Article Summary
エグゼクティブサマリー:PDFはドキュメント共有のグローバルスタンダードですが、データ分析においてはしばしばデジタル上の「デッドエンド」となります。PDFからExcelへの変換に関するこの決定版2026年ガイドでは、基本的なデータ抽出を超えて、インテリジェントデータ再構築の領域へと進みます。ニューラルグリッドマッピングとセマンティックヘッダー識別が、アメリカの企業が財務諸表、ロジスティクス明細書、監査レポートを処理する方法にどのように革命をもたらしているかを掘り下げます。このピラーページは、「データスープ」問題の解決、自動APIパイプラインの実装、HIPAA/SOC2コンプライアンスの確保について深く掘り下げます。長年の銀行取引明細書を照合するCPAであれ、データワークフローをスケーリングする開発者であれ、このリソースは99%の抽出精度と数式対応の結果を得るためのロードマップとなります。
現代の企業環境において、PDFは祝福であると同時に呪いでもあります。文書共有のグローバルスタンダードでありながら、データ分析にとっては「デジタルな行き止まり」として機能します。500ページに及ぶ銀行取引明細書を扱う監査担当者であれ、数千件の請求書を処理するロジスティクスマネージャーであれ、シームレスなPDFからExcelへの変換を実行できる能力は、オペレーションの俊敏性と管理上の行き詰まりを分けるものです。
はじめに:なぜPDFからExcelへの変換がデータ自動化における最も重要な連携なのか
毎年、グローバルサプライチェーン、金融機関、法律事務所全体で数兆ものPDF文書が生成されています。しかし、最近の業界調査によると、オフィスプロフェッショナルの約60%が、これらの静的ファイルからスプレッドシートへ手動でデータを再入力するために週に最大10時間を費やしています。これは単なる人的能力の浪費ではなく、データ整合性にとって重大なリスク要因です。
2026年にアメリカで事業を展開する企業にとって、手動入力はもはや実行可能ではありません。AI主導の分析の台頭により、競合他社は自動化されたPDFからExcelへの変換ワークフローを使用して、キャッシュフロー、在庫、プロジェクトコストに関するリアルタイムの洞察を得ている可能性が高いです。このガイドは、このテクノロジーを習得するための決定的なロードマップを提供します。「単純な抽出」を超えて、インテリジェントデータ再構築の領域へと進みます。
---
第1章:「PDFからデータへ」のギャップを理解する
適切なツールを選択するには、まず標準的なソフトウェアでPDFからExcelへの変換がなぜこれほど困難であるかを理解する必要があります。PDFは、*データ構造*ではなく、*視覚的なレイアウト*を保持するように設計されています。PDFの内部には、「列」や「行」はなく、文字が表示されるべき座標のみが白い背景上に存在します。
「データスープ」問題
従来のコンバーターは、テーブルを長いテキスト文字列として扱うことがよくあります。それをExcelに貼り付けると、列が混在し、ヘッダーが消え、小数点以下の位置がずれます。これにより、いわゆる「データスープ」が生まれます。金融の専門家にとって、小数点以下のずれは単なるタイプミスではなく、数百万ドル規模のコンプライアンスリスクとなります。
スキャンされたPDF vs. ネイティブPDF
アメリカのユーザーにとって重要な区別は、ネイティブPDF(WordやQuickBooksなどのソフトウェアから直接生成されたもの)とスキャン済みPDF(紙の文書の写真)の違いです。
- ネイティブPDF:基盤となるコードのインテリジェントな解析が必要です。
- スキャン済みPDF:ピクセルを「見て」解釈するには、高度な光学文字認識(OCR)が必要です。
TabliSyncは、両方の形式に統一されたニューラルテーブル再構築(NTR)エンジンを適用することでこのギャップを埋め、ソースに関係なく一貫した出力を保証します。
---
第2章:TabliSyncエンジン—データの再構築方法
当社のテクノロジーは単なる「コピー&ペースト」ではありません。洗練されたAIパイプラインを使用して、Excelの出力が100%監査準備完了であることを保証します。
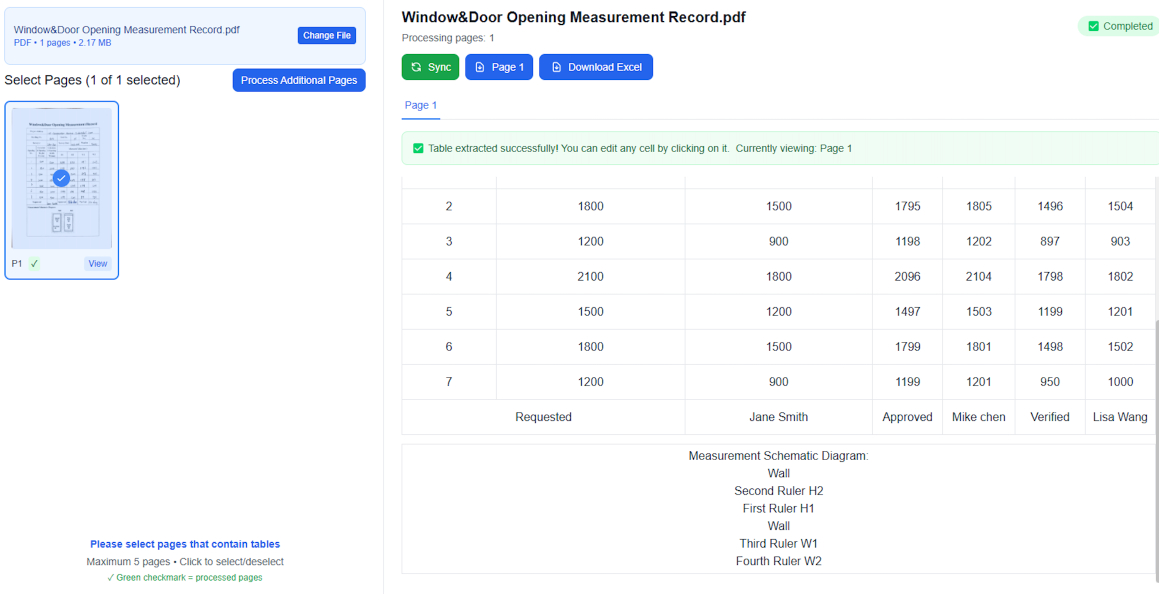
図1:TabliSyncのAIは、複雑なPDF明細書の構造グリッドを識別します。
1. ニューラルグリッドマッピング
当社のAIは、まずテキストを探すのではなく、空間論理を探します。テーブルの不可視の境界を識別します。座標ベースのシステムを使用することで、TabliSyncは、テーブルに「セル結合」や「境界線のない列」があっても、データが常に正しいExcelセル(例:A1、B2)に配置されることを保証します。
2. セマンティックヘッダー識別
PDFからExcelへの変換における最大の課題の1つは、ヘッダーが失われることです。TabliSyncのNLP(自然言語処理)レイヤーは、「数量」、「金額」、「SKU」が単なるデータではなく、記述子であることを理解しています。当社のエンジンはこれらのヘッダーをExcelシートの上部に自動的に固定し、即時のフィルタリングと並べ替えを可能にします。
3. 精密な小数点と通貨の配置
米国金融セクターでは、フォーマットが重要です。当社のエンジンは、数千もの金融レイアウトのバリエーションでトレーニングされています。通貨記号($、€、£)を認識し、数値がExcelで「テキスト」ではなく「数値」形式でエクスポートされるようにするため、クリーンアップなしで数式(SUM、VLOOKUP)の作成をすぐに開始できます。
---
第4章:ユースケース—PDFからExcelへの変換がアメリカの産業を強化する場所
高精度変換の需要は至る所にありますが、この自動化の主な受益者として際立っている3つのセクターがあります。
1. 金融監査および税務準備
公認会計士や監査担当者は、数十年前の「アーカイブスキャン」を扱います。これらを手動で照合することは、請求可能な時間の悪夢です。
- ワークフロー:12ヶ月のスキャンされた銀行取引明細書をアップロード → PDFからExcelへ → 即時ピボットテーブル分析。
- 結果:監査サイクルは70%短縮され、100%のデータカバレッジにより不正検出が向上します。
2. サプライチェーンおよびロジスティクス
ロジスティクス企業は、数百の異なるベンダーからの「船荷証券」および「梱包明細書」を処理します。各ベンダーは異なるレイアウトを使用しています。
- イノベーション:TabliSyncのテンプレートフリーOCRにより、サプライヤーごとにカスタムルールを作成する必要がなくなります。AIはオンザフライでレイアウトを学習します。
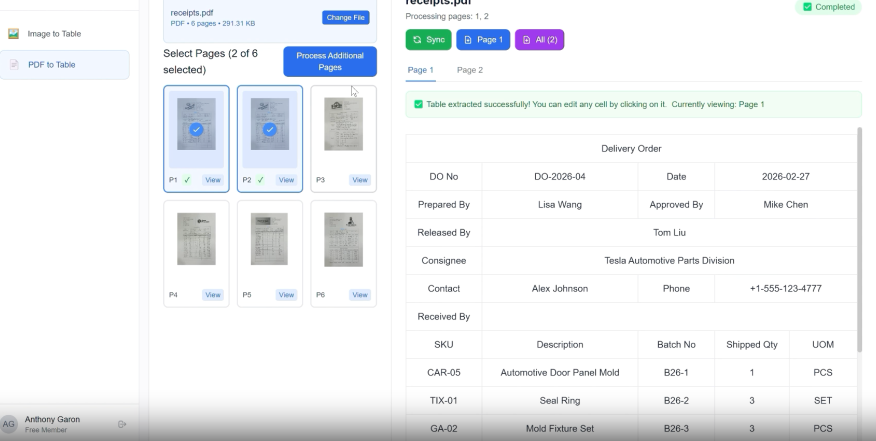
図2:混沌としたロジスティクス文書を構造化データに変換します。
第3章:専門業界アプリケーション—PDFデータを実行可能な洞察に変える
基本的なPDFからExcelへのコンバーターは、1ページのドキュメントには十分かもしれませんが、エンタープライズレベルの課題には、特定の業界規制やワークフローに合わせて調整された専門的なロジックが必要です。
1. 建設および土木工学:「紙の記録」の管理
アメリカの建設業界では、「Submittal」および「RFI(Request for Information)」プロセスにより、毎年数千ものPDFが生成されます。見積もり担当者は、操作が困難な大判PDF形式の「Quantity Takeoff」シートや「Bill of Materials(BOM)」を受け取ることがよくあります。
- 課題:24x36インチのブルーインプリントPDFからExcelに表をコピーしようとすると、通常は断片化されたデータになります。
- TabliSyncのソリューション:当社のエンジンは「Large-Format Parsing」を使用して、材料の説明と数量の関係を失うことなく、特大ドキュメントから表形式のデータを抽出します。
2. ヘルスケア管理:保険請求と患者記録
米国の医療提供者は、PDFで提供される給付明細書(EOB)フォームや検査レポートに埋もれています。
- コンプライアンス第一:当社の「PDF to Excel」ワークフローは、HIPAA基準を念頭に設計されており、請求コード(ICD-10)とコストの内訳を抽出すると同時に、厳格なデータ主権を維持できます。
- 精度が重要:ヘルスケアでは、「7」が「1」と読み取られると、請求の却につながる可能性があります。TabliSyncの「Neural Validation」レイヤーは、抽出されたデータを相互参照して、合計が常に一致することを保証します。
---
第4章:開発者のブループリント—APIによるPDFからExcelへのスケーリング
最新のSaaS企業やエンタープライズIT部門にとって、手動アップロードはボトルネックです。「PDF to Excel」の未来は、プログラムによる統合にあります。TabliSyncの「RESTful API」は、データがシステム間でシームレスに流れる必要がある高ボリューム環境向けに設計されています。
1. 自動データパイプラインの構築
毎月5,000件の請求書がメールで会社に届くと想像してみてください。開発者はTabliSync APIを使用して「ゼロタッチ」ワークフローを作成できます。
- 取り込み: S3バケットに新しいPDFが配置されるたびに、AWS Lambda関数がトリガーされます。
- 処理: PDFはTabliSyncのPDFからExcel APIに送信されます。
- マッピング: JSONまたはXLSXの出力は、SQLデータベースまたはERP(SAPやNetSuiteなど)に自動的にマッピングされます。
2. 開発者がTabliSyncを好む理由
- 高同時実行性: 当社のインフラストラクチャは水平方向にスケーリングするため、税務シーズンなどのピーク時には数百件のPDFからExcelリクエストを同時に処理できます。
- Webhook通知: 定期的なポーリングは不要です。データが準備できた時点でAPIがシステムに通知します。
- カスタムロジックの挿入: APIを使用して、「クリーニングルール」(例:空白の自動削除や日付のMM/DD/YYYY形式への変換)を定義してから、データをExcelファイルに渡すことができます。
---
第5章:自動化のROI — 「無料」ツールがより高くつく理由
多くのユーザーは「無料のPDFからExcelコンバーター」を検索することから始めます。しかし、ビジネスにとって「無料」は、セキュリティリスク、データ制限、精度の低さといった隠れた代償を伴うことがよくあります。
「クリーンアップ」税
無料ツールが90%の精度率である場合でも、エラーを手動で修正するために時間の10%を費やす必要があります。
計算:
- 手入力: 60分/ドキュメント
- 低品質OCR: 15分のクリーンアップ/ドキュメント
- TabliSync AI: 1分未満の検証/ドキュメント
時給30ドルの従業員の場合、TabliSyncは文書あたり約25ドルの人件費を節約できます。これを数千のファイルに拡大すると、ROIは四半期あたり数万ドルになります。
セキュリティと知的財産
無料のオンラインツールは、モデルを「トレーニング」するため、またはさらに悪いことに、メタデータを販売するためにデータを保存することがよくあります。アメリカの企業にとって、これはコンプライアンスの悪夢です。TabliSyncは、エンタープライズクライアントに「ストレージなし」保証を提供します。製造業のPDFにある独自の処方箋であろうと、機密の法的契約であろうと、あなたの知的財産はあなたのものであり、あなただけのものであることに変わりはありません。

図3:AI駆動型自動化による大規模な効率向上を可視化。
---
第6章:高度なフォーマット—データを「数式対応」にする
PDFからExcelへのツールに関する一般的な苦情は、結果のデータが「死んでいる」ということです。数字は見えますが、データがテキストとしてフォーマットされているため、=SUM()関数を実行できません。
自動型検出
TabliSyncのエンジンは、抽出中にデータ型指定を実行します。次のものを識別します。
- 整数と小数:数値セルとして抽出され、即座に計算できます。
- 日付文字列:Excelフレンドリーな日付形式に標準化されます。
- ブール値:PDFフォームの「はい/いいえ」または「支払い済み/未払い」チェックボックスを識別します。
「数式対応」ファイルを配信することで、チームがExcelでVALUE()またはTRIM()関数を実行する必要がなくなり、分析フェーズに直接移行できます。
第7章:セキュリティ、プライバシー、および連邦コンプライアンス
米国では、データ主権とプライバシーは単なる運用上の好みではなく、規制された要件です。機密性の高い顧客情報、財務記録、または知的財産を含むPDFからExcelへの変換を実行する場合、データが負債にならないようにする必要があります。
1. エンタープライズグレードの暗号化
TabliSyncは、保存時にはAES-256ビット暗号化、転送時にはTLS 1.2+を採用しています。これにより、データパケットが傍受されたとしても、読み取ることができなくなります。米国の政府機関や防衛請負業者にとって、このレベルのセキュリティは、すべてのドキュメント処理の基準となります。
2. HIPAAおよびSOC2タイプIIへの準拠
ヘルスケアおよび金融セクター向けに、特別な環境を提供しています。
- HIPAA:医療機関向けに事業提携契約(BAA)を提供し、医療PDF内のPII(個人識別情報)が最高機密で処理されることを保証します。
- SOC2準拠:当社のシステムは、セキュリティ、可用性、および処理の整合性を検証するために、厳格な第三者監査を受けています。
3. 「ゼロ保持」保証
多くの「無料」のPDFからExcelへの変換ツールは、AIのトレーニングのためにファイルのコピーを保持しています。TabliSyncはエンタープライズプライバシースキルドを提供します。変換が完了し、Excelファイルをダウンロードすると、当社のサーバーはソースPDFの暗号化ワイプを実行します。お客様のデータは、明示的な同意なしにトレーニングに使用されることはありません。
---
第8章:PDFからExcelへの変換百科事典(包括的なFAQ)
複雑なドキュメントの課題を乗り越えるために、北米のユーザーから最も頻繁に寄せられる20の質問をまとめました。
技術的および構造的なFAQ
1. PDFをExcelに変換すると、一部の列が結合されるのはなぜですか?
これは通常、標準のOCRでは「空白」を列の区切りとして検出できないために発生します。TabliSyncはニューラルテーブル再構築を使用して、縦線がなくても配置を識別し、列の結合を防ぎます。
2. TabliSyncは回転したページを含むPDFを処理できますか?
はい。当社の前処理エンジンは、ページの向きを自動的に検出し、PDFからExcelへの抽出を開始する前に、正しい0度の平面に回転させます。
3. 変換できるページ数に制限はありますか?
当社のエンタープライズプランは、最大2,000ページの「メガPDF」をサポートしており、年次財務報告書や長文の法的開示に適しています。
4. AIは、単一セル内の複数行のテキストをどのように処理しますか?
TabliSyncは、「テキストラッピング」ロジックを識別します。複数行の説明を複数の行に分割するのではなく、Alt+Enterフォーマットを使用して単一のExcelセル内に保持します。
5. パスワードで保護されたPDFを変換できますか?
はい、許可があれば可能です。AIが暗号化されたデータを解析できるように、アップロード段階でパスワードを入力するように求められます。
業界と財務に関するFAQ
6. コンバーターは米国の日付形式(MM/DD/YYYY)を認識しますか?
もちろんです。Excelが実際の「日付」オブジェクトとして認識し、並べ替えられるように、出力設定を特定の地域形式に設定できます。
7. 1ページに複数の異なるテーブルがあるPDFをどのように処理しますか?
当社のエンジンはマルチテーブル検出を実行し、各テーブルを分離して、同じExcelシートに配置するか、別のタブに分割します。
8. 「読み取り専用」で制限されたPDFからデータを抽出できますか?
はい。当社のPDFからExcelへのエンジンは、視覚的な再構築(OCR)とコード解析の両方を使用するため、標準のコピー&ペーストでは「読み取れない」制限されたファイルを「読み取る」ことができます。
9. 会計スタイルの負の数(括弧付き)をサポートしていますか?
はい。TabliSyncは、Excelで(500.00)を-500.00として認識し、財務数式が正確であることを保証します。
10. 紙の表紙の写真をExcelに変換できますか?
はい、これは、特殊な産業グレードのOCRを使用する、当社のスキャン済みPDF/JPGからExcelへの機能の一部です。
統合とワークフローに関するFAQ
11. PythonまたはNode.js経由でTabliSyncを使用できますか?
はい、両方のSDKを提供しており、ローカル開発環境内でPDFからExcelへのタスクを自動化できます。
12. PDFにスタンプや署名などの「ノイズ」がある場合、どうなりますか?
当社のニューラルレイヤーは、アーティファクトを「透視」するようにトレーニングされており、署名やスタンプが一部重なっていても、下のテキストを識別します。
13. XLSXの代わりにCSVへの変換もサポートしていますか?
はい、データベースとの互換性を高めるために、出力形式として.csv、.xlsx、または.jsonを選択できます。
14. 一度に1,000件のPDFをバッチ変換する方法はありますか?
当社のバッチ処理ダッシュボードでは、一括アップロードが可能で、すべての結果を1つのマスターExcelファイルに統合できます。
15. このツールはMacとWindowsで動作しますか?
クラウドベースのソリューションであるTabliSyncは、ブラウザに依存せず、どのOSでも完璧に動作します。
高度なフォーマットと精度
16. 財務レポートの罫線なしテーブルをどのように処理しますか?
「配置近接性」アルゴリズムを使用して、テキストの配置を見て、線なしでグリッドロジックを再構築します。
17. ドキュメント全体ではなく、特定のページを選択して変換できますか?
はい、ページセレクターを使用すると、関連するデータページのみを対象にできるため、処理時間とクレジットを節約できます。
18. TabliSyncは元のフォントと色を保持しますか?
「フォーマットを保持」を切り替えてビジュアルスタイルを維持することも、「生データ」を選択してクリーンでフォーマットされていないExcelシートを取得することもできます。
19. AIが間違いを犯した場合はどうなりますか?
当社のサイドバイサイドエディターは、信頼度の低い文字を赤でハイライト表示し、ダウンロード前にデータを迅速に確認および修正できます。
20. どのくらいの時間を節約できますか?
平均して、TabliSyncは手入力や従来のコンバーターと比較して、データ入力とクリーニングの時間を95%削減します。
---
結論:データ戦略を将来にわたって保護する
PDFからExcelへの移行は、単なるファイル変換以上のものです。静的な情報と動的なインテリジェンスの架け橋となります。スピードと精度が究極の競争優位性となるアメリカのビジネス環境では、データをPDFの「デジタルアンバー」に閉じ込めておく余裕はありません。
TabliSyncは、人間の目の精度とスーパーコンピューターの速度を提供します。ドキュメントワークフローを自動化することで、チームは行、列、タイポではなく、分析、戦略、成長に集中できるようになります。
データを解き放つ準備はできましたか?
手作業によるデータ入力を排除した何千もの業界リーダーに加わりましょう。現在市場で最も正確なPDFからExcelへのテクノロジーを体験してください。
エンタープライズ向けPDFからExcelへの変換ガイド(2026年)とは?
エンタープライズ向けPDFからExcelへの変換ガイド(2026年)についての要点と、TabliSyncがExcel作業をどう速くするか。
エンタープライズ向けPDFからExcelへの変換ガイド(2026年)とは?
エンタープライズ向けPDFからExcelへの変換ガイド(2026年)は実務的なExcelワークフロー、よくある落とし穴、自動化パターンを扱います。このTabliSyncガイドが概念、例、関連チュートリアルを示します。
TabliSyncはエンタープライズ向けPDFからExcelへの変換ガイド(2026年)にどう役立ちますか?
スクリーンショットやPDFから表を抽出し、乱れたデータを整え、エンタープライズ向けPDFからExcelへの変換ガイド(2026年)関連の反復タスクを自動化します。
エンタープライズ向けPDFからExcelへの変換ガイド(2026年)はどこから始めればよいですか?
このページの概要から始め、下の関連記事でステップごとの手順とAIワークフローを確認してください。
すべての PDFからExcelへ 記事(31)
How to copy a table from a PDF to Excel: Native Options and AI OCR Workflow
In today's fast-paced business environment, efficiently transferring data from PDFs to Excel is crucial for productivity. Many users face challenges when attempting to copy tables from PDFs due to the cumbersome nature of manual data entry and the limitations of basic OCR tools. This article provides a comprehensive guide on how to effectively copy tables from PDFs into Excel. It covers both native options for those who prefer manual methods, as well as innovative AI OCR solutions like TabliSync that can significantly enhance the efficiency of this process. By following the step-by-step instructions, users will learn how to easily extract data from various types of PDF documents, ensuring a seamless transition to structured Excel formats. Whether you're an accountant, a data entry professional, or someone who frequently deals with financial documents, this guide will equip you with the knowledge to streamline your data extraction tasks.

Excel でシートを複製する方法: ステップバイステップ ガイド
このガイドでは、Excel でシートを複製する方法を段階的に説明し、ユーザーがスプレッドシートを効率的かつ正確に管理できるようにします。財務レポート、在庫シート、その他のデータを使用している場合でも、シートを複製することで時間を節約し、一貫性を確保できます。明確な指示に従って、この不可欠な Excel スキルを習得してください。このガイドの終わりまでに、自信を持ってシートを複製し、作業を整理できるようになります。このスキルを習得したら、TabliSync がスプレッドシート管理タスクをさらに強化する方法もぜひ探索してください。

PDFをExcelとして保存する方法
このガイドでは、TabliSyncを使用してPDFファイルをExcelスプレッドシートに変換するプロセスを説明します。PDFから編集可能な形式へのデータ転送に苦労した経験がある方は少なくありません。多くのユーザーは、手作業での入力が遅い、フォーマットの問題、データ転送の不正確さなどの課題に直面しています。この記事では、PDFを効率的にExcelファイルに変換するための明確なステップバイステップのアプローチを提供します。変換を実行する方法だけでなく、最良の結果を保証するためのヒントや、避けるべき一般的な落とし穴についても学びます。TabliSyncを使用すると、データ管理タスクを簡素化し、ワークフローを改善する合理化されたソリューションを見つけることができ、退屈なデータ入力ではなく分析に集中できるようになります。

Excelの数式ロック解除トラブルシューティング
このトラブルシューティングガイドは、Excelの数式ロック解除に関する実践的なソリューションをユーザーに提供し、一般的な問題に対処し、将来の問題を防ぐためのヒントを提供します。数式がロックされることは、特に正確なデータ操作に依存する財務および管理部門のビジネスユーザーにとって、大きな障害となる可能性があります。ステップバイステップのアプローチを通じて、この記事は読者が数式ロックの原因を理解し、これらの問題を解決するための効果的な戦略を提供するのに役立ちます。ここに概説されているソリューションを実装することにより、ユーザーはスプレッドシートの制御を回復し、不必要なフラストレーションなしにデータを効果的に編集および管理できるようになります。この記事はまた、将来そのような問題を防ぐためのベストプラクティスを強調しており、よりスムーズで効率的なスプレッドシートワークフローに貢献し、ユーザーが正確なデータ処理に完全に集中できるようになります。

Excel にドロップダウン メニューを追加する方法
Excel を使用するビジネス スタッフにとって、反復的な手作業によるデータ入力は、データの一貫性の低下や作業効率の低下を招くことがよくあります。この記事では、Excel のドロップダウン メニューの作成における難しさと、手動設定と自動データ抽出方法を含む 2 つのソリューションを紹介します。また、詳細な操作手順、主要なエクスポート前チェック、一般的な設定エラー、FAQ についても説明します。標準化されたドロップダウン メニューを構築することは、データ入力標準を効果的に統一し、手作業によるエラーを削減し、日々のオフィス データ処理および財務報告ワークフローを最適化します。

Excelでヘッダーを作成する方法
"Excelヘッダーに関するこの包括的なガイドで、データ整理の技術を習得しましょう。ステップバイステップの作成方法から高度なカスタマイズテクニックまで、この記事はデータの明確性を高め、非常にプロフェッショナルでインパクトのあるスプレッドシートを作成するための不可欠なスキルを身につけさせます。"

Excel で非表示の行をすべて再表示する方法:簡単なガイド
Excel で非表示になっている行は、ビジネスおよび会計担当者のデータ分析とレポート作成の精度をしばしば妨げます。この記事では、行を再表示する手動および自動の方法を紹介し、一般的な運用上の落とし穴と主要なデータ検証ポイントをリストアップします。これにより、ユーザーはスプレッドシートの完全なデータを効率的に復元し、信頼性の高いデータ処理を保証できます。

PDFからExcelへ表をコピーする方法
["PDFファイルから編集可能なExcelスプレッドシートへの表データの変換に関する詳細なステップバイステップガイド", "変換精度を保証し、エラーを回避するために抽出されたデータコンテンツをチェックおよび検証するための専門的なヒント", "請求書や財務諸表などの一般的なドキュメントを対象とした、PDF表変換の実用的な応用シナリオ", "日々のPDFデータ変換とソート作業を簡素化および最適化するための効果的な方法と経験", "日常のオフィスワークのための効率的で時間のかからないPDFからExcelへのデータ処理ワークフローの構築に関するガイダンス"]

Excelでボックスプロットを作成する方法:複雑なテーブルを実用的なインサイトに変える
構造化されたデータ準備と動的なExcel範囲を使用して、手動のチャート作成時間を70%削減します。 ボックスプロット生成前にAI OCR解析を統合することで、構造化されていないソースからのデータ入力エラーを排除します。 生テーブルと可視化レイヤー間のリアルタイム同期により、統計分析のための単一の真実の情報源を維持します。

Excel で行をまとめて並べ替える方法: 複雑なデータ テーブル ガイド
Excel テーブルまたは選択範囲の拡張オプションを使用することで、行の分割エラーを完全に排除し、並べ替え後のデータ修復時間を最大 90% 短縮します。 Power Query または構造化参照を使用して、手動選択なしで複数列のグループ化されたデータを横断して並べ替えを自動化し、ワークフローのステップを 8 クリックから 1 クリックに削減します。 AI OCR 前処理と TabliSync を並べ替え前に組み合わせることで、半構造化インポート(PDF、請求書)でのデータ破損を防ぎ、行の整合性を 99.5% 達成します。

キーボードショートカット「値の貼り付け」を使用して複雑なスプレッドシートデータをクリーニングする方法
手動での書式削除ではなく、直接ショートカットキーで値の貼り付けを使用することで、データクリーニング時間を最大80%削減します。 インポートされたデータセットまたはレガシーデータセットから、隠れた書式エラー、壊れた数式、一貫性のないデータ型を排除します。 マクロやVBAなしで、クリーンで再現可能なデータパイプラインを維持します — ネイティブExcelのキーストロークのみを使用します。 値の貼り付けとTabliSyncのような抽出ツールを組み合わせることで、構造化データと非構造化データのワークフローを橋渡しします。

大規模データセットのExcel自動調整行の高さを自動化する
自動調整が失敗する最も一般的な理由は、手動で設定された行の高さや結合されたセルです。結合されたセルは、結合領域の内容を無視し、左上のセルの高さのみを参照します。実用的な教訓:動的な高さが必要な行を結合することは避けるか、テキストの折り返し後に結合された行を手動で調整する必要があることを受け入れてください。自動調整後に行が高すぎるように見える場合は、隠された文字や過剰な改行がないか、書式設定をクリアして確認してください。診断アプローチは簡単です:行の境界線をダブルクリックしても何も起こりませんか?手動の上書きを疑ってください。行は縮小されますが、コンテンツはまだ切り取られていますか?テキストの折り返しがないことを疑ってください。

Excelの空白行を削除する方法:ネイティブExcelとAIワークフローオプション
TabliSyncは、Excelの空白行をワンクリックで削除し、手作業でのクリーニングを不要にします。 現在、お客様の地域で提供されているすべてのユーザーが、追加費用なしでStandardプランで即時利用可能です。 Excel 2019(Windows)およびExcel 365(Windows/macOS)をサポート。VBAやマクロは不要です。 バッチ処理は、シートあたり最大10,000行を処理し、完全に空白の行を自動検出します。

ワークフローを中断せずにExcelでIF OR文を使用する方法
Excelで複数の条件をテストするために、無限にネストされたIF文ではなくIF OR文を使用してください。 手動入力は、特に3つ以上の論理テストの場合、エラーが発生しやすく、監査が困難です。 TabliSync AIは条件マッピングを自動化し、数秒でクリーンな数式を生成します。 誤った結果を避けるために、常に空白や混合データ型などのエッジケースをテストしてください。

Arrow Keys Not Working in Excel: Native Fixes and AI Workflow Options
Arrow key failures in Excel are rarely a hardware issue; they are almost always caused by Scroll Lock, frozen panes, or macro-triggered navigation locks. Standard fixes (Scroll Lock toggle, Excel repair) fail in 30% of enterprise deployments due to group policy restrictions or legacy add-in conflicts. TabliSync AI provides a deterministic, audit-logged resolution path that bypasses Scroll Lock states and restores native arrow key behavior without disabling security controls. Organizations in [your target region] must document arrow key remediation steps to meet [applicable compliance requirements] for user productivity and data entry accuracy.

Excelで2つの列をマージする方法:ネイティブExcelとAIワークフロー
サイレントなデータ破損を防ぐため、常にマージされたデータをソース列と照合して確認してください。 完全な帰属を確保するため、監査証跡または数式ベースの連結を提供するツールのみを使用してください。 エッジケースを手動で検証せずに、AI生成のマージ提案に頼らないでください。 コンプライアンス準備のために、データガバナンスログにマージ方法と日付を記録してください。

Excelの空白行を安全に削除する方法:ネイティブExcelとAIワークフローガイド
Excelの空白行は、スペースや不可視文字のような部分的なコンテンツによって隠されることがよくあります。削除する前に、必ず「すべて表示」してからスキャンしてください。 AIツールは空白行を削除するためのVBAマクロや数式を生成できますが、AIの出力は常にデータのコピーでテストしてから使用してください。 隣接するデータを破損させないように、「行全体を削除」を無闇に使用しないでください。フィルターまたは「ジャンプ先」機能を使用してください。 人間の目視検査と自動化された手順を組み合わせてください。最良の削除ワークフローは、人間のAI協調であり、丸投げではありません。

Excel 2026で非表示の行を再表示する方法:ネイティブExcelとAIワークフローの方法
Excel 2026で3つの主要な方法を使用して行を再表示します。右クリックコンテキストメニュー、キーボードショートカット(Ctrl+Shift+9)、および表示の下にある[書式]リボンを使用します。 フィルターによって非表示になった行については、行の非表示コマンドではなく、行列のフィルターをクリアするためにフィルターのドロップダウンを使用します。 ワークシート全体を選択(Ctrl+A)してから右クリックして[行の非表示解除]を選択することで、一度に複数の行をバッチ非表示解除します。 印刷または共有する前に、ワークシート保護設定を監査し、[ジャンプ先]機能を使用して非表示の行を特定することで、偶発的な非表示を防ぎます。

AIで数秒でPDFをXLSに変換する方法
AI OCRと構造化データ抽出を使用して、PDFからExcelへの変換時間を15分から10秒未満に短縮します。 自動スキーマ検証と正規化された出力により、手動データ入力エラーを最大99%削減します。 ソースPDFとExcelワークブック間のリアルタイム同期を維持し、データリフレッシュサイクルをゼロにカットします。 再トレーニングやカスタムスクリプトなしで、半構造化およびスキャンされたPDFレイアウトを処理します。

Excelで行を挿入するショートカットキー:データ準備を高速化
Ctrl+Shift++ショートカットを使用して行を80%速く挿入し、データ準備時間を数秒からキーストロークに短縮します。 行挿入とExcelテーブル構造化参照を組み合わせることで、手動コピー&ペーストのエラーを排除し、数式が自動拡張されるようにします。 ショートカットと、PDFや画像をライブExcelテーブルに解析して挿入準備のできるAI OCRワークフローを組み合わせることで、データ入力の摩擦を軽減します。 新しく挿入された行に名前付き範囲とデータ検証を使用して、監査証跡とデータガバナンスを維持し、構造の破損を防ぎます。
_20260527094715A097.png)
TabliSyncでExcelの2つの列の比較をマスターする
TabliSyncの自動データ取り込みとリアルタイム同期を使用して、手動での列比較時間を70%削減します。 重複、フォーマットの不一致、欠落値によるVLOOKUPエラーを、構造化参照マッチングで排除します。 AI OCR解析とExcelネイティブ検証ツールの組み合わせにより、非構造化ソース全体で100%のデータ整合性を維持します。
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す