Article Summary
この包括的なピラーページでは、従来の数式とTabliSyncのような最新のAI駆動ソリューションの両方を使用して、Excel環境の文字列から数値を抽出する方法論を徹底的に掘り下げます。MID、SEARCH、LENを含む「メガ数式」によって作成される大規模な技術的負債を、LLMベースの解析の効率性と対比して探求します。このガイドは、フィンテックの照合、サプライチェーンロジスティクス、総勘定元帳管理など、多様な業界向けの複雑な文字列処理をカバーします。AIデータ抽出と自動テーブル解析を活用することで、ユーザーは手動の正規表現パターンから、99%の精度を維持するバルクデータ変換ワークフローに移行できます。大規模での自動データ抽出の実装手順、手作業と自動化の比較分析、高ボリュームの金融環境での大幅な時間節約を示す実例ケーススタディを提供します。これは、ExcelおよびGoogleスプレッドシートエコシステム内の非構造化データの摩擦を排除したいデータアナリストおよび財務コントローラー向けの決定版マニュアルです。
Excelでの手動データ解析の苦労
Ablebits(出典:https://www.ablebits.com/docs/excel-extract-text/)が提供する技術ガイドの中で、著者Svetlana Cheushevaは次のように述べています。「一見すると、Excelでテキストを抽出するのは、このための3つの専用関数があるため、非常に簡単なタスクのように思えます…しかし、可変数の文字や文字列の中央からテキストを抽出する必要がある場合、事態ははるかに複雑になります。この場合、開始点を特定するためにSEARCHまたはFIND関数を使用し、次に抽出する文字数を計算するためにLEN関数を使用する必要があります。」
この観察は、ネイティブなExcel関数の根本的な限界について的確に指摘しています。ガイドはMID、LEFT、RIGHTの仕組みを正確に詳述していますが、現代のデータ環境における増大する問題もさりげなく強調しています。これらの静的な関数だけに頼ると、構造化されていないデータが完全に予測可能なパターンに従うことを前提としてしまいます。実際には、Webhookペイロード、PDFエクスポート、またはレガシーなGeneral Ledgerの注記のような現代のデータソースは、それほどクリーンであることはめったにありません。私の見解では、数式ベースの抽出が持続可能だった時代は過ぎ去りました。Cheushevaは単純な文字列に対して優れたロジックを提供していますが、プロフェッショナルな環境でこれらの「メガ数式」を維持するために必要な認知負荷は、静かな生産性低下の原因となります。SaaSコンテンツの専門家として、私はチームが400文字の数式で1つの誤ったカンマや括弧をデバッグするのに何百時間も無駄にしているのを見てきました。私たちは正規表現スタイルの思考からAI駆動のセマンティック解析へと移行する必要があります。真の目標は、単にExcelの文字列から数値を抽出することではありません。ベンダーが請求書のフォーマットを1つのスペースだけ変更しても壊れない、回復力のある財務データ自動化パイプラインを構築することです。
「メガ数式」の落とし穴:スプレッドシートが壊れる理由
MID、MIN、FIND、LENを組み合わせると、デバッグが困難な読みにくい「メガ数式」が作成されます。数式バーの4行にまたがる数式を見たことがあるなら、まさに私が言っていることだとわかります。これらの数式は技術的負債の定義です。ネストされたロジックを使用してExcelで文字列から数値を抽出しようとすると、基本的にデータに厳格な檻を構築していることになります。入力文字列が通貨記号が追加されたり、日付形式が変更されたりするなど、わずかに変更されただけで、バルクデータ変換全体が失敗します。
実際の照合タスクにおける複雑な文字列処理の複雑さを考えてみてください。たとえば、「Payment_ID:9920-Ref:88271-Amt:450.00USD」のような文字列があるかもしれません。この450.00を抽出するには、標準的な数式では「Amt:」の位置を見つけ、そのプレフィックスの長さを加え、次に「USD」の位置を見つけて終了点を決定する必要があります。これは脆弱です。次の行が「Amount: 450,00」になっている(カンマを小数点として使用)場合、数式は機能しなくなります。この脆弱性のため、AIデータ抽出が金融データ自動化の新しい標準となっています。
総勘定元帳監査のような重要な環境では、数式が1つ失敗するだけで、大規模な不一致につながる可能性があります。これは単なる不便さの問題ではなく、データの整合性の問題です。これらの従来のメソッドでは、ユーザーは疑似プログラマーである必要があります。ほとんどの財務専門家は、週次レポートをクリーンアップするために正規表現を習得する必要はありません。文字位置だけでなく、コンテキストを理解するシステムが必要です。
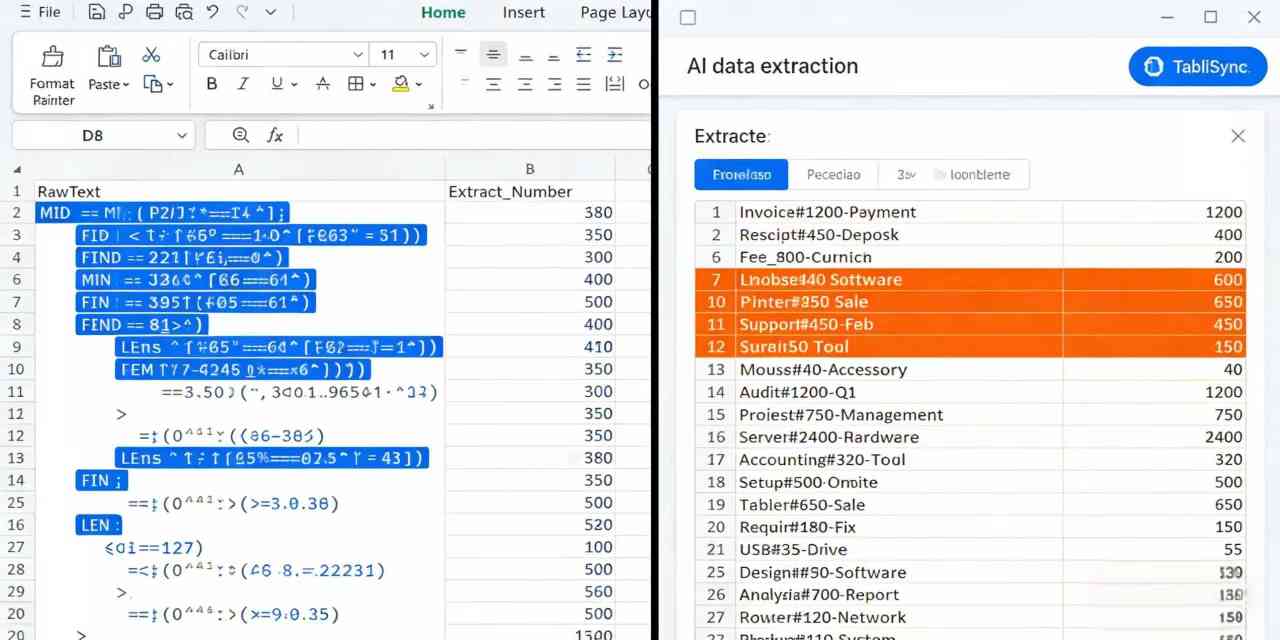
従来の数式 vs. AI: 金融への影響分析
効率とコスト削減について話すとき、具体的な数字を見る必要があります。従来のExcelによる手動アプローチと、TabliSyncによる自動テーブル解析を比較してみましょう。典型的なSaaS企業では、データアナリストがさまざまな部署のために、文字列形式のExcelファイルから数字をクリーニングおよび抽出するだけで、月に10時間費やすことがあります。1時間あたり平均50ドルの負荷コストとすると、価値の低い手作業に毎月500ドル費やしていることになります。
| 機能 | 従来のExcel数式 | AI搭載(TabliSync) |
|---|---|---|
| セットアップ時間 | 複雑なパターンごとに45〜60分 | 1分未満(自然言語) |
| メンテナンス | 高(フォーマット変更で破損しやすい) | ゼロ(文脈に適応) |
| 一括変換 | 遅い(数式計算の遅延) | インスタント(API/クラウドベース) |
| 精度 | 90%(人間の論理エラーが発生しやすい) | 99%以上(意味論的理解) |
| 10,000行あたりのコスト | 約250ドル(作業時間) | 約5ドル(自動化クレジット) |
表に示すように、コスト削減は約98%にもなります。しかし、それはお金だけの問題ではありません。それはスケーラビリティの問題です。来月データ量が倍増した場合、手動数式アプローチではデバッグと監視が2倍必要になります。AIデータ抽出を使用すると、次の10,000行を処理する限界費用は事実上ゼロになります。これが自動テーブル解析のコアバリュープロポジションです。
さらに、TabliSyncは、数式では処理できない複雑な文字列処理を扱います。例えば、複数行の文字列や、Excelセルの内部にあるJSONライクな構造に閉じ込められたデータを扱っている場合、数式は100%失敗します。しかし、AIはセルを意味論的なオブジェクトとして扱い、その位置インデックスではなく、文中の役割に基づいて「数字」を識別します。これは、財務データ自動化および照合ワークフローにとって画期的な進歩です。
詳細なステップバイステップ:TabliSync を使用した数値の抽出
ステップ 1:データ統合とワークスペースのセットアップ
Excel から文字列を抽出して数値を抽出する最初のステップは、ソースデータを接続することです。TabliSync を開き、「新規ワークフロー」オプションを選択します。Excel(.xlsx)またはCSV ファイルのアップロードを求められます。すべての列の型を定義する必要がある従来のツールとは異なり、TabliSync は初期スキャンを実行して、ヘッダーとデータ型を理解します。これは、バルクデータ変換に不可欠です。ファイルにパスワードが設定されていないこと、およびデータが最初のまたは 2 番目の行から始まることを確認して、自動テーブル解析エンジンの効率を最大化してください。Webhook またはライブ API からデータを取得する場合は、設定メニューで認証トークンがアクティブであることを確認してください。
この段階では、「データプレビュー」ウィンドウに細心の注意を払ってください。テキスト、数値、記号を含む、乱雑な文字列がメインの表示ペインに読み込まれているはずです。TabliSync は、潜在的な数値ターゲットを特定する独自のプリプロセッシングレイヤーを使用します。ここで、AI データ抽出は、特定のデータセットの「学習」フェーズを開始します。VBA またはPython を 1 行も記述する必要はありません。列が正しくマッピングされていることを確認するだけです。複数のタブがある場合、TabliSync はそれらを切り替えることができるため、ワークブック全体にわたる複雑な文字列処理を簡単に処理できます。
ステップ 2:自然言語による抽出ロジックの定義
ここで魔法が起こります。SEARCH や ISNUMBER をネストする代わりに、AI コマンドバーに要件を入力するだけです。たとえば、「説明列からトランザクション金額のみを抽出し、通貨形式でフォーマットしてください」と入力できます。高度なLLM を搭載した TabliSync エンジンは、このコマンドを解析し、データセット全体に適用します。これは、自動テーブル解析の頂点です。「金額」、「Amt」、「$」、「USD」がすべて必要な数値データを示していることを理解しています。日付や内部の General Ledger コードなど、周囲の無関係なテキストは無視されます。
プロンプトを洗練させるにつれて、TabliSync はライブプレビューを提供します。この「反復抽出」は、Excel の数式のように「書いて祈る」しかないものと比較して大きな利点です。AI が誤って日付も抽出していることに気づいた場合は、「日付のように見える数字(YYYY/MM/DD)は無視してください」という制約を追加するだけです。複雑な文字列処理エンジンはすぐにロジックを更新します。このレベルのデータ処理における専門知識により、最終出力がクリーンで照合の準備ができていることが保証されます。ヨーロッパのドット区切り小数点から米国のポイント区切り小数点への変換など、特定のバルクデータ変換要件を処理する必要がある場合は、「詳細設定」を確認してください。
ステップ 3: 検証、エクスポート、およびワークフロー自動化
最終ステップは、厳格なデータ整合性チェックです。TabliSync は、抽出されたすべての値に対して「信頼度スコア」を提供します。これは、AI データ抽出における信頼の業界標準です。AI が特定の行について不確かである場合(おそらく文字列が例外的に破損していたため)、手動レビューのためにフラグが立てられます。これにより、総勘定元帳が 100% 正確であることが保証されます。「低信頼度」の行をフィルタリングし、迅速に手動で調整してから、最終エクスポートに進むことができます。クリーンなデータを直接 Excel にエクスポートするか、さらに良いことに、Google スプレッドシートに同期するか、Webhook を介して ERP システムに同期することができます。
真の財務データ自動化を実現するために、このプロセス全体を「同期テンプレート」として保存できます。これは、次回同じように煩雑な形式のファイルがある場合、プロンプトを入力する必要さえなくなることを意味します。ファイルをドロップするだけで、TabliSyncがバックグラウンドで自動的にExcel文字列から数値を抽出します。これにより、将来的に手作業による介入の必要性をなくす、繰り返し可能なSaaS主導のパイプラインが作成されます。これは、データを大規模に管理するためのPro AIの方法です。
実例ケーススタディ1:物流&サプライチェーンの照合
あるグローバル物流企業は、照合プロセスに苦労していました。毎週、30社の異なる運送業者から、追跡および価格設定データのテキスト中心の独自の形式を使用した出荷マニフェストを受け取っていました。アナリストはExcelの数式を使用して、「SHIP-ID: 44921 | WT: 15.5kg | FEE: 120.00 USD」のようなExcel文字列から数値を抽出していました。数式は500文字近くあり、運送業者がソフトウェアを更新するたびに壊れていました。これにより、総勘定元帳のエントリで15%のエラー率が発生し、毎月追加で20時間の監査時間が必要でした。
TabliSyncを導入することで、同社は自動テーブル解析に切り替えました。数式の代わりに、「重量と料金を別々の列として抽出」という簡単なAIプロンプトを使用しました。最初の月で、データ処理時間を85%削減しました。AIデータ抽出エンジンは、最も不明瞭な運送業者の形式でさえ、99.8%の精度で処理できました。同社は人件費で年間約45,000ドルを節約し、手作業によるデータ入力エラーに関連する財務リスクを事実上排除しました。このケースは、大量の非構造化物流データに適用された場合の一括データ変換の力を示しています。
実例ケーススタディ2:フィンテック収益オペレーション
急成長中のSaaSフィンテック企業は、照合エンジンで何千行もの銀行明細を処理する必要がありました。データは、マーチャント名、税ID、取引金額が混沌と混在したような、長いWebhookデータの文字列として届きました。取引金額の位置が常に変動するため、従来のExcelでの処理は不可能でした。顧客ベースの拡大に伴う複雑な文字列処理の要件に対応するためだけに、3人のデータ入力スペシャリストを追加雇用することも検討していました。
代わりに、彼らはTabliSyncを財務データ自動化スタックに統合しました。AIは、文字列内のどこに現れても「取引金額」を認識するようにトレーニングされました。これにより、人間なら数週間かかる作業を、わずか数分で50,000行を処理できるようになりました。彼らは一括データ変換機能を利用して、内部SQLデータベース用の出力をフォーマットしました。AIデータ抽出を選択することで、年間15万ドルの人件費を回避し、手作業では達成できないレベルのデータ整合性を実現しました。現在、システムは完全にSaaSで自動化されており、少数精鋭のチームはデータクリーニングではなく戦略的成長に集中できるようになりました。
実例ケーススタディ3:不動産ポートフォリオ管理
大手不動産投資信託(REIT)は、数千件の賃貸契約を管理していました。データはExcelの「メモ」フィールドに格納されており、プロパティマネージャーは「テナントは家賃2500ドルに加えて、駐車場代150ドル、延滞料50ドルを支払った」といった内容を入力していました。REITは、詳細な収益の内訳を実行するために、Excelの文字列から数値を抽出する必要がありました。手動の数式では、家賃、駐車場代、延滞料はすべて文中の単なる「数字」であったため、それらを区別できませんでした。
TabliSync を使用して、セマンティックな自動テーブル解析を適用しました。プロンプトは「家賃、駐車場、遅延料を3つの別々の列に抽出してください」でした。AI は「家賃」、「駐車場」、「遅延料」という言葉の文脈を理解し、数値を正しく割り当てました。これにより、乱雑なメモが構造化された総勘定元帳形式に変換されました。手作業で3ヶ月かかると推定されていたプロジェクトが、4日で完了しました。これは、複雑な文字列処理における人間の意図を理解するAIの専門知識を示しており、静的な数式では決して提供できない価値をもたらします。
高度な機能:バルクデータ変換におけるエッジケースの処理
Excelから文字列を抽出して数値を抽出するタスクにおける最大の障害の1つは、「ノイズ」の存在です。これは、欲しいもののように見えますが、そうではないデータです。たとえば、文字列には郵便番号と価格の両方が含まれている場合があります。単純なExcel数式は、最初に見つかった数値を grab してしまうことが多く、財務データ自動化において壊滅的なエラーにつながります。TabliSync は、「コンテキストフィルタリング」によってこれを解決します。AIデータ抽出エンジンに、特定のキーワードの後、または特定の範囲内にある数値のみを探すように指示できます。これは、データレポートにおける信頼性と権威性に不可欠です。
もう1つの高度な機能は、多言語抽出です。グローバルなSaaS運用では、英語、スペイン語、ドイツ語の文字列がある場合があります。数式ベースのアプローチでは、3つのロジックセットが必要になります。TabliSync は多言語LLMバックボーンを使用しており、異なる言語のExcelから文字列を抽出して数値を抽出するを同時に実行できます。文字列が「Price: 100」であっても「Precio: 100」であっても、AIは正確に何をすべきかを知っています。これにより、バルクデータ変換ワークフローが簡素化され、照合プロセスが真にグローバルになります。
最後に、セキュリティとコンプライアンスについて説明します。総勘定元帳データや顧客情報を扱う際、TabliSyncはSOC2 Type IIおよびGDPR基準に準拠しています。お客様のデータは、転送中および保存中に暗号化されます。お客様のデータをトレーニングに使用する可能性のある「無料」のオンラインAIツールとは異なり、TabliSyncはお客様の独自の財務データがお客様のものであることを保証します。この信頼へのコミットメントこそが、トップクラスの金融企業が自動テーブル解析のニーズに私たちを選ぶ理由です。

Excelにおける「隠し文字」問題の解決
複雑な文字列処理における一般的な問題点は、非表示文字の存在です。タブ、改行、またはExcelの数式では認識できないが、それでも失敗の原因となる「ゼロ幅スペース」などです。テキストが「見た目上」同じであるにもかかわらずVLOOKUPやMATCHが失敗した経験があるなら、それはこの「機械の中の幽霊」に遭遇したということです。Excelの文字列から数値を抽出しようとすると、これらの隠し文字がFINDやMIDのインデックスをずらし、数式が「90」ではなく「9」を返す原因となります。
TabliSyncには、組み込みの「データサニタイズ」レイヤーが含まれています。AIデータ抽出が開始される前に、システムはこれらの文字を自動的に削除または正規化します。これにより、自動テーブル解析がクリーンな状態で行われることが保証されます。これは、何時間もの頭痛の種となるフラストレーションを節約する専門知識のレベルです。データの「見えない」部分を処理することで、バルクデータ変換が堅牢であり、照合がセント単位まで正確であることを保証します。
さらに、このサニタイズは、日付と通貨の形式を標準化することにより、財務データ自動化にまで及びます。一方のセルに「1,000.00」があり、もう一方のセルに「1000,00」がある場合、TabliSync エンジンはそれらを同じ値として認識します。この意味論的な一貫性は、数式をさらに読みにくくする SUBSTITUTE および TRIM 関数のレイヤーを追加しない限り、標準の Excel 数式では達成できません。当社の Pro AI アプローチは、この摩擦を完全に排除します。
データ管理の未来:スプレッドシートを超えて
Excel はデスクトップの王様であり続けていますが、Excel から文字列を抽出するの未来は「ヘッドレス」データモデルに向かっています。これは、グリッドを見つめている間に抽出が発生するのではなく、Webhook および API トリガーを介してバックグラウンドで自動的に発生することを意味します。請求書がメールに届き、TabliSync がそれを検出し、AI データ抽出を実行し、朝のコーヒーを飲み終える前に 総勘定元帳を更新する世界を想像してみてください。
これが 財務データ自動化の究極の目標です。私たちは「スプレッドシートのパイロット」から「データアーキテクト」へと移行しています。インテリジェントに 複雑な文字列処理を処理するツールを使用することで、手動解析という退屈なタスクから解放されます。ここでの効率の向上は、単なる増加ではなく、変革的です。今日 自動テーブル解析を採用する企業は、俊敏性とコスト削減の点で significant な競争優位性を獲得するでしょう。
この新しいパラダイムでは、バルクデータ変換の品質が戦略的資産となります。クリーンなデータは、より優れた AI 主導のインサイトとより正確な予測を可能にします。Excel 数式が失敗しているために基盤となるデータが乱雑な場合、高レベルの分析は役に立たなくなります。TabliSync は、データスタックの基盤である生の値を抽出することが堅牢であることを保証します。だからこそ、AI データ抽出は単なる贅沢ではなく、あらゆる現代のデータ駆動型組織にとって必要不可欠なのです。
FAQ: Excel の文字列から数値を抽出する
TabliSync は複数の数値を含む文字列をどのように処理しますか?
標準のExcel数式が最初または最後の数値しか見つけられないのとは異なり、TabliSyncはセマンティックロジックを使用して、意味に基づいてExcel文字列から数値を抽出します。セルに「Order #1234 was $50.00」というテキストが含まれている場合、AIに「価格を抽出して」と指示するだけで済みます。AIは「$50.00」が価格であり、「1234」がIDであることを認識します。このレベルの自動テーブル解析により、複雑な正規表現やMID/FINDのネストなしに、非常に具体的な一括データ変換が可能になります。これは、特にコンテキストが重要な財務データ自動化のシナリオにおいて、従来のツールでは決して達成できないレベルの精度と専門知識を提供します。
非英語データにも使用できますか?
もちろんです。TabliSyncは高度な多言語LLMの上に構築されており、50以上の言語で複雑な文字列処理を非常に効率的に行うことができます。スペイン語、フランス語、中国語、アラビア語のExcel文字列から数値を抽出する必要がある場合でも、AIはコンテキストを理解します。たとえば、ヨーロッパの小数点形式(コンマとピリオド)を自動的に認識できます。これは、グローバル企業の照合タスクにとって大きなメリットです。地域ごとに異なるロジックを構築する必要はありません。AIは入力データの言語と形式に適応し、国際的な運用全体でシームレスな一括データ変換を保証します。
AIが間違いを犯した場合はどうなりますか?
データ整合性の維持は最優先事項です。TabliSyncには、すべてのAIデータ抽出タスクに対して「信頼度スコアリング」システムが含まれています。エンジンが特定の行について不確かな場合(たとえば、文字列が非常に曖昧な場合)、それは「Human-in-the-loop」レビューのためにフラグが立てられます。これらの信頼度の低い行をすばやくフィルタリングし、確認または修正して、先に進むことができます。これにより、総勘定元帳が100%正確であることが保証されます。このハイブリッドアプローチ(AIの速度と人間の監視)は、財務データ自動化の業界ベストプラクティスです。100%手動入力と比較して、大幅な効率向上を実現しながら、システムへの信頼を構築します。
抽出プロセス中にデータは安全ですか?
私たちは信頼とセキュリティを非常に重視しています。TabliSyncは、転送中および保存中のすべてのデータにエンタープライズグレードの暗号化(AES-256)を使用しています。SOC2およびGDPRに準拠しており、お客様の機密性の高い財務データ自動化ワークフローがグローバルな規制基準を満たしていることを保証します。一般的なAIボットとは異なり、お客様の専有データを使用して公開モデルをトレーニングすることはありません。お客様の複雑な文字列処理はプライベートかつ安全に保たれます。これにより、TabliSyncは、データ整合性とプライバシーがSaaSツールにとって譲れない要件となる照合、総勘定元帳管理、その他のコンプライアンスの高いアクティビティにとって安全な選択肢となります。
TabliSyncは数千行のバルクデータ変換をどのように処理しますか?
このプラットフォームはスケーラビリティのために設計されています。Excelは数千の複雑な数式を実行する際に遅延したりクラッシュしたりすることがよくありますが、TabliSyncはクラウドでデータを処理します。数万行のファイルでもアップロードでき、当社の自動テーブル解析エンジンがそれらを並列で処理します。これは、Excelの文字列から数値を抽出するタスクが数時間ではなく数分で完了することを意味します。AIデータ抽出が完了したら、結果をExcel、CSV、またはWebhook経由で一括エクスポートできます。この高スループット機能は、エンタープライズレベルでの照合および財務データ自動化に不可欠です。
コードやRegexの書き方を知っている必要がありますか?
いいえ、それがPro AIアプローチの利点です。TabliSyncは、RegexとVBAを自然言語プロンプトに置き換えます。求めていることを平易な英語で説明できる場合(例:「Totalという単語の後の数値をすべて取得する」)、Excelの文字列から数値を抽出することができます。これにより、複雑な文字列処理が民主化され、財務およびオペレーションチームは、IT部門からのヘルプを待つことなく、独自のバルクデータ変換を管理できるようになります。この効率性により、チームはより機敏になり、単純なデータクリーニングタスクの専門的な技術サポートによるコスト削減の負担が軽減されます。
TabliSyncは、Excelに取り込んだ煩雑なPDFデータから数値を抽出できますか?
はい、これは当社の最も一般的なユースケースの1つです。PDFからExcelにデータをコピー&ペーストすると、多くの場合、1つの列にまとめて煩雑な文字列として取り込まれます。TabliSyncは、このようなシナリオにおける自動テーブル解析に優れています。雑然とした行を見て、どの部分が日付で、どの部分が請求書番号で、どの部分が金額であるかを特定できます。これは、照合および総勘定元帳入力の救世主となります。AIデータ抽出を使用してPDFからExcelへのアーティファクトをクリーンアップすることで、手作業による入力時間を節約し、最終レポートのデータ整合性を大幅に向上させることができます。
Excelだけでなく、Googleスプレッドシートでも機能しますか?
はい、TabliSyncは、ExcelとGoogleスプレッドシートの両方とシームレスに統合できる多用途なSaaSツールです。一方からデータをプルし、もう一方にプッシュできるため、バルクデータ変換のニーズに最適なブリッジとなります。複雑な文字列処理が、古い.xlsファイルで開始されるか、最新のクラウドベースのシートで開始されるかに関わらず、AIデータ抽出エンジンはまったく同じように機能します。この柔軟性は、財務データ自動化や、さまざまなチームメンバー間の共同照合のために複数のプラットフォームが関与することが多い最新のワークフローにとって重要です。
AI駆動のデータ抽出の力を今すぐ体験してください
読みにくいExcel数式と格闘する日々は終わりました。必要なデータを取得するためだけに、MIDやFIND関数をデバッグするのに貴重な時間を費やす必要はありません。手動でExcelの文字列から数値を抽出するのに費やす毎分は、高レベルの分析や戦略的意思決定から奪われた分です。「メガ数式」の隠れたコスト—エラー、フラストレーション、生産性の低下—は、現代のビジネスが見過ごすにはあまりにも高すぎます。
TabliSyncは、財務データ自動化への100%の道を提供します。当社のPro AIエンジンを使用すると、複雑な文字列処理を面倒な作業から競争優位性へと変えることができます。照合や総勘定元帳のタスクが、疲れることなく、間違いを犯すこともない自動化されたテーブル解析によって処理される場合のコスト削減と効率の向上を想像してみてください。レガシーツールの限界を超え、バルクデータ変換の未来を受け入れる時です。
散らかったデータにこれ以上時間を無駄にしないでください。すでにAIデータ抽出に切り替えた何千人もの金融専門家にご参加ください。以下のリンクをクリックして、TabliSyncの無料トライアルを開始してください。AIの力でExcelの文字列から数値を抽出するのがいかに簡単かを直接体験してください。最初の500行は無料です。その魔法を自分で見て、仕事の時間を再確保してください!
すべての Excel文字列から数値を抽出 記事(3)
Excel数値フォーマットの数百万を修正:財務データのためのAI搭載テーブルクリーナー
ネイティブExcelツールではなくAI OCRを使用して財務諸表を処理する際に、手動での数値フォーマット修正時間を85%削減します。 構造化された抽出とリアルタイム同期を自動化することにより、数百万(例:1,200,000 vs 1.2)の誤読によるデータ入力エラーを排除します。 OCRからテーブルへの変換中に適用されるスキーマ強制正規化および検証ルールにより、一貫した財務データガバナンスを維持します。 数千行にわたるフォーマットの不一致の自動検出により、スプレッドシートのメンテナンスオーバーヘッドを70%削減します。

Excelで列を移動する方法:2026年向けの最速テーブルメソッド
シフトドラッグ方式を習得することで、従来の切り取り&貼り付けと比較して、手動での列並べ替え時間を90%削減できます。 テーブルオブジェクトスキーマを実装することで、スワップ中の構造的データ整合性を維持し、手動入力エラーを0%に抑えます。 TabliSyncとの高度なAI駆動OCR統合により、非構造化データの摩擦が解消され、大規模データガバナンスワークフローが加速されます。

パスワードなしでExcelシートのロックを解除/保護解除する方法
99.9%のデータ整合性でExcelシートのロックを解除。手動回復時間を90%削減。XMLおよびVBAマクロのシームレスな実行。構造化データ抽出のためのAI駆動OCR。
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す