Article Summary
この包括的なガイドでは、複雑で構造化されていないテーブル内の「テキストを列に分割」という重要なタスクに焦点を当て、データ解析の進化を探ります。ネストされたデータ、一貫性のない区切り文字、または複数行のセルエントリに直面した場合にしばしば失敗するExcelの「テキストから列へ」ウィザードのようなレガシーツールの制限について掘り下げます。AIデータ抽出と自動テーブル解析を統合することにより、ユーザーは前例のない精度で財務データクリーニングと複雑なOCR処理を処理できるようになりました。このピラーページは、手動の正規表現ベースの方法と、TabliSyncのような最新のAI駆動ソリューションを比較しながら、構造化データ変換の戦術的なウォークスルーを提供します。総勘定元帳の照合、請求書の自動処理、高度な補完戦略によるnull値の処理など、特定のエンタープライズユースケースをカバーします。このガイドは、精度やセキュリティを犠牲にすることなくデータワークフローを拡張する必要があるオペレーションマネージャー、データアナリスト、および金融専門家向けの技術マニュアルとして機能します。SOC2コンプライアンスの重要性と、最新のビジネスインテリジェンスのためのシームレスで自動化されたエンドツーエンドのデータパイプラインの構築におけるWebhooksの役割を強調します。
データ解析の進化:基本ウィザードを超えて
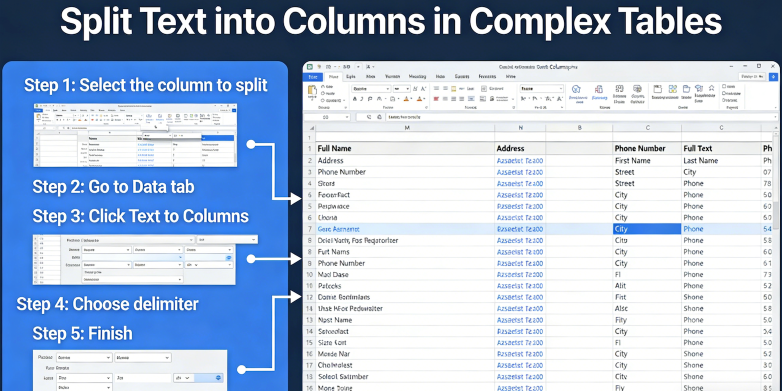
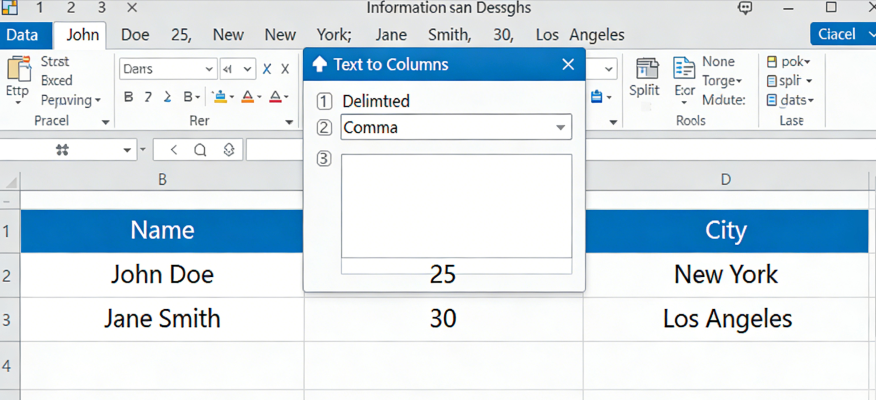
テキストを列に分割の現状を理解するには、まず従来の基盤に目を向ける必要があります。Microsoftのサポートドキュメント「テキストを列に変換ウィザード」によると、次のようになっています。
「1つ以上のセルにあるテキストを、テキストを列に変換ウィザードを使用して複数のセルに広げることができます。これは通常、コンマなどの特定の文字で区切られたデータ、または固定幅のデータに使用されます。たとえば、1つの列にフルネームのリストがある場合、その列を個別の名と姓の列に分割したい場合があります。分割したいテキストが含まれるセルまたは列を選択します。データ > テキストを列にを選択します。テキストを列に変換ウィザードで、区切り記号 > 次へ を選択します。データの区切り記号を選択します。たとえば、コンマとスペースです。データプレビューウィンドウでデータのプレビューを確認できます。次へ を選択します。列のデータ形式を選択するか、Excelが選択したものを使用します。完了 を選択します。」(出典:Microsoft Support、2024年)。
この基本的なアプローチは基本的なスプレッドシートタスクの定番ですが、最新の財務データクリーニングにははるかに強力な処理能力が必要です。Microsoftの方法は、実際の複雑なOCR処理ではめったに存在しない、ある程度のデータクリーンネスを前提としています。プロフェッショナルな環境では、単に「ジョン・ドウ」を2つのセルに分割するだけではありません。数が多いスペース、改行、あるいはそれ以上に悪いことに、行全体が左にずれてしまい、総勘定元帳の配置を台無しにする欠落値が「区切り文字」となる、古いPDFからの構造化データ変換を扱っています。
この点に関する私の見解は、「ウィザード」はもはや時代遅れだということです。高リスクなAIデータ抽出では、手動での区切り文字選択に頼るのは破滅への道です。50,000行のデータがある場合、余分なコンマが1つ含まれるだけで、監査に何時間もかかる連鎖的なエラーが発生します。セミコロンを探すだけでなく、データのコンテキストを理解する自動テーブル解析へと移行する必要があります。ルールベースの分割からコンテキスト認識型抽出への移行こそが、次世代の生産性ツールの定義となるでしょう。
サイレントキラー:欠損値とNULL値の処理
テキストを列に分割するワークフローにおける最も重大な問題点は、欠損値やnull値の処理が不十分であることです。多くのレガシーシステムでは、これらのギャップを補完またはフラグ付けする体系的な方法がありません。ERPシステムからの大規模なエクスポートを処理していると想像してください。A列は日付、B列はベンダー、C列は金額です。もし数行でベンダー名が欠落している場合、標準的な自動テーブル解析スクリプトは、「金額」を「ベンダー」列に引き込んでしまう可能性があります。これは単にデータが乱雑になるだけでなく、目に見えないエラーが発生し、照合の失敗につながります。
null値をフラグ付けする方法がなければ、構造化データ変換は負担となります。ほとんどのユーザーは、数千行を手動でスクロールして「シフトした」データを探すことでこれを修正しようとします。これは時間の無駄であるだけでなく、データパイプラインの根本的な失敗です。これは財務データクリーンアップでよく見られます。ここでの総勘定元帳コードの欠落は、経費が誤って分類される原因となり、監査の失敗や税金の不一致につながる可能性があります。体系的な「補完」または「フラグ付け」エンジンの欠如は、データコンシューマーが常に不完全なデータセットで作業していることを意味します。
エンタープライズレベルでは、人間を主要な「nullチェッカー」として採用することはできません。期待されるデータ型に基づいて値の不在を検出するシステムが必要です。C列が通貨形式を期待していて文字列が見つかった場合、システムはその行を直ちにフラグ付けする必要があります。従来のOCR処理は、文字認識に焦点を当てており意味論的な理解ではないため、これらのニュアンスを見逃すことがよくあります。ここでAIデータ抽出がギャップを埋め、プレースホルダーの自動挿入や、異常が検出された場合にのみ人間のレビューのためのWebhookのトリガーを可能にします。
従来のExcelとAIデータ抽出:効率のギャップ
テキストを列に分割することについて話すとき、従来の AI データ抽出との費用対効果分析に対処する必要があります。中規模の会計事務所が関与した最近のケーススタディでは、銀行の明細書や総勘定元帳のエクスポートを手動でクリーンアップするのに週に約15時間を費やしていました。従来のExcelウィザードを使用すると、アナリストは銀行のフォーマットごとに「固定幅」を手動で調整する必要がありました。平均時給45ドルとすると、この事務所は基本的な財務データクリーンアップだけで年間35,000ドル以上を費やしていました。
TabliSyncによる自動テーブル解析に切り替えることで、同社はその15時間の作業負荷をわずか12分の検証に削減しました。効率の向上はほぼ98%でした。Excelウィザードとは異なり、AIデータ抽出は機械学習を使用してパターンを特定します。銀行がフォントを変更したり、PDFの上部に新しいロゴを追加したりしても関係ありません。構造化データ変換エンジンは、テーブルヘッダーを特定し、物理的なレイアウトの変更に関係なく、コンテンツを正しい列にインテリジェントにマッピングします。これが「ツール」と「ソリューション」の違いです。
さらに、コスト削減は労働力だけにとどまりません。データ入力エラーのコストを検討してください。照合プロセスでは、テキストから列への分割の失敗による1つの小数点位置のずれが、数千ドルの不一致につながる可能性があります。複雑なOCR処理とAI検証を組み合わせることで、エラー率は業界平均の4%(手動入力)から0.1%未満に低下します。財務諸表の再作成のリスクの低減を考慮すると、自動テーブル解析のROIは指数関数的に増加します。企業はもはや時間を節約しているだけでなく、正確さと安心感を購入しています。
機能 従来のExcelウィザード TabliSync AI抽出
セットアップ時間
ファイルタイプごとに手動
テンプレートなしのワンタイム学習
複雑なテーブル
ネストされた/複数行のセルでは失敗する
ネストされた構造を簡単に処理
Null処理
列のシフトを引き起こす
自動フラグ付けと構造維持
スケーラビリティ
人間の能力に限定される
API経由で数千ページを処理
ステップバイステップ:複雑なテキストの分割と列への変換をマスターする
ステップ1:ソース構造と区切り文字の分析
テキストの分割と列への変換を考える前に、ソースデータを徹底的に監査する必要があります。これは、特に「テキスト」がフラットファイルまたはPDFから抽出される複雑なOCR処理の場合に当てはまります。データが実際に区切り文字(カンマ、タブ、またはパイプ)で区切られているのか、それとも固定幅のスペースに依存しているのかを特定する必要があります。多くの最新の財務データクレンジングタスクには、標準のテキストエディタでは表示されないノンブレークスペースや特定のASCII文字などの「隠れた」区切り文字が含まれています。
このステップでは、ハイレベルなテキストエディタ(VS CodeやSublimeなど)を使用して隠し文字を表示する必要があります。不整合を探してください。3行目に引用符で囲まれた文字列の中に余分なカンマがありますか?標準の構造化データ変換ツールはこれに失敗します。「貪欲な」正規表現を使用するか、よりニュアンスのあるAIデータ抽出モデルを使用するかを決定する必要があります。総勘定元帳を扱っている場合は、勘定科目番号と説明が1つのフィールドにマージされているかどうかを確認してください。これは、分割の「ロジック」を定義する段階です。基本的なウィザードが失敗する主な理由である複数行のセルに注意してください。
プロのヒント:自動テーブル解析スクリプトを実行する前に、必ず生のデータのバックアップを作成してください。正規表現のロジックが間違っていると、重要なデータを上書きしてしまう可能性があります。この分析フェーズ中に、「エッジケース」、つまりパターンに合わない行を文書化してください。これらは、機械的にではなく文脈的に解釈するためにAIデータ抽出を必要とする行です。ここでデータの「形状」を理解することで、ステップ3でのトラブルシューティングの時間を節約できます。
ステップ2:AI抽出エンジンの設定
パターン(またはその欠如)を特定したら、自動テーブル解析エンジンの設定に進みます。TabliSyncでは、これはコードの記述ではなく、抽出したい「エンティティ」を定義することを含みます。システムに「すべてのカンマで分割」と指示するのではなく、「請求書番号、日付、および品目合計を見つける」と指示します。このAIデータ抽出アプローチは、空間認識と意味論的ロジックを使用してテキストの分割と列への変換タスクを実行するため、はるかに堅牢です。
設定中、構造化データ変換のルールを設定できます。たとえば、値が「日付」として識別された場合、分割中にISO 8601形式(YYYY-MM-DD)に正規化するようにシステムに指示できます。ここで財務データクレンジングがリアルタイムで行われます。単にテキストを移動しているのではなく、変換しているのです。NULL値の処理もここで設定する必要があります。システムに「数量」列が空の場合は、この行を手動レビューのためにフラグ付けし、照合エクスポートに進まないでください」と指示します。
このステップは、Webhook設定を統合する場所でもあります。数千ものドキュメントを処理している場合、テキストを列に分割プロセスが完了したら、システムがERP(NetSuiteやSAPなど)に通知するようにしたいはずです。これにより、シームレスな自動テーブル解析パイプラインが作成されます。AIがヘッダーと複雑なOCR処理の境界を正しく識別していることを確認するために、10〜20のさまざまなドキュメントの小さなサブセットに対して設定をテストしてください。バルク処理に進む前に、100%のフィールドカバレッジを確認してください。
ステップ3:分割後の実行とデータ検証
最終ステップは、テキストを列に分割タスクの実際の実行とそれに続く検証です。ここで「いよいよ本番」となります。AIデータ抽出エンジンがファイルを処理すると、ターゲット列が入力されます。しかし、作業はまだ終わっていません。検証レイヤーを実装する必要があります。これには、抽出されたデータを既知のビジネスルールに対してチェックすることが含まれます。たとえば、財務データクレンジングでは、「分割」明細の合計は、ヘッダーから抽出された「合計金額」と等しくなければなりません。一致しない場合、自動テーブル解析は整合性チェックに失敗したことになります。
検証は、構造化データ変換がエンタープライズグレードになる場所です。「信頼度が低い」スコアを探すべきです。最新のOCR処理ツールは、各セルに信頼度パーセンテージを提供します。システムが分割について60%しか確信がない場合は、人間の検証のためにキューに保留する必要があります。この「ヒューマン・イン・ザ・ループ」モデルにより、ボリュームの95%を自動化しながら、100%の精度を維持できます。検証後、データは最終的な照合、またはビジネスインテリジェンスダッシュボードでの使用の準備が整います。
前述のnull値をシステムがどのように処理したかに細心の注意を払ってください。正しくフラグが立てられましたか?列は整列したままでしたか?繰り返し発生するエラーが見つかった場合は、ステップ2に戻り、AIの指示を洗練してください。目標は、各テキストを列に分割ジョブが前回よりも正確になるような、自己改善ループを作成することです。最後に、必要な形式(CSV、JSON、または直接APIプッシュ)でデータをエクスポートし、SOC2コンプライアンスと監査証跡のために元のドキュメントをアーカイブしてループを閉じます。
財務監査における構造化データ変換の役割
財務データクレンジングの世界では、構造化データ変換は単なる利便性以上のものです。最新の監査には必須です。今日の監査人は、サンプルベースのテストから全母集団テストへと移行しています。これは、数件だけでなく、総勘定元帳のすべてのトランザクションに対してテキストを列に分割できる必要があることを意味します。データが、乱雑でフォーマットされていないPDFエクスポートに閉じ込められている場合、巨額の監査費用または限定的な意見に直面することになります。
AIデータ抽出を使用してこれらのレコードを正規化することで、すべてのトランザクションを検索可能かつ分類可能にすることができます。たとえば、銀行の明細書と社内記録との間の照合を実行する場合、トランザクション文字列を「日付」、「トランザクションID」、「販売者」に自動的に分割する機能により、自動マッチングが可能になります。この自動テーブル解析機能により、年末監査に費やす時間を数週間短縮できます。さらに、複雑なOCR処理ログは、データがどのように変換されたかの明確な監査証跡を提供し、内部統制にとって大きなメリットとなります。
SOC2コンプライアンスでは、データは安全かつ正確に処理されなければならないとも規定されています。手動のテキストを列に分割プロセスは、人間の改ざんや偶発的な削除の対象となりやすいです。TabliSyncのような自動化された構造化データ変換システムは、変換ロジックが一貫して適用され、クリーンアッププロセス中に不正な変更が行われないことを保証します。このレベルの信頼性は、CFOやコントローラーが、基盤となるデータの整合性に絶対的な自信を持って財務諸表に署名する必要があるため、不可欠です。
ケーススタディ1:物流会社が船荷証券の解析を自動化
グローバルな物流プロバイダーは、船荷証券の複雑なOCR処理に苦労していました。各配送パートナーは異なるテーブルフォーマットを使用しており、多くのドキュメントは低品質のスキャンでした。彼らの手動のテキストを列に分割ワークフローには、PDFからExcelにデータをコピー&ペーストし、列のずれによって発生したエラーを手動で修正する5人の常勤従業員が関わっていました。彼らは月に2,000件のドキュメントを処理しており、「重量」と「宛先」の列のエラー率は12%でした。
彼らはTabliSyncをAIデータ抽出のために導入しました。システムはさまざまなドキュメントレイアウトでトレーニングされ、周囲のノイズに関係なくコアテーブルを特定することを学習しました。自動テーブル解析エンジンは、複数行の商品説明を、99%の精度で個別の「SKU」、「数量」、「重量」の列に分割することができました。この構造化データ変換は時間の節約になっただけでなく、Webhookを介してデータを追跡システムに直接統合することを可能にし、顧客にリアルタイムの可視性を提供しました。
その結果、初年度の総コストは120,000ドル削減されました。さらに重要なのは、出荷処理のターンアラウンドタイムが4時間から5分に短縮されたことです。これにより、人員を増やさずに、より多くのクライアントを獲得できるようになりました。この事例は、AIによって強化されたSplit Text to Columnsが、バックオフィス業務ではなく戦略的優位性になることを浮き彫りにしています。Efficiencyの向上により、手作業での処理では決して達成できなかった方法でスケールアップすることが可能になりました。
事例 2: 不動産投資信託(REIT)の財務データクリーンアップ
大手REITは、financial data cleanupに大きな課題を抱えていました。毎月、さまざまな形式で数千もの異なるレントロールを受け取っていました。Excelファイル、PDF、さらには画像もありました。このデータを単一のGeneral Ledgerに統合するために必要なstructural data conversionは悪夢でした。彼らの主な問題は「ネストされた」データであり、複数の値が単一のセルに詰め込まれており、標準的なツールでは対応できない複雑なSplit Text to Columns操作が必要でした。
AI data extractionを導入することで、REITはテナント名、リース日、支払い履歴の抽出を自動化できるようになりました。automated table parsingエンジンは、単一のセルに基本賃料と共益費(CAM)の両方が含まれていることを認識し、それらを別々の列に分割して正確な会計処理を行いました。このレベルのcomplex OCR processingは、以前はかなりの人的介入なしには不可能でした。
REITは、月次決算を締め切るのに必要な時間を70%削減したと報告しました。Reconciliationプロセスを自動化することにより、過去数ヶ月の手作業による抜き打ちチェックで見逃されていた50,000ドル以上の過少申告賃料を発見しました。このEfficiencyとそれに伴うcost savingsは、大量で複雑な財務データセットを管理するあらゆる組織にとって、AI data extractionが不可欠なツールであることを証明しました。structural data conversionは、データの真の価値を引き出す鍵でした。
事例 3: 法律事務所とディスカバリー文書の解析
大規模訴訟事件の発見段階で、法律事務所は10万ページを超える銀行記録と社内メモを処理する必要がありました。不正行為のパターンを探すために、言及されているすべての金融取引についてテキストを列に分割する必要がありました。時間とSOC2コンプライアンスの懸念から、手作業での入力は不可能でした。厳格な証拠保全を維持しながら、複雑なOCR処理を処理できる構造化データ変換ツールが必要でした。
TabliSyncは、必要なAIデータ抽出機能を提供しました。「受取人」、「金額」、「日付」、「口座元」などの検索可能な列に分割し、取引テーブルを特定して文書を解析しました。文書が回転していたり、わずかにぼやけていたりしても、自動テーブル解析エンジンは高い精度を維持しました。同事務所は、Webhook統合を使用して、このデータを訴訟支援ソフトウェアに直接フィードし、高度な分析を行いました。
この自動化により、法務チームは3日間で重要な証拠を発見することができました。これは、パラリーガルのチームが数ヶ月かかっていた作業でした。正確な財務データクリーンアップと堅牢な監査証跡によって構築された信頼は、事務所が訴訟に勝訴する上で不可欠でした。これは、構造化データ変換が金融部門をはるかに超える汎用性の高いツールであり、法務、コンプライアンス、調査業務において重要な役割を果たしていることを示しています。
高度なテクニック:構造化データ変換における正規表現対AI
何十年もの間、構造化データ変換のゴールドスタンダードは正規表現(Regex)でした。Regexは強力ですが、壊れやすいです。開発者はデータのあらゆる可能なバリエーションを予測する必要があります。ベンダーが請求書のフォーマットを変更して「合計」を1センチ右に移動させた場合、Regexはしばしば壊れます。これは、メンテナンスと壊れた自動テーブル解析スクリプトの絶え間ないサイクルにつながります。対照的に、AIデータ抽出は回復力があります。特定の座標にある特定の文字を探すのではなく、「合計」という「概念」を探します。
一般総勘定元帳でテキストを列に分割するタスクを実行している場合、勘定コードと勘定名(例:「1001-現金」)の両方を含むセルに遭遇する可能性があります。Regexはハイフンで簡単に分割できます。しかし、勘定名自体にハイフンが含まれている場合はどうでしょうか?標準的な分割では、2列ではなく3列が作成されます。AIデータ抽出はコンテキストを理解し、「現金」が名前であることを知っています。たとえそれが異常な文字を含んでいてもです。これにより、絶え間ない「Regexチューニング」の必要性が減り、財務データクリーニングの技術的な障壁が低くなります。
さらに、AIによる自動テーブル解析は「分割不可能なもの」を処理できます。行が線ではなく、空白とフォントサイズによってきれいに分離されていないテーブルを考えてみてください。複雑なOCR処理は、これらの視覚的な手がかりを特定して、ある列がどこで終わり、次の列がどこで始まるかを判断できます。これは、最も高度なレベルでの構造化データ変換です。Regexは依然として非常に単純で高速なタスクには場所がありますが、現代の企業は、変動性、複雑性、または高リスクのデータに対しては、AIデータ抽出に頼るべきです。開発者の時間だけのコスト削減だけでも、AIが明確な勝者となります。
WebhooksとAPIでデータ戦略を将来にわたって保護する
Split Text to Columnsを真にマスターするには、スプレッドシートを超えて見る必要があります。自動テーブル解析の未来は、統合されリアルタイムです。Webhookを利用することで、ドキュメントがクラウドストレージフォルダにアップロードされた瞬間に、AIデータ抽出エンジンが起動し、構造化データ変換を実行し、クリーニングされたデータをデータベースにプッシュするデータパイプラインを作成できます。手動でのダウンロードやアップロードは不要です。これが効率性の頂点です。
財務データクリーニングへのAPIファーストアプローチにより、既存のソフトウェアが構造化データを「要求」できるようになります。たとえば、照合ソフトウェアは生のPDFをAPIエンドポイントに送信し、すでに適用されたすべてのSplit Text to Columnsロジックを含む、完全にフォーマットされたJSONオブジェクトを受け取ることができます。これにより、「スプレッドシートの中間業者」がなくなり、データ破損のリスクが軽減されます。開発者にとっては、基盤となる複雑なOCR処理やテーブル抽出ロジックを心配することなく、クリーンなデータの上に複雑な機能を構築できることを意味します。
最後に、信頼性とセキュリティの側面を考慮してください。Webhookを備えた自動パイプラインは、生の機密データにアクセスできる人の数を減らします。AIデータ抽出は安全な環境で実行され、構造化された出力はターゲットシステムに直接配信されます。これは、データ侵害の攻撃対象領域を最小限に抑えるため、SOC2コンプライアンスフレームワークに完全に適合します。これらのツールでデータ戦略を将来にわたって保証することで、今日のSplit Text to Columnsの問題を解決するだけでなく、次の10年間のデジタルトランスフォーメーションのためのスケーラブルな基盤を構築することになります。
よくある質問 (FAQ)
Q1: AIは分割中に異なる日付形式をどのように処理しますか?
AIデータ抽出を使用してテキストを列に分割する操作を実行すると、システムは単にテキストを分割するだけでなく、データ型を識別します。1つの行に「MM/DD/YYYY」があり、別の行に「DD-Mon-YY」がある場合、自動テーブル解析エンジンは、構造化データ変換中に両方を一貫した形式に正規化できます。たとえば、総勘定元帳の照合では、すべての日付を自動的に標準ISO形式に変換できます。これにより、日付のロジックを理解しない単純なテキスト分割ウィザードを使用した場合に通常発生する、財務データクリーンアップのエラーを防ぐことができます。
Q2: 1つのセル内で複数行にまたがるテキストを分割できますか?
はい、これは従来のツールに対するAIデータ抽出の最大の利点の1つです。基本的なExcelウィザードは、単一のデータ行がPDFや画像内の複数の物理的な行にまたがる場合に失敗することがよくあります。複雑なOCR処理は、テーブル行の視覚的な境界を認識し、テキストを列に分割ロジックを適用する前に、複数行のテキストを単一のエンティティとして扱うことができます。これは、請求書の明細がしばしば長く、複数行に折り返される財務データクリーンアップに不可欠であり、数量と価格が常に正しい品目に一致することを保証します。
Q3: 一部の行で区切り文字が欠落している場合はどうなりますか?
従来のテキストを列に分割ワークフローでは、区切り文字が欠落するとデータがシフトし、データセット全体が台無しになります。しかし、AIを使用した自動テーブル解析は、区切り文字だけに依存しません。空間的および意味的なコンテキストを使用します。カンマが欠落していても、システムが明確な間隔とデータ型の変更(例:テキストから通貨へ)を認識した場合、分割は正しく実行されます。これにより、「null値」の問題を防ぎ、複雑なOCR処理で一般的なシナリオである不完全なソースファイルでも、構造化データ変換が正確であることを保証します。
Q4: コードを使用せずに列を分割することは可能ですか?
もちろんです。TabliSyncのようなツールは、RegexやPythonスクリプトを書く必要なくAIデータ抽出を必要とするビジネスユーザー向けに設計されています。システムをテーブルにポイントするだけで、自動テーブル解析エンジンが重労働を行います。これにより、構造化データ変換が民主化され、会計士やオペレーションマネージャーが自身の財務データクリーニングを実行できるようになります。技術的なボトルネックを排除することで、組織は効率性を向上させ、ITチームはより高度な統合タスクに集中できるようになり、ビジネスユーザーは自身でデータ品質を管理できるようになります。
Q5: 抽出プロセス中に私の財務データはどの程度安全ですか?
財務データクリーニングにおいては、セキュリティが最優先事項です。TabliSyncのようなプロフェッショナルなAIデータ抽出プラットフォームは、SOC2準拠を念頭に置いて構築されています。これは、データが保存時および転送時に暗号化されることを意味します。安全でないローカルマシンで行われる可能性のある手動のテキストを列に分割タスクとは異なり、自動化された構造化データ変換は、管理されたクラウド環境で行われます。これにより、信頼性が確保され、組織が自動テーブル解析ライフサイクル中に機密性の高い総勘定元帳または顧客情報を処理する際に、法的および規制要件を満たすのに役立ちます。
Q6: 手書き文書内のテーブルも処理できますか?
最新の複雑なOCR処理は、手書き文字の認識において大きな進歩を遂げています。印刷されたテキストよりも困難ですが、AIデータ抽出は、手書きのメモやフォーム内のテーブル構造を識別できることがよくあります。自動テーブル解析エンジンは、テキストの相対的な位置を探して列を推測します。デジタルPDFよりも精度がわずかに低い可能性がありますが、構造化データ変換の大きな前進となります。レガシーな紙の記録の財務データクリーニングの場合、これにより、手動のデータ入力と転記作業の何千時間も節約できます。
Q7: Webhookとは何ですか?また、列の分割にどのように役立ちますか?
Webhookとは、イベントが発生したときに、あるアプリケーションから別のアプリケーションにリアルタイムでデータを送信する方法です。自動テーブル解析の文脈では、AIデータ抽出がテキストを列に分割するジョブを完了するとすぐに、結果の構造化データがERPまたは照合ソフトウェアに自動的に送信されるようにWebhookを設定できます。これにより、CSVをエクスポートして別の場所にアップロードする手動のステップが不要になり、データパイプライン全体の効率が大幅に向上し、財務データクリーンアップが常に最新の状態に保たれます。
Q8:数千行に及ぶ非常に大きなテーブルをシステムはどのように処理しますか?
AIデータ抽出はスケーラビリティのために構築されています。量が増えるにつれて遅くなる手動プロセスとは異なり、自動テーブル解析は数秒で数千行を処理できます。構造化データ変換ロジックはデータセット全体に一貫して適用され、1行目と10,000行目が同じ精度で処理されることが保証されます。これは、総勘定元帳のエクスポートが膨大になる可能性のある大企業における財務データクリーンアップにとって不可欠です。自動システムを使用することで、データのニーズが増加しても効率を失うことはありません。
Q9:分割後にヘッダーをカスタマイズできますか?
はい、自動テーブル解析の設定中に、出力ヘッダーがどうなるかを正確に定義できます。元のドキュメントに不明瞭または説明不足のヘッダーがある場合でも、AIデータ抽出エンジンはそれらを標準化された内部フォーマットにマッピングできます。これは構造化データ変換の重要な部分であり、データが照合またはBIツールですぐに使用できる状態であることを保証します。分割プロセス中にヘッダーをカスタマイズすることは、異なるデータソースやベンダー間で一貫性を維持するため、財務データクリーンアップのベストプラクティスです。
Q10:手動分割とAI分割のコストの違いは何ですか?
コスト削減は通常、相当なものです。手動でのテキスト分割(列へ)タスクは、時間がかかるだけでなく、高額なエラーにつながりやすいです。熟練した財務アナリストの時間給を考慮すると、手動での財務データクレンジングにかかるコストは、自動テーブル解析ソリューションを使用するよりも10倍から50倍高くなる可能性があります。AIデータ抽出は、ドキュメントまたは行ごとに固定された予測可能なコストを提供するため、予算編成が容易になり、人員を線形に増やさずに構造化データ変換業務を拡大できます。これにより、ROIが大幅に向上します。
データとの格闘をやめ、同期を始めましょう
壊れたテキスト分割(列へ)ウィザードや位置ずれした総勘定元帳エクスポートに苦労する日々は終わりました。データを見てきたはずです。手動クレンジングは、あなたの効率を消耗させ、あなたの信頼を危険にさらし、莫大な資本を浪費します。チームが手動で構造化データ変換エラーを修正するのに費やす毎分は、高価値の分析や戦略的成長に費やすことができない毎分です。AIデータ抽出を使用する企業とそうでない企業との差は、日々広がっています。
複雑なOCR処理の失敗によって引き起こされる照合の悪夢で、もう月末を迎えさせないでください。TabliSyncは、他のツールでは対応できない、乱雑で、ネストされた、構造化されていないテーブルを処理するために設計された、財務データクレンジングのための究極の武器です。私たちは、自動テーブル解析の精度と、SOC2準拠のセキュリティを提供し、データパイプラインが高速であると同時に堅牢であることを保証します。これは、あなたの時間を回復し、データワークフローで100%の精度を確保するチャンスです。
今すぐTabliSyncのパワーを体験してください。期間限定で、無料トライアルにサインアップして、私たちのAIデータ抽出が、あなたの最も乱雑なテーブルを数秒で完全に構造化された資産に変える方法を正確に確認できます。下のリンクをクリックして開始してください。手動データ入力があなたのビジネスの足を引っ張ることをこれ以上許さないでください。構造化データ変換の未来はここにあり、それはわずかワンクリックで手に入ります。
複雑なテーブルでテキストを列に分割する方法とは?
複雑なテーブルでテキストを列に分割する方法についての要点と、TabliSyncがExcel作業をどう速くするか。
複雑なテーブルでテキストを列に分割する方法とは?
複雑なテーブルでテキストを列に分割する方法は実務的なExcelワークフロー、よくある落とし穴、自動化パターンを扱います。このTabliSyncガイドが概念、例、関連チュートリアルを示します。
TabliSyncは複雑なテーブルでテキストを列に分割する方法にどう役立ちますか?
スクリーンショットやPDFから表を抽出し、乱れたデータを整え、複雑なテーブルでテキストを列に分割する方法関連の反復タスクを自動化します。
複雑なテーブルでテキストを列に分割する方法はどこから始めればよいですか?
このページの概要から始め、下の関連記事でステップごとの手順とAIワークフローを確認してください。

手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す