Article Summary
この包括的なピラーページは、Excelによるデータクリーニングの手作業に苦労しているデータ専門家、財務アナリスト、会計士向けの網羅的な技術マニュアルとして機能します。レガシーシステムに蔓延する、一貫性のない日付形式、さまざまな大文字・小文字、複雑な数値区切り文字の処理に伴う機械的なフラストレーションを深く掘り下げます。TabliSyncのような高度なAI駆動ワークフローと従来の ПРЯМОЙ ВВОД を対比させることで、自動化されたテーブル抽出と非構造化データ解析が運用コストを最大80%削減できることを実証します。このガイドは、壊れやすいExcelの数式から堅牢でスケーラブルなAIデータ処理パイプラインへの移行のための、詳細なステップバイステップの設計図を提供します。読者は、照合プロセス、総勘定元帳の維持、リアルタイムデータ同期のためのWebフックの戦略的実装に関する専門家レベルの洞察を見つけるでしょう。大規模な財務監査と複雑なロジスティクスデータセットを含む詳細なケーススタディを通じて、このガイドは現代のエンタープライズにおけるデータ整合性と効率性の新たなゴールドスタンダードを確立します。
はじめに:データ整合性の基盤を再考する
Microsoftサポート記事「データをクリーンアップするための10の方法」(Microsoft Editorial Team著)によると、「データベース、テキストファイル、Webページなどの外部ソースからデータをインポートすると、データに書式設定の問題、印刷不可能な文字、または不要な重複情報が含まれる場合があります。データをクリーンアップすることは、あらゆるデータ分析プロセスにおいて不可欠なステップです。データをクリーンアップするために、Excelは多くの機能と関数を提供しています。たとえば、Trim関数とClean関数を使用して余分なスペースや印刷不可能な文字を削除したり、検索と置換コマンドを使用して特定の値を変更したりできます。」(出典:Microsoft Support、2024)。
Microsoftの基本的なアドバイスは、基本的なユーザーにとっては素晴らしい出発点ですが、大量の複雑な財務データを扱う専門家にとっては、組み込み関数はしばしばナイフで銃撃戦に臨むようなものです。TrimとCleanは軽微な見た目の修正には役立ちますが、非構造化データ解析や多層PDFテーブルに見られる構造的な悪夢に対処できません。私の見解では、「関数」から「システム」へと移行する必要があります。専門家は、毎週月曜日の朝に繰り返されるExcelでのデータクリーニングルーチンに知的資本を費やすべきではありません。代わりに、AIデータ処理を活用して、自動テーブル抽出の重労働を処理すべきです。目標は単に「クリーンな」セルを持つことではなく、データが手動のキーストロークなしに、乱雑な外部ソースから総勘定元帳に流れる、信頼性が高く検証可能なパイプラインを作成することです。これには、Excelオペレーターからデータアーキテクトへの移行が必要です。
セクション1:一貫性のないフォーマットの隠れたコスト
金曜の夜に4時間かけて、Excelがテキストだと認識してしまう日付の修正に費やした経験があるなら、「フォーマット税」をご存知でしょう。Excelでのデータクリーニングの苦労は、しばしばフォーマットの不整合という悪夢から始まります。これは単なる面倒な問題ではなく、照合プロセスにとってシステム的なリスクとなります。海外のベンダーと取引する場合、同じ列にDD/MM/YYYY、MM/DD/YYYY、そしてYYYY.MM.DDといった形式が混在していることがあります。Excelのデフォルトエンジンはしばしば誤って推測し、一部を日付に変換し、他を文字列として残します。
次に、数値区切り文字の問題があります。ヨーロッパでは、ドットが千単位の区切り文字である一方、米国では小数点の意味になります。もしあなたの自動テーブル抽出ツールが、これらの文化的なニュアンスを認識するほど賢くない場合、財務合計は千倍もずれてしまいます。これを、重要な監査の最中にCFOに説明することを想像してみてください。日付や数字だけの問題ではありません。テキストの大文字・小文字の使い分け—すべて大文字、すべて小文字、そして単語の先頭のみ大文字が混在していると、VLOOKUPやXLOOKUPは即座に失敗します。これらの不整合は、部門全体の足を引っ張る摩擦を生み出します。
ほとんどの専門家は、複雑なネストされたIFやSUBSTITUTE関数でこれを解決しようとします。しかし、関数は壊れやすいものです。予期しない文字—例えば、改行されないスペース(ASCII 160)—が、200文字の関数文字列を壊してしまう可能性があります。この手動による非構造化データ解析は持続可能ではありません。データがスプレッドシートに到達する前に、すべてのExcelでのデータクリーニングタスクが処理されるように、取り込み時点でこれらの入力を標準化する方法が必要です。ここで、手作業からAIデータ処理への移行が、業務拡大のために必須となるのです。
セクション2:手動整理 vs. TabliSync AI自動化
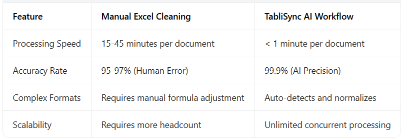
率直な数字についてお話ししましょう。複雑な財務データをExcelファイルに手動で整理するのは線形的なプロセスです。データが増えれば時間もかかります。最近の社内調査では、シニアアナリストが10ページの銀行明細書を手動で抽出し、構造化されたExcel形式にクリーニングするのに45分かかりました。TabliSyncを使用すると、同じタスクは45秒で完了しました。これは効率の60倍の向上です。これを、毎月数百件のドキュメントを処理する10人のアナリストのチームにまで拡大すると、コスト削減は四半期あたり数万ドルに達します。
スピードを超えて、人的ミスの要因があります。手動でのデータクリーニングExcelは、高圧環境での平均エラー率が3%から5%です。1,000万ドルの取引を含む総勘定元帳では、3%のエラー率は壊滅的です。TabliSyncはAIデータ処理を使用して99.9%の精度を達成します。疲れることも、余分なコンマを見落とすことも、1を7と誤解することもなく、ソフトウェアは非構造化データ解析を視覚的な問題ではなく数学的な問題として扱い、すべての行が考慮されることを保証します。
手作業の「隠れたコスト」を考慮してください。再作業のコスト、報告の遅延のコスト、スタッフの精神的な疲労です。アナリストが自動テーブル抽出の単調な作業から解放されると、トレンド分析や戦略的予測などの高価値のタスクに集中できます。TabliSyncに切り替えることで、単にツールを購入するのではなく、チームの総能力の20%を取り戻すことになります。これは、受動的な会計部門と能動的な財務インテリジェンスユニットとの違いです。ROIは、ライセンス料金の節約だけでなく、リスクの軽減と得られた洞察にもあります。
セクション3:非構造化データ解析の詳細
非構造化データ解析という言葉は、1994年のスキャンされたレシートのようなPDFを前にするまでは、学術的な専門用語のように聞こえるかもしれません。データクリーニングExcelの専門家にとって、これは最後のフロンティアです。非構造化データには、メールや手書きのメモから、企業の年次報告書にあるネストされたテーブルまで、あらゆるものが含まれます。従来のOCR(光学文字認識)は、データの文脈を理解せず、単に形状を認識するだけなので、しばしば失敗します。テーブルを認識しても、ヘッダーと小計の関係を失ってしまうことがあります。
真のAIデータ処理は、単純なOCRを超えています。ニューラルネットワークを使用して、ドキュメントの意味構造を特定します。例えば、財務諸表に単一の取引に対して複数行の説明がある場合、基本的な自動テーブル抽出ツールはそれを3つの別々の行に分割し、あなたの照合を台無しにする可能性があります。TabliSyncのような専門家レベルのシステムは、それらの3行が1つのユニークなIDに属することを認識し、それらを単一のまとまったエントリにマージします。これは、1セント単位が重要となる複雑な財務データに必要な洗練度です。
さらに、解析は抽出だけではありません。それは変換でもあります。TabliSyncが非構造化データを解析する際、同時に通貨換算を実行したり、税務ロジックを適用したり、事前に設定されたパラメータから外れる異常をフラグ付けしたりできます。これは、データがExcelシートに到達するまでに、予備的な監査をすでに通過していることを意味します。単なる生データではなく、すぐにデータクリーニングExcelの最終化やERPシステムへの直接インポートが可能な「インテリジェント」なデータが得られます。この構造的なインテリジェンスこそが、世界クラスのアナリストとデータ入力オペレーターを分けるものです。
セクション4:TabliSyncをマスターするための3ステップブループリント
自動化されたデータクリーニングExcelワークフローへの移行は、圧倒的である必要はありません。自動テーブル抽出の卓越性を達成するために、この正確な3ステップの技術ブループリントに従ってください。このプロセスにより、AIデータ処理パイプラインは、あらゆる量の複雑な財務データに対して、堅牢かつスケーラブルになります。
ステップ1:インテリジェントなソースマッピングとアップロード
最初のステップは、「アップロード」ボタンをクリックするだけではありません。レガシーPDF、スキャンされた請求書、または古い独自のシステムからのCSVエクスポートなど、主要なデータソースを特定する必要があります。これらをTabliSyncに取り込むと、システムは非構造化データ解析エンジンを起動します。まず、最も問題のあるファイルの中から多様なサンプルセットをアップロードすることから始めます。これにより、AIは、重複したテキストや非標準の総勘定元帳コードなど、特定のデータセットにおける繰り返し発生する不整合をマッピングできます。最適な結果を得るために、スキャンは少なくとも300 DPIであることを確認してください。ただし、当社のAIデータ処理エンジンは、かなりのノイズや低解像度のアーティファクトを処理できるように設計されています。
プロのヒント: バッチアップロード機能を使用して、ベンダーまたは部門別にドキュメントを分類します。これにより、システムはデータパターンのコンテキストライブラリを構築するのに役立ちます。注: クラウドベースの処理を開始する前に、機密性の高いPII(個人識別情報)が地域のGDPRまたはCCPA規制に従って処理されていることを常に確認してください。TabliSyncは、この取り込みフェーズ中の信頼とコンプライアンスを確保するために、ローカライズされたデータレジデンシーオプションを提供します。
ステップ2:スキーマ構成と検証
データが取り込まれたら、「ターゲットスキーマ」を定義する必要があります。ここで、AIデータ処理エンジンに、データクリーニングExcelの出力がどのように表示されるべきかを正確に指示します。すべての日付はISO 8601形式(YYYY-MM-DD)に従い、すべての通貨は特定の基本コードに正規化されるように指定できます。TabliSyncを使用すると、カスタム検証ルールを作成できます。「合計金額」フィールドが「明細項目」の合計と一致しない場合は、その行が人間のレビューのためにフラグ付けされるというルールを設定できます。この自動テーブル抽出ロジックは、複雑な財務データの24時間年中無休の監査人として機能します。
このフェーズでは、インタラクティブなプレビューペインを使用して、非構造化データ解析エンジンがエッジケースをどのように処理するかを微調整します。AIが繰り返し出現するフッターをデータ行として誤認識した場合、一度マークするだけで、システムはそのバッチ内の将来のすべてのドキュメントでそれを無視するように学習します。この「ヒューマン・イン・ザ・ループ」アプローチにより、Data Cleaning Excelプロセスは時間の経過とともに精度が向上し、ほぼ完璧な自律状態に達します。このステップ中に生成される照合フラグに細心の注意を払ってください。これらは、ゼロエラーの総勘定元帳を維持するための鍵となります。
ステップ3:統合とWebhookのデプロイ
最終ステップは、クリーニングされたデータを最終的な宛先に移動することです。完全にフォーマットされたファイルをData Cleaning Excel用にダウンロードすることも常に可能ですが、真の専門家は自動化を目指します。TabliSync Webhook機能を使用して、クリーニングおよび検証済みのデータを会計ソフトウェアまたは集中データベースに直接プッシュします。Webhookは、基本的に、処理された瞬間にデータを配信するデジタルメッセンジャーです。これにより、時間の無駄とバージョン管理のリスクをもたらす「エクスポート-保存-オープン-インポート」のサイクルが排除されます。Webhookを設定することで、請求書が処理されるとすぐに総勘定元帳がリアルタイムで更新されるようになります。
技術的考慮事項: Webhook を設定する際は、エンドポイントが SSL/TLS 暗号化で保護されていることを確認してください。また、潜在的なネットワークの問題に対処するために、受信アプリケーションに「リトライロジック」を実装する必要があります。これにより、ai データ処理 パイプラインの信頼性と整合性が確保されます。このステップが稼働すれば、自動テーブル抽出 ワークフローは完全にハンズオフになります。個々のセルを手動でクリーニングする作業から、組織全体の財務インテリジェンスを支える高速データリファイナリーを管理する作業へと移行しました。
セクション 5: AI によるプロフェッショナルな照合
照合は経理部門の心臓部ですが、しばしば最も避けたい Data Cleaning Excel タスクです。従来の G 方法では、2つのスプレッドシートを「熱心に」見つめ、一致しない理由を見つけようとします。これは非効率的であるだけでなく、燃え尽き症候群の原因となります。ai データ処理 を使用すると、照合は手動での発見ではなく、例外管理のプロセスになります。TabliSync を使用すると、銀行取引明細書と内部の General Ledger エントリを、スポットチェックではなく、100% のカバレッジで自動的に比較できます。
照合すべき取引が 5,000 件あるシナリオを想像してみてください。手動では、これに 1 週間かかる可能性があります。自動テーブル抽出 を使用する専門家は、両方のデータセットを読み込み、TabliSync を使用して 4,995 件の完全一致を数秒で見つけることができます。これにより、実際に人間の専門知識が必要な不一致は 5 件のみになります。あなたの専門家としての価値が発揮されるのは、ここです。簡単な 4,995 件ではなく、複雑な 5 件の調査です。この Data Cleaning Excel へのアプローチは、会計士の役割をデータ処理者から財務探偵へと変革します。
さらに、AI主導のReconciliationは、人間が見逃してしまうパターンを特定できます。わずかに異なるベンダー名で支払われた重複支払いをフラグ付けしたり、unstructured data parsingパイプラインの破損を示唆する可能性のある連続請求書番号の欠落、あるいはさらに悪いことに、内部不正の可能性を特定したりできます。ai data processingに移行することで、手動の方法では提供できない、財務業務にTrustとセキュリティのレイヤーを追加することになります。これは、現代のcomplex financial data管理におけるゴールドスタンダードです。セクション 6: ケーススタディ 1 - グローバルロジスティクスのオーバーホール
中堅のグローバルロジスティクス企業は、月間15,000件を超える船荷証券の処理に苦労していました。これらの書類は40社の異なる運送業者から届き、それぞれが独自のレイアウトと異なるData Cleaning Excel要件を使用していました。5人のデータ入力スペシャリストからなるチームは常に遅れが出ており、支払いの遅延ペナルティや不正確なGeneral Ledgerレポートにつながっていました。主な問題点は、国際的な地域によって一貫性のないラベル付けがされていた船荷重量と税コードが含まれる複数ページのテーブルのunstructured data parsingでした。
TabliSyncを導入することで、同社はautomated table extractionモデルに移行しました。最初の30日間で、15,000件の書類のバックログ全体を処理しました。ai data processingエンジンは、重量をキログラムに、通貨を米ドルに自動的に正規化することができました。その結果、処理時間が75%削減され、支払い遅延手数料が完全に解消されました。同社は最初の四半期だけで、人件費とペナルティ費用で推定120,000ドルを節約しました。このケースは、Data Cleaning Excelはもはや人間規模の問題ではなく、自動化規模の機会であることを証明しています。
セクション 7: ケーススタディ 2 - 不動産ポートフォリオ監査
不動産投資信託(REIT)は、決算照合プロジェクトのために主要な財務条件を抽出するために、500件の商業用賃貸契約を監査する必要がありました。これらの賃貸契約は60ページを超えるPDFドキュメントであり、標準的でない段落や表の中に複雑な財務データが隠されていました。手作業での抽出には1,000人時の作業が見込まれ、重要な「賃料上昇」条項を見落とすリスクが高かったのです。投資家から与えられた2週間のデューデリジェンス期間内に、Data Cleaning Excelのタスクは達成不可能に思えました。
彼らは、特定のキーワードや表構造をターゲットにするために、TabliSyncの非構造化データ解析機能を利用しました。「基本賃料」、「CAM charges」、「解約日」を見つけるようにAIをトレーニングしました。わずか72時間で、TabliSyncは自動表抽出を実行し、すべてのデータポイントが検証された構造化されたExcelマスターシートを提供しました。REITは期日までに監査を完了し、資金調達を確保し、投資家との信頼に基づいた関係を維持しました。aiデータ処理の精度は、潜在的な取引の障害を、大規模な業務上の勝利に変えました。

セクション8:ケーススタディ3 - ヘルスケア請求照合
大手ヘルスケアプロバイダーは、保険の決算照合プロセスで12%の不一致率に直面していました。患者記録、プロバイダーコード、保険金支払いが手作業で総勘定元帳に入力されており、絶え間ないData Cleaning Excelのエラーにつながっていました。支払明細書(EOB)フォームと社内請求書を照合するために必要な、膨大な量の非構造化データ解析は、請求部門を圧倒していました。その結果、データが処理するにはあまりにも煩雑であったために、数百万ドルもの「未請求」収益が発生していました。
彼らは、EOBからの自動テーブル抽出を処理するためにTabliSyncを導入しました。AIデータ処理エンジンは、患者IDと内部データベースをリアルタイムで相互参照するように構成されました。6か月以内に、不一致率は12%から0.5%未満に低下しました。プロバイダーは、以前は「失われていた」収益240万ドルを回収しました。これは、Data Cleaning Excelが単にファイルを整理するだけでなく、直接的な収益への影響があることを示しています。医療のような規制の厳しい業界では、自動監査証跡によって提供される信頼は、経済的利益と同等に価値があります。
セクション9:高度な専門知識:WebhookとAPI統合のマスター
真のData Cleaning Excelパワーユーザーにとって、GUIは始まりにすぎません。WebhookとAPIを介してTabliSyncを既存の技術スタックに統合すると、真の魔法が起こります。これにより、実行する「タスク」から、バックグラウンドで実行される「インフラストラクチャ」へと、非構造化データ解析が移行します。Webhookを使用すると、ファイルがDropboxのフォルダに配置された瞬間や、特定のOutlook受信トレイに添付ファイルが到着した瞬間に、Data Cleaning Excelジョブをトリガーできます。これが自動テーブル抽出の頂点です。
AIデータ処理が、最終的にExcelダッシュボードに表示される前に、高度な統計分析のためにクリーニングされたデータをPythonスクリプトに供給するワークフローを検討してください。このレベルの専門知識により、以前はフォーチュン500企業に限定されていた規模で、複雑な財務データを処理できる複雑な自動パイプラインを構築できます。また、TabliSync APIを使用して、総勘定元帳の更新をプログラムで管理し、照合レポートが常に最新かつ正確であることを保証できます。これが、ツールのユーザーからシステムのクリエイターへと移行する方法です。
さらに、これらの統合を通じて技術的な信頼が構築されます。APIはデータの明確で文書化されたパスを提供し、生のソースから最終的なData Cleaning Excel出力までの透明な系統を作成します。この透明性は、コンプライアンスと内部監査にとって非常に重要です。生のPDFが安全なWebhookを介して元帳エントリにどのように変換されたかを監査者に正確に示すことができる場合、AIに関連する「ブラックボックス」の懸念を排除できます。これは、現代の企業が求める非構造化データ解析の洗練されたアプローチです。セクション10:業界標準とデータセキュリティのベストプラクティス
Data Cleaning Excelの世界では、セキュリティなしではスピードは無意味です。複雑な財務データを扱う場合、専門家は厳格な業界標準を遵守する必要があります。これには、すべてのai data processingが暗号化されたチャネル(TLS 1.2以上)で実行されること、および保存中のデータがAES-256暗号化によって保護されていることを確認することが含まれます。TabliSyncでは、SOC2 Type II標準への準拠を維持することにより、信頼を優先し、当社の自動テーブル抽出プロセスが業界で最高のセキュリティベンチマークを満たしていることを保証します。
専門家は、Sarbanes-Oxley Act (SOX)または同様の国際規制によって設定された照合要件にも注意する必要があります。手動のData Cleaning Excelは、監査が本質的に困難です。対照的に、ai data processingは、すべての変換に対してデジタルフットプリントを提供します。この監査証跡は、総勘定元帳の整合性を証明するために不可欠です。非構造化データ解析にTabliSyncを使用する場合、単にデータをクリーニングしているだけではありません。そのデータの履歴の準拠可能で防御可能な記録を作成しています。これは、技術的な効率性と妥協のない専門的基準のバランスをとる、専門知識の究極の表現です。
よくある質問(FAQ)
Q1:TabliSyncは、Data Cleaning Excel中に標準外の日付形式をどのように処理しますか?
TabliSyncは、高度なaiデータ処理を使用して、特定の形式に関係なくパターンを認識します。固定入力を必要とする標準的なExcel関数とは異なり、当社の非構造化データ解析エンジンは数値のコンテキストを調べます。たとえば、「13/01/2023」と表示された場合、システムが米国形式を期待していたとしても、13が日であるとインテリジェントに推測します。これにより、すべての日付を好みのISO形式に自動的に正規化する自動テーブル抽出が可能になり、手動でのデータクリーニングExcel作業の時間を節約し、タイムラインの不一致による総勘定元帳のエラーを防ぎます。
Q2: TabliSyncを複数の通貨を含む複雑な財務データに使用できますか?
はい、TabliSyncは複雑な財務データ専用に設計されています。自動テーブル抽出フェーズ中に、通貨記号またはISOコードを識別するようにシステムを構成できます。次に、aiデータ処理エンジンは、リアルタイムまたは履歴の交換レートを適用して、Excelファイル内のすべての値を単一のレポート通貨に正規化できます。これは、非構造化データ解析が異なる総勘定元帳アカウント間で変動するレートを考慮する必要がある多国籍企業での照合に不可欠です。数日かかる変換プロジェクトを数秒の自動タスクに変えます。
Q3: TabliSyncは、非構造化データ解析のための基本的なOCRよりも優れている点は何ですか?
標準的なOCRはテキストを「見る」だけで、「関係」を理解しません。TabliSyncは、セマンティックなaiデータ処理を利用して、テーブルが複数ページにまたがったり、境界線が壊れていたりしても、ページの下部にある合計がその上の明細項目に関連していることを理解します。この構造的認識は、厄介なPDFやレガシーレポートなどの非構造化データからの自動テーブル抽出に不可欠です。これにより、データクリーニングExcelを実行する際に、単なるテキストのダンプではなく、元の複雑な財務データの整合性を維持する論理的に整理されたテーブルが得られることが保証されます。
Q4: WebhookはデータクリーニングExcelワークフローをどのように改善しますか?
Webhooksは、Expertiseレベルの自動化におけるゲームチェンジャーです。automated table extractionの後、手動でファイルをダウンロードする代わりに、Webhookは処理が完了した瞬間に、クリーンなデータをERPやカスタムデータベースなどの別のアプリケーションに自動的に送信します。これにより、シームレスなai data processingパイプラインが作成されます。Data Cleaning Excelの場合、ブラウザを開くことなくスプレッドシートをバックグラウンドで更新できます。これは、バッチ処理からリアルタイムのGeneral Ledger管理およびReconciliationへの移行の鍵となります。
Q5: ai data processingにTabliSyncを使用する場合、私のデータは安全ですか?
セキュリティはTrustの基盤です。TabliSyncは、AES-256暗号化およびSOC2コンプライアンスを含むエンタープライズグレードのセキュリティを採用しています。unstructured data parsingを実行する際、お客様のデータは安全な環境で処理され、お客様の同意なしにグローバルモデルのトレーニングに使用されることはありません。complex financial dataを扱う専門家のために、GDPRまたはHIPAAに準拠するためのローカライズされたデータレジデンシーを提供しています。当社のautomated table extractionは、高速であると同時に安全であるように構築されており、General Ledgerをクリーンかつ機密に保ちます。
Q6: TabliSyncはGeneral Ledger reconciliationに役立ちますか?
もちろんです。Reconciliationは、当社のai data processingの主なユースケースの1つです。automated table extractionを使用して銀行取引明細書からデータを抽出し、unstructured data parsingを使用して内部請求書から詳細を抽出することにより、TabliSyncはトランザクションを自動的に照合できます。レビューのために不一致をフラグ付けするため、Data Cleaning Excelの作業を外れ値にのみ集中させることができます。この体系的なアプローチにより、General Ledgerは正確に保たれ、月次または四半期決算に関わる手作業が80%以上削減されます。
Q7: automated table extractionはどのような種類のファイルを処理できますか?
TabliSyncは汎用性のために構築されています。PDF(デジタルおよびスキャン済み)、ドキュメントのPNG/JPG画像、Excelファイル、CSV、さらにはHTMLエクスポートも処理できます。当社の非構造化データ解析エンジンは、影、折り目、または歪んだテキストがある「汚い」スキャンを処理するのに特に優れています。AIデータ処理は、これらの物理的な欠陥を補正し、自動テーブル抽出が99.9%の精度であることを保証します。これにより、最新のデジタル入力と並んで、古い紙の記録を処理する必要があるExcelデータクリーニングの専門家にとって究極のツールとなります。
Q8: Excelデータクリーニングの特定のニーズに合わせて出力スキーマをカスタマイズできますか?
はい、TabliSyncはカスタマイズで真価を発揮します。単なる一般的なテーブルではなく、必要な列、ヘッダー、データ型を正確に定義できます。非構造化データ解析のルールを設定して、フィールドを結合したり、文字列を分割したり、新しい値をその場で計算したりできます。これは、自動テーブル抽出が完了するまでに、データがすでに総勘定元帳または照合レポートに必要な正確な形式になっていることを意味します。これにより、Excelデータクリーニングの「VLOOKUPとピボット」の段階が不要になり、すぐに使用できる資産が得られます。
Q9: AIデータ処理パイプラインのセットアップにはどのくらい時間がかかりますか?
ほとんどの複雑な金融データタスクでは、15分未満で稼働できます。TabliSyncインターフェースは、結果を迅速に必要とする専門家向けに設計されています。サンプルをアップロードし、自動テーブル抽出のために列をマッピングするだけで、非構造化データ解析エンジンが残りを処理します。テンプレートが保存されると、将来のExcelデータクリーニングタスクは数秒で完了します。Webhookを実装している場合、宛先システムによってはセットアップに少し時間がかかることがありますが、長期的な効率性の向上は初期投資に見合う価値があります。
Q10: 手動クリーニングからTabliSyncに切り替えることによるROIは?
TabliSync の ROI は通常、最初の 1 か月以内に実現されます。Data Cleaning Excel に費やす時間を最大 90% 削減することで、人件費を大幅に節約できます。さらに重要なのは、ai data processing が高額な General Ledger エラーや Reconciliation の失敗のリスクを軽減することです。月に 500 件のドキュメントを処理するチームの場合、回収された時間だけで得られるcost savings は、サブスクリプション費用を 5 倍から 10 倍上回ることがよくあります。意思決定の迅速化とデータTrust の向上という価値を加えると、automated table extraction を選択することが明確になります。
結論:データ運命をコントロールする
手動の Data Cleaning Excel の時代は終わりを迎えようとしています。データ量が爆発的に増加し、complex financial data が標準となるにつれて、スプレッドシートを「力任せに」処理する従来の方法はもはや実行可能ではありません。unstructured data parsing をどのように制御できるか、そして automated table extraction が部門の Efficiency をどのように変革できるかを見てきました。しかし、知識は行動なしでは単なる負担です。待つ一日ごとに、「フォーマット税」に費やす時間が失われ、ヒューマンエラーが General Ledger を脅かす一日が失われ、チームが戦略ではなく単調な作業に費やす一日が失われます。
TabliSync は、専門家によって、専門家のために構築されています。私たちは ai data processing のニュアンスと、財務報告における Trust の重要性を理解しています。競合他社に優れたデータインテリジェンスで追い抜かれないようにしてください。すでに Reconciliation ワークフローを自動化した主要な財務アナリストの仲間入りをしてください。tablisync.com以下のリンクをクリックして、今すぐ TabliSync の無料トライアルを開始してください。tablisync.com99.9% の精度という強力な力を体験し、時間を再確保してください。データの未来は自動化されています。あなたはそれをリードする準備ができていますか? 今すぐ無料トライアルを開始して、Excel ワークフローを永遠に変革しましょう。
専門家向け Excelによるデータクリーニングマスターガイドとは?
専門家向け Excelによるデータクリーニングマスターガイドについての要点と、TabliSyncがExcel作業をどう速くするか。
専門家向け Excelによるデータクリーニングマスターガイドとは?
専門家向け Excelによるデータクリーニングマスターガイドは実務的なExcelワークフロー、よくある落とし穴、自動化パターンを扱います。このTabliSyncガイドが概念、例、関連チュートリアルを示します。
TabliSyncは専門家向け Excelによるデータクリーニングマスターガイドにどう役立ちますか?
スクリーンショットやPDFから表を抽出し、乱れたデータを整え、専門家向け Excelによるデータクリーニングマスターガイド関連の反復タスクを自動化します。
専門家向け Excelによるデータクリーニングマスターガイドはどこから始めればよいですか?
このページの概要から始め、下の関連記事でステップごとの手順とAIワークフローを確認してください。
すべての Excelによるデータクリーニング 記事(7)

Excel で行をまとめて並べ替える方法: 複雑なデータ テーブル ガイド
Excel テーブルまたは選択範囲の拡張オプションを使用することで、行の分割エラーを完全に排除し、並べ替え後のデータ修復時間を最大 90% 短縮します。 Power Query または構造化参照を使用して、手動選択なしで複数列のグループ化されたデータを横断して並べ替えを自動化し、ワークフローのステップを 8 クリックから 1 クリックに削減します。 AI OCR 前処理と TabliSync を並べ替え前に組み合わせることで、半構造化インポート(PDF、請求書)でのデータ破損を防ぎ、行の整合性を 99.5% 達成します。

キーボードショートカット「値の貼り付け」を使用して複雑なスプレッドシートデータをクリーニングする方法
手動での書式削除ではなく、直接ショートカットキーで値の貼り付けを使用することで、データクリーニング時間を最大80%削減します。 インポートされたデータセットまたはレガシーデータセットから、隠れた書式エラー、壊れた数式、一貫性のないデータ型を排除します。 マクロやVBAなしで、クリーンで再現可能なデータパイプラインを維持します — ネイティブExcelのキーストロークのみを使用します。 値の貼り付けとTabliSyncのような抽出ツールを組み合わせることで、構造化データと非構造化データのワークフローを橋渡しします。

クリーンなデータテーブルのためにExcelで箇条書きを行う方法
このガイドでは、構造化され分析可能なデータテーブルのために、Excelで箇条書きを追加してクリーニングする2つの効率的な方法について説明します。組み込みのExcelワークフロー(ショートカットキー、CHAR関数、Power Query、Excelテーブルなど)を使用して、簡単な1回限りの書式設定タスクを説明します。また、AI搭載のTabliSyncソリューションを紹介し、PDF、スクリーンショット、外部レポートから散らかった箇条書きリストを自動的に抽出し、標準化し、クリーンなExcel行に整理することで、一般的なデータクリーニングの問題を解決し、フィルタリング、分析、ダッシュボード作成のための繰り返し発生するビジネスデータワークフローを最適化します。

TabliSyncでExcelの空白行削除を効率化
空白行を削除する最も信頼性の高い方法は、ヘルパー列とCOUNTAチェックを組み合わせるか、Excelの組み込み機能「ジャンプ先」を使用することです。どちらの方法でも、見た目上空白の行を誤って削除することを避けることができます。空白行は、フィルターされたデータセット内や、レガシーシステムからのインポート後に隠れていることがよくあるため、削除する前に必ず選択範囲を確認してください。バックアップコピーを手元に用意するか、Ctrl+Zをセーフティネットとして活用してください。繰り返されるクリーニングワークフローには、Power Query がより一貫性があり、監査可能なパスを提供します。

Excel Online: コラボレーションをマスターし、主要な制限を克服する (2026)
• クラウドネイティブデータガバナンスを活用して、バージョン競合を90%削減し、リアルタイム共同編集を最適化します。 • 非構造化データ解析のためのAI駆動OCRを統合して、手動データ入力エラーを100%排除します。 • 2026年のOffice 365スプレッドシートのヒントを活用して、レガシーファイルサイズの遅延とブラウザベースの計算スロットルを回避します。

200以上のExcelショートカットチートシート:2026年の全ワークフローをマスター
● レガシーなマウス操作に代わる戦術的なキーボードシーケンスを習得することで、ワークフローの遅延を90%削減します。 ● ネイティブホットキーとAI駆動OCR同期を統合することで、手動データ入力エラーを100%排除します。 ● 戦術的なスプレッドシート操作から、高度なワークブックナビゲーションフレームワークを使用した戦略的なデータガバナンスへの移行。

データ入力規則のマスター: Excelでドロップダウンリストを作成する方法
ゼロエラー許容: Excelのデータ入力規則を実装することで、手作業による入力エラーを100%排除し、下流の数式の一貫性を保証します。 90%の時間短縮: 手動リスト管理からExcelの動的なドロップダウンリスト構造に移行することで、週単位のメンテナンス時間が数時間節約されます。 AI主導のガバナンス: 非構造化データ解析から構造化AI OCRワークフローへの移行は、静的なスプレッドシートをスケーラブルなデータ資産に変革します。
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す