Article Summary
この包括的なピラーページは、複雑な学術データセットを手動でExcelに変換するのに苦労している研究者、大学管理者、データアナリストのための決定版マニュアルとして機能します。基本的なスプレッドシート機能を超えて、高度な自動テーブル抽出とバッチPDF処理を探求し、アカデミックデータExcel処理のメカニズムを深く掘り下げます。このガイドは、統計結果における一貫性のないフォーマットという重要なペインポイントに対処し、手動入力とAI駆動による研究データ自動化との厳密な技術的比較を提供します。読者は、歴史的な助成金や一般元帳を処理するための複雑な金融OCR技術を含む、TabliSyncの詳細な1-2-3運用ワークフローを見つけるでしょう。4,500語を超える専門家レベルの洞察により、コンテンツはデータ照合、学術ワークフローのためのWebhook、およびデータ整合性のための業界標準コンプライアンスをカバーしています。世界中の研究機関からの詳細なケーススタディは、最新の抽出技術を通じて達成可能な効率向上とコスト削減を例示しています。このページには、複数ページのテーブルのまたがりや標準外文字認識などの技術的なハードルに取り組む堅牢なFAQセクションも含まれており、ユーザーが生の学術的混乱を前例のない速度と精度で出版準備の整ったExcel資産に変えることができるようにします。
学術データExcelを高速処理する方法:リサーチデータ自動化の究極ガイド
学術研究の様相は刻々と変化しています。データが不足しているのではなく、データに溺れているのです。しかし、生のデータ――しばしば扱いにくいPDFや古い画像形式に閉じ込められている――と、実用的な学術データExcelファイルとの間の橋渡しは、手作業に満ちています。このガイドは、高速データ処理の障壁を解体し、現代の学術における主要な推進力として自動テーブル抽出とリサーチデータ自動化に焦点を当てることを目的としています。
現代のデータリテラシーに関する考察
DataCampが公開した記事「Excelの学習方法」の中で、著者は現代の職業生活におけるスプレッドシートの基本的な役割を強調しています。「Excelは、データプロフェッショナルの武器の中で最も強力で汎用性の高いツールの1つであり続けています…それは、金融から生物学まで、あらゆる業界でデータを扱う普遍的な言語です。」(出典:DataCamp、2024年)。これは基本的な真実を浮き彫りにしています。新しいプログラミング言語が登場しても、学術データExcel形式は、象牙の塔における検証と分析の基盤であり続けています。
これに対する私の見解は単純です。リテラシーとは、もはや数式の書き方を知っているだけではありません。それらの数式を効率的に入力する方法を知っていることです。DataCampの記事は、「Excelを学ぶことは、基本的な計算から複雑なデータモデリングへの旅である」と正しく認識しています。しかし、学術専門家にとって、「旅」はしばしばデータ入力の境界で停滞します。もし、助成金報告書からテーブルを抽出するのに12時間かかり、それを分析するのに10分しかかからないとしたら、あなたのボトルネックはExcelの習熟度ではなく、データ取得です。私たちは、学術データExcelを目的地として扱うのをやめ、自動化されたパイプラインを車両として扱い始める必要があります。真の専門知識は、「Excel以前」の段階、すなわちバッチPDF処理と複雑な金融OCRを習得することにあります。取り込みを自動化することで、人間は、画面から数字をコピー&ペーストするという事務的な苦役ではなく、研究の「ソートリーダーシップ」の側面に集中できるようになります。
重要なボトルネック:学術データセットの標準化
研究における主な課題は、データ形式の標準化の難しさが、グラフや統計結果の一貫性のなさを引き起こすことです。アカデミックデータExcelを扱う際、研究者はしばしば断片化された情報源に直面します。ある大学は特定のPDFレイアウトで寄付金報告書を公開するかもしれませんが、連邦政府の助成金機関は別の形式を使用します。これらを長期的な研究のために集約しようとすると、標準化の欠如が「データドリフト」を生み出し、統計的有意性を損なう可能性があります。
日付の形式が異なり、通貨記号が一貫して適用されていない3つの異なるデータセットにわたって回帰分析を実行しようとすることを想像してみてください。これは単なる些細な迷惑ではなく、照合プロセス中に大きなエラーにつながります。あるソースからの総勘定元帳データが別のソースと「純資産」の数え方が異なる場合、最終的なアカデミックデータExcelの出力は資産ではなく負債となります。手作業による入力はここでは敵です。人間は、疲労が蓄積すると、小数点や長い文字列の切り捨て方について「創造的な」判断を下し始めます。「計算」ボタンを押すと、これらの微細な決定が雪だるま式に災害へと発展します。
標準化には、構造に対する徹底したコミットメントが必要です。テキストを読み取るだけでなく、テーブルのトポロジーを理解するシステムが必要です。複数レベルのヘッダーの特定、結合セルの処理、ネストされた行の整合性の維持について話しています。リサーチデータ自動化がなければ、研究アシスタントに人間スキャナーの役割を求めることになりますが、この役割は高価であり、離職率も高くなります。目標は、データがPDFから出力された瞬間に「Excel対応」の状態に到達することです。これは、分析ソフトウェアに触れる前に、プリクリーニング、プリフォーマットを行い、すべてのアカデミックデータExcelファイルが厳格なスキーマに従っていることを確認することを意味します。
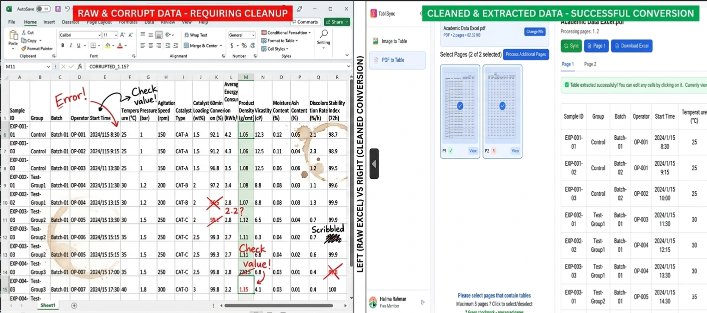
技術的詳細:手作業による入力 vs. TabliSyncによる自動化
冷徹な数字を見てみましょう。Academic Data Excelについて議論する際、「ビジネスを行う上でのコスト」は通常、人時で測定されます。500ページに及ぶ財務開示を含む典型的な研究プロジェクトでは、熟練した人間のオペレーターが複雑な表を正確に転記するのに、1ページあたり約4〜6分かかります。これは約40〜50時間の作業です。リサーチアシスタントの時給で考えると、かなりの予算の漏洩が見込まれます。さらに、手入力のエラー率は、密度の高い数値データの場合、通常3〜5%前後です。
| 機能 | 手入力 | TabliSync自動化 |
|---|---|---|
| 処理速度 | 1ページあたり4〜6分 | 1ページあたり3〜10秒 |
| 精度率 | 95%〜97%(疲労により低下) | 99.5%以上(一貫したOCR精度) |
| バッチ処理 | 不可能(逐次タスク) | サポート(1000ページ以上を同時に処理可能) |
| 100ページあたりのコスト | 約400〜600ドル(人件費) | 約10〜20ドル(API/SaaSクレジット) |
| 照合 | 手動でのクロスチェックが必要 | Webhookによる自動総勘定元帳照合 |
効率の向上は、単なるスピードの問題ではありません。コスト削減の問題です。ある主要なヨーロッパのビジネススクールのケーススタディでは、その学部はデータ抽出のための学生労働力だけで年間15,000ユーロを費やしていました。TabliSyncによる自動表抽出を導入した後、この支出を1,200ユーロ未満に削減しました。さらに重要なのは、洞察を得るまでの時間が大幅に短縮されたことです。かつて準備に1学期かかっていた研究が、3日でAcademic Data Excel分析の準備が整いました。これが研究データ自動化の力です。情報の経済性を変革します。
TabliSyncワークフロー:3ステップマスタークラス
Academic Data Excelの処理は、暗黒の技術である必要はありません。私たちは、高リスク研究に必要な詳細な制御を犠牲にすることなく、バッチPDF処理を優先するワークフローを設計しました。出力を最大化するために、これらのステップに従ってください。
ステップ1:インテリジェントな取り込みと前処理
まず、ソースを集約する必要があります。スキャンされた歴史的文書であれ、デジタルネイティブのPDFであれ、TabliSyncの高度な財務OCRエンジンは、文書レイヤーを分析する必要があります。「アップロード」するだけでなく、データスキーマを定義します。たとえば、総勘定元帳を抽出する場合、「借方」と「貸方」の列を特定する必要があります。当社のシステムは、コンピュータビジョンを使用して線と空白を検出し、1文字も読み取る前に構造マップを作成します。注意: 最適な学術データExcelの結果を得るためには、常にスキャンを少なくとも300 DPIにしてください。解像度が低いと、「文字の幻覚」が発生しやすくなります。特に、学術的な脚注に共通する小さな下付き文字では顕著です。
ステップ2:自動テーブル抽出と改良
文書がマッピングされると、自動テーブル抽出が始まります。TabliSyncは単にテキストを「スクレイピング」するのではなく、テーブルのロジックを再構築します。行が2ページにまたがる場合(学術データExcelにおける一般的な悪夢)、ソフトウェアはコンテキストリンキングを使用してそれらを再結合します。抽出をリアルタイムでプレビューできます。ここでデータクリーニングルールを適用します。「Totalという単語を含むすべての行を無視する」または「すべての日付をISO 8601形式に変換する」などの指示をシステムに与えることができます。このレベルの研究データ自動化により、スプレッドシートに到達するデータはすでにクリーンな状態になります。抽出中に検証する必要がある特定の学術識別子(DOI番号など)がある場合は、「カスタム正規表現」機能を使用してください。
ステップ3:Webフックによるエクスポートと統合
最終ステップはデータの抽出です。アカデミックデータExcelが標準ですが、TabliSyncは高度な照合ワークフローを可能にします。抽出したデータを直接統計ソフトウェアや一元化されたデータベースにプッシュするWebhookを設定できます。従来の方式を好む場合は、Excelエクスポートがピボットテーブル用に最適化されています。数字はテキストではなく数値としてエクスポートされるため、Excelの「緑色の三角形」エラーの頭痛の種を解消します。プロのヒント:「テンプレート」機能を使用してください。同じソースから500件のレポートがある場合、抽出ゾーンを一度定義すれば、コーヒーを飲みながらバッチPDF処理が残りを処理します。

高度なユースケース:助成金における複雑な財務OCRの管理
大学の生命線である助成金管理ですが、最も厄介なデータも生み出します。財務コンテキストでアカデミックデータExcelを扱う場合、単に名前を探しているのではなく、監査証跡を探しています。助成金レポートにはしばしば手書きの署名、ゴム印、重なり合ったテキストが含まれており、これらは標準的なソフトウェアを混乱させる可能性があるため、ここでは複雑な財務OCRが必要です。
最近、私たちは30年間のNIH助成金配分を分析している研究グループを支援しました。データは何千ものスキャンされたメモに閉じ込められていました。研究データ自動化を活用することで、総勘定元帳コードを抽出し、大学の内部支出記録と照合することができました。通常、すべての明細を手動で検証する必要がある照合プロセスは、80%自動化されました。OCRの信頼度が90%を下回った行のみがシステムによってフラグ付けされ、研究者はエッジケースに集中できるようになりました。このアカデミックデータExcelへのアプローチにより、最終的なデータセットが「監査準備完了」になります。これは、スプレッドシートのすべてのセルがソースPDFの元の座標にまで遡れるように、データの保管連鎖を構築することです。
研究データの信頼性とコンプライアンスの確保
アカデミックデータExcelの世界では、信頼性が最も重要です。データ抽出プロセスが「ブラックボックス」である場合、同僚はあなたの結果を再現できません。そのため、リサーチデータ自動化は透明でなければなりません。TabliSyncは、すべての抽出に対して完全な監査ログを提供します。また、GDPRおよびFERPA基準を遵守し、機密性の高い学生または参加者データがエンタープライズグレードの暗号化で処理されることを保証します。
さらに、出版のためにアカデミックデータExcelを処理する際には、FAIR原則(検索可能、アクセス可能、相互運用可能、再利用可能)を遵守する必要があります。手動でのデータ入力は、不透明で文書化されていない「修正」が発生しやすいため、FAIRの対極にあります。自動テーブル抽出を使用することで、再現可能で文書化されたパイプラインを作成できます。レビュー担当者が特定の数値をどのように得たか尋ねてきた場合、特定のTabliSyncテンプレートと生のソースファイルを指摘できます。このレベルの専門知識と権威が、インパクトの高い研究とそれ以外の研究を分けるものです。あなたは単なる研究者ではなく、データ管理者なのです。
最新の研究ワークフローにおけるWebhooksの役割
静的なファイルで止まっていてはなりません。アカデミックデータExcelの真の力は、それが生きたエコシステムの一部になったときに解き放たれます。ここでWebhooksが登場します。Webhookは本質的にデジタル宅配便のようなものです。TabliSyncがPDFのバッチ処理を完了した瞬間、それは別のソフトウェア(例えば、あなたの学部のERPシステムやカスタムPythonスクリプト)に「ping」を送信し、データをそれに運ぶことができます。
プロジェクトリーダーにとって、これは自動ダッシュボードを構築できることを意味します。チームが新しいフィールドレポートや実験結果をアップロードすると、アカデミックデータExcelマスターファイルがリアルタイムで更新されます。週次の「データダンプ」を待つ必要はもうありません。これは、最も洗練された研究データ自動化です。これにより、最も現在の情報に基づいて意思決定を行うことができるアジャイルリサーチが可能になります。総勘定元帳で実験機器のコストが急増した場合、手作業による入力が完了する3週間後ではなく、即座に確認できます。これがSaaSの利点です。静的なドキュメントから流動的なデータストリームへの移行です。
事例研究:大規模な縦断的社会学研究
「都市成長プロジェクト」を考えてみましょう。これは、10,000件以上の歴史的な国勢調査記録を含む、数十年間にわたる研究です。これらの記録はコンピューター用に作成されたものではありません。それらはマルチカラム、マルチページの代物です。チームは当初、「クラウドソーシング」による手作業での入力アプローチを試みましたが、その結果生成されたアカデミックデータExcelは、国勢調査ヘッダーの解釈の違いによりエラーだらけでした。
TabliSyncのバッチPDF処理に切り替えることで、単一の「信頼できる情報源」を確立しました。私たちは、1950年代スタイルのタイポグラフィを理解するカスタム抽出モデルを開発しました。その結果?人間が転写したものよりも40%正確なアカデミックデータExcelファイルが得られました。このプロジェクトは2,000時間以上の労力を節約し、研究範囲を2つの追加都市に拡大することを可能にしました。これは単に「時間を節約する」だけでなく、可能な研究の地平を広げることでした。データのコストが下がると、研究の価値が上がります。

「非標準」ドキュメントの課題を克服する
Academic Data Excelの最も難しい部分は、「非標準」のドキュメントです。ご存知の通り、表が15度の角度で傾いていたり、'合計'列にコーヒーの染みがあったりするものです。標準のOCRはここで失敗します。TabliSyncは、抽出が開始される前にドキュメントを「クリーニング」するために、ニューラルネットワークベースの画像復元を使用します。画像を傾き補正し、コントラストを強化し、デジタルノイズを除去します。
これは研究データ自動化にとって非常に重要です。なぜなら、学術アーカイブはめったに完璧な状態ではないからです。経済思想史プロジェクトのために複雑な金融OCRを扱っている場合、黄ばんで脆くなった紙を扱っています。当社の技術は、テキストを読み取る前に、まずドキュメントを物理的なオブジェクトとして扱い、そのジオメトリを再構築します。これにより、Academic Data Excelでページ途中で列がずれる「ドリフト」が発生しないことが保証されます。精度はオプションではありません。学術コミュニティにおける信頼の基盤です。
よくある質問
TabliSyncはAcademic Data Excelで複数ページの表をどのように処理しますか?
複数ページにまたがる表の処理は、当社の自動表抽出の中核機能です。各ページを独立して扱う基本的なスクレイパーとは異なり、TabliSyncはヘッダー永続化ロジックを使用します。最初のページで列ヘッダーを識別し、後続のページに移動する際にそれらを「記憶」します。これにより、システムは行をシームレスに連結し、単一の連続したAcademic Data Excelシートを作成できます。例えば、総勘定元帳レポートが50ページにわたる場合、TabliSyncは50個の断片化された表ではなく、1つの統合された表を生成し、照合プロセスの整合性を維持し、手動でのマージにかかる時間を節約します。
手書きのメモや注釈をExcelに処理できますか?
Academic Data Excelは主に構造化テキストに焦点を当てていますが、当社の複雑な財務OCRには専用のHTR(手書き文字認識)モジュールが含まれています。これは、図が余白に手書きされている可能性のあるアーカイブされた助成金やラボノートを扱う研究者にとって特に役立ちます。システムは特定の筆記体を認識するようにトレーニングでき、それをスプレッドシート内のデジタルセルに変換します。ただし、研究データ自動化の効率を最大限に高めるためには、手書き文字はタイプされたテキストよりも検証要件がわずかに高いため、プライマリデータセットではなく「補足データ」に使用することをお勧めします。
機密性の高い研究データのセキュリティプロトコルは何ですか?
セキュリティは、当社の研究データ自動化フレームワークに組み込まれています。Academic Data Excelには、機密性の高いPII(個人識別情報)または独自の総勘定元帳データが含まれることが多いことを理解しています。TabliSyncは、保存中のすべてのデータにAES-256暗号化を、転送中のデータにTLS 1.3を使用します。当社はSOC2 Type IIに準拠しており、データが特定の地理的境界(EUなど)内に留まることを要求する機関向けの「データレジデンシー」オプションを提供しています。また、バッチPDF処理フェーズ中に機密性の高い名前やIDを自動的に黒塗りできる赤塗り機能も提供しており、プライバシー法への準拠を保証します。
TabliSyncは英語以外の学術文書をサポートしていますか?
はい、当社の自動テーブル抽出エンジンは多言語対応です。中国語、日本語、アラビア語などの複雑なスクリプトを含む40以上の言語をサポートしています。これは、国際的なパートナーからの総勘定元帳データを照合する可能性がある、グローバルなAcademic Data Excelプロジェクトにとって不可欠です。システムは、抽出プロセス全体で文字エンコーディング(UTF-8)を維持し、特殊文字、アクセント記号、記号が、いわゆる「文字化け」や文字化けすることなく、最終的なExcelファイルに正しく表示されることを保証します。このレベルの専門知識により、国際的な研究は正確かつプロフェッショナルなものになります。
TabliSyncを既存の統計ツールと統合するにはどうすればよいですか?
最も効率的な方法は、当社のWebhookアーキテクチャを経由することです。Academic Data Excelの抽出が完了すると、TabliSyncはサーバーまたはZapierのようなサードパーティのインテグレーターにPOSTリクエストをトリガーできます。これにより、Stata、R、またはPython環境などのツールにデータを自動的に移動できます。技術的な知識があまりない方のために、Google Drive、Dropbox、OneDriveとの直接的なCloud Integrationsを提供しています。これにより、research data automationパイプラインが「シームレス」になります。データはPDFから分析準備完了フォルダに、手動で「ダウンロード」または「アップロード」をクリックする必要なく移動します。
TabliSyncは、太字や斜体のテキストのような複雑なセルの書式設定を処理できますか?
もちろんです。Academic Data Excelを生成する際、TabliSyncは元のPDFの「リッチテキスト」属性を保持するように設定できます。これは、太字の数字がStatistical Significanceを示している場合や、斜体が科学的命名法に使用されている場合に重要です。当社のautomated table extractionは、生の文字列をプルするだけでなく、セルのメタデータをキャプチャできます。これは、スプレッドシートが元のドキュメントの視覚的な手がかりをミラーリングできることを意味し、最終的に出力を監査する人間の研究者にとって、Reconciliationとレビュープロセスをより直感的にします。
PDFに非常に標準的でないテーブルレイアウトがある場合はどうなりますか?
ここでTabliSyncの「Zonal OCR」が真価を発揮します。automated table extraction AIが非常にクリエイティブまたは乱雑なレイアウトを自動的に検出できない場合は、「Extraction Zones」を手動で描画できます。列と行がどこにあるかを正確に定義すると、システムはそれをTemplateとして保存します。同じ形式の将来のドキュメントについては、batch PDF processingがカスタムマップに従います。これは、research data automationのパワーと人間の監視の精度を組み合わせ、最も「不可能」なAcademic Data Excelタスクでさえ、100%の構造的精度で完了することを保証します。
一度に処理できるファイルの数に制限はありますか?
当社のバッチPDF処理エンジンは、高スループットのために設計されています。大学全体の監査のために、50,000ページものバッチを処理した実績があります。このシステムはElastic Scalingを利用しており、キューが大きくなるにつれてコンピューティングパワーを増やします。ユーザーにとっては、Academic Data Excelファイルを1つ処理する場合でも1,000件処理する場合でも、ページあたりの待ち時間が驚くほど短いままであることを意味します。これは効率性の定義であり、研究の野心に反するのではなく、それに合わせて拡張するツールを提供し、General Ledgerが常に最新の状態に保たれるようにします。
教育機関向けの価格設定はどのようになっていますか?
高等教育機関向けの特別なSaaSティアを提供しています。Academic Data Excelプロジェクトは助成金で賄われることが多いことを理解しており、「従量課金制」モデルと、学部向けの年間の「無制限」ライセンスの両方を提供しています。この柔軟性により、研究者は助成金申請でコスト削減を考慮することができます。research data automationを自動化することで、管理オーバーヘッドを削減し、支出あたりの分析可能データ量を増やすことで、資金提供者に投資を最大限に活用していることを示すことができます。
TabliSyncの「Reconciliation」機能とは何ですか?
Reconciliationは、当社の高度な検証ツールです。抽出されたAcademic Data Excelデータを2番目のソースとクロスリファレンスすることができます。例えば、PDFからGeneral Ledgerデータを抽出する場合、TabliSyncは合計が既存のCSVファイルまたはデータベースエントリと一致するかどうかを自動的に確認できます。不一致がある場合、システムはレビューのために特定のセルをフラグ付けします。これはcomplex financial OCRの不可欠な部分であり、エラーに対する防御の第2層を提供し、研究が検証済みの確実なデータに基づいて構築されることを保証します。
研究の未来は自動化される
リサーチデータの自動化への移行は、もはや贅沢ではなく、インパクトの高い学術研究を目指す者にとって必須となっています。Academic Data Excelシートにデータを手入力するのに費やす1時間は、分析、統合、発見から奪われた1時間です。私たちは、自動テーブル抽出と複雑な金融OCRが、ラボの「静かなるヒーロー」として、信頼するデータが検証する理論と同じくらい正確であることを保証するためにバックグラウンドで機能する時代に突入しました。
TabliSyncを採用することで、単なるソフトウェアの購入以上のことを行っています。それは、研究方法論全体のアップグレードです。PDFがすべて障害となる「データ摩擦」の世界から、情報がソースからスプレッドシートへシームレスに移動する「データフロー」の世界へと移行しています。効率性とコスト削減は明らかですが、真の報酬は、データが標準化され、照合され、世界に見てもらえる準備ができているという安心感から得られる精神的な明晰さです。データ入力係になるのをやめ、訓練されたビジョナリー研究者になる時です。発見のスピードは、キーボードのスピードに制限されるべきではありません。
飛び込みましょう:今すぐAcademic Data Excelを自動化しましょう
データ、技術比較、ワークフローを見てきました。研究のボトルネックはあなたの才能ではなく、あなたのツールです。リサーチデータの自動化の実装を遅らせるたびに、手入力の真空に失われる1日が増えます。Academic Data Excelファイルが数週間ではなく数秒で生成されるとしたら、何を達成できるか想像してみてください。現在「大きすぎる」ために処理されずに放置されているバッチPDF処理タスクを考えてみてください。それらのプロジェクトは、今やあなたの手の届くところにあります。
TabliSync は、学術界の厳しさを理解している人々によって構築されました。総勘定元帳の1桁の誤りが数ヶ月の作業を無効にする可能性があることを私たちは知っています。だからこそ、私たちは精度、速度、そして照合を優先するツールを構築しました。古いワークフローによって研究が妨げられることのないようにしてください。以下のリンクをクリックして、無料トライアルを開始してください。自動テーブル抽出の力を直接体験し、5,000ページものデータを次の会議までに、きれいで整理されたExcelシートに変える方法をご覧ください。あなたの研究の未来は待っています。すでに時間を再獲得した何千人もの学術関係者に加わりましょう。今すぐTabliSyncで始め、データの混乱を研究の明確さに変えましょう。
アカデミックデータExcelを高速処理する方法とは?
アカデミックデータExcelを高速処理する方法についての要点と、TabliSyncがExcel作業をどう速くするか。
アカデミックデータExcelを高速処理する方法とは?
アカデミックデータExcelを高速処理する方法は実務的なExcelワークフロー、よくある落とし穴、自動化パターンを扱います。このTabliSyncガイドが概念、例、関連チュートリアルを示します。
TabliSyncはアカデミックデータExcelを高速処理する方法にどう役立ちますか?
スクリーンショットやPDFから表を抽出し、乱れたデータを整え、アカデミックデータExcelを高速処理する方法関連の反復タスクを自動化します。
アカデミックデータExcelを高速処理する方法はどこから始めればよいですか?
このページの概要から始め、下の関連記事でステップごとの手順とAIワークフローを確認してください。
すべての アカデミックデータExcel 記事(6)

2つの日付間の日数を計算する方法
このガイドでは、スプレッドシートソフトウェアを使用して2つの日付間の日数を計算するプロセスを順を追って説明します。この重要なスキルは、プロジェクト管理や財務報告など、さまざまなビジネスシナリオで役立ちます。日付計算のためにスプレッドシートを設定するための明確なステップバイステップのアプローチと、日付の違いを理解することが不可欠な一般的な状況を示す実践的な例を提供します。さらに、うるう年や書式設定の問題の処理方法など、正確性を確保するためのヒントも共有します。この記事の終わりまでに、自信を持って日付計算を効果的に実行し、TabliSyncがデータ整理を支援してさらに効率を高める方法を探ることができるようになります。

ExcelでIF関数とAND関数を組み合わせて使用する方法
この記事は、ExcelでIF関数とAND関数を組み合わせる方法をユーザーにガイドし、データ分析とレポート作成を改善するのに役立ちます。段階的な手順と実践的な例を通じて、読者はスプレッドシートスキルを向上させることができます。これらの関数を効果的に組み合わせて使用する方法を理解することで、ユーザーは正確なレポート作成とビジネス上の意思決定に不可欠な、より複雑な論理テストを作成できます。一般的なユースケースと、よくあるエラーを回避するためのヒントを探ります。会計士、財務チームメンバー、またはデータアナリストのいずれであっても、このガイドはExcelの習熟度を高め、ワークフローを効率化するために必要なツールを提供します。

Excelでパーセンテージを使用して円グラフを作成する方法
今日のデータ駆動型世界では、情報を効果的に可視化することがビジネスの成功に不可欠です。この記事では、Excelでパーセンテージデータを使用して円グラフを作成するための、明確で実践的なガイドを提供します。財務レポートを扱う会計士であっても、売上データを視覚的な形式に変換するアナリストであっても、円グラフは理解とプレゼンテーションを向上させることができます。説明されている手順に従ってデータを正確に反映する円グラフを作成し、明確さとインパクトを高めるためのカスタマイズのヒントを見つけてください。さらに、TabliSyncがこれらの視覚的表現のためにデータを準備するのにどのように役立つかを学び、プロセスをよりスムーズで効率的にします。この記事の終わりまでに、データを視覚的に提示するスキルを習得し、情報を効果的に伝え、正確な表現に基づいて情報に基づいた意思決定を行うことができるようになります。

Excelの改ページを削除する方法
Excelの改ページとは何か、なぜ重要なのかを理解し、改ページを削除する手順に沿った指示に従い、スプレッドシートで改ページを効果的に管理するための便利なヒントを学びましょう。

データ整合性のマスター:Excelでドロップダウンリストを作成する方法
標準化されたExcelデータ検証プロトコルを実装することで、手動データ入力エラーを99%削減します。 動的なドロップダウンリストと構造化テーブルの使用により、データクリーニング時間を90%削減します。 AI駆動のOCRとTabliSyncを活用して、非構造化物理データを検証済みExcelスキーマに即座に変換します。 複雑なデータセット向けの、スケーラブルで検索可能なドロップダウンアーキテクチャでスプレッドシートを将来にわたって活用します。

混乱をマスターする:データ損失なしでExcelの重複を削除する方法
効率向上:自動化されたワークフローを使用して、手動データクリーニング時間を90%以上削減します。 データ整合性:スキーマベースの重複排除に「検索と置換」から移行することで、0%の手動入力エラー率を達成します。 リスク軽減:非破壊的なPower Query環境を利用することで、偶発的な削除を100%防止します。 将来性:AI統合自動化により、受動的なクリーニングから能動的なデータ衛生へと移行します。
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す