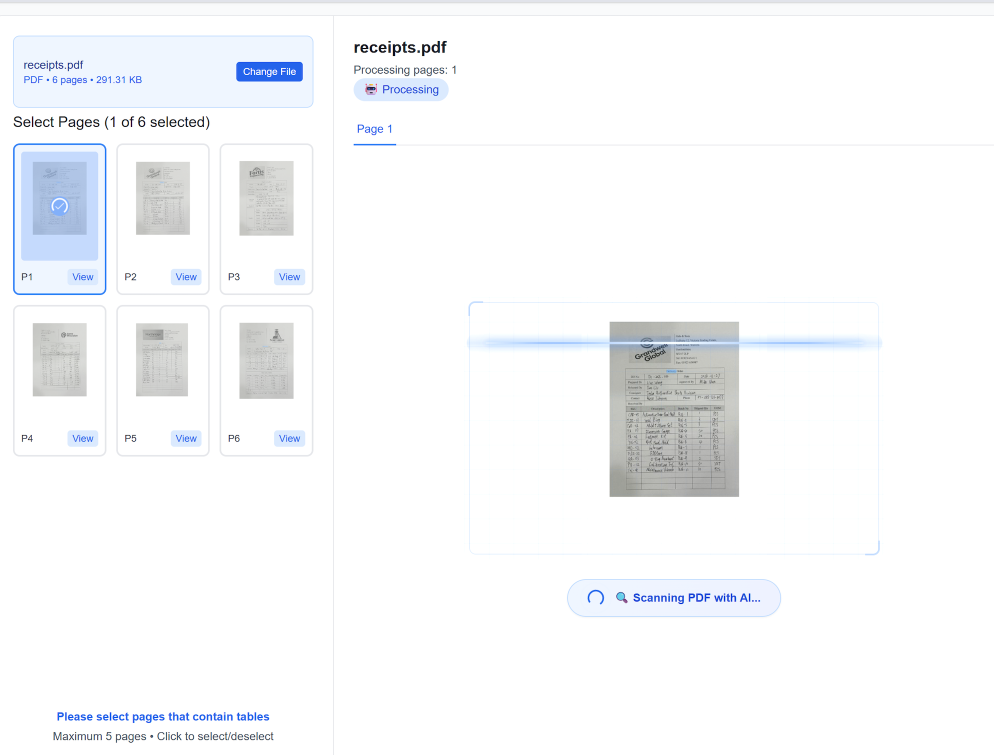
ステップ1:バッチ構成とドキュメントの取り込み
最初で、おそらく最も重要なステップは、バッチを設定し、多様なドキュメントを取り込むことです。ここで、マルチフォーマットのボトルネックを克服します。TabliSyncでは、ファイルを事前に並べ替える必要はありません。安全なダッシュボードにログインし、新しい[処理バッチ]を作成するだけです。構成設定内で、[出力フォーマット](この場合はExcel)、希望する[OCRエンジン設定](例えば、特に粗いスキャンに対して速度と精度のバランスを取る)、および自動回転やノイズリダクションのような[前処理ルール]を指定します。
構成が完了したら、大規模データセットを取り込むための複数のオプションがあります。数百ファイル程度であれば、[直接Webアップロード]インターフェースで十分です。数千のドキュメントの場合は、安全な[SFTPゲートウェイ]または強力な[TabliSync API]を使用するのが理想的です。例えば、グローバルロジスティクス企業はAPIを使用して、添付ファイル付きの受信メールを処理バッチに直接自動ルーティングし、手動処理を完全に排除しています。TabliSyncは、マルチページPDF、複雑なTIFF、JPEG、さらにはさまざまなファイルタイプを含むZIPアーカイブなど、事実上あらゆるフォーマットを受け入れます。システムは、各ドキュメントを自動的に[解凍、標準化、準備]し、次のステージに進め、リアルタイムの取り込みログを提供します。
[注意点]:バッチを設定する際は、[ドキュメント言語設定]に細心の注意を払ってください。TabliSyncは複数の言語をサポートしていますが、ドキュメントの主要言語を選択することで、特に微妙な文字のバリエーションや通貨記号の場合に精度が大幅に向上します。また、スキャンされたドキュメントの場合は、信頼性の高い結果を得るために、少なくとも[300 DPI]の解像度があることを確認してください。解像度が非常に低いスキャンは、OCRエラーの最大の原因です。
ステップ2:インテリジェントレイアウト分析とテーブル解析
ドキュメントが取り込まれると、TabliSync のコア AI エンジンが稼働します。このステップはテキストを読むことではなく、各ページの [視覚的な階層と構造的な関係] を理解することです。ここで **財務テーブルの解析** が重要になります。当社のエンジンはキーワードを探すだけでなく、空白、配置、書式設定の手がかりを分析して、[テーブル、明細項目、ヘッダー、キーと値のペア](「請求書の日付」とその対応する日付など)を特定します。
これはテンプレート不要のプロセスです。TabliSync の AI は数百万もの多様なドキュメントでトレーニングされているため、仕入先の請求書にある明細項目のテーブルが、複数ページにまたがり、明確な罫線がない場合でも、単一のエンティティとして自動的に認識します。**財務テーブルの解析** のために、[数量、単価、説明、および明細合計] を個別の正確な列にインテリジェントに分離します。TabliSync ダッシュボードでこの進捗状況を監視でき、どのドキュメントが分析されているかを正確に表示し、レイアウトが不明瞭な場合は人間によるレビューのためにフラグを立てます。
[総勘定元帳] の照合でプロフェッショナルグレードの結果を保証するために、TabliSync の検証ルールを使用してください。個々の明細項目の合計が請求書の小計に達しているか、または指定されたレートに基づいて税額が正しく計算されているかを確認するルールを設定できます。これは単純な抽出を超え、[ビジネスロジック検証] のレイヤーを追加し、Excel ファイルに到達するデータが正確であるだけでなく、論理的にも一貫していることを保証し、下流の **照合** プロセスを大幅にスピードアップします。
ステップ 3: データ検証、例外処理、および Excel エクスポート
最終ステップは、抽出されたデータを精査し、例外を処理し、最終化された構造化情報を Excel にエクスポートすることです。AI が分析を完了すると、TabliSync は [検証インターフェイス] を表示します。ここでは、キーフィールドに対する AI の信頼スコアが事前に定義されたしきい値を下回った場合にのみ、人間によるレビューのためにドキュメントがフラグ付けされます。たとえば、特に乱雑な手書きのメモが「合計金額」を不明瞭にしている場合、システムはその特定のドキュメントをフラグ付けします。
検証画面では、元のドキュメント画像と抽出されたデータを並べて表示できます。AIが苦戦した部分に人間の知性を加えることで、チームは[エラーを迅速に修正]できます。通常のバッチ処理では、10,000件すべてのドキュメントを見るのではなく、フラグが付けられた例外のみを確認するため、このレビューは信じられないほど高速です。一括ドキュメント処理の場合、この人間参加型のアプローチは、ほぼ100%のデータ整合性を維持するために不可欠です。インターフェースは速度のために最適化されており、検証者はフィールド間をタブで移動し、キーボードショートカットを使用して迅速な修正を行うことができます。すべてのドキュメントが検証されたら、[Excelにエクスポート]をクリックするだけです。
TabliSyncは、生のテキストのダンプを提供するだけでなく、美しく構造化されたマルチシートのExcelワークブックを提供します。1つのシートには[ヘッダーレベルのデータ](請求書番号、日付、ベンダー名)を含めることができ、別のシートにはすべての[詳細な明細項目](製品SKU、説明、数量、価格)を含めることができ、それらをリンクする一意の識別子があります。このリレーショナル構造は、複雑な分析やERP統合に非常に役立ちます。さらに、エクスポートを特定の[Excelデータ型](日付を日付として、通貨を数値としてフォーマットするなど)を使用するように構成できるため、ピボットテーブルや財務モデリングで手動でのクリーンアップを必要とせずに、データをすぐに使用できるようになります。
戦略的影響:なぜバッチOCRからExcelがコアコンピタンスであり、追加機能ではないのか
長すぎる間、企業はドキュメント処理をバックオフィス管理タスク、つまり必要なコストセンターとして扱ってきました。これは深刻な戦略的誤算です。デジタル時代において、ビジネスを支える非構造化ドキュメントから自動データ抽出を行う能力は、運用速度、財務的機敏性、そして最終的には競争優位性の[直接的な決定要因]となります。バッチOCRからExcelを習得することは、単に時間を節約するだけでなく、組織データ内の潜在的な価値を解き放つことです。
[ほぼリアルタイムの財務データ] を持つことの戦略的価値を考えてみてください。週単位ではなく数時間で 10,000 件の請求書を処理できる場合、買掛金チームは過去の出来事に対応するのではなく、[積極的にキャッシュフローを管理] し、運転資本を最適化し、早期支払い割引を活用できるようになります。調達チームは、数千件の購入にわたる品目レベルのデータを分析して、支出パターンを特定し、サプライヤーとのより良い条件を交渉できます。コンプライアンスおよび監査チームは、すべてのトランザクションに対して [即時かつ検証可能な監査証跡] を持つことができ、監査に関連するコストとリスクを大幅に削減できます。このレベルの応答性は、堅牢で高精度な一括処理ソリューションでのみ可能です。
さらに、このデータアジリティは、高度な分析および AI イニシアチブの基盤となります。正確で詳細な品目レベルのデータでリアルタイムに更新される [総勘定元帳] は、予測および戦略計画のための強力なツールになります。この構造化データを機械学習モデルにフィードして、需要を予測したり、在庫レベルを最適化したり、不正なトランザクションを検出したりできます。ドキュメントに隠された非構造化データは、デジタルトランスフォーメーションの燃料であり、Batch OCR to Excel はそれを利用可能にする精製所です。これを無視することは、油田を持っていてもパイプラインの建設を拒否するようなものです。
詳細 FAQ: 大規模 OCR to Excel の複雑性への対応
手動プロセスから、複雑で自動化された Batch OCR to Excel ソリューションへの移行は、必然的に技術的および運用上の疑問を生じさせます。この FAQ セクションでは、数百件の大規模ドキュメント自動化プロジェクトを展開した深い専門知識を活用しています。私たちは、「どのように」だけでなく、「なぜ」と「もしも」にも対応し、プロフェッショナルで成功した展開に必要なニュアンスを理解できるようにします。
テーブル検出とテーブル抽出の違いは何ですか?
これはしばしば見落とされる重要な違いです。テーブルの[検出]は、単にページ上にテーブルが存在することを特定し、その周りにボックスを描画することです。多くの汎用OCRツールはここで止まります。一方、テーブルの[抽出]は、そのテーブルの内部構造を理解するという、はるかに複雑なタスクです。これには、テーブルに境界線がない場合や、複雑なセルが結合されている場合でも、行、列、ヘッダー、および各セル内の正確なデータを正確に特定することが含まれます。財務テーブルの解析においては、信頼性の高い抽出は譲れません。TabliSyncは高度なレイアウト分析を使用して、テーブルを検出するだけでなく、その構造とデータをExcelで忠実に再現します。
TabliSyncはスキャンされた、低品質、または歪んだドキュメントを処理できますか?
はい、ただし注意が必要です。TabliSyncのエンジンは非常に堅牢であり、自動画像[前処理]機能が含まれています。ドキュメントの傾き補正、ノイズ削減、テキストのシャープ化を行い、認識を向上させることができます。当社の高精度OCRは、複雑なレイアウトやさまざまな印刷品質に特に効果的です。しかし、OCRの基本原則である[ゴミを入れればゴミが出てくる]は依然として当てはまります。極端なぼやけ、重要なテキスト上の大幅な手書き、または[300 DPI]未満の解像度のドキュメントでは、抽出精度は常に低くなります。これらのケースでは、TabliSyncはヒューマンレビューのためにドキュメントをフラグ付けし、最終的なExcelレポートに誤ったデータが含まれないようにします。
TabliSyncはGDPRおよびCCPAに準拠していますか?
特に財務または個人情報を含むドキュメントを扱う場合、データプライバシーは最優先事項です。TabliSyncは、エンタープライズグレードのセキュリティとコンプライアンスを中核として構築されています。当社はGDPR、CCPA、およびその他の主要なデータプライバシー規制に完全に準拠しています。すべてのデータは、保存時および転送時ともに[暗号化]されます。さらに、自動PII[匿名化]や設定可能なデータ保持ポリシーなどの機能を提供し、機密情報がどのように処理および保存されるかを完全に制御できるようにします。TabliSyncで一括ドキュメント処理を行う場合、セキュリティと規制コンプライアンスを優先するプラットフォームを利用していることになります。
TabliSyncを既存のERPまたは会計システムに統合するにはどうすればよいですか?
真の自動化にはシームレスな統合が不可欠です。Excelへのエクスポートは強力ですが、直接統合が最終的な目標となることがよくあります。TabliSyncは、パイプライン全体を自動化できる堅牢で[ドキュメント化されたAPI]を提供します。APIを使用して、ドキュメントをTabliSyncにプッシュし、ステータスを監視し、構造化され検証済みのデータをNetSuite、Salesforce、QuickBooksなどのERPまたは会計システムに直接プルできます。また、[Webhooks]もサポートしているため、処理バッチが完了したときに他のシステムに即座に通知され、ワークフローでさらなる自動化アクションがトリガーされます。
AIが重要なデータポイントを正しく抽出できなかった場合はどうなりますか?
ここで「ヒューマン・イン・ザ・ループ」検証ステップが重要になります。TabliSyncは推測するだけでなく、抽出されたすべてのデータポイントに信頼度スコアを提供します。定義したしきい値を下回る重要なフィールド(例:「合計金額」)の信頼度スコアの場合、ドキュメントは自動的にフラグが付けられ、[検証インターフェース]に表示されます。その後、チームはその特定のポイントを迅速にレビューして修正できます。これにより、最終的なExcelファイルにエクスポートされるのは100%検証済みで正確なデータのみとなり、プロフェッショナルな照合および財務報告に必要な高いデータ整合性が維持されます。
TabliSyncは、テーブルがページをまたいでいる複数ページのドキュメントを処理できますか?
はい、これは当社の財務テーブル解析エンジンのコアな強みです。TabliSyncは、複数のページにわたるテーブルをインテリジェントに追跡できます。最初のページでテーブルヘッダーを認識し、ヘッダーが繰り返されていなくても、後続のページが同じテーブルの続きであることを理解します。すべてのデータをExcel出力の[単一の連続したテーブル]に統合し、データの構造的関係を維持し、そうでなければ必要となる手動での統合作業の時間を節約します。
人間が処理する必要がある「例外」の種類は何ですか?
例外は、OCRの信頼度が低いというだけではありません。[ビジネスロジック検証]も含まれる場合があります。たとえば、TabliSyncは、抽出された明細項目の合計が抽出された請求書合計と一致するかどうかを確認できます。一致しない場合、そのドキュメントは例外となります。これは、実際の抽出エラーによるものである可能性も、ベンダーの請求書自体の計算エラーである可能性もあります。その後、人間によるレビュー担当者にコンテキストが提示され、抽出を修正するか、経理チームがベンダーに対処するためにドキュメントをフラグ付けすることで、問題を迅速に解決できます。
バッチで処理できるドキュメント数に制限はありますか?
管理しやすいパフォーマンスを維持するために単一バッチには実用的な制限がありますが、TabliSyncは大規模なスケーリングのために設計されています。非常に大規模なデータセットの場合、論理的なバッチ(例:ベンダー別または月別)に処理を分割することをお勧めします。当社のエンタープライズティアは、年間[数十万、あるいは数百万]ドキュメントにスケーリングできるように設計されています。特に大規模で高ボリュームの要件については、[自動データ抽出]ワークフローが正確な速度とボリュームのSLAを満たすことを保証するために、専用の処理リソースを構成できます。
今日、前例のないデータアジリティと効率性を解き放ちましょう
これで、手作業による処理の根本的なペインポイントから、TabliSyncのようなプラットフォームでの正確なステップバイステップ実行まで、バッチOCRからExcelへの変換の包括的な状況を検討しました。大量の非構造化、マルチフォーマットドキュメントを構造化された、実行可能なデータに自動的かつ正確に変換する機能は、もはや周辺的な効率向上ではありません。これは、データ駆動型の世界で運用上の卓越性と戦略的なアジリティを目指すあらゆる組織にとって、中核的なビジネス要件です。行動を起こさないことによるコスト—高い人件費、蔓延するデータエラー、遅いサイクルタイム、そしてスケーラビリティの完全な欠如—は、無視するにはあまりにも高すぎます。
チームが手作業でのデータ入力に費やす毎分は、価値の高い分析、ベンダーとの照合、戦略的な財務計画に費やせるはずの時間を奪うものです。競争環境は、文書処理の近代化を待ってくれません。今、自動データ抽出を採用する組織は、将来にわたって利益をもたらす運用上の俊敏性の基盤を築いています。重要なビジネスデータが紙や断片化されたデジタルファイルに閉じ込められたままにしないでください。データパイプラインを管理し、組織を前進させましょう。TabliSyncがワークフローを変革する能力に自信があるため、ぜひ直接体験してください。手作業によるボトルネックに足を引っ張られるのはもうやめましょう。今すぐTabliSyncの無料トライアルにサインアップして、高精度OCRの即時的かつ変革的な力を目の当たりにしてください。データアジリティの未来は今始まります。遅れることはありません。
大量データセットのためのバッチOCRからExcelへの使用方法とは?
大量データセットのためのバッチOCRからExcelへの使用方法についての要点と、TabliSyncがExcel作業をどう速くするか。
大量データセットのためのバッチOCRからExcelへの使用方法とは?
大量データセットのためのバッチOCRからExcelへの使用方法は実務的なExcelワークフロー、よくある落とし穴、自動化パターンを扱います。このTabliSyncガイドが概念、例、関連チュートリアルを示します。
TabliSyncは大量データセットのためのバッチOCRからExcelへの使用方法にどう役立ちますか?
スクリーンショットやPDFから表を抽出し、乱れたデータを整え、大量データセットのためのバッチOCRからExcelへの使用方法関連の反復タスクを自動化します。
大量データセットのためのバッチOCRからExcelへの使用方法はどこから始めればよいですか?
このページの概要から始め、下の関連記事でステップごとの手順とAIワークフローを確認してください。
すべての バッチOCRからExcelへ 記事(11)

Excel でシートを複製する方法: ステップバイステップ ガイド
このガイドでは、Excel でシートを複製する方法を段階的に説明し、ユーザーがスプレッドシートを効率的かつ正確に管理できるようにします。財務レポート、在庫シート、その他のデータを使用している場合でも、シートを複製することで時間を節約し、一貫性を確保できます。明確な指示に従って、この不可欠な Excel スキルを習得してください。このガイドの終わりまでに、自信を持ってシートを複製し、作業を整理できるようになります。このスキルを習得したら、TabliSync がスプレッドシート管理タスクをさらに強化する方法もぜひ探索してください。

Excelの数式ロック解除トラブルシューティング
このトラブルシューティングガイドは、Excelの数式ロック解除に関する実践的なソリューションをユーザーに提供し、一般的な問題に対処し、将来の問題を防ぐためのヒントを提供します。数式がロックされることは、特に正確なデータ操作に依存する財務および管理部門のビジネスユーザーにとって、大きな障害となる可能性があります。ステップバイステップのアプローチを通じて、この記事は読者が数式ロックの原因を理解し、これらの問題を解決するための効果的な戦略を提供するのに役立ちます。ここに概説されているソリューションを実装することにより、ユーザーはスプレッドシートの制御を回復し、不必要なフラストレーションなしにデータを効果的に編集および管理できるようになります。この記事はまた、将来そのような問題を防ぐためのベストプラクティスを強調しており、よりスムーズで効率的なスプレッドシートワークフローに貢献し、ユーザーが正確なデータ処理に完全に集中できるようになります。

Excel にドロップダウン メニューを追加する方法
Excel を使用するビジネス スタッフにとって、反復的な手作業によるデータ入力は、データの一貫性の低下や作業効率の低下を招くことがよくあります。この記事では、Excel のドロップダウン メニューの作成における難しさと、手動設定と自動データ抽出方法を含む 2 つのソリューションを紹介します。また、詳細な操作手順、主要なエクスポート前チェック、一般的な設定エラー、FAQ についても説明します。標準化されたドロップダウン メニューを構築することは、データ入力標準を効果的に統一し、手作業によるエラーを削減し、日々のオフィス データ処理および財務報告ワークフローを最適化します。

Excelで箇条書きを追加する方法
このガイドでは、キーボードショートカットとリボンメニューを使用してExcelで箇条書きを追加する手順、専門文書での実用的な使用例、および全体的な可読性を高めるための効果的な書式設定のヒントを提供します。

キーボードショートカット「値の貼り付け」を使用して複雑なスプレッドシートデータをクリーニングする方法
手動での書式削除ではなく、直接ショートカットキーで値の貼り付けを使用することで、データクリーニング時間を最大80%削減します。 インポートされたデータセットまたはレガシーデータセットから、隠れた書式エラー、壊れた数式、一貫性のないデータ型を排除します。 マクロやVBAなしで、クリーンで再現可能なデータパイプラインを維持します — ネイティブExcelのキーストロークのみを使用します。 値の貼り付けとTabliSyncのような抽出ツールを組み合わせることで、構造化データと非構造化データのワークフローを橋渡しします。

クリーンなデータテーブルのためにExcelで箇条書きを行う方法
このガイドでは、構造化され分析可能なデータテーブルのために、Excelで箇条書きを追加してクリーニングする2つの効率的な方法について説明します。組み込みのExcelワークフロー(ショートカットキー、CHAR関数、Power Query、Excelテーブルなど)を使用して、簡単な1回限りの書式設定タスクを説明します。また、AI搭載のTabliSyncソリューションを紹介し、PDF、スクリーンショット、外部レポートから散らかった箇条書きリストを自動的に抽出し、標準化し、クリーンなExcel行に整理することで、一般的なデータクリーニングの問題を解決し、フィルタリング、分析、ダッシュボード作成のための繰り返し発生するビジネスデータワークフローを最適化します。

AI: Excelで姓と名を分離する方法
AI駆動の解析を使用することで、手動での氏名分割エラーを排除し、データクリーニング時間を最大85%削減します。 PDFおよび画像ベースのレポートから姓と名の自動抽出を行い、アナリスト1人あたり週10時間以上を節約します。 リアルタイム同期により、データセット全体で氏名のフォーマットの一貫性を維持し、下流の照合失敗を90%削減します。

Excelでセルをロックする方法:特定のデータ変更から保護する
手動による数式の上書きエラーを0%に抑えるための詳細なセル保護を実装します。スプレッドシート監査に費やす時間を90%削減するための、二段階ロックと保護ワークフローを習得します。AI駆動のOCR同期を活用して、構造化されていないデータをロックされた不変のビジネス資産に変革します。

Excelで重複と元のエントリを削除する方法:ステップバイステップガイド
ノイズを100%排除:重複だけでなく、元のエントリも削除し、真にユニークなデータのみを残すテクニックを習得します。 90%の時間節約:手作業による行ごとの監査から、自動化されたデータクリーニング自動化ワークフローへ移行します。 手作業による入力エラー0%:AI OCRを活用して、非構造化データを人間による介入なしにクリーンなスキーマに解析します。 スケーラブルなデータハイジーン:10万行を超えるデータセットも楽に処理できる、高度なExcelユニーク値戦略を実装します。

Excelブックエラー:解決策が見つかりませんでした
* Excelの起動エラーを、隠されたローカル一時パスを特定して即座に修正します。 * 自動化されたパス検証を使用して、手動トラブルシューティング時間を90%削減します。 * AI OCRを介して非構造化データを移行することで、手動入力エラーを0%達成します。 * 破損したファイルリンクを、回復力のあるクラウド同期データ資産に変換します。

パスワードなしでExcelシートのロックを解除/保護解除する方法
99.9%のデータ整合性でExcelシートのロックを解除。手動回復時間を90%削減。XMLおよびVBAマクロのシームレスな実行。構造化データ抽出のためのAI駆動OCR。
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す