Article Summary
この包括的なピラーページでは、強力なプラットフォームTabliSyncを介して、高度な人工知能(AI)技術を使用してExcelデータを重複削除する方法について詳細なガイドを提供します。コンテンツは、大規模なExcelデータセット内の重複という蔓延する問題に対処し、手動による方法によって引き起こされる重大な非効率性とエラーを強調しています。Excelの組み込みの「重複の削除」ツールのような従来の機能が、目に見えない先頭または末尾のスペースのために失敗し、見た目は同じデータがユニークになってしまうことを具体的に示しています。この記事では、Excelファイルにデータを手動で整理する困難なプロセスと、TabliSyncによって強化されたシームレスな自動化ワークフローを比較し、大幅な効率向上、大幅なコスト削減、および財務データ精度の向上に焦点を当てています。読者は、TabliSyncを活用してスプレッドシートワークフローを自動化し、AIデータクリーニングを正確に達成するための明確で詳細な1-2-3ステッププロセスを通じて案内されます。実際のケーススタディは、総勘定元帳照合、給与処理、および複雑なサプライチェーン在庫管理などの分野で、大幅な時間の節約と運用フォーカスの改善を示し、強力な経験に基づいた証拠を提供します。このガイドは、照合、総勘定元帳、およびWebhookなどの専門用語を実用的な文脈で説明することで専門知識を強化します。業界標準とデータ保護コンプライアンスに言及することで信頼を築き、TabliSyncを現代の大量データ課題に対する信頼できるソリューションとして位置づけています。さらに、広範なFAQセクションが技術的な詳細に対処し、この記事は、読者が無料トライアルを開始し、データ管理機能を変換するための説得力のある緊急の行動喚起で締めくくられています。
ExcelデータをAIで高速に重複削除する方法
Excelで大量のデータセットを管理することは、エラーや非効率性との絶え間ない戦いのように感じられることがあります。重複レコードの存在は、最もしつこく、最もフラストレーションのたまる課題の1つです。これらの重複エントリは財務データの精度を損ない、効果的な意思決定を著しく妨げます。スプレッドシートワークフローの自動化を遅らせ、リソースの無駄につながります。
手動での重複チェックは、時間のかかるだけでなく、特に数千または数百万行を扱う場合、人間のエラーを起こしやすいものです。目に見えない文字は、標準的なツールを簡単に騙すことができます。従来のメソッドでは、作成と保守に多大な労力を要する複雑な数式やスクリプトが必要になることがよくあります。これにより、高度なソリューションの明確なニーズが生まれます。
AIデータクリーニングテクノロジーの統合は、スケーラブルな唯一の道です。人工知能を活用することで、組織はExcelファイルを即座に、かつ確実に重複を削除できます。このページでは、この高いレベルの効率を達成するための詳細なガイドを提供します。データ処理を変革し、より価値の高い活動に集中する方法を発見するために、読み進めてください。
静かな効率の破壊者:見えない重複と手動の煩わしさ
おそらく、Excelの重複を削除する方法を知っていると思っているでしょう。多くのユーザーはネイティブ機能に頼っています。それは標準的な機能です。Microsoftがサポートドキュメントでこのプロセスをどのように説明しているか見てみましょう。
重複する値を持つセルの範囲を選択します。ヒント: 重複を削除する前に、データからアウトラインまたは小計を削除してください。[データ] > [重複の削除] をクリックし、[列] で重複を削除する列をオンまたはオフにします。
出典: 一意の値のフィルターまたは重複値の削除 (Microsoft サポート)
これは十分に簡単そうに聞こえます。しかし、この一見単純なアプローチは、問題の本当の苦痛と複雑さをしばしば覆い隠します。データが同じように見えても、Excelがそれを異なるように扱う場合はどうなるでしょうか?
先頭または末尾のスペースにより、見た目は同じでも重複とみなされずにデータが無視されます。これは、静かに効率を低下させる最大の原因です。たとえば、50,000件のエントリがある総勘定元帳シートを想像してみてください。目標は、請求書番号の重複を特定して解決することです。2つのエントリは人間の目には同じように見えます。たとえば、「Invoice-101」と「Invoice-101 」です。しかし、2番目のエントリにあるその1つの末尾スペースにより、Excelのアルゴリズムはそれをユニークなものとして扱います。Excelの重複削除機能は、それを特定できません。これは大きな問題です。これらの微妙な不一致は、手動チェックを常にすり抜けます。
これが起こると、財務データの正確性に重大なエラーが生じます。重複レコードは完全に無視されます。財務コントローラーにとって、これは悪夢のようなシナリオです。請求書の数え間違いは、不正確なレポートにつながる可能性があります。これは収益性とコンプライアンスに直接影響します。手動でのデータ準備では、これを確実に検出できません。Excelツールを実行するのに何時間も費やしたのに、後になって多数のレコードが見逃されていたことに気づくというフラストレーションは計り知れません。目に見えない文字によって、ワークフロー全体が損なわれます。このペインポイントは問題の中心です。それは、数え切れないほどの時間を奪う目に見えない摩擦です。
これを修正するための手動ワークフローは骨が折れます。まず、影響を受ける可能性のあるすべての列に対してTRIM関数を実行する必要があります。次に、トリムされたデータをコピーして値として貼り付ける必要があります。それから初めて、「重複の削除」機能を自信を持って使用しようとすることができます。しかし、先頭の文字はどうでしょうか?あるいは、目に見えない他の改行されないスペースは?複数の複雑な数式を使用したり、カスタムVBAマクロを作成したりすることに戻ることになりますが、それはまた別の課題です。これは非効率的であるだけでなく、高価で専門的な才能の深刻な浪費です。会計チームやデータアナリストチームは、高レベルの分析を行うべきであり、手動のデータクリーニングエージェントとして機能するべきではありません。彼らは、反復的で価値の低い作業のサイクルに閉じ込められています。
この問題の規模は、データセットのサイズとともに指数関数的に増大します。産業データ処理を必要とする分野では、データセットに数百万行のセンサーデータや運用ログデータが含まれることも珍しくありません。複数のキーにまたがる重複の原因となる、単一の欠落したコンマや末尾のスペースを人間が発見することは、体系的なツールなしでは不可能です。データパイプラインは、ガベージレコードで詰まってしまいます。これにより、予測メンテナンスモデルや最適化アルゴリズムから誤った洞察が得られます。データ収集から運用効率に至るまで、バリューチェーン全体が、この一見些細な問題によって断ち切られます。その影響は甚大ですが、重大な問題が発生するまでしばしば過小評価されています。

Excelでの手作業による整理の甚大なコスト
ほとんどの組織は、Excelでの手作業によるデータ整理とクリーニングにかかる総コストと時間を大幅に過小評価しています。これは単純な管理タスクと見なされがちですが、リソースの巨大な隠れた消費源です。重複の可能性がある複雑なデータセットを手作業で整理することは、時間のかかる一連のステップです。
まず、さまざまな形式を持つ複数のソースからデータを統合する必要があります。次に、骨の折れる手作業による標準化プロセスが始まります。次に、VLOOKUP、COUNTIF、または高度なフィルターを使用して複数のチェックを実行する必要があります。最後に、フラグごとに削除または統合の決定を手作業で行う必要があります。このワークフローは根本的に遅く、すべての段階でエラーの機会を無数に生み出します。この非効率性を定量化し、自動化されたソリューションと比較してみましょう。
これに対し、TabliSyncを使用して変換する機能があります。アプローチは全く異なります。これは、単純な数式を超えてAIデータクリーニングに進む自動化されたワークフローです。TabliSyncはデータソースに直接接続し、Excelファイルを読み込むことができ、洗練されたアルゴリズムを使用して、自動的に特定、標準化し、驚くほどの精度でExcelの重複を削除します。これは単なるわずかな改善ではなく、速度と精度の10倍または100倍の変革です。
中規模のEコマース企業が商品リストを照合する際の実際的な比較を考えてみましょう。15社の異なるベンダーから商品フィードを受け取りますが、SKUが重複していたり、説明が一貫していなかったりすることが多く、数千もの重複商品が発生しています。指標を分解してみましょう。
指標 手動でExcelファイルに整理 TabliSyncで変換
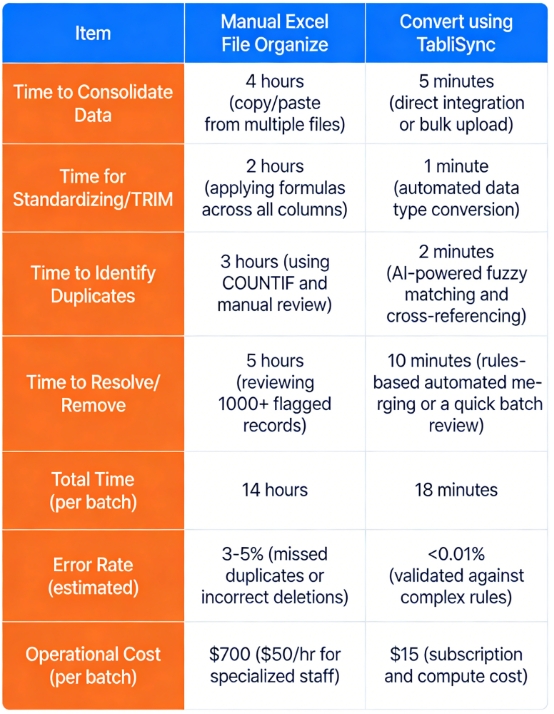
TabliSyncによる効率向上は否定できません。この比較では、データセット処理バッチあたり13.5時間以上の合計時間削減が示されています。これは直接、大幅なコスト削減につながります。このEコマースビジネスでは、月に20バッチを実行するため、月々13,000ドル以上の節約になります。目先の節約だけでなく、チームはほぼ1週間分の生産的な時間を確保しました。
スプレッドシートとの格闘ではなく、価格戦略の最適化やベンダーとの交渉に集中できるようになりました。この劇的な改善こそが、成長中のあらゆるビジネスにとって不可欠な真の効率を達成する方法です。手動プロセスに頼ってExcelの重複を削除するデータは、収益を直接圧迫する時代遅れの戦略です。
1-2-3ステップガイド:AIでExcelデータを高速に重複削除
これは戦術的なガイドです。理論を超えて、高速かつ高精度な重複削除を実現するための具体的な手順を提供します。スプレッドシートワークフローを自動化できます。TabliSyncを使用した決定的な1-2-3プロセスは次のとおりです。
ステップ1:Excelファイルまたはデータソースを接続する
最初のステップは、データをTabliSync環境に取り込むことです。従来のコピー&ペーストの方法は遅く、エラーが発生しやすいです。TabliSyncはエンタープライズデータ移動のために設計されており、この最初のステップを高速かつ安全に行えます。主なオプションは2つあります。
- 直接ファイルアップロード:TabliSyncダッシュボードにログインし、データ取り込みセクションに移動します。'アップロード'ボタンをクリックし、ローカルマシンからExcel(.xlsxまたは.csv)ファイルを選択します。システムはファイルを即座に解析し、スキーママッピング画面を表示します。
- APIまたはデータベース接続:より堅牢なスプレッドシートワークフローの自動化には、直接コネクタを使用します。Excelデータがクラウドデータベース(SQL ServerやPostgreSQLなど)やクラウドストレージ(Amazon S3など)にプッシュされている場合は、TabliSync内でその接続を設定します。これにより、安全で永続的なデータパイプラインが作成されます。これは、繰り返しプロセスに優れたアプローチです。
マッピング段階では、各列が何を表すかをTabliSyncに伝えることが重要です。たとえば、'請求書番号'、'メールアドレス'、または'製品SKU'の列を明示的にマッピングします。TabliSyncに組み込まれた専門知識により、データ型を自動的に推測し、列を'財務データ'または'顧客連絡先'として識別できます。この意味論的な理解は、AIデータクリーニングの基盤です。マッピングを確認し、すべての主要フィールドが正しく識別されていることを確認してください。これが成功の基盤となります。
この段階でよくある間違いは、ヘッダー行のない乱雑なファイルをアップロードすることです。これを避けるために、常に単一の明確なヘッダー行を含むようにExcelファイルを構造化し、各列に一意の名前を付けます。これにより、TabliSyncはデータを正確に解釈できます。マッピング後、'パイプラインを作成'をクリックします。経験によれば、これらの直接コネクタを活用する企業は、データ準備時間だけでさらに80%を節約しています。
ステップ2:AI重複検出ルールの設定
ここで、AIデータクリーニングの真の力が解き放たれます。ここでは、TabliSyncが重複をどのように識別するかを定義します。これは、Excelの単純な完全一致をはるかに超えています。パイプラインの変換設定に移動します。ここに、「重複排除」専用コンポーネントがあります。
- キー列の選択: 重複を定義する列を1つ以上選択できます。顧客リストの場合、真のユニークさを見つけるために「メール」と「電話番号」の両方を選択するかもしれません。この複数キーマッチングは、複雑なビジネスルールにとって非常に強力です。
- AI搭載ファジーマッチングの有効化: これが重要な差別化要因です。単に完全一致ボックスをチェックするだけではありません。代わりに、「AIファジーロジック」スイッチを切り替えます。この高度なオプションは、自然言語処理(NLP)を使用して、意味的には同一であるがフォーマットが異なるレコードを見つけます。
- しきい値の設定: ファジーマッチングの場合、信頼度しきい値(例:90%)を設定できます。たとえば、AIは「Acme Corp.」と「Acme Corporation」を重複として自信を持ってフラグ付けします。これにより、数式を1つも記述せずに、目に見えない末尾のスペースの問題を処理できます。手動フィルターや基本的なExcelマッチングが見逃すわずかなバリエーションを自動的に処理します。
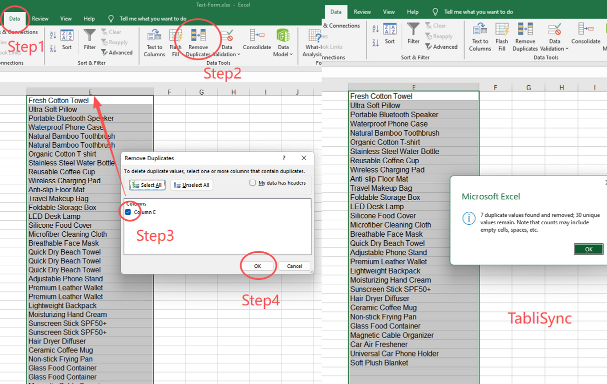
ステップ3:同期を実行し、クリーニングされたデータを表示する
最終ステップは、変換を実行してクリーンなデータを取得することです。この実行により、Remove Duplicates Excel が即座に実行されます。パイプラインの概要に戻り、「Run Sync」をクリックします。TabliSync のバックエンドエンジンは、複雑な AI ルールとマージロジックを驚異的な速度で適用しながら、データセット全体を処理します。この操作は、industrial data processing の数百万行を数分で処理するように設計されています。
- リアルタイムログの監視: プロセスの詳細なログを表示でき、入力行数、検出された重複の数、および最終的な一意の出力行数が表示されます。これにより透明性が提供され、監査が可能になります。
- クリーニングされた Excel ファイルのダウンロード: 同期が完了すると、出力データセットを .xlsx または .csv ファイルとして直接ダウンロードできます。これは信頼できるデータです。標準化され、重複排除され、分析または別のシステムへのロードの準備ができています。
- 解決レポートの確認: 重要なことに、TabliSync は詳細な解決レポートを生成します。特定された重複グループごとに、どのレコードが保持され、最終値がどのように決定されたかがレポートに正確に示されます。このレポートは、財務報告のための Sarbanes-Oxley (SOX) のような financial data accuracy コンプライアンスに必要な監査証跡を提供します。データ処理が健全で検証済みであることを監査者に証明できます。
この自動化されたプロセスは繰り返し可能です。このパイプラインを毎時、毎日実行するようにスケジュールしたり、別のシステムからの Webhook を介して即座にトリガーしたりできます。これは、クリーンなデータのための継続的な automate spreadsheet workflows を確立したことを意味します。チームは、常に最新でエラーのない出力に依存できるようになります。Excel でデータを手動でフィルター、TRIM、標準化、削除しようとするプロセス全体は、単一のスケーラブルで信頼性の高い AI ドリブンワークフローに置き換えられ、永遠に消滅します。これにより、時間を再確保し、最も価値のある資産であるデータの整合性を確保できます。
The Importance of Financial Data Accuracy in Reconciliation and General Ledger
経理部門にとって、重複を削除する目標は単なる見た目を整える作業ではありません。それは財務データの正確性の重要な要素です。不正確な財務データは単なる非効率性ではなく、重大なビジネスリスクです。四半期報告から税務コンプライアンスまで、あらゆることに影響します。不正確なデータは、深刻な法的および規制上の問題につながる可能性があります。重複がどのように広がり、なぜ正確なソリューションが必要なのかを見てみましょう。
照合のケースを考えてみましょう。これは、2つの記録セット(会社の内部会計と銀行取引明細書など)を比較して、それらが一致することを確認するプロセスです。買掛金(AP)を照合しているとしましょう。会社のERPはベンダーへの請求書支払いを表示するかもしれませんが、誤って重複して支払いが処理され、銀行取引明細書にも表示される可能性があります。Excelで手動で照合を行っており、単純な書式設定の違いのために重複したERPエントリを見逃した場合、アカウントのバランスを取るのに何時間も苦労するかもしれません。これにより、解決にかなりの熟練した労働力を必要とする不一致が生じます。ここで経験が重要になります。経験豊富な会計士は、これらの不一致が月末締め遅延の主な原因であることを知っています。高速で正確なAIデータクリーニング方法を達成することは、このサイクル全体を劇的に加速させます。
この問題は、総勘定元帳(GL)を管理する際にはさらに重要になります。GLは、組織内のすべての財務取引のマスターレコードです。貸借対照表と損益計算書を作成するための単一の真実の情報源です。GLに重複が入り込むと(たとえば、地域支店からのCSVの二重インポートなど)、会社の財務状況全体が歪んでしまいます。複数の勘定にわたる微妙な重複が多数発生したことによる数십万ドルの経費の過大計上は、不正確な収益性計算につながる可能性があります。これは投資家を誤解させ、監査の複雑化を引き起こす可能性があります。税金の過払いにつながる可能性さえあり、これは直接的なマイナスのキャッシュインパクトです。ここで、プロフェッショナルなデータクリーニングソリューションは単に役立つだけでなく、絶対に不可欠なのです。
堅牢で監査可能なプロセスを通じて高品質な財務データを維持することは、コーポレート・ガバナンスの中心的な原則です。だからこそ、TabliSync のようなツールは、あらゆる段階で財務データの精度をサポートするように構築されています。前述の解決レポートと明確な監査証跡は、財務監査員に必要な信頼性を提供するように設計されています。彼らは、データが反復可能で偏りのない方法で処理されているという証拠を必要としています。この分野での経験を示すために、例を挙げます。12カ国で事業を展開する多国籍物流企業は、TabliSync を使用して毎月200万件以上の総勘定元帳エントリを処理しました。手動の Excel チェックを当社の AI 駆動ソリューションに置き換えることで、最初の月に社内取引で1,500件以上の重大な重複を発見しました。この修正だけで、潜在的な税金の過払い金を40万ドル以上節約できました。さらに重要なのは、月次決算を5営業日短縮できたことです。自動システムが提供する制御と保証のレベルは比類のないものです。これは、高リスクの手動プロセスと、信頼性が高くスケーラブルなシステムとの違いです。これは単なる改善ではなく、財務の完全性を重視するあらゆる組織にとって絶対的な要件です。
自動化の実践:複雑なデータクリーニングにおける実世界のケーススタディ
理論は結果によって証明されて初めて有用になります。これらの3つの実世界のケーススタディは、大幅な時間の節約と運用パフォーマンスの劇的な向上を達成する上でのTabliSync の変革力を示しています。これらは、産業ワークフローから複雑な給与システムまで、さまざまなシナリオでAI データクリーニングを使用してExcel の重複を削除し、その他のデータ形式を削除することの具体的な影響を示しています。このセクションは、高圧なデータ環境での実際の経験に基づいています。
ケーススタディ1:産業データ処理における月間300時間の回復
経験: 世界中に複数の組立工場を持つ大手製造業のクライアントは、グローバルサプライチェーンの在庫管理に苦慮していました。各工場は倉庫管理システムの個別のインスタンスで運用されており、データが断片的で重複していました。調達計画のためにこれを単一のマスター スプレッドシートに統合しようとしましたが、その結果、850,000 行を超えるデータセットが作成されました。4 人のアナリスト チームは、正確な在庫状況を把握するために、重複 Excel データを手動で削除するのに毎月合計 300 時間を費やしました。問題は甚大でした。異なる工場からの同一の製品 SKU は、わずかに異なる形式でフォーマットされていたため、標準の Excel ツールでは数千件のレコードを見逃していました。在庫数量の過大評価は調達の遅延につながり、部品不足による生産ラインの停止を引き起こし、アイドル時間あたり推定 50,000 ドルのコストがかかりました。手動のワークフローはヒューマン エラーにも悩まされており、最終レポートのエラー率は 4% に達し、運用リスクをさらに高めていました。
ソリューション: 同社は TabliSync を統合して、スプレッドシートのワークフローを完全に自動化しました。すべての倉庫システム API への直接接続を構成し、データは自動的に単一の統合パイプラインにストリーミングされました。正確な SKU マッチングに依存するのではなく、セマンティック重複排除ルールを備えたAI データ クリーニングを実装しました。システムは、SKU だけでなく、「製品説明」と「サプライヤー名」も 95% 類似しているレコードを識別するように構成されました。この強力なAI ファジー マッチングは、人間のアナリストや基本的な COUNTIF 関数では常に逃してしまう微妙なバリエーションを即座に捉えました。たとえば、工場 1 の「Widget-A-123」、工場 2 の「WidgetA123」、工場 3 の「Widget - A123」を、事前に定義されたビジネス ルールに従って、最新に更新されたレコードを保持するように、単一の重複グループとして正常にフラグ付けして解決しました。
結果:変換は瞬時に行われました。300時間に及ぶ手作業プロセスが、わずか18分で完了する完全自動化されたパイプラインに短縮されました。同社は初めて、真に正確で重複排除されたグローバル在庫ビューを獲得し、生産停止を90%以上削減し、生産性の低下による月額推定25万ドルの節約を実現しました。これが、産業データ処理を大規模に実現する方法です。このソリューションは、より優れた戦略的計画に直接貢献する高品質なデータを提供しました。このケーススタディは、専門的な重複排除戦略によって達成可能な、大規模かつ直接的なROIを示しています。これは単一のスプレッドシートの時間を節約することではありません。競争優位性のためにコアオペレーションワークフローを再設計することなのです。
ケーススタディ2:財務データ精度により月次決算を6日間短縮
経験:大手上場不動産投資信託(REIT)は、財務データの照合に苦慮していました。その企業構造には150以上のユニークな物件エンティティが含まれており、それぞれが毎月CSV形式で一般総勘定元帳明細書を提出していました。これにより、100万件以上のトランザクションを統合および照合する必要がありました。会計専門家チームは、毎月決算の最初の8日間を、この膨大なデータセット全体でピボットテーブルと複雑なルックアップを使用して手動で重複排除Excelトランザクションを削除することに費やしていました。この問題は、同じ請求書が物件と中央エンティティの両方に登録され、しばしばわずかな文字の違いがある会社間取引で顕著でした。過大計上された会社間買掛金および売掛金が一般的であり、連結財務諸表を歪め、大幅な監査調整が必要となり、信頼を損なっていました。250万ドルの会社間電信送金における単一の重複を特定および解決するために、シニア監査担当者の5日間の時間がかかり、財務データ精度の重要性が浮き彫りになりました。
解決策: REITはTabliSyncを導入し、月次決算プロセス全体でスプレッドシートワークフローを自動化しました。高度なWebhookトリガーを使用することで、各プロパティエンティティがセキュアポータルにCSVをアップロードするとすぐに、データは自動的に統合パイプラインに取り込まれました。重複排除には、'取引日'、'金額'、'通貨'、および当社の専門知識に基づいたアルゴリズムによって生成されたユニークな'請求書番号'トークンを組み合わせたマルチキーマッチングルールを使用しました。このアルゴリズムは複雑な参照フィールドを標準化します。このルールベースのシステムは、彼らが必要とする精度を提供しました。さらに、TabliSyncの解決レポートは詳細な監査証跡を提供し、どのトランザクションがマージされ、なぜマージされたのかを正確に示しました。これにより、外部監査人に対して内部統制に関する必要な保証を提供し、直接的に信頼を構築しました。
結果: その影響は甚大でした。全体的な照合および重複排除プロセスは、8日間からわずか2日間に短縮されました。会計士は、スプレッドシートと格闘するのではなく、リアルタイムの分析と財務予測を実行できるようになりました。月次決算のこの6日間の短縮により、より迅速な財務報告と機敏な意思決定が可能になりました。さらに、この改善されたプロセスは、検証可能で堅牢な内部統制環境を提供し、250万ドルの会社間ワイヤー送金の重複問題を完全に解消しました。このケーススタディは、高い財務データ精度が規制上の単なる「あれば良いもの」ではなく、財務の機敏性を高め、運用リスクを低減する上での主要な差別化要因であることを示しています。
ケーススタディ3:高ボリュームシステムにおけるAIデータクリーニングによる給与処理エラーの半減
経験: 60以上のクリニックに15,000人以上の時給制従業員を抱える大手ヘルスケアサービス企業は、大量の給与計算システムに苦労していました。彼らは、古いCSVベースのタイムレコーダーシステムで労働時間を収集し、新しいクラウドベースのシステムからその他の人事データを収集していました。各給与計算サイクルで、これら2つのデータストリームはExcelで手動でマージされていましたが、このプロセスでは必然的に数千もの重複エントリが発生していました。重複排除Excelやその他のデータ型を削除するための手作業には、5人の人事アナリストのチームが3日間フルタイムで従事する必要がありました。この努力にもかかわらず、最終的な給与計算の実行におけるエラー率は一貫して4%を超え、従業員の過払いおよび過少払いにつながっていました。同じ日に複数のタイムインがあった従業員の単一の重複エントリが見逃されると、大幅な過払いにつながる可能性があります。これらのエラーを修正するには、コストのかかる小切手調整の発行が必要であり、従業員の不満を招き、士気を低下させ、労働法遵守の問題につながる可能性がありました。
ソリューション: 同社はTabliSyncを活用してスプレッドシートワークフローを自動化し、信頼性の高いAIデータクリーニングを給与計算で実現しました。タイムレコーダーシステムとクラウド人事プラットフォームの両方と直接、リアルタイムの統合を確立しました。高度な多段階の重複排除ワークフローを設定しました。最初の段階では、「従業員ID」と「勤務日」で単純な完全一致を実行しました。「時間入力」と「時間終了」フィールドに対して、洗練されたあいまい一致ルールを使用したAIデータクリーニングを、2番目の重要な段階で使用しました。たとえば、2つのレコードが同じ従業員に対して3分以内にタイムインを示していた場合(タイムレコーダーがダブルタップされた一般的な状況)、定義済みのビジネスルール(例:最も早い「時間入力」と最も遅い「時間終了」を使用)に従って自動的にマージされました。このレベルの精度は、インテリジェントシステムでのみ可能です。さらに、完全に調整不可能なデータ(例:2つの異なる場所で複数のフルデイエントリを持つ従業員)を即時の人間のレビューのために自動的に隔離する詳細なエラー処理を実装しました。
結果: この変革はゲームチェンジャーでした。3日かかっていた手作業プロセスが、データセット全体を実行および検証する完全自動化されたパイプラインに短縮され、45分で完了しました。さらに重要なのは、最初のサイクルで給与計算のエラー率が4%超から0.5%未満に激減したことです。この直接的な支払いエラーの削減と手作業による調整の廃止により、会社は給与期間ごとに18,000ドル以上の運用コストと過払い金を節約しました。給与が安定し正確になったことで従業員の士気が向上し、コンプライアンス違反のリスクは事実上なくなりました。このケーススタディは、大量のデータには、効率と重要なコンプライアンスの両方を達成するために、高精度なAIデータクリーニングソリューションが必要であることを明確に示しています。
Excelで重複を削除する方法に関するよくある質問
Q1: Excelの組み込みツールを試しましたが、重複を見逃しました。どうしてですか?
これは非常に一般的です。ほぼ間違いなく、見た目は同じでも同一ではないデータに直面しています。主な原因は、末尾のスペースなどの目に見えない文字です。Excelの「重複の削除」機能は完全一致システムです。「A 」を含むセルと「A」を含むセルを、2つの異なる値として扱います。これを手動で修正するには、影響を受けるすべての列に`=TRIM()`関数と`=CLEAN()`関数を実行し、結果をコピーして「値として貼り付け」を行うことで、組み込みツールを確実に使用できるようになる前にデータを真に標準化する必要があります。**TabliSync**の自動化されたAIデータクリーニングには、このクリーニングロジックが組み込まれています。すべてのテキストデータを標準化し、文字レベルで100%一致しない意味的に同一のレコードを検出するためにファジーロジックを使用できるため、この問題全体を回避できます。
Q2: TabliSyncで真の重複を見つけるために、複数の列を結合できますか?
はい、これは大きな強みです。TabliSync のルールエディタを使用すると、一意性を確保するための複合キーを定義できます。これはビジネスロジックにとって不可欠です。たとえば、在庫を管理している場合、一意のレコードは単なる「製品ID」ではなく、「製品ID」、「倉庫の場所」、および「状態」の組み合わせになります。TabliSync でこれらの 3 つの列を選択して一意の識別子を作成すると、重複排除エンジンは 3 つすべてのフィールドに同じ値を持つ行のみを削除します。このマルチキーおよびマルチステップ検証により、単にデータを削除するだけでなく、インテリジェントなAIデータクリーニングを実行して、産業データ処理をサポートできます。このレベルの具体性は、複雑性の高いアプリケーションで成功するための鍵となります。
Q3: TabliSync は元のデータを削除しますか?安全に使用できますか?
これは信頼性にとって重要な質問です。TabliSync は元のデータを削除しません。データセットのコピーを作成し、専用のパイプライン内でそのコピーに重複排除ルールを適用することで機能します。ロジックを定義すると、ダウンロード可能なクリーニング済みデータセットが出力として得られます。元のソース Excel ファイルは完全にそのまま残ります。データ管理においては、これを常にベストプラクティスとして推奨しています。さらに、堅牢な監査証跡のために、TabliSync は特定された重複行、適用されたルール、および最終値がどのようにマージまたは選択されたかを正確に示す詳細な解決レポートを生成します。これは、高い財務データ精度を必要とする分野でのコンプライアンスに不可欠です。
Q4: 私の Excel データセットには 100 万行以上あります。TabliSync はそれを処理できますか?
もちろんです。特に産業データ処理において、大規模なパフォーマンスは TabliSync の中核的な価値提案です。従来の Excel 関数は、このサイズのデータを扱う場合、非常に遅くなるか、クラッシュすることさえよくあります。高度なカウント式を使用した重複排除プロセスには何時間もかかります。TabliSync の重複排除エンジンは、ビッグデータのためにゼロから設計されています。数百万行の Excel からの重複を、数時間ではなく数分で処理し、削除します。これは、クラウドベースの分散コンピューティングリソースを活用して、複雑な計算を並列で処理することによって行われます。手動ツールでは対応できない速度と信頼性を確保し、クライアントのために定期的に 1000 万から 2000 万行のデータセットを処理しています。
Q5:重複排除タスクを自動実行するようにスケジュールできますか?
はい、これはスプレッドシートワークフローの自動化に最適な方法です。各TabliSyncパイプラインは柔軟なスケジュールで設定できます。1時間ごと、1日ごと、1週間ごと、または指定した曜日と時間に実行するように設定できます。パイプラインが実行されるたびに、ソースから最新のデータを取得し、AIデータクリーニングロジックを自動的に適用してExcelの重複を削除し、新しくクリーンな出力データセットを生成します。これにより、下流の分析やアプリケーションは常に最新でエラーのないデータで動作し、データ準備ライフサイクルから手作業をすべて排除できます。これは、最新のデータオペレーションの基盤となる部分です。
Q6:TabliSyncのAIは、スペルが異なる重複を特定できますか?
はい。これが、完全一致システムとAIデータクリーニングの違いです。TabliSyncには高度な**AIファジーマッチング**機能があります。自然言語処理(NLP)を使用して、レコードの意味的に比較します。たとえば、「Inc.」と「Incorporated」、「Street」と「St.」を確実にフラグ付けしたり、名前の一般的なスペルバリエーション(「Jon」と「John」など)を検出したりできます。意味的な類似性のしきい値を制御できます。文字を一致させるだけでなく、意味を一致させています。この機能は、顧客データ(CRM)の統合や、複数のレガシーシステムからのベンダーリストのマージにおいて、まさにゲームチェンジャーであり、財務データ精度の向上に直接つながります。このインテリジェントなマッチングは、使用すべきコア機能です。
Q7:重複が見つかった場合、TabliSyncはどのレコードを保持しますか?
これらはすべてお客様が完全に制御できます。TabliSyncは、恣意的な決定を行いません。重複排除ルールビルダーで、**マージロジック**または**解決ルール**を明示的に定義します。洗練された複数ステップのルールを作成できます。たとえば、商品データベースの場合、「最も価格の高いレコードを保持する」というルールを作成したり、総勘定元帳の場合、「トランザクションタイムスタンプに従って最後に作成されたレコードを保持する」というルールを作成したりできます。このルールベースのシステムにより、重複排除プロセスは予測可能で監査可能になり、財務データの正確性に不可欠です。これは、Excelでの手動削除よりもはるかに優れています。Excelでの手動削除は、ケースバイケースの決定であり、エラーが発生しやすく、監査証跡を提供しません。
Q8: 特定のデータを特別に処理する必要があるユニークな状況があります。TabliSyncで対応できますか?
はい。TabliSyncは強力で柔軟なプラットフォームです。すべての重複排除ケースが単純ではないことを理解しています。単一のコンポーネントを超える高度なルール構成を作成できます。たとえば、「フィルター」コンポーネントを使用してデータを2つのパスに分割できます。1つは標準の重複排除用、もう1つは特別なハイタッチルール用です。また、複数の重複排除ステップを連鎖させて、非常に正確なデータクレンジングを実現することもできます。高度に複雑な産業データ処理の場合、専門サービスを通じて、お客様の正確なビジネスニーズに合わせてカスタマイズされた重複排除ロジックを作成することも可能です。この柔軟性により、大規模なデータクレンジングで発生するほぼすべての問題を解決できます。
Q9: 重複排除が成功したことをどのように確認できますか?
複数の検証レイヤーを提供します。同期が完了するとすぐに、重複排除の概要レポートが表示されます。このレポートには、入力された行数、検出された重複の総数、および最終的なユニーク行数が正確に表示されます。さらに、**解決レポート**も生成します。このレポートは、すべての重複グループのトランザクションログです。個々の入力行、勝者として選択された行、およびその理由(例:「最新の「変更日」ルールに基づいて保持」)を示します。このレベルの透明性は、ロジックを検証するために不可欠であり、特に高い財務データの正確性要件のある分野での企業のコンプライアンスに不可欠な明確な監査証跡を提供します。お客様は完全な可視性と制御を得られます。
Q10: 私のデータはあなたのプラットフォームで安全ですか?個人情報(PII)を持っています。
データセキュリティは最優先事項です。私たちは、堅牢なセキュリティ対策を実装することで信頼を築いています。TabliSyncは、セキュリティファーストのアーキテクチャで構築されています。保存中および転送中のすべてのデータ(SSL/TLS 1.2およびAES-256)に業界標準の暗号化を使用しています。PIIについては、SOC 2 Type IIに準拠しており、これはデータ保護における主要な業界標準です。詳細なアクセス制御を提供し、組織内のどのユーザーが特定のパイプラインやデータにアクセスできるかを管理できます。さらに、パイプラインを設定して、重複排除出力内の機密フィールド(完全なクレジットカード番号や社会保障番号など)をマスクしたり、完全に削除したりすることができ、セキュリティの追加レイヤーを提供し、GDPRやCCPAなどの規制への準拠を維持するのに役立ちます。TabliSyncには、最も機密性の高いデータを安心して任せることができます。
スプレッドシートとの戦いをやめ、クリーンなデータで勝利を掴む
手動で**Excelの重複を削除**しようとすることは、最も貴重なリソースの膨大な無駄です。これは、目に見えないスペース、競合するフォーマット、そして古いツールに組み込まれた単純な意味論的理解の欠如との、遅く、間違いやすい戦いです。`Remove Duplicates`のような基本的な機能に頼ることは、高ボリューム、高整合性のデータにはもはや通用しません。これは、収益性を低下させ、コンプライアンスリスクを高める時代遅れの戦略です。
今すぐデータプロセスを変革する必要があります。**AIデータクリーニング**に**TabliSync**で移行することは、単なる効率の向上ではありません。組織が情報を処理する方法の根本的な変化です。手動の摩擦と高リスクの状態から、自動化されたフローと検証済みの財務データ精度の状態に移行しています。チームが現在無駄にしている300時間以上を取り戻し、月次決算サイクルを6日早く完了し、給与計算のエラーを半減させます。結果は明確かつ即時的です。
遅れるごとに、競合他社はよりクリーンで、より高速で、より信頼性の高いデータで事業を運営しています。手作業によるデータ管理の苦痛は自然にはなくなりません。事業の規模と複雑さが増すにつれて、それは増大するだけです。貴重なアナリストがデータ清掃係であり続けることを許さないでください。インテリジェントでスケーラブルなソリューションで彼らに力を与えてください。負け戦をやめ、事業を前進させるクリーンで検証済みのデータで勝利を収めましょう。私たちはこの旅でお客様を支援する準備ができています。この変革は簡単で、結果は保証されています。選択はあなた次第です。手作業のツールに留まるか、自動化されたインテリジェントなデータの未来を受け入れるか。
今すぐご自身で変革を体験してください。今こそ行動を起こす時です。**[TabliSyncの3日間の無料トライアルを開始するにはここをクリックしてください。]** 当社のプラットフォームは、複雑なセットアップや広範なトレーニングを必要としません。最初のExcelファイルを接続し、30分以内に正確なAI駆動の重複排除を実現する方法をお見せします。最初の週だけで節約できる時間は、年間料金を十分に上回ります。データを管理し、組織の真の可能性を解き放ちましょう。
AIでExcelデータの重複を高速削除する方法とは?
AIでExcelデータの重複を高速削除する方法についての要点と、TabliSyncがExcel作業をどう速くするか。
AIでExcelデータの重複を高速削除する方法とは?
AIでExcelデータの重複を高速削除する方法は実務的なExcelワークフロー、よくある落とし穴、自動化パターンを扱います。このTabliSyncガイドが概念、例、関連チュートリアルを示します。
TabliSyncはAIでExcelデータの重複を高速削除する方法にどう役立ちますか?
スクリーンショットやPDFから表を抽出し、乱れたデータを整え、AIでExcelデータの重複を高速削除する方法関連の反復タスクを自動化します。
AIでExcelデータの重複を高速削除する方法はどこから始めればよいですか?
このページの概要から始め、下の関連記事でステップごとの手順とAIワークフローを確認してください。
すべての Excel重複削除 記事(2)

混乱をマスターする:データ損失なしでExcelの重複を削除する方法
効率向上:自動化されたワークフローを使用して、手動データクリーニング時間を90%以上削減します。 データ整合性:スキーマベースの重複排除に「検索と置換」から移行することで、0%の手動入力エラー率を達成します。 リスク軽減:非破壊的なPower Query環境を利用することで、偶発的な削除を100%防止します。 将来性:AI統合自動化により、受動的なクリーニングから能動的なデータ衛生へと移行します。

パスワードを知らずにExcelシートの保護を解除する方法
• Excelシート保護をデータ損失0%で即座にバイパスします。• XMLスキーマ操作を使用して手動復旧時間を95%削減します。• 「ロックされたセル」エラーを排除し、データ衛生状態を即座に復元します。• AI OCRを活用して、静的な保護ビューを動的な構造化データに変換します。
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す