Article Summary
この包括的なピラーページは、データ抽出ワークフローの最適化を目指す専門家向けの決定版XLOOKUPチュートリアルとして機能します。XLOOKUPの仕組みを深く掘り下げ、基本的な構文を超えて、財務データ抽出、PDFテーブル解析、産業レポート自動化などの高度なアプリケーションを探求します。このガイドでは、「テキストとして保存された数値」エラーという、照合プロセスを悩ませる一般的な業界のペインポイントに対処します。手動データ入力とTabliSyncのBatch OCR to Excel機能などの自動ソリューションを比較することで、大幅なコスト削減と精度の達成方法を実証します。読者は、複雑なルックアップの詳細なステップバイステップの説明、総勘定元帳とWebhookを含む実世界のケーススタディ、技術的なハードルに対処する堅牢なFAQセクションを見つけることができます。あなたが財務アナリストであろうと、ロジスティクスマネージャーであろうと、このガイドは、最新のExcel関数とAI駆動の自動化ツールを使用して、乱雑な生データを実用的なビジネスインテリジェンスに変換するために必要な専門家の洞察を提供します。
はじめに:なぜ現代のデータ抽出にはより優れたツールが必要なのか
データ管理のエキサイティングな状況において、情報を正確に取得する能力は、収益性の高い四半期と財務監査の悪夢との違いを生み出します。Nexacu が 2026 年のガイドで指摘しているように、「XLOOKUP は Excel で最も強力で柔軟な検索関数であり、VLOOKUP、HLOOKUP、LOOKUP を置き換えます。返却列がどちら側にあっても、データセット内の値をすばやく見つけることができます。」 (出典: Nexacu, Excel で XLOOKUP を使用する方法: 完全な 2026 年ガイド)。この柔軟性は単なる利便性ではありません。ERP エクスポートやレガシー PDF ファイルなどのさまざまなソースから発生する、現代的で断片化されたデータセットを扱う際には、構造的な必要性です。
Nexacu の洞察に対する私の見解は、彼らが XLOOKUP を「VLOOKUP キラー」として正しく特定している一方で、ほとんどのユーザーは 自動データ入力 におけるこの関数の役割を過小評価しているということです。もはやリスト内の価格を探しているだけではありません。書式設定の不整合によってデータ整合性が損なわれることが多い数千行にわたる複雑な 財務データ抽出 を実行しています。静的な検索から動的配列への移行は、産業レポート自動化 を処理する方法における根本的な変化を表しています。古いインデックスマッチの組み合わせにまだ依存している場合、処理速度とエラー処理機能をテーブルに残していることになります。真の力は、XLOOKUP ロジックと バッチ OCR から Excel への変換 技術を組み合わせて、物理的なドキュメントとデジタル分析の間のギャップを埋めることにあります。
機械の中の幽霊:「テキストとして保存された数値」の危機
財務データ抽出 における最も永続的でイライラする障害の 1 つは、目に見えない不一致です。総勘定元帳レポートと銀行取引明細書があります。どちらも請求書番号「100582」を示しています。XLOOKUP チュートリアル に準拠した数式を作成しますが、#N/A が返されます。なぜでしょうか?1 つは 実数 であり、もう 1 つは テキストとして保存された数値 であるためです。これは単なる軽微な書式設定の不具合ではありません。会計部門に数百時間の人件費を要する体系的な障害です。照合。
Excelは、テキストとして保存されている数値を、数学的な値ではなく文字の文字列として扱います。人間が見ると、それらは全く同じように見えます。しかし、XLOOKUPエンジンにとっては、文字「A」と数字「1」ほど異なります。これは、OCRソフトウェアがデータ型を正しく識別できなかったり、古いERPシステムからのCSVエクスポートで数値が引用符で囲まれている場合に、PDFテーブル解析でよく発生します。自動データ入力を扱っている場合、この「機械の中の幽霊」は、完全な産業レポート自動化パイプラインを停止させる可能性があります。 この影響は、照合のような重要なタスクで最も強く感じられます。5,000件の明細項目を照合しようとしていると想像してください。そのうち15%が正しくフォーマットされていません。一部のコード(郵便番号や部品番号など)には、実際には先頭のゼロが必要な場合があるため、「すべて選択して数値に変換」するだけでは済みません。より洗練されたアプローチが必要です。ここで、TabliSyncは、バッチOCRからExcelへの変換ワークフローが、データ型をスプレッドシートに到達する前に検証することで、手動でのトラブルシューティングの頭痛の種をなくします。
効率とコスト:手動対自動データ抽出
XLOOKUPチュートリアル戦略について話すとき、実装コストに対処する必要があります。多くの企業は、より多くのデータ入力担当者を雇用することが安全でスケーラブルな解決策だと考えています。しかし、データは異なる物語を語っています。手動データ入力の平均エラー率は1%から4%です。数百万ドルが関わる財務データ抽出の文脈では、1%のエラー率は壊滅的です。数字を見てみましょう。
| メトリック | 手動データ入力 | 自動化(TabliSync + XLOOKUP) |
|---|---|---|
| 処理速度 | 〜毎分20〜30フィールド | 〜毎分1,000フィールド以上 |
| エラー率 | 1% - 4% | OCR検証で0.1%未満 |
| 人件費(年間) | 担当者あたり$45,000 - $60,000 | SaaSサブスクリプションの従量課金 |
| スケーラビリティ | 追加の雇用が必要 | 即時スケーリング |
コスト削減は給与だけではありません。それは、照合に費やす時間の節約です。バッチOCRからExcelへを使用すると、システムは人間が8時間のシフトで維持できないレベルの精度でPDFテーブル解析を処理します。産業レポート自動化では、ログが24時間年中無休で生成される可能性があるため、手動入力は単に不可能です。自動データ入力システムを実装することで、企業はしばしば最初の3か月以内に投資収益率(ROI)を達成します。最も重要な隠れた節約は、「修正サイクル」(エラーを見つけて修正するのに費やす時間)の削減です。データがクリーンなため、XLOOKUPが最初に機能する場合、チーム全体の生産性は3倍になります。
プロフェッショナル向けXLOOKUPチュートリアル:ステップバイステップ
データ抽出のためにXLOOKUPを習得するには、規律あるアプローチが必要です。これは単なる数式ではなく、データアーキテクチャに関するものです。自動データ入力が鉄壁であることを保証するために、これらのステップに従ってください。生の総勘定元帳エクスポートからの財務データ抽出を含むシナリオに焦点を当てます。
ステップ1:データサニタイズとタイプアラインメント
単一の「=」記号を入力する前に、検索値とソース配列が同じ形式であることを確認する必要があります。これは、XLOOKUPチュートリアルの最も重要な部分です。=ISNUMBER()関数を使用してキー列を確認します。テキストとして保存されている数値が見つかった場合は、=VALUE(A2) を使用したヘルパー列を使用して変換します。この手順により、前述の#N/Aエラーが防止されます。プロフェッショナルな産業レポート自動化では、Power QueryまたはTabliSyncの組み込みデータクリーニングアルゴリズムを使用して、この手順を自動化することがよくあります。専門家のアドバイス: PDFテーブル解析中にしばしば発生する目に見えない末尾のスペースを削除するために、TRIM()関数を使用して常にテキスト文字列をトリミングしてください。
ステップ 2: XLOOKUP数式の構築
XLOOKUPの美しさはそのシンプルさにあります。構文は =XLOOKUP(lookup_value, lookup_array, return_array, [if_not_found], [match_mode], [search_mode]) です。自動データ入力の場合、常に'[if_not_found]'引数を使用してください。Excelに醜いエラーを返させる代わりに、0または「ソースデータの確認」のような特定の文字列を返すように設定します。これにより、これらの特定のフラグをフィルタリングできるため、照合がはるかに速くなります。財務データ抽出を実行する場合、デフォルトですが覚えておくと良い、正確な一致のために'match_mode'を0に設定します。産業レポート自動化で段階的な価格設定を扱っている場合は、近似一致のために'1'または'-1'を使用する場合があります。
ステップ 3: バッチ処理のための動的配列の実装
自動データ入力を完全にマスターするには、動的配列とともにXLOOKUPを使用する必要があります。'lookup_value'に単一のセルを選択する代わりに、列全体を選択します。Excelは結果を自動的に列に「スピル」します。これは、バッチOCRからExcelへの変換ワークフローのゲームチェンジャーです。これにより、大規模なスプレッドシートでエラーの一般的な原因となる数式を「下にドラッグ」する必要がなくなります。データがスピルするための十分な空きスペースが数式のすぐ下にあり、十分でない場合は#SPILL!エラーが発生します。この方法は、Webhook経由で新しいデータがリアルタイムで入力される財務データ抽出レポートを生成するのに非常に効率的です。
高度なユースケース:財務データの抽出と照合
企業の財務部門における実際の応用例を見てみましょう。中堅製造業の企業は、毎月の照合に苦労していました。彼らはPDF形式で数百件の出荷請求書を受け取っていました。手作業のプロセスでは、担当者が請求書番号をExcelシートに入力し、次にVLOOKUPを使用して総勘定元帳で対応する発注書を見つけていました。PDFテーブル解析は存在せず、すべて手作業の転記でした。タイプミスによる5%のエラー率に直面し、支払遅延による罰金やベンダーとの関係悪化を招いていました。
TabliSyncをバッチOCRからExcelへ切り替えることで、旅の最初の半分を自動化しました。AI駆動のPDFテーブル解析は、請求書番号、日付、合計金額を標準化されたExcelテーブルに直接抽出しました。次に、高度なXLOOKUPを適用しました:=XLOOKUP(A2:A500, GL_Invoices, GL_Status, "Missing", 0)。これにより、総勘定元帳に一致するエントリがない請求書が即座にフラグ付けされました。'Missing'フラグにより、チームはすべての行をチェックするのではなく、例外のみに集中できるようになりました。これが産業レポート自動化の本質です:データ入力からデータ管理への移行。
その結果、照合時間が85%削減されました。財務マネージャーは、チームが以前は7日かかっていた決算を2日で完了できるようになったと報告しました。さらに、自動データ入力により、バッチOCRツールがクリーンな数値データを出力するように設定されていたため、「テキストとして保存された数値」の問題が解消されました。このケーススタディは、XLOOKUPの技術的な理解が、最大の効率を達成するために適切な抽出ツールと組み合わされる必要がある理由を強調しています。
産業レポート自動化とWebhookによるスケーリング
重工業では、データは単なるスプレッドシートにあるのではなく、クラウドにあります。産業レポート自動化では、Excel を外部データベースに接続する必要がよくあります。ここでWebhookが登場します。センサーが値を記録した瞬間や、倉庫管理者が出荷を承認した瞬間に、Webhook はスプレッドシートの更新をトリガーできます。ファイルを開かなくても、XLOOKUP テーブルが自動的に更新されるのを想像してみてください。これが自動データ入力の頂点です。
たとえば、石油・ガス会社は XLOOKUP を使用して機器の健全性を監視しています。センサーは Webhook 経由でデータを中央リポジトリに送信し、それが Excel に取り込まれます。次に、XLOOKUP 関数がこれらのセンサー ID を「しきい値」テーブルにマッピングして、値が安全限界を超えていないかを確認します。一致が見つかり、「クリティカル」ステータスを示す場合、スプレッドシートは自動メールアラートをトリガーできます。このレベルの産業レポート自動化は、Excel を受動的な記録保持ツールから能動的な監視システムに変えます。
バッチ OCR から Excel への変換と Webhook の統合により、シームレスなループが作成されます。物理的な検査レポートはスキャンされ、PDF テーブル解析によって解析され、データはクラウドにプッシュされます。次に Excel がそのデータをプルし、必要な XLOOKUP 操作を実行してマスターダッシュボードを更新します。これにより、機器の健全性の総勘定元帳が常に正確で最新の状態に保たれます。これは、大規模な産業オペレーションで一般的なデータサイロを防ぐ、堅牢でスケーラブルなアーキテクチャです。
信頼の確保:データの整合性と法的コンプライアンス
自動データ入力と財務データ抽出を実装する際には、法的およびコンプライアンスのフレームワークを無視することはできません。多くの法域では、財務記録は明確な監査証跡とともに保持する必要があります。元のソースドキュメントを保持しない場合、数式でデータを上書きするだけでは危険な場合があります。TabliSync のようなバッチ OCR から Excel への変換ツールは、ここで重要な利点を提供します。抽出された Excel の行と元の PDF ページ間のリンクを維持することがよくあります。これは、照合監査に不可欠です。
機密性の高い総勘定元帳データを扱う際は、SOC2やGDPRなどの業界標準を遵守することが不可欠です。XLOOKUPチュートリアルには、常にデータセキュリティに関するセクションを含めるべきです。専門家のアドバイス:数式に機密情報をハードコーディングしないでください。名前付き範囲または暗号化された外部接続を使用してください。PDFテーブル解析を実行する際は、OCRプロバイダーが必要以上にデータを保存せず、厳格な暗号化プロトコルに従っていることを確認してください。信頼は、データの信頼性と、それを配信するパイプラインのセキュリティの上に構築されます。
さらに、産業レポート自動化における精度は、効率性だけでなく安全性にも関わります。航空宇宙や製薬などの分野では、バッチOCRからExcelへの変換プロセスにおける1桁の誤りが、人生を変えるような結果をもたらす可能性があります。したがって、XLOOKUPを使用して2つの独立したソース間でデータをクロスリファレンスする多段階検証の実装は、ベストプラクティスと見なされます。この「冗長ルックアップ」戦略は、データ管理における高度な専門知識の証です。
一般的なXLOOKUPの落とし穴のトラブルシューティング
完璧なXLOOKUPチュートリアルがあっても、問題が発生する可能性があります。「テキスト対数値」の問題以外で最も一般的なエラーは、循環参照です。これは、return_arrayに数式自体が存在するセルが含まれている場合に発生します。自動データ入力では、ユーザーが列をその場で「更新」しようとすると、これがよく発生します。データの整合性を維持するために、常に新しい列にXLOOKUPの結果を出力してください。もう1つの落とし穴は、#REF!エラーです。これは、財務データ抽出のソースワークブックが閉じられているか移動された場合に発生します。絶対セル参照($記号付き)または名前付き範囲を使用することは、これを軽減するためのプロフェッショナルな方法です。
パフォーマンスについてお話ししましょう。XLOOKUPはVLOOKUPよりも高速ですが、50万行ものデータと数百回の検索を行うと、ワークブックの動作が遅くなる可能性があります。産業レポート自動化ファイルを最適化するには、検索モード引数を検討してください。これを「2」に設定するとバイナリ検索が実行され、非常に高速ですが、データがソートされている必要があります。これは、大量のデータセットを扱うバッチOCRからExcelへの変換ワークフローにおけるプロレベルのテクニックです。ワークブックの動作が遅い場合は、列全体を参照している(A:Aなど)かどうかを確認してください。代わりに、データが含まれる行のみに計算を制限するテーブル参照(Table1[Column1]など)を使用してください。
最後に、隠れ文字には常に注意してください。PDFテーブル解析を実行すると、テキストに印刷できない文字(改行されないスペースなど)が含まれることがあります。これらは目には見えませんが、XLOOKUPを壊してしまいます。数式内でCLEAN()とTRIM()を組み合わせて使用する(例:=XLOOKUP(CLEAN(TRIM(A2))...))ことは、自動データ入力が不格好なソースデータに対して堅牢であることを保証する効果的な方法です。この細部へのこだわりが、データ自動化の分野で初心者とSaaSコンテンツマーケティングエキスパートを分けるものです。
FAQ: XLOOKUPエコシステムのマスター
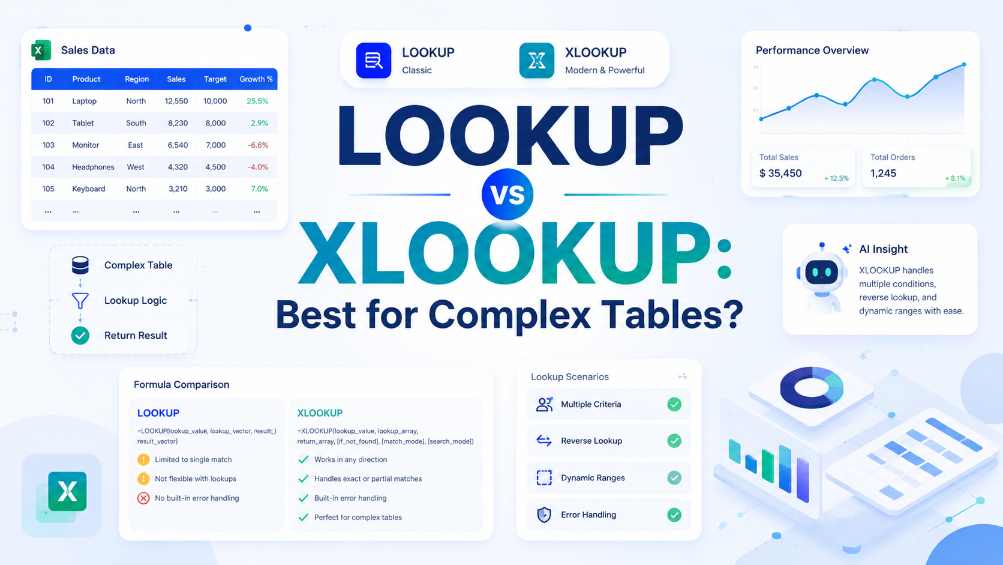
1. XLOOKUPは、すべての財務データ抽出タスクでVLOOKUPを置き換えることができますか?
もちろんです。XLOOKUPは、論理的には下位互換性があるように設計されていますが、実行においては優れています。列番号を数える必要がなくなり、これは総勘定元帳のメンテナンスにおけるエラーの主な原因となります。ソースデータに列を追加するとVLOOKUPは壊れますが、XLOOKUPは直接の範囲参照を使用するため、そのまま機能します。自動データ入力にとって、この耐久性は非常に価値があります。また、VLOOKUPでは複雑なINDEX-MATCHの回避策なしではできない左方向の検索も可能です。XLOOKUPへの切り替えは、産業レポート自動化を近代化するための最初の一歩です。
2. TabliSyncは、バッチOCRからExcelへの変換中に「テキストとして保存された数値」をどのように処理しますか?
TabliSyncは、高度なAIヒューリスティック分析を使用して意図されたデータ型を特定します。PDFテーブル解析フェーズでは、文字を見るだけでなく、コンテキストも考慮します。数字の文字列が「合計金額」列にある場合、システムは自動的にExcelの実数としてフォーマットします。これにより、財務データ抽出におけるXLOOKUPの失敗の主な原因を防ぎます。TabliSyncは、ソースでデータをクリーニングすることにより、自動データ入力ワークフローがシームレスであり、フォーマットのための手動介入を一切必要としないことを保証します。
3. WebhookをXLOOKUPで使用する利点は何ですか?
Webhookは、リアルタイムの産業レポート自動化を可能にします。毎朝CSVを手動でインポートする代わりに、WebhookはERPまたはOCRツールから新しいデータをExcel環境に直接プッシュできます。XLOOKUP数式、特に動的配列を使用するものは、新しい情報を反映するように自動的に更新されます。これは、請求書または出荷の現在のステータスを即座に知る必要がある照合タスクにとって重要です。データ処理を「バッチモード」から「ライブモード」に移行させ、運用効率を大幅に向上させます。
4. XLOOKUPはすべてのExcelバージョンで利用できますか?
XLOOKUPは、Microsoft 365、Excel 2021、およびExcel for the webで利用できます。古いバージョン(Excel 2016など)を使用しているクライアントと財務データ抽出レポートを共有する場合、#NAME?エラーが表示されます。このような場合は、送信前にTabliSyncを使用してデータを値にフラット化するか、受信者がアップグレードしたことを確認するのが最善です。社内の産業レポート自動化については、これらの最新の関数と自動データ入力機能を最大限に活用するために、すべてのチームメンバーがMicrosoft 365を使用していることを確認することを強くお勧めします。
5. 複数の基準に一致させるためにXLOOKUPを使用できますか?
はい、古い関数よりもはるかに簡単です。アンパサンド (&) を使用して、検索値と検索配列で条件を結合できます。たとえば、=XLOOKUP(Dept&ID, DeptRange&IDRange, ReturnRange) のようになります。これは、勘定コードが部署ごとに再利用される可能性がある **総勘定元帳** タスクに非常に役立ちます。これにより、'ヘルパー列' を作成する必要なく、**財務データ抽出** で 100% の精度が保証されます。この複数条件アプローチは、データ ポイントに複数の識別子を持つことが多い高度な **産業レポート自動化** の定番です。6. XLOOKUP のチュートリアルで部分一致をどのように処理しますか?
XLOOKUP は、ワイルドカード一致 (* や ?) をサポートしています。[match_mode] 引数を '2' に設定するだけです。これは、ベンダー名がドキュメント間でわずかに異なる場合がある **PDF テーブル解析** に最適です (例: "Apple Inc." 対 "Apple")。=XLOOKUP("*Apple*", NameArray, ReturnArray, , 2) を使用すると、正しいデータをプルできます。これにより、以前は達成が非常に困難だった **自動データ入力** に柔軟性が追加されます。これは、乱雑な **産業レポート** データをクリーンアップするための強力なツールです。
7. XLOOKUP はワークブックの計算速度にどのような影響を与えますか?
一般的に、XLOOKUP は高度に最適化されています。ただし、他の関数と同様に、数百万のセルに適用すると CPU サイクルを消費します。大規模な **財務データ抽出** の場合、重要なのは揮発性依存関係を回避することです。**TabliSync** を使用して **バッチ OCR から Excel への変換** の重い処理を実行し、その後 XLOOKUP を最終的な照合にのみ使用するのが最も効率的なアーキテクチャです。これにより、ワークブックは軽量で応答性が高くなります。**産業レポート自動化** の場合、データソースに一括変更を加える場合は、「手動計算」モードを使用することをお勧めします。
8. XLOOKUP は外部ワークブックで動作しますか?
はい、可能です。他のExcelファイルの範囲を参照できます。ただし、自動データ入力の場合、外部ファイルが移動または名前が変更されるとリンクが壊れる可能性があるため、リスクが伴います。産業レポート自動化のより良い実践方法は、Power Queryを使用して外部データを現在のブック内のテーブルに取り込み、そのテーブルでXLOOKUPを使用することです。これにより、すべてのデータが1か所に含まれるため、財務データ抽出がはるかに安定し、監査しやすくなります。
9. XLOOKUPは一度に複数の列を返すことができますか?
バッチOCRからExcelへのユーザーにとって最もクールな機能の1つは、XLOOKUPが完全な行または複数の列を返すことができることです。return_arrayが3列にまたがる場合、XLOOKUPは結果を3列にわたってスピルします。これは、自動データ入力にとって大幅な時間節約になります。「日付」、「金額」、「ベンダー」の3つの別々の数式を作成する代わりに、1つを作成します。これにより、データが同期され、照合中にいずれかの列で数式エラーが発生する可能性が減少します。
10. XLOOKUPが間違った値を返した場合、どうすればよいですか?
まず、[match_mode]を確認してください。設定されていない場合、デフォルトで0(完全一致)になります。通常はこれが望ましいです。次に、前述のテキストとして保存された数値の問題を確認してください。3番目に、検索配列に重複がないことを確認してください。XLOOKUPはデフォルトで最初に見つかった一致を返します(または、[search_mode]を変更した場合は最後)。財務データ抽出では、同じ番号の請求書が2つある場合、間違った方を取得する可能性があります。TabliSyncは、検索ステージに到達する前にソースデータが一意であり、適切にインデックス付けされていることを保証することで、これを防ぐのに役立ちます。
結論: TabliSyncでデータ抽出の未来を体験してください
XLOOKUPチュートリアルをマスターすることは、オペレーショナルエクセレンスへの道のりの始まりにすぎません。Excelは強力なツールですが、入力するデータと同等です。財務データ抽出や産業レポート自動化を手作業で行うことは、エラーと停滞を招く従来のやり方です。現代のプロフェッショナルは、強力なロジックと強力なツールの相乗効果から効率性が生まれることを知っています。
ワークフローにTabliSyncを統合することで、PDFテーブル解析やバッチOCRからExcelへの変換の摩擦を排除できます。ぼやけたスキャンを凝視したり、手動で「テキストとして保存された数値」エラーを照合したり、時間を無駄にしたりする必要はもうありません。TabliSyncは、XLOOKUP数式が求めるクリーンで忠実度の高いデータを提供します。行動しないコストは、チームが戦略的分析ではなく、退屈なデータ入力に費やす毎分で測られます。
AIの方が得意なタスクに専門知識を浪費するのをやめましょう。待つ秒ごとに、自動化できたはずのデータ行が増えます。今すぐTabliSyncの無料トライアルを開始するには、下のリンクをクリックしてください。自動データ入力をボトルネックから競争優位に変えましょう。データの未来は自動化されています。乗り遅れないでください。● Excelの日付フォーマッター
手動入力は不要 – 数秒でテーブルを抽出
画像やPDFの表を99.9%の精度で即座にExcelに変換。TabliSyncのAI OCRは手書きフォーム、レシート、複雑な表を処理し、Google Sheets、Notion、Airtableに直接同期します
今すぐTabliSyncを無料で試す